 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLemeng Wu
Communication Efficient Distributed Training with Distributed Lion
Mar 30, 2024
The Lion optimizer has been a promising competitor with the AdamW for training large AI models, with advantages on memory, computation, and sample efficiency. In this paper, we introduce Distributed Lion, an innovative adaptation of Lion for distributed training environments. Leveraging the sign operator in Lion, our Distributed Lion only requires communicating binary or lower-precision vectors between workers to the center server, significantly reducing the communication cost. Our theoretical analysis confirms Distributed Lion's convergence properties. Empirical results demonstrate its robustness across a range of tasks, worker counts, and batch sizes, on both vision and language problems. Notably, Distributed Lion attains comparable performance to standard Lion or AdamW optimizers applied on aggregated gradients, but with significantly reduced communication bandwidth. This feature is particularly advantageous for training large models. In addition, we also demonstrate that Distributed Lion presents a more favorable performance-bandwidth balance compared to existing efficient distributed methods such as deep gradient compression and ternary gradients.
Language Rectified Flow: Advancing Diffusion Language Generation with Probabilistic Flows
Mar 25, 2024Recent works have demonstrated success in controlling sentence attributes ($e.g.$, sentiment) and structure ($e.g.$, syntactic structure) based on the diffusion language model. A key component that drives theimpressive performance for generating high-quality samples from noise is iteratively denoise for thousands of steps. While beneficial, the complexity of starting from the noise and the learning steps has limited its implementation to many NLP real-world applications. This paper proposes Language Rectified Flow ({\ours}). Our method is based on the reformulation of