 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQing Xu
Improve Knowledge Distillation via Label Revision and Data Selection
Apr 03, 2024
Knowledge distillation (KD) has become a widely used technique in the field of model compression, which aims to transfer knowledge from a large teacher model to a lightweight student model for efficient network development. In addition to the supervision of ground truth, the vanilla KD method regards the predictions of the teacher as soft labels to supervise the training of the student model. Based on vanilla KD, various approaches have been developed to further improve the performance of the student model. However, few of these previous methods have considered the reliability of the supervision from teacher models. Supervision from erroneous predictions may mislead the training of the student model. This paper therefore proposes to tackle this problem from two aspects: Label Revision to rectify the incorrect supervision and Data Selection to select appropriate samples for distillation to reduce the impact of erroneous supervision. In the former, we propose to rectify the teacher's inaccurate predictions using the ground truth. In the latter, we introduce a data selection technique to choose suitable training samples to be supervised by the teacher, thereby reducing the impact of incorrect predictions to some extent. Experiment results demonstrate the effectiveness of our proposed method, and show that our method can be combined with other distillation approaches, improving their performance.
UN-SAM: Universal Prompt-Free Segmentation for Generalized Nuclei Images
Feb 26, 2024In digital pathology, precise nuclei segmentation is pivotal yet challenged by the diversity of tissue types, staining protocols, and imaging conditions. Recently, the segment anything model (SAM) revealed overwhelming performance in natural scenarios and impressive adaptation to medical imaging. Despite these advantages, the reliance of labor-intensive manual annotation as segmentation prompts severely hinders their clinical applicability, especially for nuclei image analysis containing massive cells where dense manual prompts are impractical. To overcome the limitations of current SAM methods while retaining the advantages, we propose the Universal prompt-free SAM framework for Nuclei segmentation (UN-SAM), by providing a fully automated solution with remarkable generalization capabilities. Specifically, to eliminate the labor-intensive requirement of per-nuclei annotations for prompt, we devise a multi-scale Self-Prompt Generation (SPGen) module to revolutionize clinical workflow by automatically generating high-quality mask hints to guide the segmentation tasks. Moreover, to unleash the generalization capability of SAM across a variety of nuclei images, we devise a Domain-adaptive Tuning Encoder (DT-Encoder) to seamlessly harmonize visual features with domain-common and domain-specific knowledge, and further devise a Domain Query-enhanced Decoder (DQ-Decoder) by leveraging learnable domain queries for segmentation decoding in different nuclei domains. Extensive experiments prove that UN-SAM with exceptional performance surpasses state-of-the-arts in nuclei instance and semantic segmentation, especially the generalization capability in zero-shot scenarios. The source code is available at https://github.com/CUHK-AIM-Group/UN-SAM.
VADv2: End-to-End Vectorized Autonomous Driving via Probabilistic Planning
Feb 20, 2024Learning a human-like driving policy from large-scale driving demonstrations is promising, but the uncertainty and non-deterministic nature of planning make it challenging. In this work, to cope with the uncertainty problem, we propose VADv2, an end-to-end driving model based on probabilistic planning. VADv2 takes multi-view image sequences as input in a streaming manner, transforms sensor data into environmental token embeddings, outputs the probabilistic distribution of action, and samples one action to control the vehicle. Only with camera sensors, VADv2 achieves state-of-the-art closed-loop performance on the CARLA Town05 benchmark, significantly outperforming all existing methods. It runs stably in a fully end-to-end manner, even without the rule-based wrapper. Closed-loop demos are presented at https://hgao-cv.github.io/VADv2.
