 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhen Chen
Enhancing Surgical Robots with Embodied Intelligence for Autonomous Ultrasound Scanning
May 01, 2024
Ultrasound robots are increasingly used in medical diagnostics and early disease screening. However, current ultrasound robots lack the intelligence to understand human intentions and instructions, hindering autonomous ultrasound scanning. To solve this problem, we propose a novel Ultrasound Embodied Intelligence system that equips ultrasound robots with the large language model (LLM) and domain knowledge, thereby improving the efficiency of ultrasound robots. Specifically, we first design an ultrasound operation knowledge database to add expertise in ultrasound scanning to the LLM, enabling the LLM to perform precise motion planning. Furthermore, we devise a dynamic ultrasound scanning strategy based on a \textit{think-observe-execute} prompt engineering, allowing LLMs to dynamically adjust motion planning strategies during the scanning procedures. Extensive experiments demonstrate that our system significantly improves ultrasound scan efficiency and quality from verbal commands. This advancement in autonomous medical scanning technology contributes to non-invasive diagnostics and streamlined medical workflows.
Transitive Vision-Language Prompt Learning for Domain Generalization
Apr 29, 2024The vision-language pre-training has enabled deep models to make a huge step forward in generalizing across unseen domains. The recent learning method based on the vision-language pre-training model is a great tool for domain generalization and can solve this problem to a large extent. However, there are still some issues that an advancement still suffers from trading-off between domain invariance and class separability, which are crucial in current DG problems. However, there are still some issues that an advancement still suffers from trading-off between domain invariance and class separability, which are crucial in current DG problems. In this paper, we introduce a novel prompt learning strategy that leverages deep vision prompts to address domain invariance while utilizing language prompts to ensure class separability, coupled with adaptive weighting mechanisms to balance domain invariance and class separability. Extensive experiments demonstrate that deep vision prompts effectively extract domain-invariant features, significantly improving the generalization ability of deep models and achieving state-of-the-art performance on three datasets.
Large-Scale Multi-Domain Recommendation: an Automatic Domain Feature Extraction and Personalized Integration Framework
Apr 15, 2024Feed recommendation is currently the mainstream mode for many real-world applications (e.g., TikTok, Dianping), it is usually necessary to model and predict user interests in multiple scenarios (domains) within and even outside the application. Multi-domain learning is a typical solution in this regard. While considerable efforts have been made in this regard, there are still two long-standing challenges: (1) Accurately depicting the differences among domains using domain features is crucial for enhancing the performance of each domain. However, manually designing domain features and models for numerous domains can be a laborious task. (2) Users typically have limited impressions in only a few domains. Extracting features automatically from other domains and leveraging them to improve the predictive capabilities of each domain has consistently posed a challenging problem. In this paper, we propose an Automatic Domain Feature Extraction and Personalized Integration (DFEI) framework for the large-scale multi-domain recommendation. The framework automatically transforms the behavior of each individual user into an aggregation of all user behaviors within the domain, which serves as the domain features. Unlike offline feature engineering methods, the extracted domain features are higher-order representations and directly related to the target label. Besides, by personalized integration of domain features from other domains for each user and the innovation in the training mode, the DFEI framework can yield more accurate conversion identification. Experimental results on both public and industrial datasets, consisting of over 20 domains, clearly demonstrate that the proposed framework achieves significantly better performance compared with SOTA baselines. Furthermore, we have released the source code of the proposed framework at https://github.com/xidongbo/DFEI.
Unified Multi-modal Diagnostic Framework with Reconstruction Pre-training and Heterogeneity-combat Tuning
Apr 09, 2024Medical multi-modal pre-training has revealed promise in computer-aided diagnosis by leveraging large-scale unlabeled datasets. However, existing methods based on masked autoencoders mainly rely on data-level reconstruction tasks, but lack high-level semantic information. Furthermore, two significant heterogeneity challenges hinder the transfer of pre-trained knowledge to downstream tasks, \textit{i.e.}, the distribution heterogeneity between pre-training data and downstream data, and the modality heterogeneity within downstream data. To address these challenges, we propose a Unified Medical Multi-modal Diagnostic (UMD) framework with tailored pre-training and downstream tuning strategies. Specifically, to enhance the representation abilities of vision and language encoders, we propose the Multi-level Reconstruction Pre-training (MR-Pretrain) strategy, including a feature-level and data-level reconstruction, which guides models to capture the semantic information from masked inputs of different modalities. Moreover, to tackle two kinds of heterogeneities during the downstream tuning, we present the heterogeneity-combat downstream tuning strategy, which consists of a Task-oriented Distribution Calibration (TD-Calib) and a Gradient-guided Modality Coordination (GM-Coord). In particular, TD-Calib fine-tunes the pre-trained model regarding the distribution of downstream datasets, and GM-Coord adjusts the gradient weights according to the dynamic optimization status of different modalities. Extensive experiments on five public medical datasets demonstrate the effectiveness of our UMD framework, which remarkably outperforms existing approaches on three kinds of downstream tasks.
