 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhenghua Chen
TSLANet: Rethinking Transformers for Time Series Representation Learning
Apr 12, 2024
Time series data, characterized by its intrinsic long and short-range dependencies, poses a unique challenge across analytical applications. While Transformer-based models excel at capturing long-range dependencies, they face limitations in noise sensitivity, computational efficiency, and overfitting with smaller datasets. In response, we introduce a novel Time Series Lightweight Adaptive Network (TSLANet), as a universal convolutional model for diverse time series tasks. Specifically, we propose an Adaptive Spectral Block, harnessing Fourier analysis to enhance feature representation and to capture both long-term and short-term interactions while mitigating noise via adaptive thresholding. Additionally, we introduce an Interactive Convolution Block and leverage self-supervised learning to refine the capacity of TSLANet for decoding complex temporal patterns and improve its robustness on different datasets. Our comprehensive experiments demonstrate that TSLANet outperforms state-of-the-art models in various tasks spanning classification, forecasting, and anomaly detection, showcasing its resilience and adaptability across a spectrum of noise levels and data sizes. The code is available at \url{https://github.com/emadeldeen24/TSLANet}
Improve Knowledge Distillation via Label Revision and Data Selection
Apr 03, 2024Knowledge distillation (KD) has become a widely used technique in the field of model compression, which aims to transfer knowledge from a large teacher model to a lightweight student model for efficient network development. In addition to the supervision of ground truth, the vanilla KD method regards the predictions of the teacher as soft labels to supervise the training of the student model. Based on vanilla KD, various approaches have been developed to further improve the performance of the student model. However, few of these previous methods have considered the reliability of the supervision from teacher models. Supervision from erroneous predictions may mislead the training of the student model. This paper therefore proposes to tackle this problem from two aspects: Label Revision to rectify the incorrect supervision and Data Selection to select appropriate samples for distillation to reduce the impact of erroneous supervision. In the former, we propose to rectify the teacher's inaccurate predictions using the ground truth. In the latter, we introduce a data selection technique to choose suitable training samples to be supervised by the teacher, thereby reducing the impact of incorrect predictions to some extent. Experiment results demonstrate the effectiveness of our proposed method, and show that our method can be combined with other distillation approaches, improving their performance.
K-Link: Knowledge-Link Graph from LLMs for Enhanced Representation Learning in Multivariate Time-Series Data
Mar 06, 2024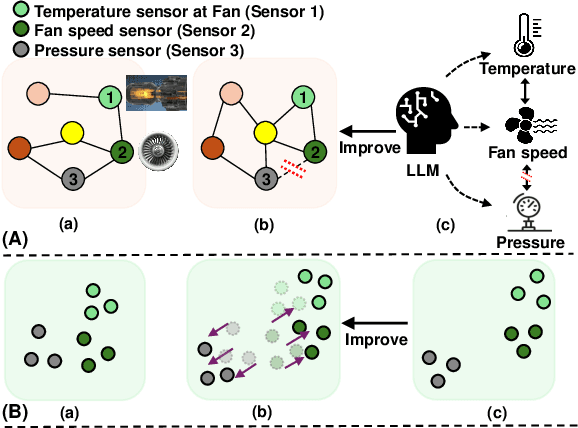
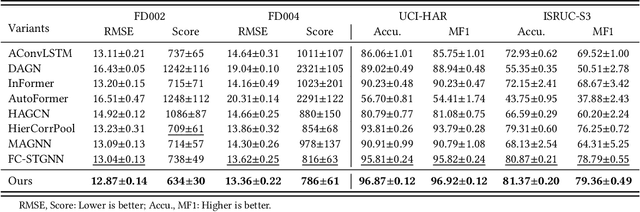
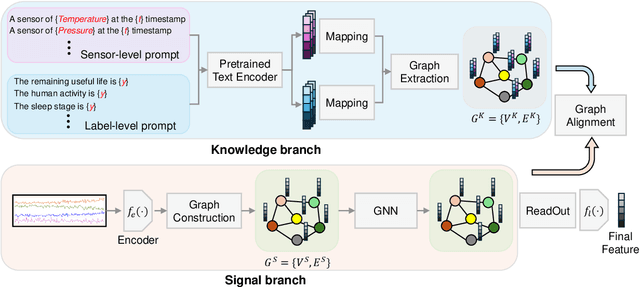
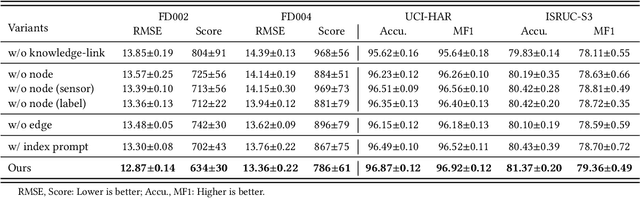