SPPNet: A Single-Point Prompt Network for Nuclei Image Segmentation
Aug 23, 2023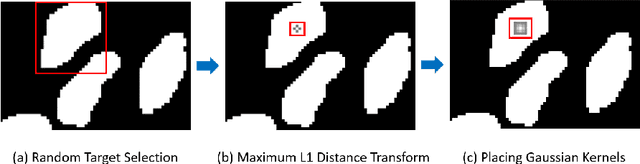
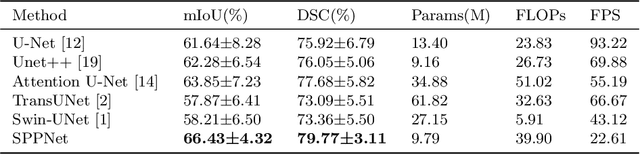
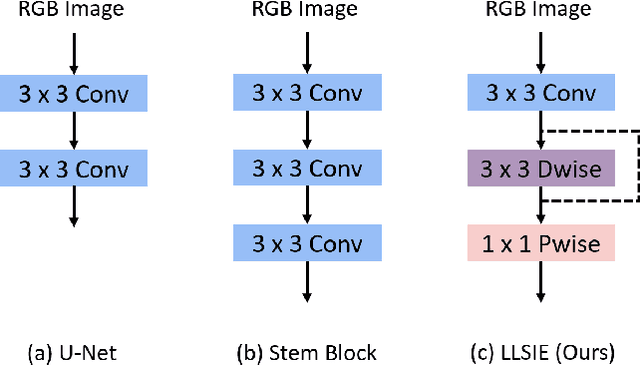
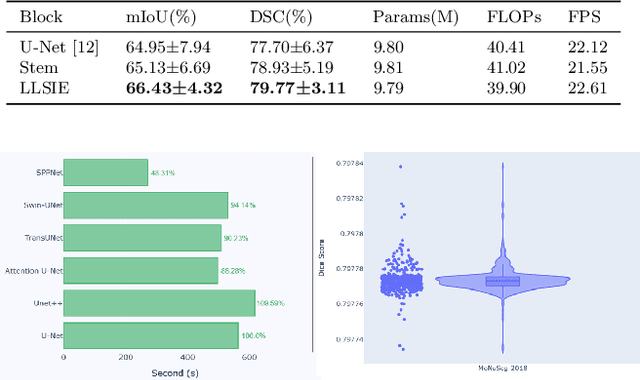
Image segmentation plays an essential role in nuclei image analysis. Recently, the segment anything model has made a significant breakthrough in such tasks. However, the current model exists two major issues for cell segmentation: (1) the image encoder of the segment anything model involves a large number of parameters. Retraining or even fine-tuning the model still requires expensive computational resources. (2) in point prompt mode, points are sampled from the center of the ground truth and more than one set of points is expected to achieve reliable performance, which is not efficient for practical applications. In this paper, a single-point prompt network is proposed for nuclei image segmentation, called SPPNet. We replace the original image encoder with a lightweight vision transformer. Also, an effective convolutional block is added in parallel to extract the low-level semantic information from the image and compensate for the performance degradation due to the small image encoder. We propose a new point-sampling method based on the Gaussian kernel. The proposed model is evaluated on the MoNuSeg-2018 dataset. The result demonstrated that SPPNet outperforms existing U-shape architectures and shows faster convergence in training. Compared to the segment anything model, SPPNet shows roughly 20 times faster inference, with 1/70 parameters and computational cost. Particularly, only one set of points is required in both the training and inference phases, which is more reasonable for clinical applications. The code for our work and more technical details can be found at https://github.com/xq141839/SPPNet.
Distilling Universal and Joint Knowledge for Cross-Domain Model Compression on Time Series Data
Jul 07, 2023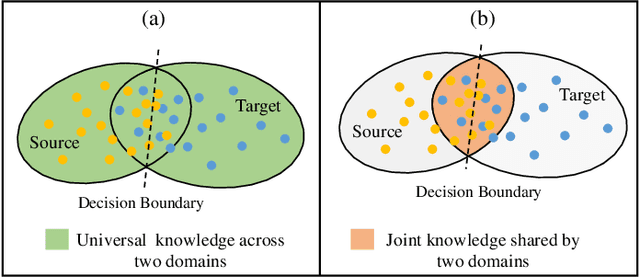
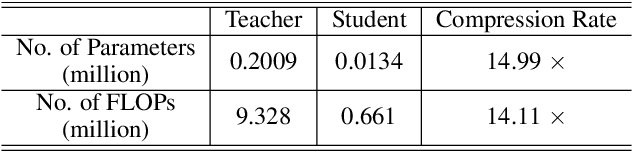
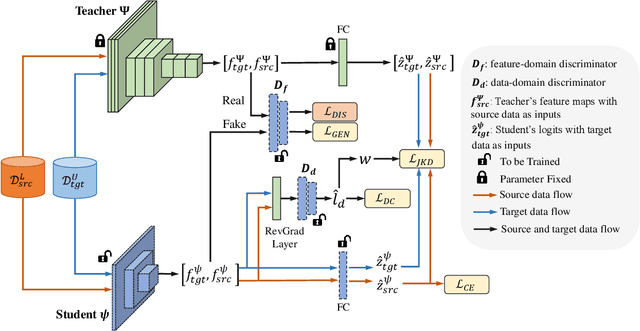
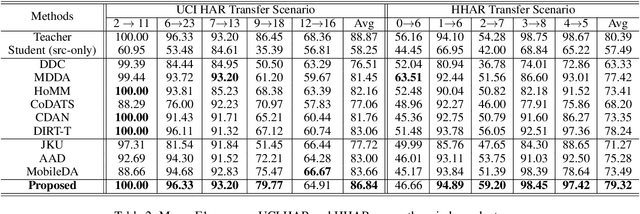
For many real-world time series tasks, the computational complexity of prevalent deep leaning models often hinders the deployment on resource-limited environments (e.g., smartphones). Moreover, due to the inevitable domain shift between model training (source) and deploying (target) stages, compressing those deep models under cross-domain scenarios becomes more challenging. Although some of existing works have already explored cross-domain knowledge distillation for model compression, they are either biased to source data or heavily tangled between source and target data. To this end, we design a novel end-to-end framework called Universal and joint knowledge distillation (UNI-KD) for cross-domain model compression. In particular, we propose to transfer both the universal feature-level knowledge across source and target domains and the joint logit-level knowledge shared by both domains from the teacher to the student model via an adversarial learning scheme. More specifically, a feature-domain discriminator is employed to align teacher's and student's representations for universal knowledge transfer. A data-domain discriminator is utilized to prioritize the domain-shared samples for joint knowledge transfer. Extensive experimental results on four time series datasets demonstrate the superiority of our proposed method over state-of-the-art (SOTA) benchmarks.