Unsupervised Learning for Joint Beamforming Design in RIS-aided ISAC Systems
Mar 26, 2024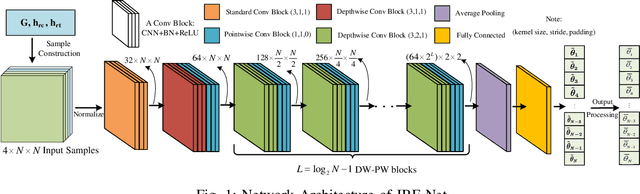
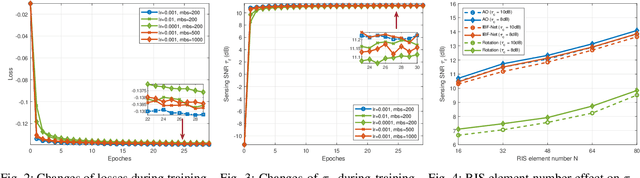
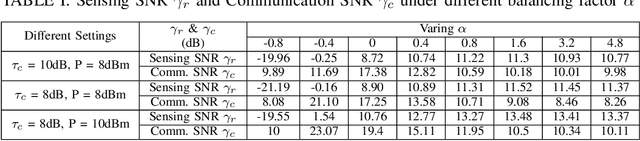
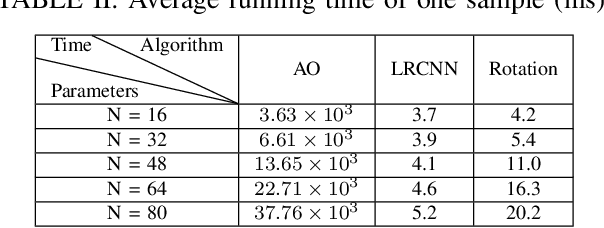
It is critical to design efficient beamforming in reconfigurable intelligent surface (RIS)-aided integrated sensing and communication (ISAC) systems for enhancing spectrum utilization. However, conventional methods often have limitations, either incurring high computational complexity due to iterative algorithms or sacrificing performance when using heuristic methods. To achieve both low complexity and high spectrum efficiency, an unsupervised learning-based beamforming design is proposed in this work. We tailor image-shaped channel samples and develop an ISAC beamforming neural network (IBF-Net) model for beamforming. By leveraging unsupervised learning, the loss function incorporates key performance metrics like sensing and communication channel correlation and sensing channel gain, eliminating the need of labeling. Simulations show that the proposed method achieves competitive performance compared to benchmarks while significantly reduces computational complexity.
Endora: Video Generation Models as Endoscopy Simulators
Mar 17, 2024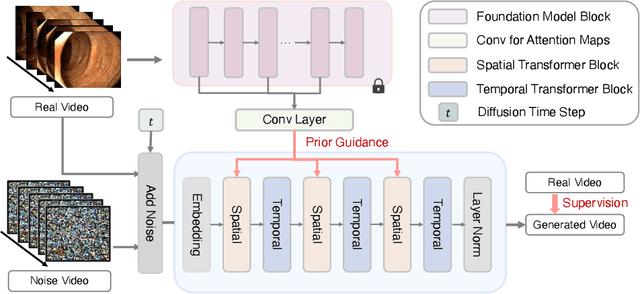


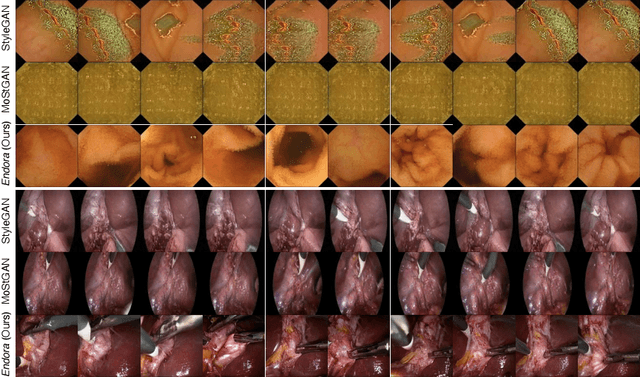
Generative models hold promise for revolutionizing medical education, robot-assisted surgery, and data augmentation for machine learning. Despite progress in generating 2D medical images, the complex domain of clinical video generation has largely remained untapped.This paper introduces \model, an innovative approach to generate medical videos that simulate clinical endoscopy scenes. We present a novel generative model design that integrates a meticulously crafted spatial-temporal video transformer with advanced 2D vision foundation model priors, explicitly modeling spatial-temporal dynamics during video generation. We also pioneer the first public benchmark for endoscopy simulation with video generation models, adapting existing state-of-the-art methods for this endeavor.Endora demonstrates exceptional visual quality in generating endoscopy videos, surpassing state-of-the-art methods in extensive testing. Moreover, we explore how this endoscopy simulator can empower downstream video analysis tasks and even generate 3D medical scenes with multi-view consistency. In a nutshell, Endora marks a notable breakthrough in the deployment of generative AI for clinical endoscopy research, setting a substantial stage for further advances in medical content generation. For more details, please visit our project page: https://endora-medvidgen.github.io/.
