 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKamalika Chaudhuri
Uncertainty-Based Abstention in LLMs Improves Safety and Reduces Hallucinations
Apr 16, 2024
A major barrier towards the practical deployment of large language models (LLMs) is their lack of reliability. Three situations where this is particularly apparent are correctness, hallucinations when given unanswerable questions, and safety. In all three cases, models should ideally abstain from responding, much like humans, whose ability to understand uncertainty makes us refrain from answering questions we don't know. Inspired by analogous approaches in classification, this study explores the feasibility and efficacy of abstaining while uncertain in the context of LLMs within the domain of question-answering. We investigate two kinds of uncertainties, statistical uncertainty metrics and a distinct verbalized measure, termed as In-Dialogue Uncertainty (InDU). Using these uncertainty measures combined with models with and without Reinforcement Learning with Human Feedback (RLHF), we show that in all three situations, abstention based on the right kind of uncertainty measure can boost the reliability of LLMs. By sacrificing only a few highly uncertain samples we can improve correctness by 2% to 8%, avoid 50% hallucinations via correctly identifying unanswerable questions and increase safety by 70% up to 99% with almost no additional computational overhead.
Guarantees of confidentiality via Hammersley-Chapman-Robbins bounds
Apr 06, 2024Protecting privacy during inference with deep neural networks is possible by adding noise to the activations in the last layers prior to the final classifiers or other task-specific layers. The activations in such layers are known as "features" (or, less commonly, as "embeddings" or "feature embeddings"). The added noise helps prevent reconstruction of the inputs from the noisy features. Lower bounding the variance of every possible unbiased estimator of the inputs quantifies the confidentiality arising from such added noise. Convenient, computationally tractable bounds are available from classic inequalities of Hammersley and of Chapman and Robbins -- the HCR bounds. Numerical experiments indicate that the HCR bounds are on the precipice of being effectual for small neural nets with the data sets, "MNIST" and "CIFAR-10," which contain 10 classes each for image classification. The HCR bounds appear to be insufficient on their own to guarantee confidentiality of the inputs to inference with standard deep neural nets, "ResNet-18" and "Swin-T," pre-trained on the data set, "ImageNet-1000," which contains 1000 classes. Supplementing the addition of noise to features with other methods for providing confidentiality may be warranted in the case of ImageNet. In all cases, the results reported here limit consideration to amounts of added noise that incur little degradation in the accuracy of classification from the noisy features. Thus, the added noise enhances confidentiality without much reduction in the accuracy on the task of image classification.
DP-RDM: Adapting Diffusion Models to Private Domains Without Fine-Tuning
Mar 21, 2024
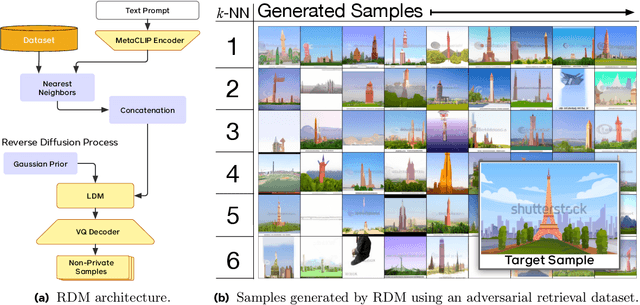
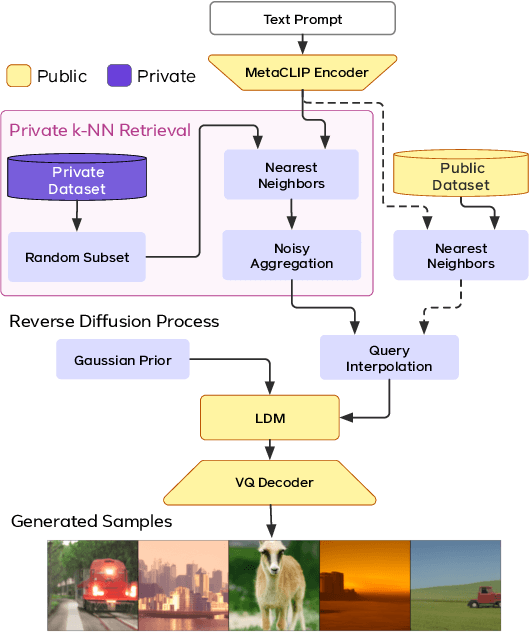

Text-to-image diffusion models have been shown to suffer from sample-level memorization, possibly reproducing near-perfect replica of images that they are trained on, which may be undesirable. To remedy this issue, we develop the first differentially private (DP) retrieval-augmented generation algorithm that is capable of generating high-quality image samples while providing provable privacy guarantees. Specifically, we assume access to a text-to-image diffusion model trained on a small amount of public data, and design a DP retrieval mechanism to augment the text prompt with samples retrieved from a private retrieval dataset. Our \emph{differentially private retrieval-augmented diffusion model} (DP-RDM) requires no fine-tuning on the retrieval dataset to adapt to another domain, and can use state-of-the-art generative models to generate high-quality image samples while satisfying rigorous DP guarantees. For instance, when evaluated on MS-COCO, our DP-RDM can generate samples with a privacy budget of $\epsilon=10$, while providing a $3.5$ point improvement in FID compared to public-only retrieval for up to $10,000$ queries.