DualAttNet: Synergistic Fusion of Image-level and Fine-Grained Disease Attention for Multi-Label Lesion Detection in Chest X-rays
Jun 23, 2023Chest radiographs are the most commonly performed radiological examinations for lesion detection. Recent advances in deep learning have led to encouraging results in various thoracic disease detection tasks. Particularly, the architecture with feature pyramid network performs the ability to recognise targets with different sizes. However, such networks are difficult to focus on lesion regions in chest X-rays due to their high resemblance in vision. In this paper, we propose a dual attention supervised module for multi-label lesion detection in chest radiographs, named DualAttNet. It efficiently fuses global and local lesion classification information based on an image-level attention block and a fine-grained disease attention algorithm. A binary cross entropy loss function is used to calculate the difference between the attention map and ground truth at image level. The generated gradient flow is leveraged to refine pyramid representations and highlight lesion-related features. We evaluate the proposed model on VinDr-CXR, ChestX-ray8 and COVID-19 datasets. The experimental results show that DualAttNet surpasses baselines by 0.6% to 2.7% mAP and 1.4% to 4.7% AP50 with different detection architectures. The code for our work and more technical details can be found at https://github.com/xq141839/DualAttNet.
Sea Ice Extraction via Remote Sensed Imagery: Algorithms, Datasets, Applications and Challenges
Jun 01, 2023
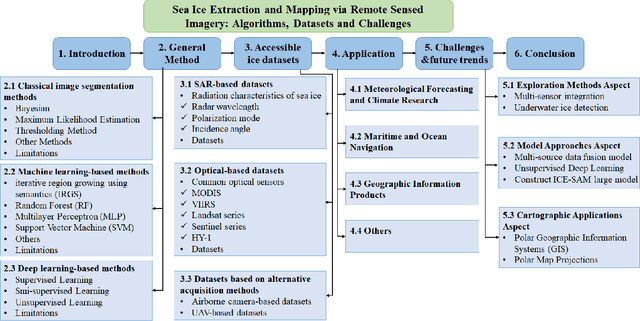
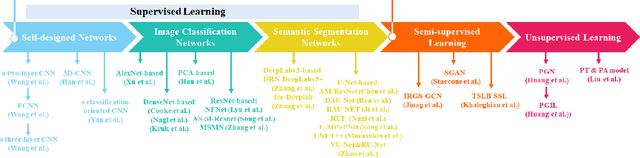
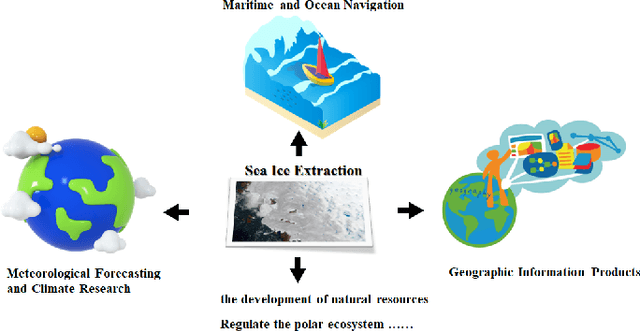
The deep learning, which is a dominating technique in artificial intelligence, has completely changed the image understanding over the past decade. As a consequence, the sea ice extraction (SIE) problem has reached a new era. We present a comprehensive review of four important aspects of SIE, including algorithms, datasets, applications, and the future trends. Our review focuses on researches published from 2016 to the present, with a specific focus on deep learning-based approaches in the last five years. We divided all relegated algorithms into 3 categories, including classical image segmentation approach, machine learning-based approach and deep learning-based methods. We reviewed the accessible ice datasets including SAR-based datasets, the optical-based datasets and others. The applications are presented in 4 aspects including climate research, navigation, geographic information systems (GIS) production and others. It also provides insightful observations and inspiring future research directions.
