 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirginia Smith
Privacy Amplification for the Gaussian Mechanism via Bounded Support
Mar 07, 2024
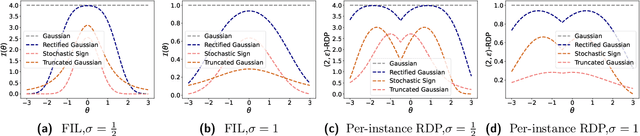

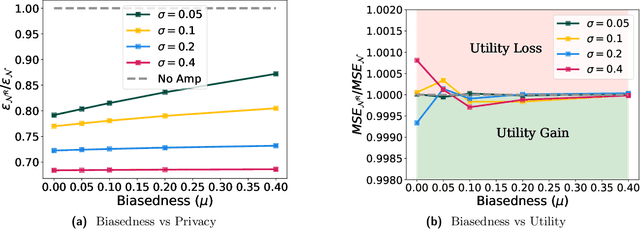

Data-dependent privacy accounting frameworks such as per-instance differential privacy (pDP) and Fisher information loss (FIL) confer fine-grained privacy guarantees for individuals in a fixed training dataset. These guarantees can be desirable compared to vanilla DP in real world settings as they tightly upper-bound the privacy leakage for a $\textit{specific}$ individual in an $\textit{actual}$ dataset, rather than considering worst-case datasets. While these frameworks are beginning to gain popularity, to date, there is a lack of private mechanisms that can fully leverage advantages of data-dependent accounting. To bridge this gap, we propose simple modifications of the Gaussian mechanism with bounded support, showing that they amplify privacy guarantees under data-dependent accounting. Experiments on model training with DP-SGD show that using bounded support Gaussian mechanisms can provide a reduction of the pDP bound $\epsilon$ by as much as 30% without negative effects on model utility.
Many-Objective Multi-Solution Transport
Mar 06, 2024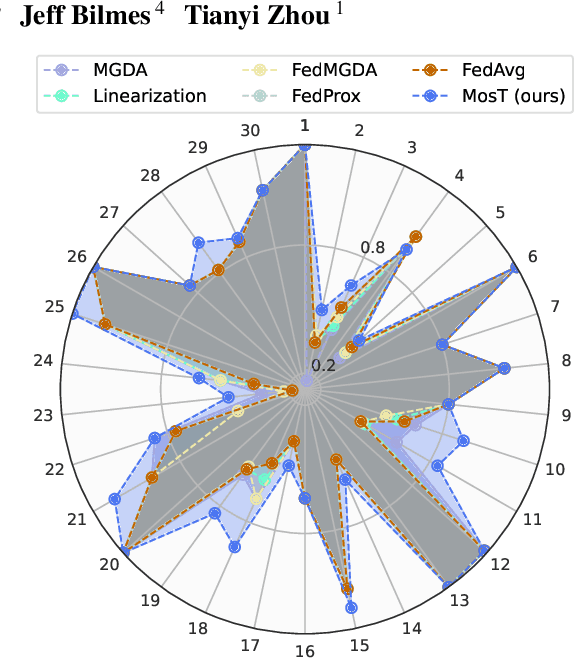

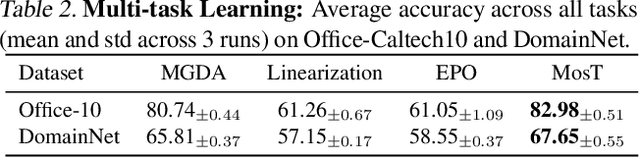
Optimizing the performance of many objectives (instantiated by tasks or clients) jointly with a few Pareto stationary solutions (models) is critical in machine learning. However, previous multi-objective optimization methods often focus on a few number of objectives and cannot scale to many objectives that outnumber the solutions, leading to either subpar performance or ignored objectives. We introduce Many-objective multi-solution Transport (MosT), a framework that finds multiple diverse solutions in the Pareto front of many objectives. Our insight is to seek multiple solutions, each performing as a domain expert and focusing on a specific subset of objectives while collectively covering all of them. MosT formulates the problem as a bi-level optimization of weighted objectives for each solution, where the weights are defined by an optimal transport between the objectives and solutions. Our algorithm ensures convergence to Pareto stationary solutions for complementary subsets of objectives. On a range of applications in federated learning, multi-task learning, and mixture-of-prompt learning for LLMs, MosT distinctly outperforms strong baselines, delivering high-quality, diverse solutions that profile the entire Pareto frontier, thus ensuring balanced trade-offs across many objectives.