Sourced from various sensors and organized chronologically, Multivariate Time-Series (MTS) data involves crucial spatial-temporal dependencies, e.g., correlations among sensors. To capture these dependencies, Graph Neural Networks (GNNs) have emerged as powerful tools, yet their effectiveness is restricted by the quality of graph construction from MTS data. Typically, existing approaches construct graphs solely from MTS signals, which may introduce bias due to a small training dataset and may not accurately represent underlying dependencies. To address this challenge, we propose a novel framework named K-Link, leveraging Large Language Models (LLMs) to encode extensive general knowledge and thereby providing effective solutions to reduce the bias. Leveraging the knowledge embedded in LLMs, such as physical principles, we extract a \textit{Knowledge-Link graph}, capturing vast semantic knowledge of sensors and the linkage of the sensor-level knowledge. To harness the potential of the knowledge-link graph in enhancing the graph derived from MTS data, we propose a graph alignment module, facilitating the transfer of semantic knowledge within the knowledge-link graph into the MTS-derived graph. By doing so, we can improve the graph quality, ensuring effective representation learning with GNNs for MTS data. Extensive experiments demonstrate the efficacy of our approach for superior performance across various MTS-related downstream tasks.
PowerSkel: A Device-Free Framework Using CSI Signal for Human Skeleton Estimation in Power Station
Mar 04, 2024
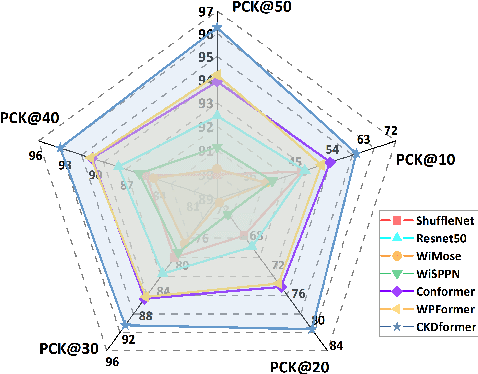
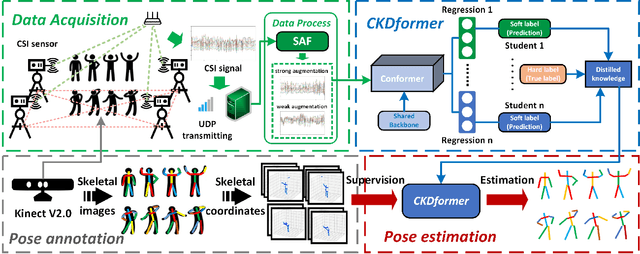
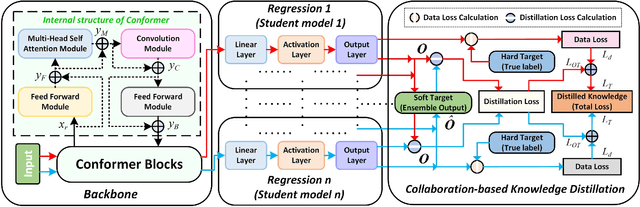
Safety monitoring of power operations in power stations is crucial for preventing accidents and ensuring stable power supply. However, conventional methods such as wearable devices and video surveillance have limitations such as high cost, dependence on light, and visual blind spots. WiFi-based human pose estimation is a suitable method for monitoring power operations due to its low cost, device-free, and robustness to various illumination conditions.In this paper, a novel Channel State Information (CSI)-based pose estimation framework, namely PowerSkel, is developed to address these challenges. PowerSkel utilizes self-developed CSI sensors to form a mutual sensing network and constructs a CSI acquisition scheme specialized for power scenarios. It significantly reduces the deployment cost and complexity compared to the existing solutions. To reduce interference with CSI in the electricity scenario, a sparse adaptive filtering algorithm is designed to preprocess the CSI. CKDformer, a knowledge distillation network based on collaborative learning and self-attention, is proposed to extract the features from CSI and establish the mapping relationship between CSI and keypoints. The experiments are conducted in a real-world power station, and the results show that the PowerSkel achieves high performance with a PCK@50 of 96.27%, and realizes a significant visualization on pose estimation, even in dark environments. Our work provides a novel low-cost and high-precision pose estimation solution for power operation.