Privacy Amplification for the Gaussian Mechanism via Bounded Support
Mar 07, 2024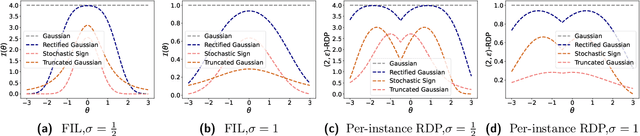

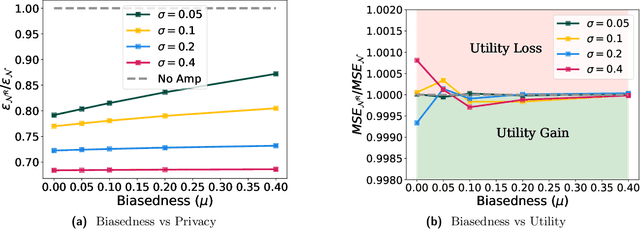

Data-dependent privacy accounting frameworks such as per-instance differential privacy (pDP) and Fisher information loss (FIL) confer fine-grained privacy guarantees for individuals in a fixed training dataset. These guarantees can be desirable compared to vanilla DP in real world settings as they tightly upper-bound the privacy leakage for a $\textit{specific}$ individual in an $\textit{actual}$ dataset, rather than considering worst-case datasets. While these frameworks are beginning to gain popularity, to date, there is a lack of private mechanisms that can fully leverage advantages of data-dependent accounting. To bridge this gap, we propose simple modifications of the Gaussian mechanism with bounded support, showing that they amplify privacy guarantees under data-dependent accounting. Experiments on model training with DP-SGD show that using bounded support Gaussian mechanisms can provide a reduction of the pDP bound $\epsilon$ by as much as 30% without negative effects on model utility.
Differentially Private Representation Learning via Image Captioning
Mar 04, 2024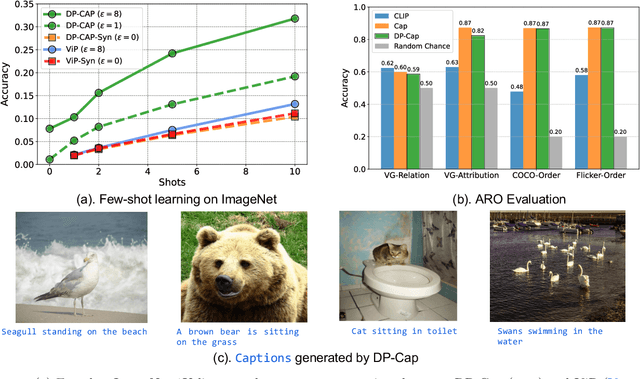
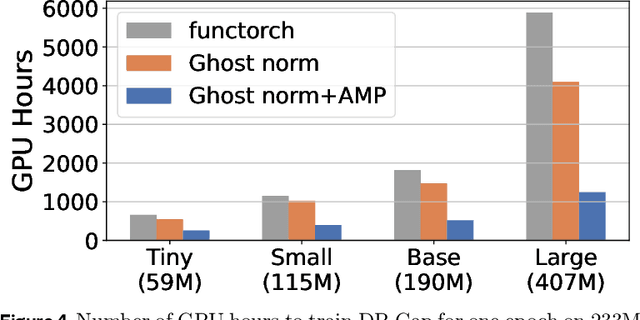
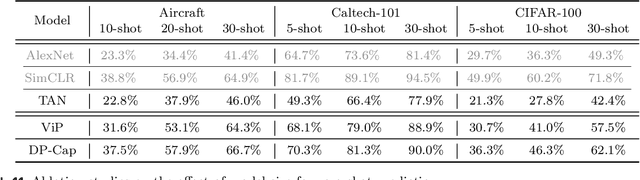
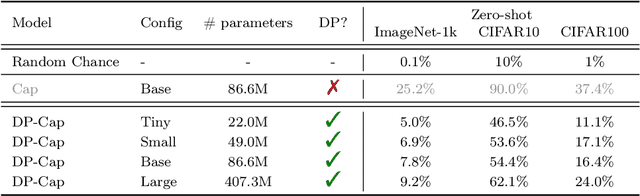
Differentially private (DP) machine learning is considered the gold-standard solution for training a model from sensitive data while still preserving privacy. However, a major barrier to achieving this ideal is its sub-optimal privacy-accuracy trade-off, which is particularly visible in DP representation learning. Specifically, it has been shown that under modest privacy budgets, most models learn representations that are not significantly better than hand-crafted features. In this work, we show that effective DP representation learning can be done via image captioning and scaling up to internet-scale multimodal datasets. Through a series of engineering tricks, we successfully train a DP image captioner (DP-Cap) on a 233M subset of LAION-2B from scratch using a reasonable amount of computation, and obtaining unprecedented high-quality image features that can be used in a variety of downstream vision and vision-language tasks. For example, under a privacy budget of $\varepsilon=8$, a linear classifier trained on top of learned DP-Cap features attains 65.8% accuracy on ImageNet-1K, considerably improving the previous SOTA of 56.5%. Our work challenges the prevailing sentiment that high-utility DP representation learning cannot be achieved by training from scratch.