the standard probabilistic flow models. Language rectified flow learns (neural) ordinary differential equation models to transport between the source distribution and the target distribution, hence providing a unified and effective solution to generative modeling and domain transfer. From the source distribution, our language rectified flow yields fast simulation and effectively decreases the inference time. Experiments on three challenging fine-grained control tasks and multiple high-quality text editing show that our method consistently outperforms its baselines. Extensive experiments and ablation studies demonstrate that our method can be general, effective, and beneficial for many NLP tasks.
SqueezeSAM: User friendly mobile interactive segmentation
Dec 11, 2023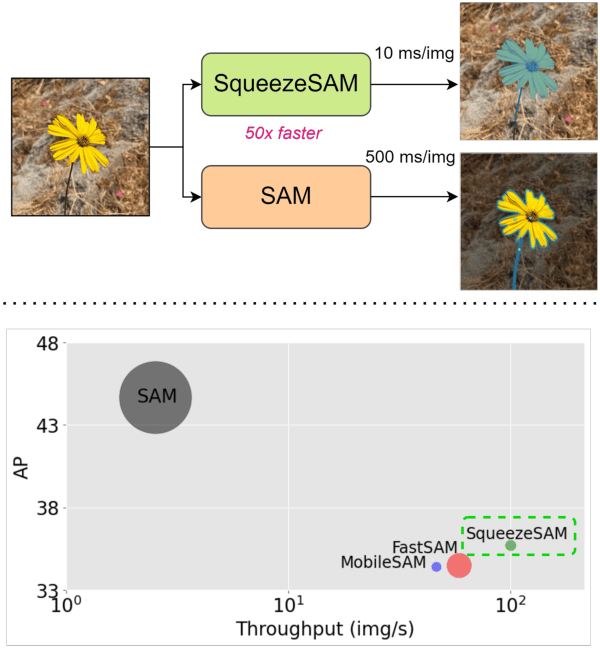
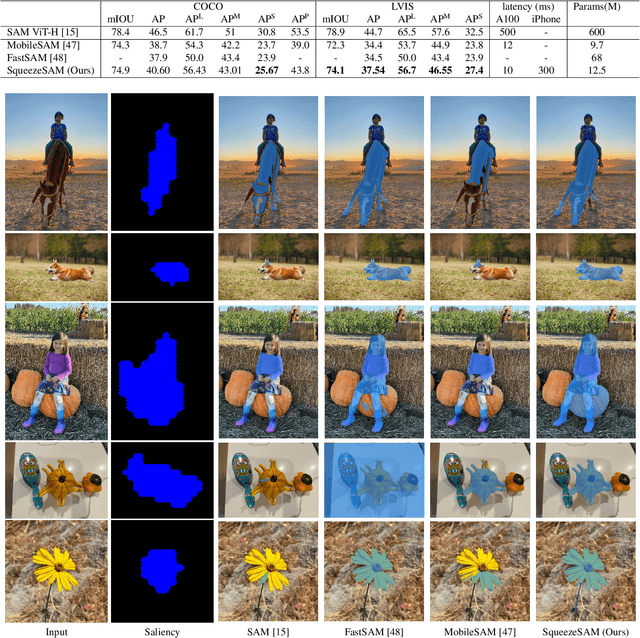

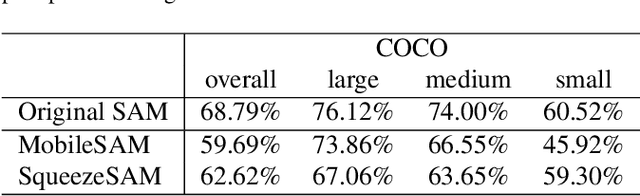
Segment Anything Model (SAM) is a foundation model for interactive segmentation, and it has catalyzed major advances in generative AI, computational photography, and medical imaging. This model takes in an arbitrary user input and provides segmentation masks of the corresponding objects. It is our goal to develop a version of SAM that is appropriate for use in a photography app. The original SAM model has a few challenges in this setting. First, original SAM a 600 million parameter based on ViT-H, and its high computational cost and large model size that are not suitable for todays mobile hardware. We address this by proposing the SqueezeSAM model architecture, which is 50x faster and 100x smaller than SAM. Next, when a user takes a photo on their phone, it might not occur to them to click on the image and get a mask. Our solution is to use salient object detection to generate the first few clicks. This produces an initial segmentation mask that the user can interactively edit. Finally, when a user clicks on an object, they typically expect all related pieces of the object to