SEA++: Multi-Graph-based High-Order Sensor Alignment for Multivariate Time-Series Unsupervised Domain Adaptation
Nov 17, 2023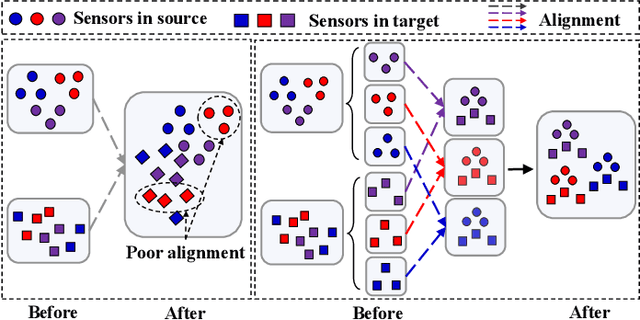
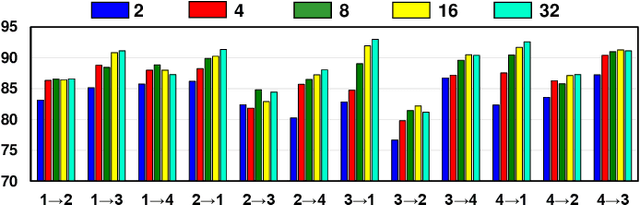
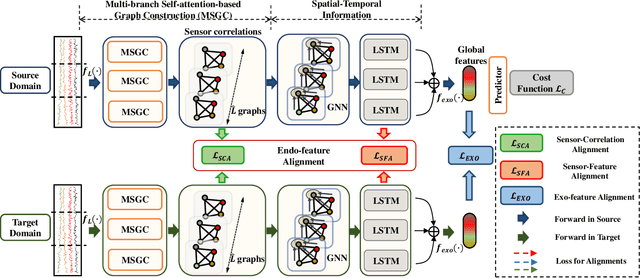
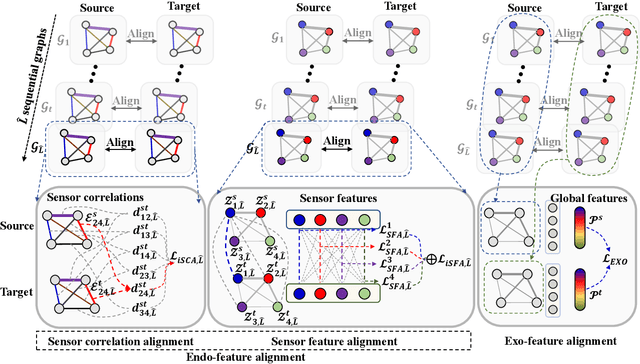
Unsupervised Domain Adaptation (UDA) methods have been successful in reducing label dependency by minimizing the domain discrepancy between a labeled source domain and an unlabeled target domain. However, these methods face challenges when dealing with Multivariate Time-Series (MTS) data. MTS data typically consist of multiple sensors, each with its own unique distribution. This characteristic makes it hard to adapt existing UDA methods, which mainly focus on aligning global features while overlooking the distribution discrepancies at the sensor level, to reduce domain discrepancies for MTS data. To address this issue, a practical domain adaptation scenario is formulated as Multivariate Time-Series Unsupervised Domain Adaptation (MTS-UDA). In this paper, we propose SEnsor Alignment (SEA) for MTS-UDA, aiming to reduce domain discrepancy at both the local and global sensor levels. At the local sensor level, we design endo-feature alignment, which aligns sensor features and their correlations across domains. To reduce domain discrepancy at the global sensor level, we design exo-feature alignment that enforces restrictions on global sensor features. We further extend SEA to SEA++ by enhancing the endo-feature alignment. Particularly, we incorporate multi-graph-based high-order alignment for both sensor features and their correlations. Extensive empirical results have demonstrated the state-of-the-art performance of our SEA and SEA++ on public MTS datasets for MTS-UDA.