Guardrail Baselines for Unlearning in LLMs
Mar 05, 2024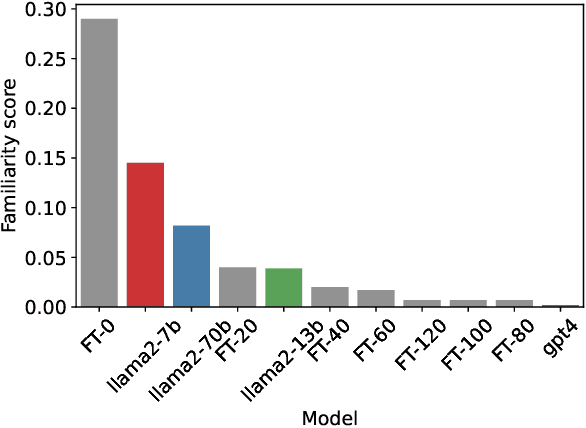
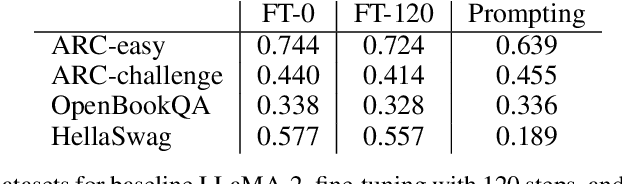
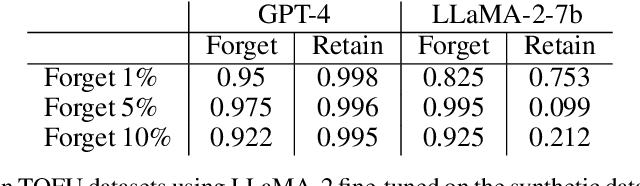
Recent work has demonstrated that fine-tuning is a promising approach to `unlearn' concepts from large language models. However, fine-tuning can be expensive, as it requires both generating a set of examples and running iterations of fine-tuning to update the model. In this work, we show that simple guardrail-based approaches such as prompting and filtering can achieve unlearning results comparable to fine-tuning. We recommend that researchers investigate these lightweight baselines when evaluating the performance of more computationally intensive fine-tuning methods. While we do not claim that methods such as prompting or filtering are universal solutions to the problem of unlearning, our work suggests the need for evaluation metrics that can better separate the power of guardrails vs. fine-tuning, and highlights scenarios where guardrails themselves may be advantageous for unlearning, such as in generating examples for fine-tuning or unlearning when only API access is available.
Attacking LLM Watermarks by Exploiting Their Strengths
Feb 25, 2024Advances in generative models have made it possible for AI-generated text, code, and images to mirror human-generated content in many applications. Watermarking, a technique that aims to embed information in the output of a model to verify its source, is useful for mitigating misuse of such AI-generated content. However, existing watermarking schemes remain surprisingly susceptible to attack. In particular, we show that desirable properties shared by existing LLM watermarking systems such as quality preservation, robustness, and public detection APIs can in turn make these systems vulnerable to various attacks. We rigorously study potential attacks in terms of common watermark design choices, and propose best practices and defenses for mitigation -- establishing a set of practical guidelines for embedding and detection of LLM watermarks.
Everybody Prune Now: Structured Pruning of LLMs with only Forward Passes
Feb 09, 2024Given the generational gap in available hardware between lay practitioners and the most endowed institutions, LLMs are becoming increasingly inaccessible as they grow in size. Whilst many approaches have been proposed to compress LLMs to make their resource consumption manageable, these methods themselves tend to be resource intensive, putting them out of the reach of the very user groups they target. In this work, we explore the problem of structured pruning of LLMs using only forward passes. We seek to empower practitioners to prune models so large that their available hardware has just enough memory to run inference. We develop Bonsai, a gradient-free, perturbative pruning method capable of delivering small, fast, and accurate pruned models. We observe that Bonsai outputs pruned models that (i) outperform those generated by more expensive gradient-based structured pruning methods, and (ii) are twice as fast (with comparable accuracy) as those generated by semi-structured pruning methods requiring comparable resources as Bonsai. We also leverage Bonsai to produce a new sub-2B model using a single A6000 that yields state-of-the-art performance on 4/6 tasks on the Huggingface Open LLM leaderboard.