Semi-supervised Road Updating Network (SRUNet): A Deep Learning Method for Road Updating from Remote Sensing Imagery and Historical Vector Maps
Apr 28, 2023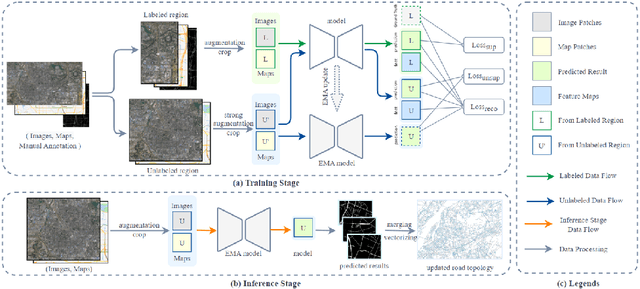
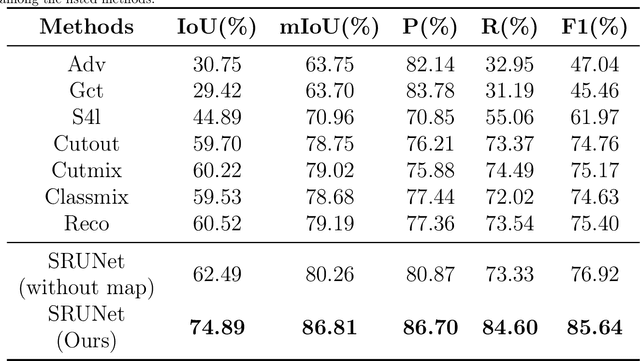
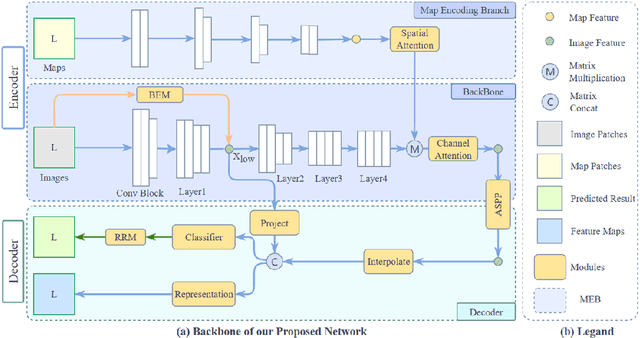
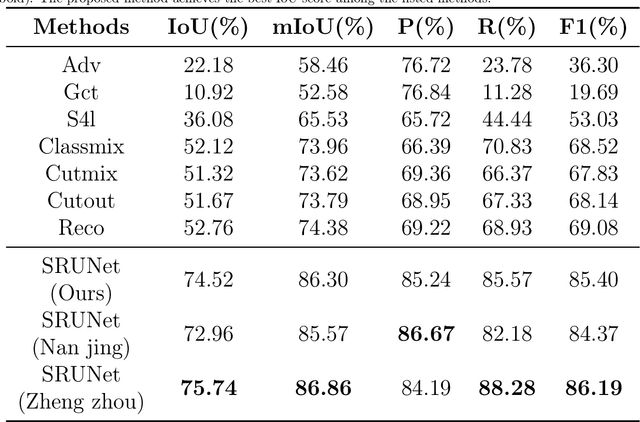
A road is the skeleton of a city and is a fundamental and important geographical component. Currently, many countries have built geo-information databases and gathered large amounts of geographic data. However, with the extensive construction of infrastructure and rapid expansion of cities, automatic updating of road data is imperative to maintain the high quality of current basic geographic information. However, obtaining bi-phase images for the same area is difficult, and complex post-processing methods are required to update the existing databases.To solve these problems, we proposed a road detection method based on semi-supervised learning (SRUNet) specifically for road-updating applications; in this approach, historical road information was fused with the latest images to directly obtain the latest state of the road.Considering that the texture of a road is complex, a multi-branch network, named the Map Encoding Branch (MEB) was proposed for representation learning, where the Boundary Enhancement Module (BEM) was used to improve the accuracy of boundary prediction, and the Residual Refinement Module (RRM) was used to optimize the prediction results. Further, to fully utilize the limited amount of label information and to enhance the prediction accuracy on unlabeled images, we utilized the mean teacher framework as the basic semi-supervised learning framework and introduced Regional Contrast (ReCo) in our work to improve the model capacity for distinguishing between the characteristics of roads and background elements.We applied our method to two datasets. Our model can effectively improve the performance of a model with fewer labels. Overall, the proposed SRUNet can provide stable, up-to-date, and reliable prediction results for a wide range of road renewal tasks.