Graph Convolutional Network with Connectivity Uncertainty for EEG-based Emotion Recognition
Oct 22, 2023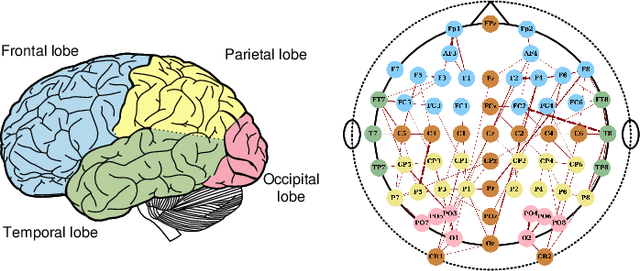
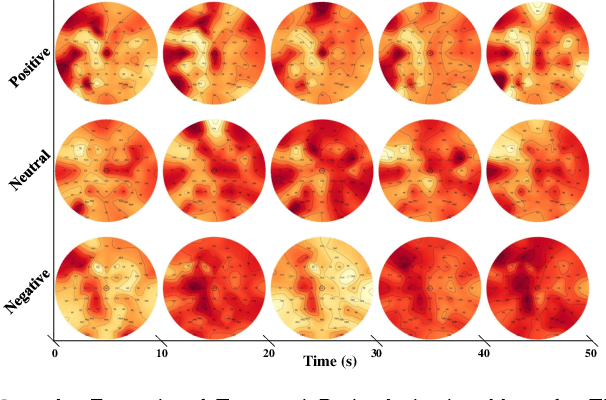
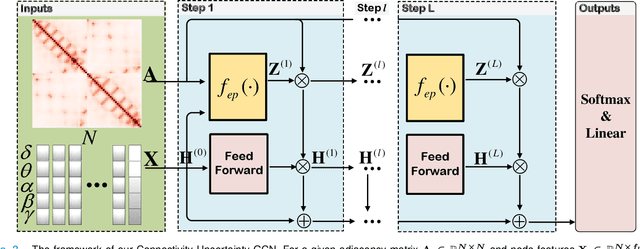
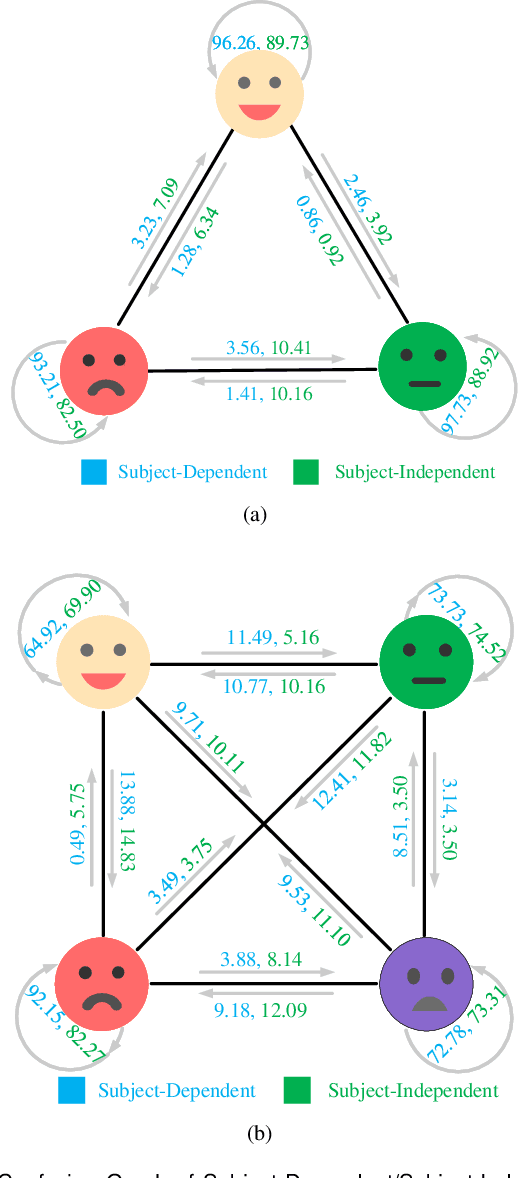
Automatic emotion recognition based on multichannel Electroencephalography (EEG) holds great potential in advancing human-computer interaction. However, several significant challenges persist in existing research on algorithmic emotion recognition. These challenges include the need for a robust model to effectively learn discriminative node attributes over long paths, the exploration of ambiguous topological information in EEG channels and effective frequency bands, and the mapping between intrinsic data qualities and provided labels. To address these challenges, this study introduces the distribution-based uncertainty method to represent spatial dependencies and temporal-spectral relativeness in EEG signals based on Graph Convolutional Network (GCN) architecture that adaptively assigns weights to functional aggregate node features, enabling effective long-path capturing while mitigating over-smoothing phenomena. Moreover, the graph mixup technique is employed to enhance latent connected edges and mitigate noisy label issues. Furthermore, we integrate the uncertainty learning method with deep GCN weights in a one-way learning fashion, termed Connectivity Uncertainty GCN (CU-GCN). We evaluate our approach on two widely used datasets, namely SEED and SEEDIV, for emotion recognition tasks. The experimental results demonstrate the superiority of our methodology over previous methods, yielding positive and significant improvements. Ablation studies confirm the substantial contributions of each component to the overall performance.