be segmented. For instance, if a user clicks on a person t-shirt in a photo, they expect the whole person to be segmented, but SAM typically segments just the t-shirt. We address this with a new data augmentation scheme, and the end result is that if the user clicks on a person holding a basketball, the person and the basketball are all segmented together.
EfficientSAM: Leveraged Masked Image Pretraining for Efficient Segment Anything
Dec 01, 2023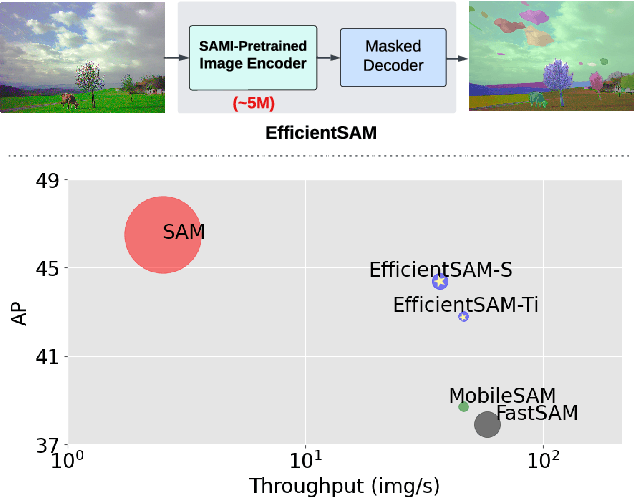
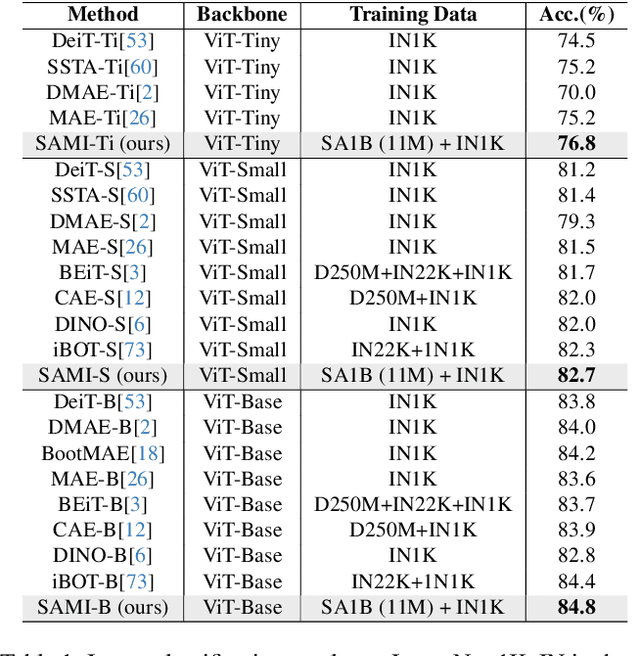
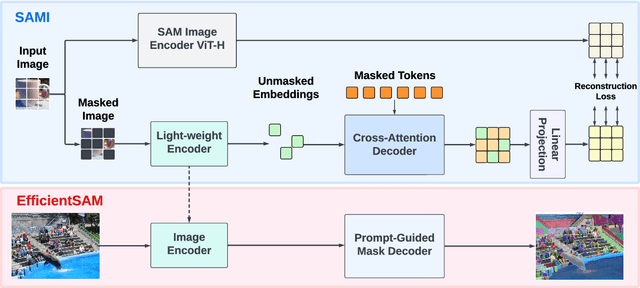
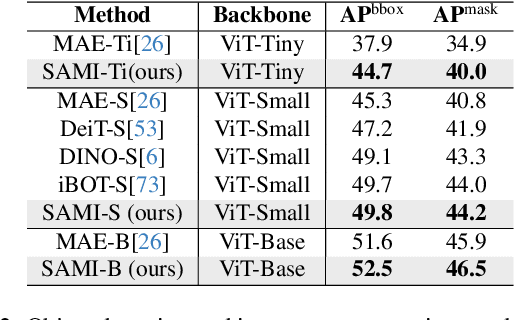
Segment Anything Model (SAM) has emerged as a powerful tool for numerous vision applications. A key component that drives the impressive performance for zero-shot transfer and high versatility is a super large Transformer model trained on the extensive high-quality SA-1B dataset. While beneficial, the huge computation cost of SAM model has limited its applications to wider real-world applications. To address this limitation, we propose EfficientSAMs, light-weight SAM models that exhibits decent performance with largely reduced complexity. Our idea is based on leveraging masked image pretraining, SAMI, which learns to reconstruct features from SAM image encoder for effective visual representation learning. Further, we take SAMI-pretrained light-weight image encoders and mask decoder to build EfficientSAMs, and finetune the models on SA-1B for segment anything task. We perform evaluations on multiple vision tasks including image classification, object detection, instance segmentation, and semantic object detection, and find that our proposed pretraining method, SAMI, consistently outperforms other masked image pretraining methods. On segment anything task such as zero-shot instance segmentation, our EfficientSAMs with SAMI-pretrained lightweight image encoders perform favorably with a significant gain (e.g., ~4 AP on COCO/LVIS) over other fast SAM models.