GaussianGrasper: 3D Language Gaussian Splatting for Open-vocabulary Robotic Grasping
Mar 14, 2024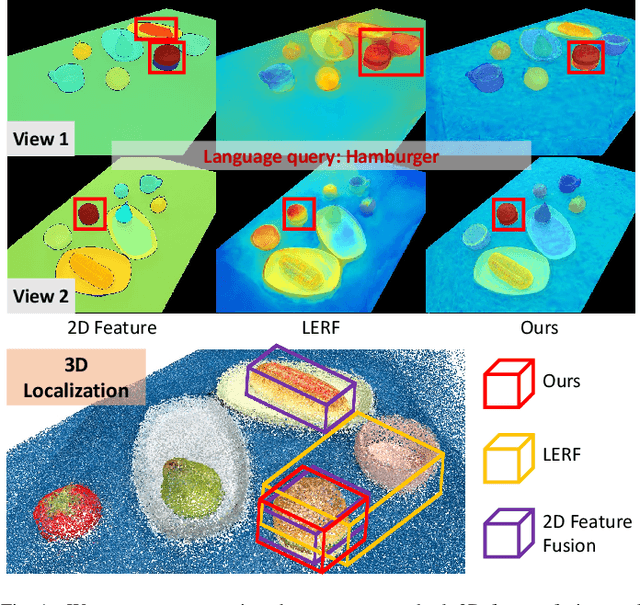
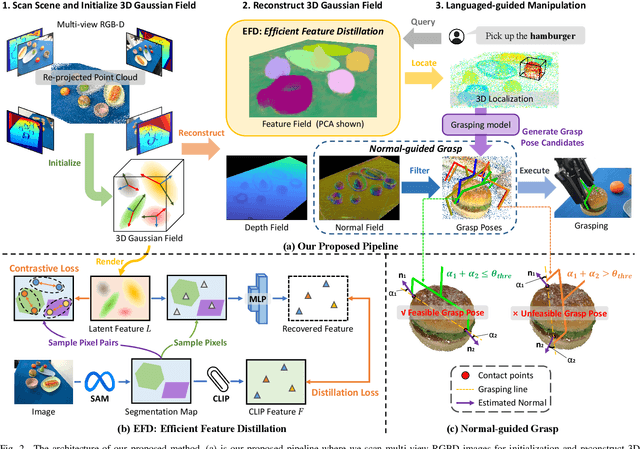
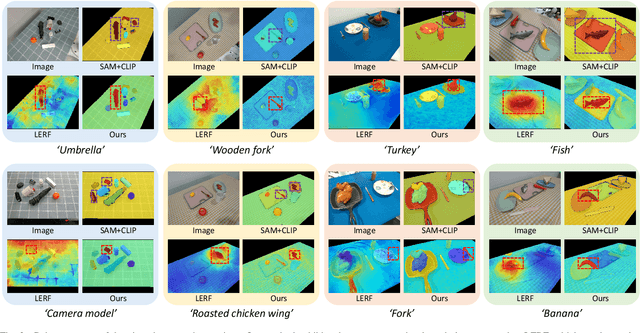

Constructing a 3D scene capable of accommodating open-ended language queries, is a pivotal pursuit, particularly within the domain of robotics. Such technology facilitates robots in executing object manipulations based on human language directives. To tackle this challenge, some research efforts have been dedicated to the development of language-embedded implicit fields. However, implicit fields (e.g. NeRF) encounter limitations due to the necessity of processing a large number of input views for reconstruction, coupled with their inherent inefficiencies in inference. Thus, we present the GaussianGrasper, which utilizes 3D Gaussian Splatting to explicitly represent the scene as a collection of Gaussian primitives. Our approach takes a limited set of RGB-D views and employs a tile-based splatting technique to create a feature field. In particular, we propose an Efficient Feature Distillation (EFD) module that employs contrastive learning to efficiently and accurately distill language embeddings derived from foundational models. With the reconstructed geometry of the Gaussian field, our method enables the pre-trained grasping model to generate collision-free grasp pose candidates. Furthermore, we propose a normal-guided grasp module to select the best grasp pose. Through comprehensive real-world experiments, we demonstrate that GaussianGrasper enables robots to accurately query and grasp objects with language instructions, providing a new solution for language-guided manipulation tasks. Data and codes can be available at https://github.com/MrSecant/GaussianGrasper.