Fully-Connected Spatial-Temporal Graph for Multivariate Time Series Data
Sep 11, 2023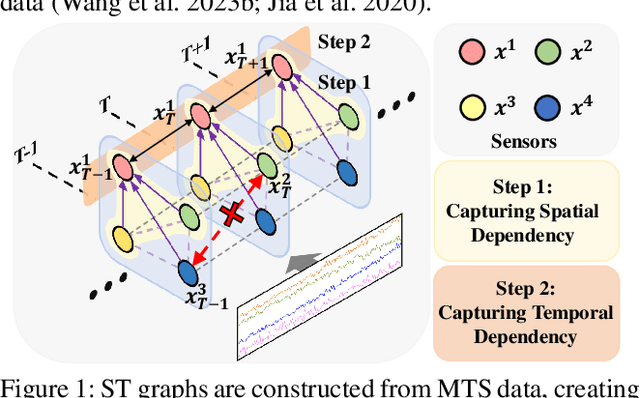
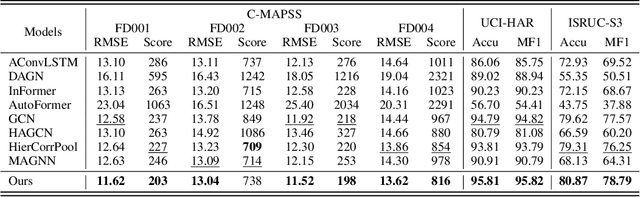
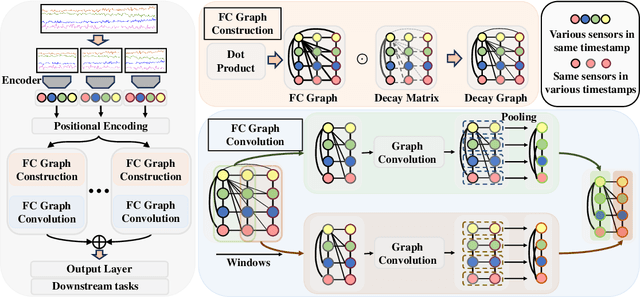
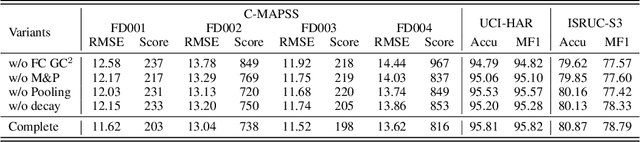
Multivariate Time-Series (MTS) data is crucial in various application fields. With its sequential and multi-source (multiple sensors) properties, MTS data inherently exhibits Spatial-Temporal (ST) dependencies, involving temporal correlations between timestamps and spatial correlations between sensors in each timestamp. To effectively leverage this information, Graph Neural Network-based methods (GNNs) have been widely adopted. However, existing approaches separately capture spatial dependency and temporal dependency and fail to capture the correlations between Different sEnsors at Different Timestamps (DEDT). Overlooking such correlations hinders the comprehensive modelling of ST dependencies within MTS data, thus restricting existing GNNs from learning effective representations. To address this limitation, we propose a novel method called Fully-Connected Spatial-Temporal Graph Neural Network (FC-STGNN), including two key components namely FC graph construction and FC graph convolution. For graph construction, we design a decay graph to connect sensors across all timestamps based on their temporal distances, enabling us to fully model the ST dependencies by considering the correlations between DEDT. Further, we devise FC graph convolution with a moving-pooling GNN layer to effectively capture the ST dependencies for learning effective representations. Extensive experiments show the effectiveness of FC-STGNN on multiple MTS datasets compared to SOTA methods.
