 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJing Chen
Towards Independence Criterion in Machine Unlearning of Features and Labels
Mar 12, 2024
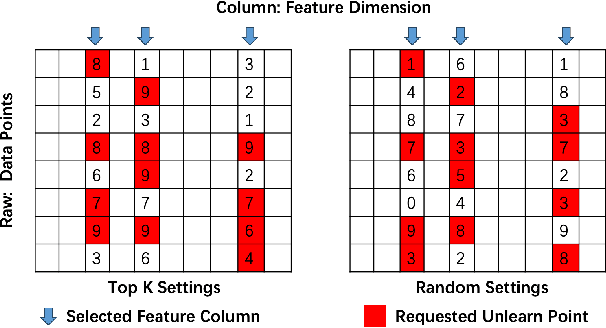
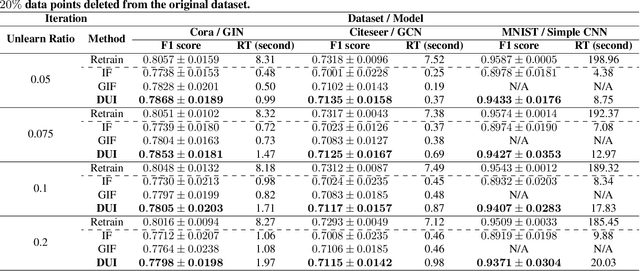
This work delves into the complexities of machine unlearning in the face of distributional shifts, particularly focusing on the challenges posed by non-uniform feature and label removal. With the advent of regulations like the GDPR emphasizing data privacy and the right to be forgotten, machine learning models face the daunting task of unlearning sensitive information without compromising their integrity or performance. Our research introduces a novel approach that leverages influence functions and principles of distributional independence to address these challenges. By proposing a comprehensive framework for machine unlearning, we aim to ensure privacy protection while maintaining model performance and adaptability across varying distributions. Our method not only facilitates efficient data removal but also dynamically adjusts the model to preserve its generalization capabilities. Through extensive experimentation, we demonstrate the efficacy of our approach in scenarios characterized by significant distributional shifts, making substantial contributions to the field of machine unlearning. This research paves the way for developing more resilient and adaptable unlearning techniques, ensuring models remain robust and accurate in the dynamic landscape of data privacy and machine learning.
Human Activity Recognition with Low-Resolution Infrared Array Sensor Using Semi-supervised Cross-domain Neural Networks for Indoor Environment
Mar 05, 2024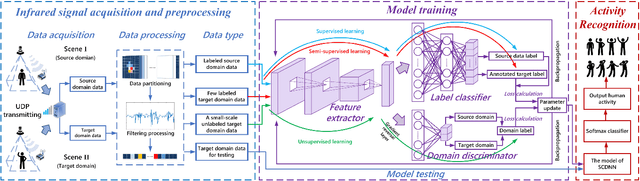
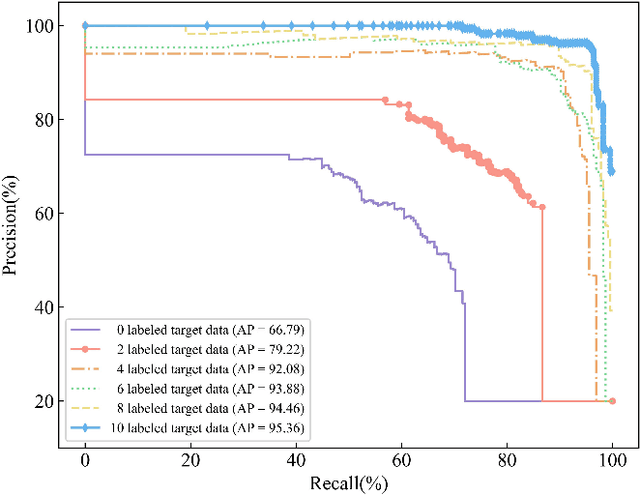
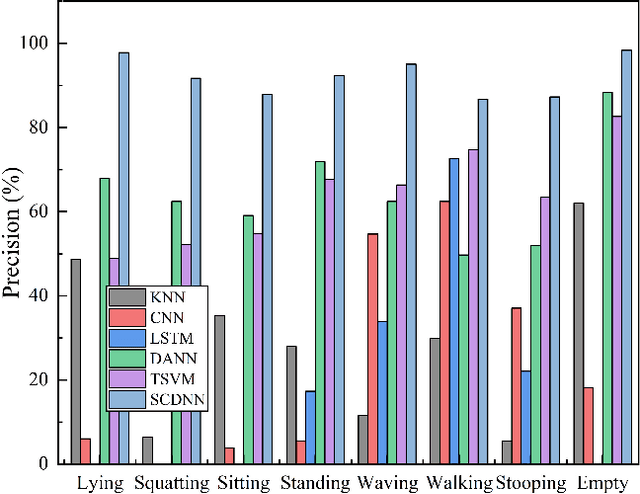
Low-resolution infrared-based human activity recognition (HAR) attracted enormous interests due to its low-cost and private. In this paper, a novel semi-supervised crossdomain neural network (SCDNN) based on 8 $\times$ 8 low-resolution infrared sensor is proposed for accurately identifying human activity despite changes in the environment at a low-cost. The SCDNN consists of feature extractor, domain discriminator and label classifier. In the feature extractor, the unlabeled and minimal labeled target domain data are trained for domain adaptation to achieve a mapping of the source domain and target domain data. The domain discriminator employs the unsupervised learning to migrate data from the source domain to the target domain. The label classifier obtained from training the source domain data improves the recognition of target domain activities due to the semi-supervised learning utilized in training the target domain data. Experimental results show that the proposed method achieves 92.12\% accuracy for recognition of activities in the target domain by migrating the source and target domains. The proposed approach adapts superior to cross-domain scenarios compared to the existing deep learning methods, and it provides a low-cost yet highly adaptable solution for cross-domain scenarios.