Leveraging Public Representations for Private Transfer Learning
Jan 16, 2024Motivated by the recent empirical success of incorporating public data into differentially private learning, we theoretically investigate how a shared representation learned from public data can improve private learning. We explore two common scenarios of transfer learning for linear regression, both of which assume the public and private tasks (regression vectors) share a low-rank subspace in a high-dimensional space. In the first single-task transfer scenario, the goal is to learn a single model shared across all users, each corresponding to a row in a dataset. We provide matching upper and lower bounds showing that our algorithm achieves the optimal excess risk within a natural class of algorithms that search for the linear model within the given subspace estimate. In the second scenario of multitask model personalization, we show that with sufficient public data, users can avoid private coordination, as purely local learning within the given subspace achieves the same utility. Taken together, our results help to characterize the benefits of public data across common regimes of private transfer learning.
Complementary Benefits of Contrastive Learning and Self-Training Under Distribution Shift
Dec 06, 2023Self-training and contrastive learning have emerged as leading techniques for incorporating unlabeled data, both under distribution shift (unsupervised domain adaptation) and when it is absent (semi-supervised learning). However, despite the popularity and compatibility of these techniques, their efficacy in combination remains unexplored. In this paper, we undertake a systematic empirical investigation of this combination, finding that (i) in domain adaptation settings, self-training and contrastive learning offer significant complementary gains; and (ii) in semi-supervised learning settings, surprisingly, the benefits are not synergistic. Across eight distribution shift datasets (e.g., BREEDs, WILDS), we demonstrate that the combined method obtains 3--8% higher accuracy than either approach independently. We then theoretically analyze these techniques in a simplified model of distribution shift, demonstrating scenarios under which the features produced by contrastive learning can yield a good initialization for self-training to further amplify gains and achieve optimal performance, even when either method alone would fail.
Noise-Reuse in Online Evolution Strategies
Apr 21, 2023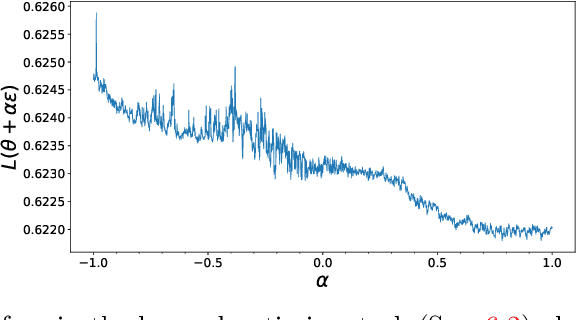

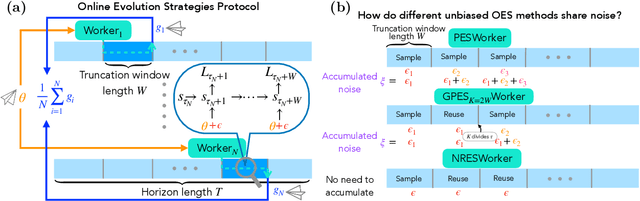
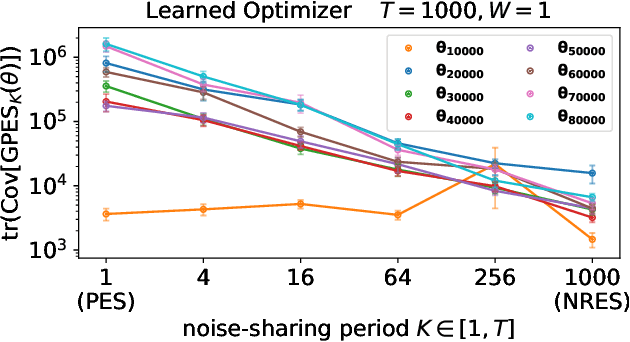
Online evolution strategies have become an attractive alternative to automatic differentiation (AD) due to their ability to handle chaotic and black-box loss functions, while also allowing more frequent gradient updates than vanilla Evolution Strategies (ES). In this work, we propose a general class of unbiased online evolution strategies. We analytically and empirically characterize the variance of this class of gradient estimators and identify the one with the least variance, which we term Noise-Reuse Evolution Strategies (NRES). Experimentally, we show that NRES results in faster convergence than existing AD and ES methods in terms of wall-clock speed and total number of unroll steps across a variety of applications, including learning dynamical systems, meta-training learned optimizers, and reinforcement learning.