Graph Contextual Contrasting for Multivariate Time Series Classification
Sep 11, 2023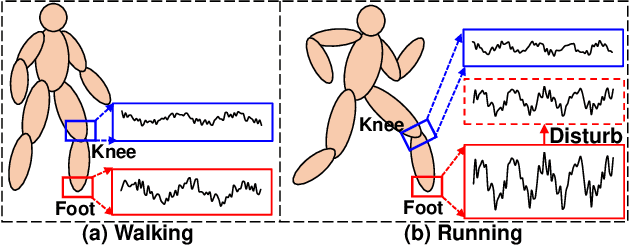

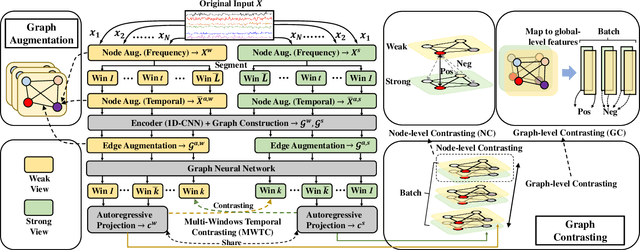
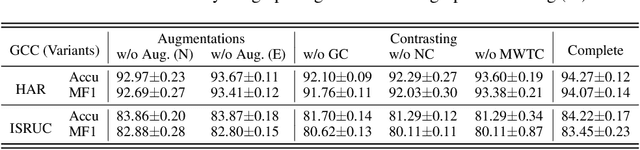
Contrastive learning, as a self-supervised learning paradigm, becomes popular for Multivariate Time-Series (MTS) classification. It ensures the consistency across different views of unlabeled samples and then learns effective representations for these samples. Existing contrastive learning methods mainly focus on achieving temporal consistency with temporal augmentation and contrasting techniques, aiming to preserve temporal patterns against perturbations for MTS data. However, they overlook spatial consistency that requires the stability of individual sensors and their correlations. As MTS data typically originate from multiple sensors, ensuring spatial consistency becomes essential for the overall performance of contrastive learning on MTS data. Thus, we propose Graph Contextual Contrasting (GCC) for spatial consistency across MTS data. Specifically, we propose graph augmentations including node and edge augmentations to preserve the stability of sensors and their correlations, followed by graph contrasting with both node- and graph-level contrasting to extract robust sensor- and global-level features. We further introduce multi-window temporal contrasting to ensure temporal consistency in the data for each sensor. Extensive experiments demonstrate that our proposed GCC achieves state-of-the-art performance on various MTS classification tasks.