UN-SAM: Universal Prompt-Free Segmentation for Generalized Nuclei Images
Feb 26, 2024In digital pathology, precise nuclei segmentation is pivotal yet challenged by the diversity of tissue types, staining protocols, and imaging conditions. Recently, the segment anything model (SAM) revealed overwhelming performance in natural scenarios and impressive adaptation to medical imaging. Despite these advantages, the reliance of labor-intensive manual annotation as segmentation prompts severely hinders their clinical applicability, especially for nuclei image analysis containing massive cells where dense manual prompts are impractical. To overcome the limitations of current SAM methods while retaining the advantages, we propose the Universal prompt-free SAM framework for Nuclei segmentation (UN-SAM), by providing a fully automated solution with remarkable generalization capabilities. Specifically, to eliminate the labor-intensive requirement of per-nuclei annotations for prompt, we devise a multi-scale Self-Prompt Generation (SPGen) module to revolutionize clinical workflow by automatically generating high-quality mask hints to guide the segmentation tasks. Moreover, to unleash the generalization capability of SAM across a variety of nuclei images, we devise a Domain-adaptive Tuning Encoder (DT-Encoder) to seamlessly harmonize visual features with domain-common and domain-specific knowledge, and further devise a Domain Query-enhanced Decoder (DQ-Decoder) by leveraging learnable domain queries for segmentation decoding in different nuclei domains. Extensive experiments prove that UN-SAM with exceptional performance surpasses state-of-the-arts in nuclei instance and semantic segmentation, especially the generalization capability in zero-shot scenarios. The source code is available at https://github.com/CUHK-AIM-Group/UN-SAM.
Exploiting Duality in Open Information Extraction with Predicate Prompt
Jan 20, 2024Open information extraction (OpenIE) aims to extract the schema-free triplets in the form of (\emph{subject}, \emph{predicate}, \emph{object}) from a given sentence. Compared with general information extraction (IE), OpenIE poses more challenges for the IE models, {especially when multiple complicated triplets exist in a sentence. To extract these complicated triplets more effectively, in this paper we propose a novel generative OpenIE model, namely \emph{DualOIE}, which achieves a dual task at the same time as extracting some triplets from the sentence, i.e., converting the triplets into the sentence.} Such dual task encourages the model to correctly recognize the structure of the given sentence and thus is helpful to extract all potential triplets from the sentence. Specifically, DualOIE extracts the triplets in two steps: 1) first extracting a sequence of all potential predicates, 2) then using the predicate sequence as a prompt to induce the generation of triplets. Our experiments on two benchmarks and our dataset constructed from Meituan demonstrate that DualOIE achieves the best performance among the state-of-the-art baselines. Furthermore, the online A/B test on Meituan platform shows that 0.93\% improvement of QV-CTR and 0.56\% improvement of UV-CTR have been obtained when the triplets extracted by DualOIE were leveraged in Meituan's search system.
Energy Efficiency Optimization in Active Reconfigurable Intelligent Surface-Aided Integrated Sensing and Communication Systems
Nov 28, 2023Energy efficiency (EE) is a challenging task in integrated sensing and communication (ISAC) systems, where high spectral efficiency and low energy consumption appear as conflicting requirements. Although passive reconfigurable intelligent surface (RIS) has emerged as a promising technology for enhancing the EE of the ISAC system, the multiplicative fading feature hinders its effectiveness. This paper proposes the use of active RIS with its amplification gains to assist the ISAC system for EE improvement. Specifically, we formulate an EE optimization problem in an active RIS-aided ISAC system under system power budgets, considering constraints on user communication quality of service and sensing signal-to-noise ratio (SNR). A novel alternating optimization algorithm is developed to address the highly non-convex problem by leveraging a combination of the generalized Rayleigh quotient optimization approach, semidefinite relaxation (SDR), and the majorization-minimization (MM) framework. Furthermore, to accelerate the algorithm and reduce computational complexity, we derive a semi-closed form for eigenvalue determination. Numerical results demonstrate the effectiveness of the proposed approach, showcasing significant improvements in EE compared to both passive RIS and spectrum efficiency optimization cases.