VAD: Vectorized Scene Representation for Efficient Autonomous Driving
Mar 21, 2023
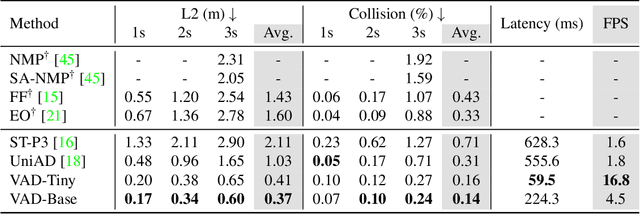
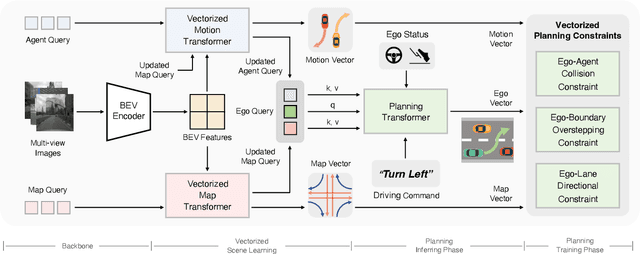
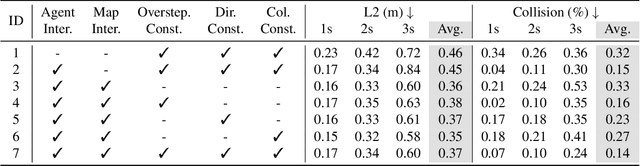
Autonomous driving requires a comprehensive understanding of the surrounding environment for reliable trajectory planning. Previous works rely on dense rasterized scene representation (e.g., agent occupancy and semantic map) to perform planning, which is computationally intensive and misses the instance-level structure information. In this paper, we propose VAD, an end-to-end vectorized paradigm for autonomous driving, which models the driving scene as fully vectorized representation. The proposed vectorized paradigm has two significant advantages. On one hand, VAD exploits the vectorized agent motion and map elements as explicit instance-level planning constraints which effectively improves planning safety. On the other hand, VAD runs much faster than previous end-to-end planning methods by getting rid of computation-intensive rasterized representation and hand-designed post-processing steps. VAD achieves state-of-the-art end-to-end planning performance on the nuScenes dataset, outperforming the previous best method by a large margin (reducing the average collision rate by 48.4%). Besides, VAD greatly improves the inference speed (up to 9.3x), which is critical for the real-world deployment of an autonomous driving system. Code and models will be released for facilitating future research.