Unlimited Knowledge Distillation for Action Recognition in the Dark
Aug 18, 2023

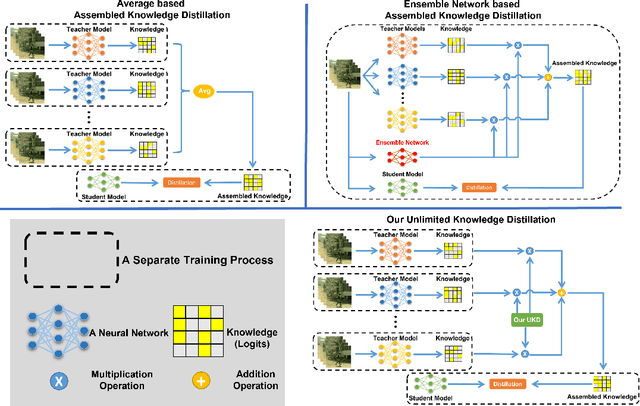

Dark videos often lose essential information, which causes the knowledge learned by networks is not enough to accurately recognize actions. Existing knowledge assembling methods require massive GPU memory to distill the knowledge from multiple teacher models into a student model. In action recognition, this drawback becomes serious due to much computation required by video process. Constrained by limited computation source, these approaches are infeasible. To address this issue, we propose an unlimited knowledge distillation (UKD) in this paper. Compared with existing knowledge assembling methods, our UKD can effectively assemble different knowledge without introducing high GPU memory consumption. Thus, the number of teaching models for distillation is unlimited. With our UKD, the network's learned knowledge can be remarkably enriched. Our experiments show that the single stream network distilled with our UKD even surpasses a two-stream network. Extensive experiments are conducted on the ARID dataset.
Shuffled Differentially Private Federated Learning for Time Series Data Analytics
Jul 30, 2023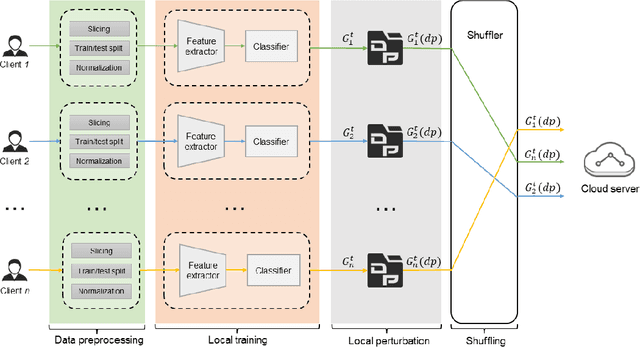
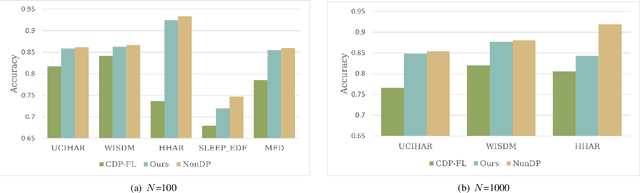
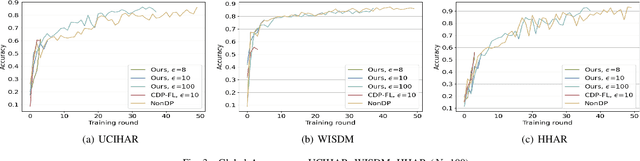
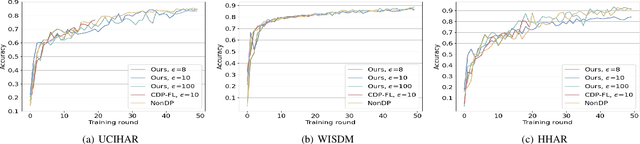
Trustworthy federated learning aims to achieve optimal performance while ensuring clients' privacy. Existing privacy-preserving federated learning approaches are mostly tailored for image data, lacking applications for time series data, which have many important applications, like machine health monitoring, human activity recognition, etc. Furthermore, protective noising on a time series data analytics model can significantly interfere with temporal-dependent learning, leading to a greater decline in accuracy. To address these issues, we develop a privacy-preserving federated learning algorithm for time series data. Specifically, we employ local differential privacy to extend the privacy protection trust boundary to the clients. We also incorporate shuffle techniques to achieve a privacy amplification, mitigating the accuracy decline caused by leveraging local differential privacy. Extensive experiments were conducted on five time series datasets. The evaluation results reveal that our algorithm experienced minimal accuracy loss compared to non-private federated learning in both small and large client scenarios. Under the same level of privacy protection, our algorithm demonstrated improved accuracy compared to the centralized differentially private federated learning in both scenarios.