 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRongsheng Zhang
Let Storytelling Tell Vivid Stories: An Expressive and Fluent Multimodal Storyteller
Mar 12, 2024
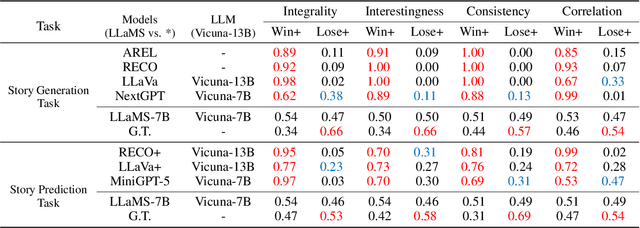
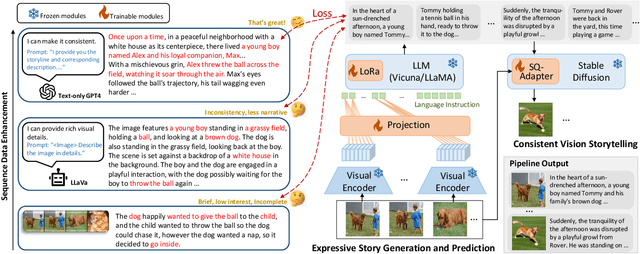
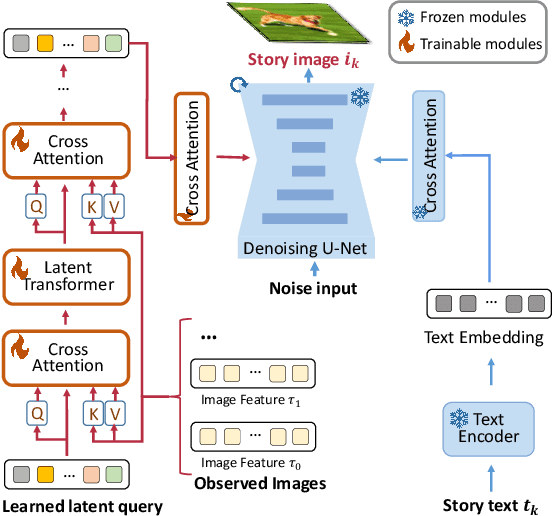
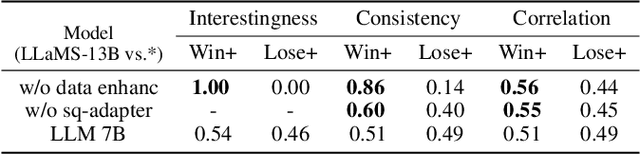
Storytelling aims to generate reasonable and vivid narratives based on an ordered image stream. The fidelity to the image story theme and the divergence of story plots attract readers to keep reading. Previous works iteratively improved the alignment of multiple modalities but ultimately resulted in the generation of simplistic storylines for image streams. In this work, we propose a new pipeline, termed LLaMS, to generate multimodal human-level stories that are embodied in expressiveness and consistency. Specifically, by fully exploiting the commonsense knowledge within the LLM, we first employ a sequence data auto-enhancement strategy to enhance factual content expression and leverage a textual reasoning architecture for expressive story generation and prediction. Secondly, we propose SQ-Adatpter module for story illustration generation which can maintain sequence consistency. Numerical results are conducted through human evaluation to verify the superiority of proposed LLaMS. Evaluations show that LLaMS achieves state-of-the-art storytelling performance and 86% correlation and 100% consistency win rate as compared with previous SOTA methods. Furthermore, ablation experiments are conducted to verify the effectiveness of proposed sequence data enhancement and SQ-Adapter.
Crafting a Good Prompt or Providing Exemplary Dialogues? A Study of In-Context Learning for Persona-based Dialogue Generation
Feb 17, 2024Previous in-context learning (ICL) research has focused on tasks such as classification, machine translation, text2table, etc., while studies on whether ICL can improve human-like dialogue generation are scarce. Our work fills this gap by systematically investigating the ICL capabilities of large language models (LLMs) in persona-based dialogue generation, conducting extensive experiments on high-quality real human Chinese dialogue datasets. From experimental results, we draw three conclusions: 1) adjusting prompt instructions is the most direct, effective, and economical way to improve generation quality; 2) randomly retrieving demonstrations (demos) achieves the best results, possibly due to the greater diversity and the amount of effective information; counter-intuitively, retrieving demos with a context identical to the query performs the worst; 3) even when we destroy the multi-turn associations and single-turn semantics in the demos, increasing the number of demos still improves dialogue performance, proving that LLMs can learn from corrupted dialogue demos. Previous explanations of the ICL mechanism, such as $n$-gram induction head, cannot fully account for this phenomenon.