Mixed Cloud Control Testbed: Validating Vehicle-Road-Cloud Integration via Mixed Digital Twin
Dec 05, 2022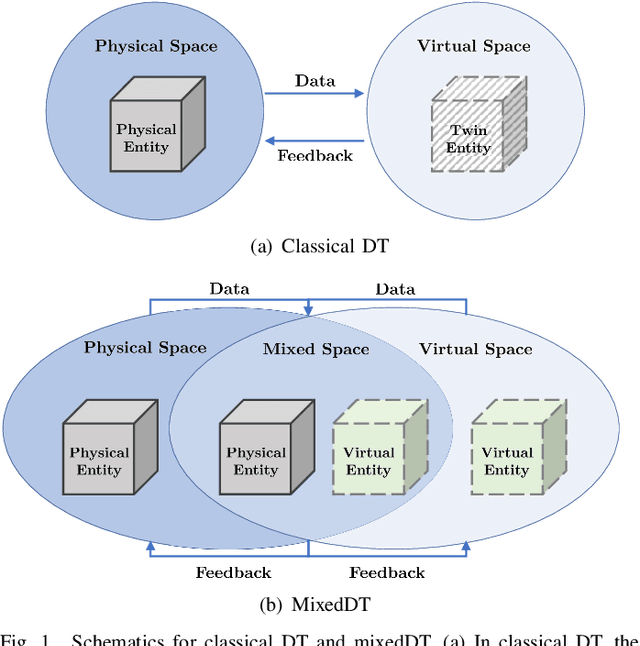

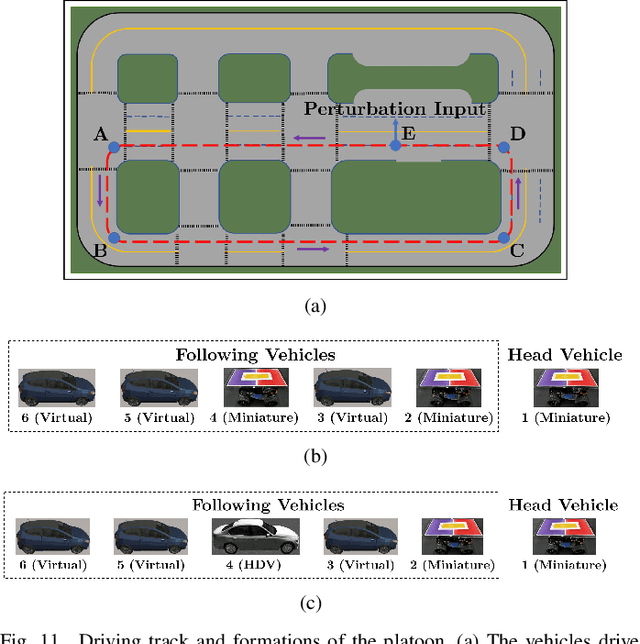
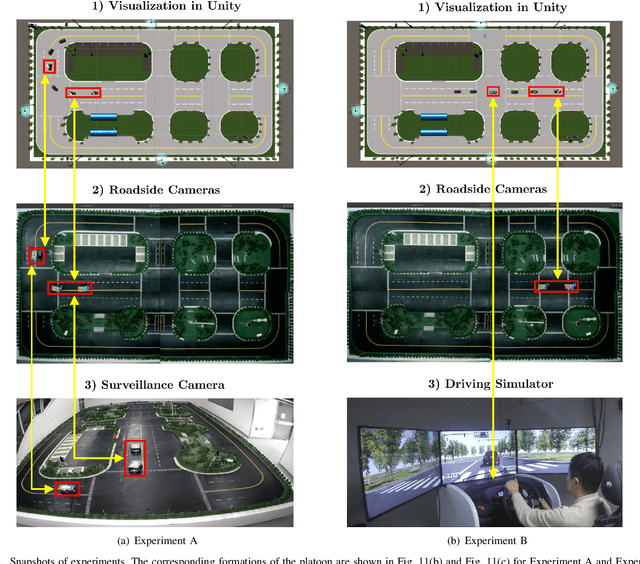
Reliable and efficient validation technologies are critical for the recent development of multi-vehicle cooperation and vehicle-road-cloud integration. In this paper, we introduce our miniature experimental platform, Mixed Cloud Control Testbed (MCCT), developed based on a new notion of Mixed Digital Twin (mixedDT). Combining Mixed Reality with Digital Twin, mixedDT integrates the virtual and physical spaces into a mixed one, where physical entities coexist and interact with virtual entities via their digital counterparts. Under the framework of mixedDT, MCCT contains three major experimental platforms in the physical, virtual and mixed spaces respectively, and provides a unified access for various human-machine interfaces and external devices such as driving simulators. A cloud unit, where the mixed experimental platform is deployed, is responsible for fusing multi-platform information and assigning control instructions, contributing to synchronous operation and real-time cross-platform interaction. Particularly, MCCT allows for multi-vehicle coordination composed of different multi-source vehicles (\eg, physical vehicles, virtual vehicles and human-driven vehicles). Validations on vehicle platooning demonstrate the flexibility and scalability of MCCT.