AutoML-GPT: Automatic Machine Learning with GPT
May 04, 2023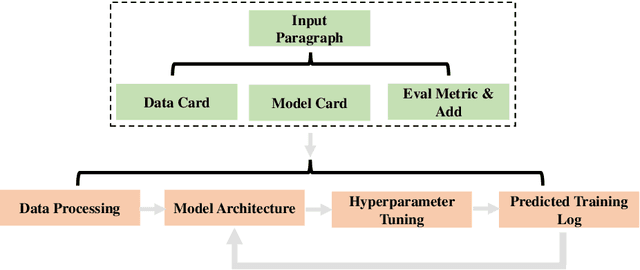
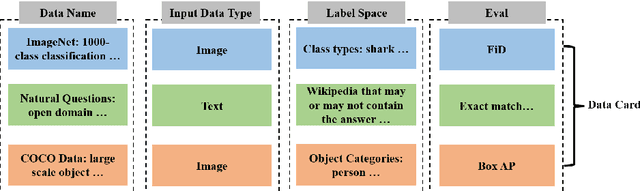

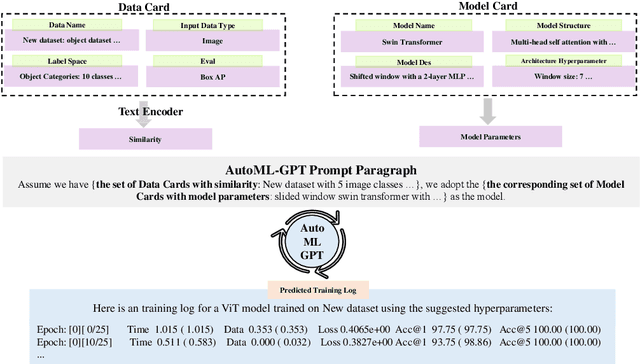
AI tasks encompass a wide range of domains and fields. While numerous AI models have been designed for specific tasks and applications, they often require considerable human efforts in finding the right model architecture, optimization algorithm, and hyperparameters. Recent advances in large language models (LLMs) like ChatGPT show remarkable capabilities in various aspects of reasoning, comprehension, and interaction. Consequently, we propose developing task-oriented prompts and automatically utilizing LLMs to automate the training pipeline. To implement this concept, we present the AutoML-GPT, which employs GPT as the bridge to diverse AI models and dynamically trains models with optimized hyperparameters. AutoML-GPT dynamically takes user requests from the model and data cards and composes the corresponding prompt paragraph. Ultimately, with this prompt paragraph, AutoML-GPT will automatically conduct the experiments from data processing to model architecture, hyperparameter tuning, and predicted training log. By leveraging {\ours}'s robust language capabilities and the available AI models, AutoML-GPT can tackle numerous intricate AI tasks across various tasks and datasets. This approach achieves remarkable results in computer vision, natural language processing, and other challenging areas. Extensive experiments and ablation studies demonstrate that our method can be general, effective, and beneficial for many AI tasks.
PathFusion: Path-consistent Lidar-Camera Deep Feature Fusion
Dec 12, 2022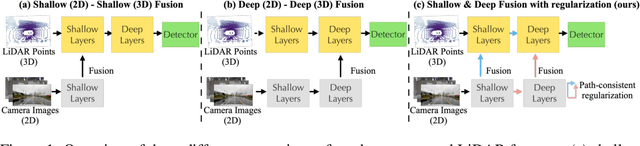
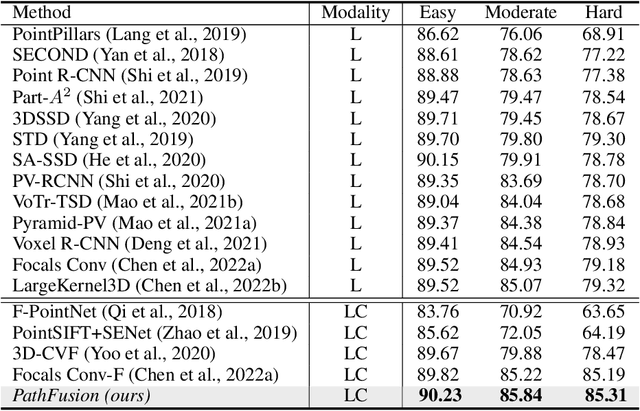
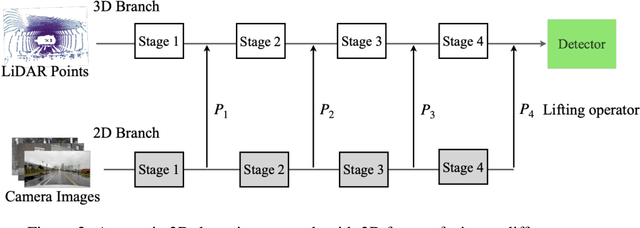

Fusing camera with LiDAR is a promising technique to improve the accuracy of 3D detection due to the complementary physical properties. While most existing methods focus on fusing camera features directly with raw LiDAR point clouds or shallow 3D features, it is observed that direct deep 3D feature fusion achieves inferior accuracy due to feature misalignment. The misalignment that originates from the feature aggregation across large receptive fields becomes increasingly severe for deep network stages. In this paper, we propose PathFusion to enable path-consistent LiDAR-camera deep feature fusion. PathFusion introduces a path consistency loss between shallow and deep features, which encourages the 2D backbone and its fusion path to transform 2D features in a way that is semantically aligned with the transform of the 3D backbone. We apply PathFusion to the prior-art fusion baseline, Focals Conv, and observe more than 1.2\% mAP improvements on the nuScenes test split consistently with and without testing-time augmentations. Moreover, PathFusion also improves KITTI AP3D (R11) by more than 0.6% on moderate level.