Towards Efficient Diffusion-Based Image Editing with Instant Attention Masks
Jan 23, 2024Diffusion-based Image Editing (DIE) is an emerging research hot-spot, which often applies a semantic mask to control the target area for diffusion-based editing. However, most existing solutions obtain these masks via manual operations or off-line processing, greatly reducing their efficiency. In this paper, we propose a novel and efficient image editing method for Text-to-Image (T2I) diffusion models, termed Instant Diffusion Editing(InstDiffEdit). In particular, InstDiffEdit aims to employ the cross-modal attention ability of existing diffusion models to achieve instant mask guidance during the diffusion steps. To reduce the noise of attention maps and realize the full automatics, we equip InstDiffEdit with a training-free refinement scheme to adaptively aggregate the attention distributions for the automatic yet accurate mask generation. Meanwhile, to supplement the existing evaluations of DIE, we propose a new benchmark called Editing-Mask to examine the mask accuracy and local editing ability of existing methods. To validate InstDiffEdit, we also conduct extensive experiments on ImageNet and Imagen, and compare it with a bunch of the SOTA methods. The experimental results show that InstDiffEdit not only outperforms the SOTA methods in both image quality and editing results, but also has a much faster inference speed, i.e., +5 to +6 times.
Examining the Effect of Pre-training on Time Series Classification
Sep 11, 2023
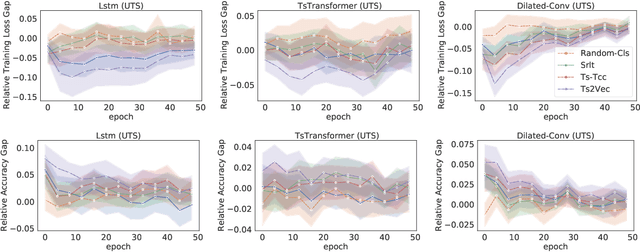
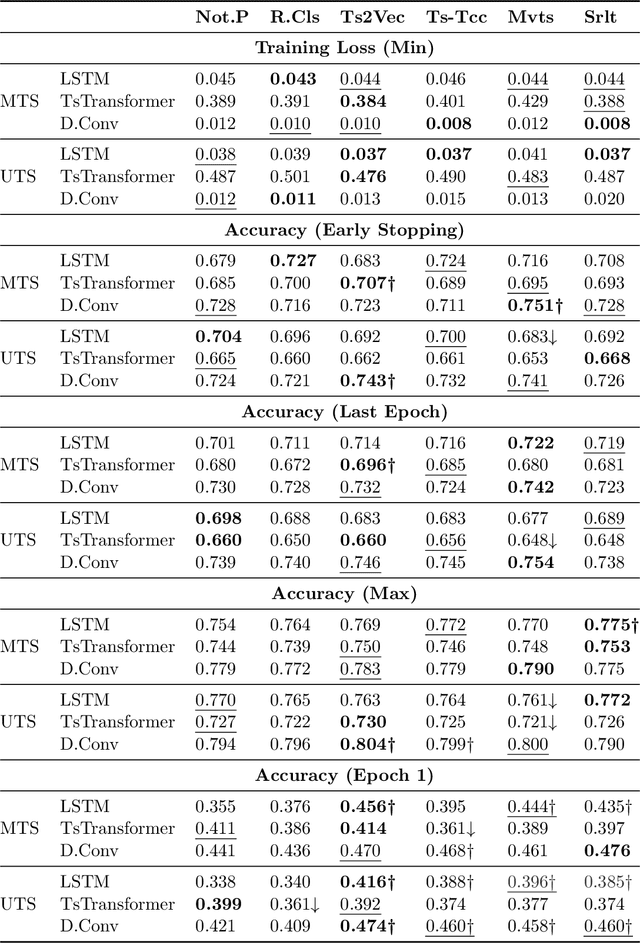
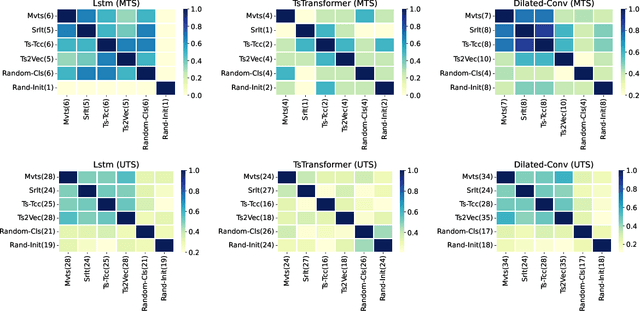