PowerSkel: A Device-Free Framework Using CSI Signal for Human Skeleton Estimation in Power Station
Mar 04, 2024
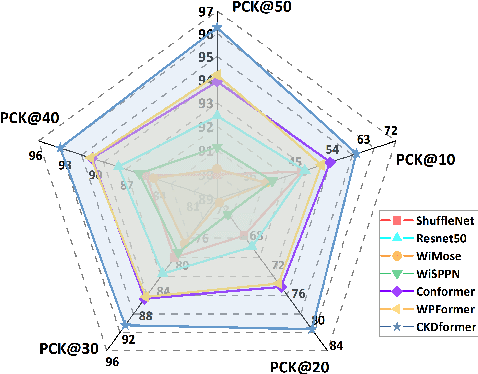
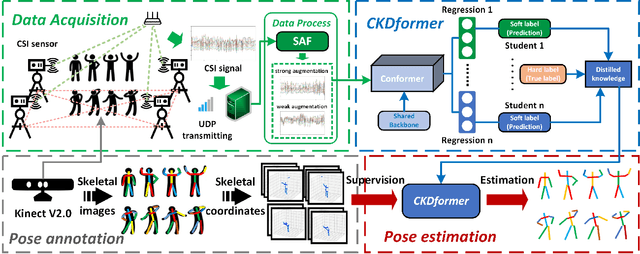
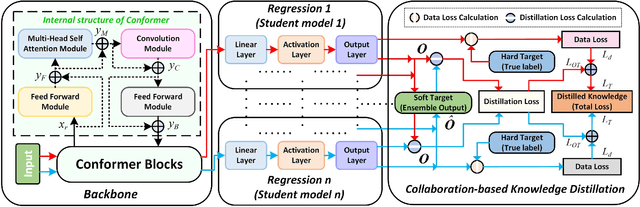
Safety monitoring of power operations in power stations is crucial for preventing accidents and ensuring stable power supply. However, conventional methods such as wearable devices and video surveillance have limitations such as high cost, dependence on light, and visual blind spots. WiFi-based human pose estimation is a suitable method for monitoring power operations due to its low cost, device-free, and robustness to various illumination conditions.In this paper, a novel Channel State Information (CSI)-based pose estimation framework, namely PowerSkel, is developed to address these challenges. PowerSkel utilizes self-developed CSI sensors to form a mutual sensing network and constructs a CSI acquisition scheme specialized for power scenarios. It significantly reduces the deployment cost and complexity compared to the existing solutions. To reduce interference with CSI in the electricity scenario, a sparse adaptive filtering algorithm is designed to preprocess the CSI. CKDformer, a knowledge distillation network based on collaborative learning and self-attention, is proposed to extract the features from CSI and establish the mapping relationship between CSI and keypoints. The experiments are conducted in a real-world power station, and the results show that the PowerSkel achieves high performance with a PCK@50 of 96.27%, and realizes a significant visualization on pose estimation, even in dark environments. Our work provides a novel low-cost and high-precision pose estimation solution for power operation.