Fast Point Cloud Generation with Straight Flows
Dec 04, 2022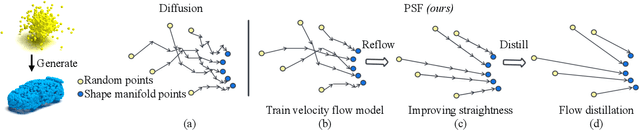
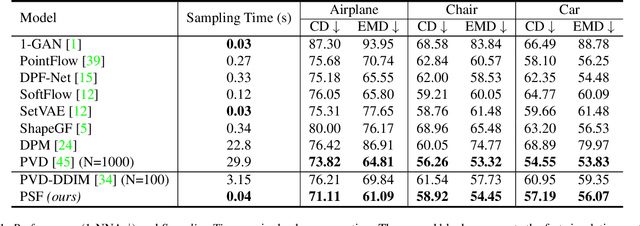
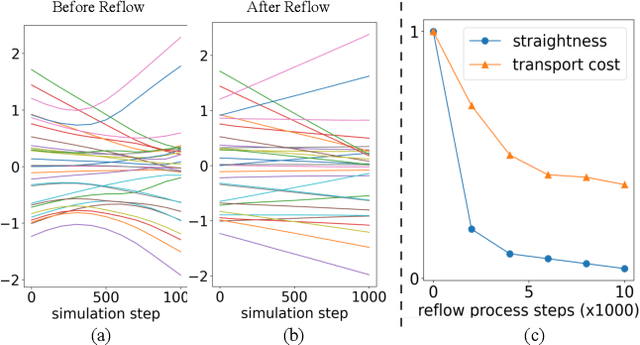
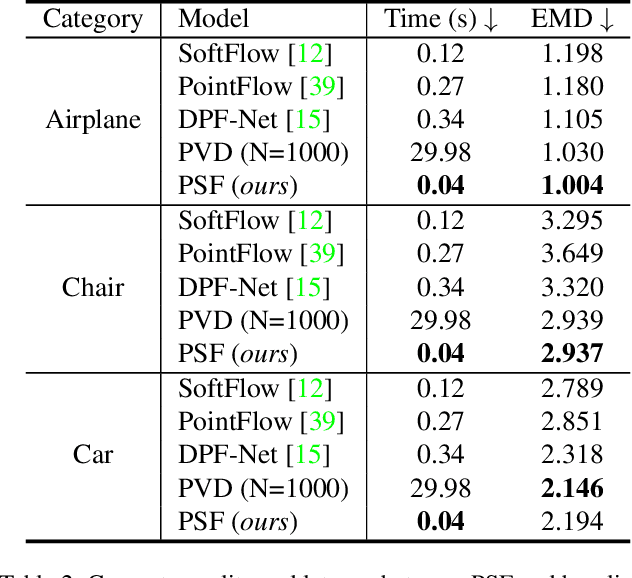
Diffusion models have emerged as a powerful tool for point cloud generation. A key component that drives the impressive performance for generating high-quality samples from noise is iteratively denoise for thousands of steps. While beneficial, the complexity of learning steps has limited its applications to many 3D real-world. To address this limitation, we propose Point Straight Flow (PSF), a model that exhibits impressive performance using one step. Our idea is based on the reformulation of the standard diffusion model, which optimizes the curvy learning trajectory into a straight path. Further, we develop a distillation strategy to shorten the straight path into one step without a performance loss, enabling applications to 3D real-world with latency constraints. We perform evaluations on multiple 3D tasks and find that our PSF performs comparably to the standard diffusion model, outperforming other efficient 3D point cloud generation methods. On real-world applications such as point cloud completion and training-free text-guided generation in a low-latency setup, PSF performs favorably.