Progressive Knowledge Distillation: Building Ensembles for Efficient Inference
Feb 20, 2023
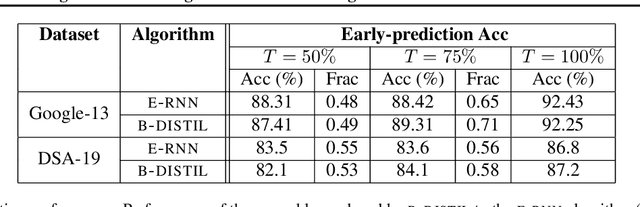
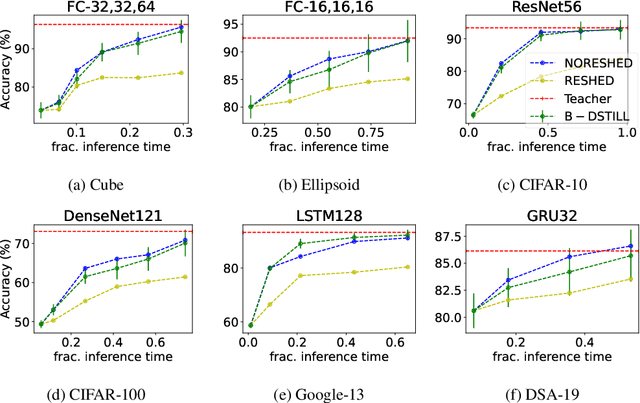
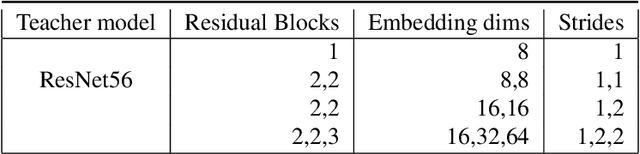
We study the problem of progressive distillation: Given a large, pre-trained teacher model $g$, we seek to decompose the model into an ensemble of smaller, low-inference cost student models $f_i$. The resulting ensemble allows for flexibly tuning accuracy vs. inference cost, which is useful for a number of applications in on-device inference. The method we propose, B-DISTIL, relies on an algorithmic procedure that uses function composition over intermediate activations to construct expressive ensembles with similar performance as $g$, but with much smaller student models. We demonstrate the effectiveness of \algA by decomposing pretrained models across standard image, speech, and sensor datasets. We also provide theoretical guarantees for our method in terms of convergence and generalization.
Federated Learning as a Network Effects Game
Feb 16, 2023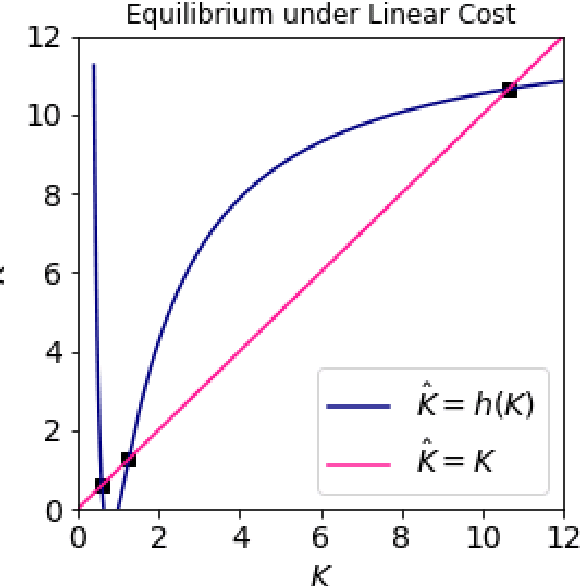
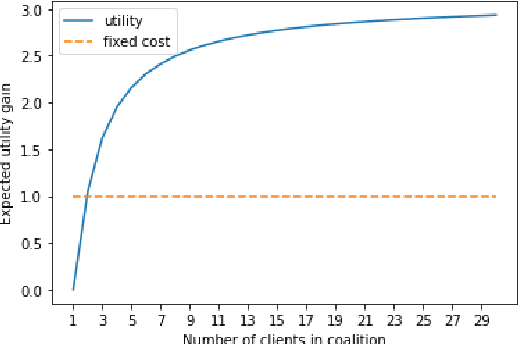
Federated Learning (FL) aims to foster collaboration among a population of clients to improve the accuracy of machine learning without directly sharing local data. Although there has been rich literature on designing federated learning algorithms, most prior works implicitly assume that all clients are willing to participate in a FL scheme. In practice, clients may not benefit from joining in FL, especially in light of potential costs related to issues such as privacy and computation. In this work, we study the clients' incentives in federated learning to help the service provider design better solutions and ensure clients make better decisions. We are the first to model clients' behaviors in FL as a network effects game, where each client's benefit depends on other clients who also join the network. Using this setup we analyze the dynamics of clients' participation and characterize the equilibrium, where no client has incentives to alter their decision. Specifically, we show that dynamics in the population naturally converge to equilibrium without needing explicit interventions. Finally, we provide a cost-efficient payment scheme that incentivizes clients to reach a desired equilibrium when the initial network is empty.