Crafting a Good Prompt or Providing Exemplary Dialogues? A Study of In-Context Learning for Persona-based Dialogue Generation
Feb 17, 2024Previous in-context learning (ICL) research has focused on tasks such as classification, machine translation, text2table, etc., while studies on whether ICL can improve human-like dialogue generation are scarce. Our work fills this gap by systematically investigating the ICL capabilities of large language models (LLMs) in persona-based dialogue generation, conducting extensive experiments on high-quality real human Chinese dialogue datasets. From experimental results, we draw three conclusions: 1) adjusting prompt instructions is the most direct, effective, and economical way to improve generation quality; 2) randomly retrieving demonstrations (demos) achieves the best results, possibly due to the greater diversity and the amount of effective information; counter-intuitively, retrieving demos with a context identical to the query performs the worst; 3) even when we destroy the multi-turn associations and single-turn semantics in the demos, increasing the number of demos still improves dialogue performance, proving that LLMs can learn from corrupted dialogue demos. Previous explanations of the ICL mechanism, such as $n$-gram induction head, cannot fully account for this phenomenon.
Wavelet-Decoupling Contrastive Enhancement Network for Fine-Grained Skeleton-Based Action Recognition
Feb 03, 2024Skeleton-based action recognition has attracted much attention, benefiting from its succinctness and robustness. However, the minimal inter-class variation in similar action sequences often leads to confusion. The inherent spatiotemporal coupling characteristics make it challenging to mine the subtle differences in joint motion trajectories, which is critical for distinguishing confusing fine-grained actions. To alleviate this problem, we propose a Wavelet-Attention Decoupling (WAD) module that utilizes discrete wavelet transform to effectively disentangle salient and subtle motion features in the time-frequency domain. Then, the decoupling attention adaptively recalibrates their temporal responses. To further amplify the discrepancies in these subtle motion features, we propose a Fine-grained Contrastive Enhancement (FCE) module to enhance attention towards trajectory features by contrastive learning. Extensive experiments are conducted on the coarse-grained dataset NTU RGB+D and the fine-grained dataset FineGYM. Our methods perform competitively compared to state-of-the-art methods and can discriminate confusing fine-grained actions well.
Self-supervised speech representation and contextual text embedding for match-mismatch classification with EEG recording
Feb 01, 2024Relating speech to EEG holds considerable importance but is challenging. In this study, a deep convolutional network was employed to extract spatiotemporal features from EEG data. Self-supervised speech representation and contextual text embedding were used as speech features. Contrastive learning was used to relate EEG features to speech features. The experimental results demonstrate the benefits of using self-supervised speech representation and contextual text embedding. Through feature fusion and model ensemble, an accuracy of 60.29% was achieved, and the performance was ranked as No.2 in Task 1 of the Auditory EEG Challenge (ICASSP 2024). The code to implement our work is available on Github: https://github.com/bobwangPKU/EEG-Stimulus-Match-Mismatch.
ConvConcatNet: a deep convolutional neural network to reconstruct mel spectrogram from the EEG
Jan 10, 2024To investigate the processing of speech in the brain, simple linear models are commonly used to establish a relationship between brain signals and speech features. However, these linear models are ill-equipped to model a highly dynamic and complex non-linear system like the brain. Although non-linear methods with neural networks have been developed recently, reconstructing unseen stimuli from unseen subjects' EEG is still a highly challenging task. This work presents a novel method, ConvConcatNet, to reconstruct mel-specgrams from EEG, in which the deep convolution neural network and extensive concatenation operation were combined. With our ConvConcatNet model, the Pearson correlation between the reconstructed and the target mel-spectrogram can achieve 0.0420, which was ranked as No.1 in the Task 2 of the Auditory EEG Challenge. The codes and models to implement our work will be available on Github: https://github.com/xuxiran/ConvConcatNet
Generative Learning of Continuous Data by Tensor Networks
Oct 31, 2023Beyond their origin in modeling many-body quantum systems, tensor networks have emerged as a promising class of models for solving machine learning problems, notably in unsupervised generative learning. While possessing many desirable features arising from their quantum-inspired nature, tensor network generative models have previously been largely restricted to binary or categorical data, limiting their utility in real-world modeling problems. We overcome this by introducing a new family of tensor network generative models for continuous data, which are capable of learning from distributions containing continuous random variables. We develop our method in the setting of matrix product states, first deriving a universal expressivity theorem proving the ability of this model family to approximate any reasonably smooth probability density function with arbitrary precision. We then benchmark the performance of this model on several synthetic and real-world datasets, finding that the model learns and generalizes well on distributions of continuous and discrete variables. We develop methods for modeling different data domains, and introduce a trainable compression layer which is found to increase model performance given limited memory or computational resources. Overall, our methods give important theoretical and empirical evidence of the efficacy of quantum-inspired methods for the rapidly growing field of generative learning.