Neural Volumetric Mesh Generator
Oct 06, 2022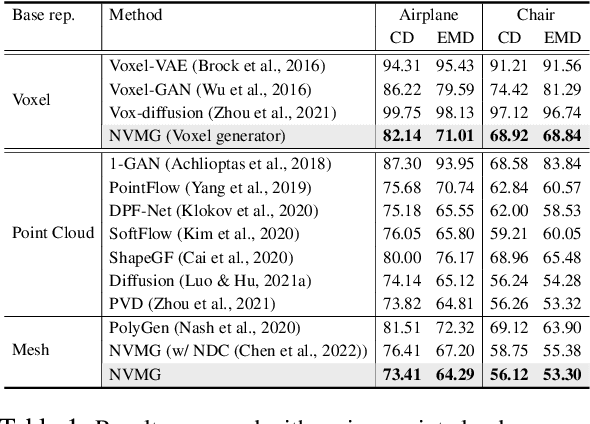
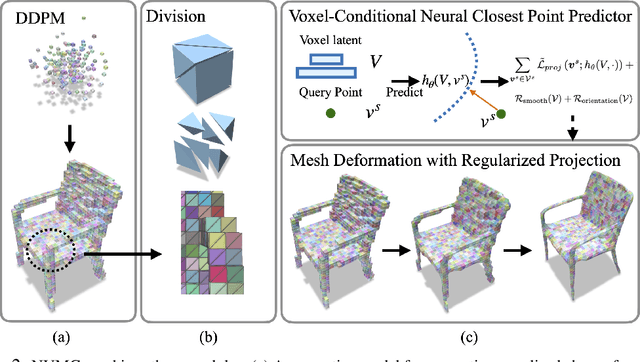

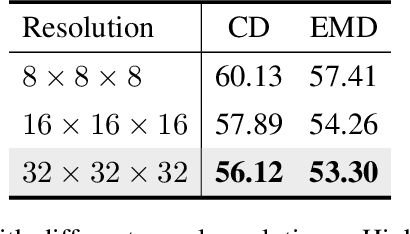
Deep generative models have shown success in generating 3D shapes with different representations. In this work, we propose Neural Volumetric Mesh Generator(NVMG) which can generate novel and high-quality volumetric meshes. Unlike the previous 3D generative model for point cloud, voxel, and implicit surface, the volumetric mesh representation is a ready-to-use representation in industry with details on both the surface and interior. Generating this such highly-structured data thus brings a significant challenge. We first propose a diffusion-based generative model to tackle this problem by generating voxelized shapes with close-to-reality outlines and structures. We can simply obtain a tetrahedral mesh as a template with the voxelized shape. Further, we use a voxel-conditional neural network to predict the smooth implicit surface conditioned on the voxels, and progressively project the tetrahedral mesh to the predicted surface under regularizations. The regularization terms are carefully designed so that they can (1) get rid of the defects like flipping and high distortion; (2) force the regularity of the interior and surface structure during the deformation procedure for a high-quality final mesh. As shown in the experiments, our pipeline can generate high-quality artifact-free volumetric and surface meshes from random noise or a reference image without any post-processing. Compared with the state-of-the-art voxel-to-mesh deformation method, we show more robustness and better performance when taking generated voxels as input.