FairProof : Confidential and Certifiable Fairness for Neural Networks
Feb 19, 2024Machine learning models are increasingly used in societal applications, yet legal and privacy concerns demand that they very often be kept confidential. Consequently, there is a growing distrust about the fairness properties of these models in the minds of consumers, who are often at the receiving end of model predictions. To this end, we propose FairProof - a system that uses Zero-Knowledge Proofs (a cryptographic primitive) to publicly verify the fairness of a model, while maintaining confidentiality. We also propose a fairness certification algorithm for fully-connected neural networks which is befitting to ZKPs and is used in this system. We implement FairProof in Gnark and demonstrate empirically that our system is practically feasible.
Déjà Vu Memorization in Vision-Language Models
Feb 03, 2024Vision-Language Models (VLMs) have emerged as the state-of-the-art representation learning solution, with myriads of downstream applications such as image classification, retrieval and generation. A natural question is whether these models memorize their training data, which also has implications for generalization. We propose a new method for measuring memorization in VLMs, which we call d\'ej\`a vu memorization. For VLMs trained on image-caption pairs, we show that the model indeed retains information about individual objects in the training images beyond what can be inferred from correlations or the image caption. We evaluate d\'ej\`a vu memorization at both sample and population level, and show that it is significant for OpenCLIP trained on as many as 50M image-caption pairs. Finally, we show that text randomization considerably mitigates memorization while only moderately impacting the model's downstream task performance.
Effective pruning of web-scale datasets based on complexity of concept clusters
Jan 09, 2024Utilizing massive web-scale datasets has led to unprecedented performance gains in machine learning models, but also imposes outlandish compute requirements for their training. In order to improve training and data efficiency, we here push the limits of pruning large-scale multimodal datasets for training CLIP-style models. Today's most effective pruning method on ImageNet clusters data samples into separate concepts according to their embedding and prunes away the most prototypical samples. We scale this approach to LAION and improve it by noting that the pruning rate should be concept-specific and adapted to the complexity of the concept. Using a simple and intuitive complexity measure, we are able to reduce the training cost to a quarter of regular training. By filtering from the LAION dataset, we find that training on a smaller set of high-quality data can lead to higher performance with significantly lower training costs. More specifically, we are able to outperform the LAION-trained OpenCLIP-ViT-B32 model on ImageNet zero-shot accuracy by 1.1p.p. while only using 27.7% of the data and training compute. Despite a strong reduction in training cost, we also see improvements on ImageNet dist. shifts, retrieval tasks and VTAB. On the DataComp Medium benchmark, we achieve a new state-of-the-art ImageNet zero-shot accuracy and a competitive average zero-shot accuracy on 38 evaluation tasks.
Differentially Private Multi-Site Treatment Effect Estimation
Oct 10, 2023Patient privacy is a major barrier to healthcare AI. For confidentiality reasons, most patient data remains in silo in separate hospitals, preventing the design of data-driven healthcare AI systems that need large volumes of patient data to make effective decisions. A solution to this is collective learning across multiple sites through federated learning with differential privacy. However, literature in this space typically focuses on differentially private statistical estimation and machine learning, which is different from the causal inference-related problems that arise in healthcare. In this work, we take a fresh look at federated learning with a focus on causal inference; specifically, we look at estimating the average treatment effect (ATE), an important task in causal inference for healthcare applications, and provide a federated analytics approach to enable ATE estimation across multiple sites along with differential privacy (DP) guarantees at each site. The main challenge comes from site heterogeneity -- different sites have different sample sizes and privacy budgets. We address this through a class of per-site estimation algorithms that reports the ATE estimate and its variance as a quality measure, and an aggregation algorithm on the server side that minimizes the overall variance of the final ATE estimate. Our experiments on real and synthetic data show that our method reliably aggregates private statistics across sites and provides better privacy-utility tradeoff under site heterogeneity than baselines.
Unified Uncertainty Calibration
Oct 02, 2023To build robust, fair, and safe AI systems, we would like our classifiers to say ``I don't know'' when facing test examples that are difficult or fall outside of the training classes.The ubiquitous strategy to predict under uncertainty is the simplistic \emph{reject-or-classify} rule: abstain from prediction if epistemic uncertainty is high, classify otherwise.Unfortunately, this recipe does not allow different sources of uncertainty to communicate with each other, produces miscalibrated predictions, and it does not allow to correct for misspecifications in our uncertainty estimates. To address these three issues, we introduce \emph{unified uncertainty calibration (U2C)}, a holistic framework to combine aleatoric and epistemic uncertainties. U2C enables a clean learning-theoretical analysis of uncertainty estimation, and outperforms reject-or-classify across a variety of ImageNet benchmarks.