First Hitting Diffusion Models
Sep 02, 2022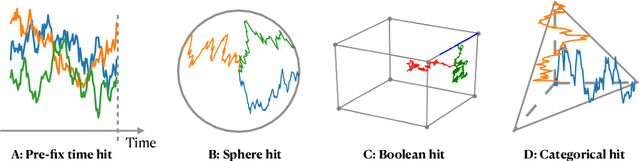
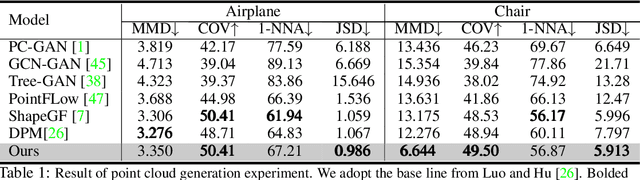
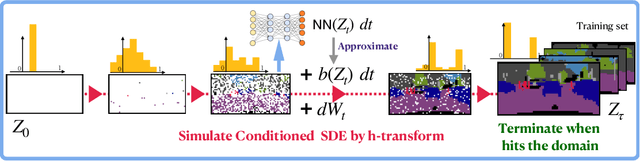
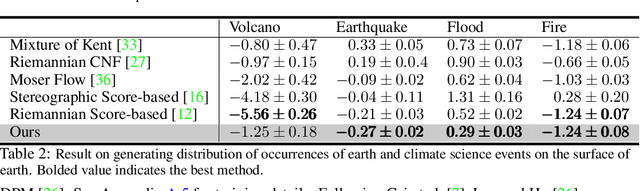
We propose a family of First Hitting Diffusion Models (FHDM), deep generative models that generate data with a diffusion process that terminates at a random first hitting time. This yields an extension of the standard fixed-time diffusion models that terminate at a pre-specified deterministic time. Although standard diffusion models are designed for continuous unconstrained data, FHDM is naturally designed to learn distributions on continuous as well as a range of discrete and structure domains. Moreover, FHDM enables instance-dependent terminate time and accelerates the diffusion process to sample higher quality data with fewer diffusion steps. Technically, we train FHDM by maximum likelihood estimation on diffusion trajectories augmented from observed data with conditional first hitting processes (i.e., bridge) derived based on Doob's $h$-transform, deviating from the commonly used time-reversal mechanism. We apply FHDM to generate data in various domains such as point cloud (general continuous distribution), climate and geographical events on earth (continuous distribution on the sphere), unweighted graphs (distribution of binary matrices), and segmentation maps of 2D images (high-dimensional categorical distribution). We observe considerable improvement compared with the state-of-the-art approaches in both quality and speed.
Diffusion-based Molecule Generation with Informative Prior Bridges
Sep 02, 2022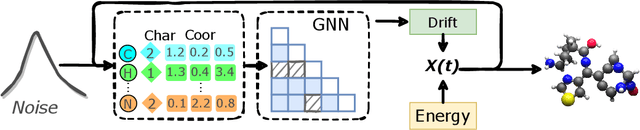
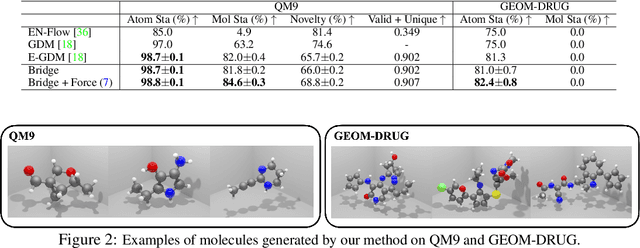


AI-based molecule generation provides a promising approach to a large area of biomedical sciences and engineering, such as antibody design, hydrolase engineering, or vaccine development. Because the molecules are governed by physical laws, a key challenge is to incorporate prior information into the training procedure to generate high-quality and realistic molecules. We propose a simple and novel approach to steer the training of diffusion-based generative models with physical and statistics prior information. This is achieved by constructing physically informed diffusion bridges, stochastic processes that guarantee to yield a given observation at the fixed terminal time. We develop a Lyapunov function based method to construct and determine bridges, and propose a number of proposals of informative prior bridges for both high-quality molecule generation and uniformity-promoted 3D point cloud generation. With comprehensive experiments, we show that our method provides a powerful approach to the 3D generation task, yielding molecule structures with better quality and stability scores and more uniformly distributed point clouds of high qualities.