Although the pre-training followed by fine-tuning paradigm is used extensively in many fields, there is still some controversy surrounding the impact of pre-training on the fine-tuning process. Currently, experimental findings based on text and image data lack consensus. To delve deeper into the unsupervised pre-training followed by fine-tuning paradigm, we have extended previous research to a new modality: time series. In this study, we conducted a thorough examination of 150 classification datasets derived from the Univariate Time Series (UTS) and Multivariate Time Series (MTS) benchmarks. Our analysis reveals several key conclusions. (i) Pre-training can only help improve the optimization process for models that fit the data poorly, rather than those that fit the data well. (ii) Pre-training does not exhibit the effect of regularization when given sufficient training time. (iii) Pre-training can only speed up convergence if the model has sufficient ability to fit the data. (iv) Adding more pre-training data does not improve generalization, but it can strengthen the advantage of pre-training on the original data volume, such as faster convergence. (v) While both the pre-training task and the model structure determine the effectiveness of the paradigm on a given dataset, the model structure plays a more significant role.
Sudowoodo: a Chinese Lyric Imitation System with Source Lyrics
Aug 09, 2023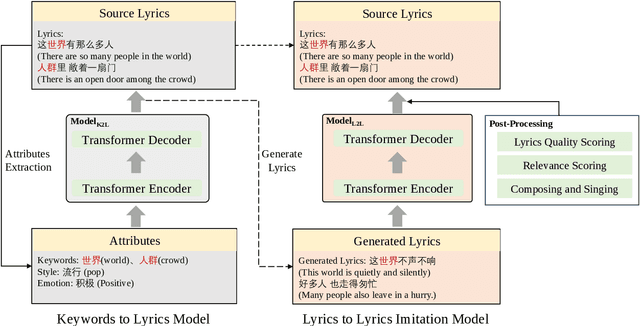

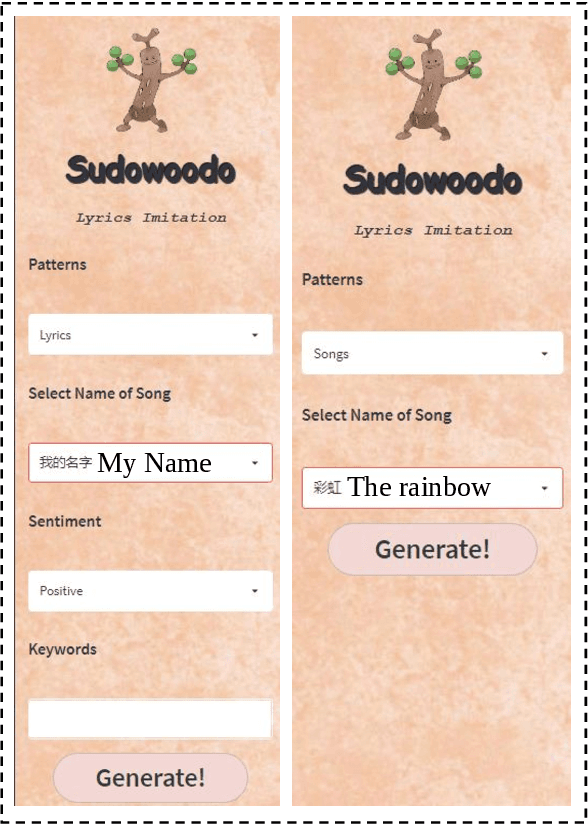

Lyrics generation is a well-known application in natural language generation research, with several previous studies focusing on generating accurate lyrics using precise control such as keywords, rhymes, etc. However, lyrics imitation, which involves writing new lyrics by imitating the style and content of the source lyrics, remains a challenging task due to the lack of a parallel corpus. In this paper, we introduce \textbf{\textit{Sudowoodo}}, a Chinese lyrics imitation system that can generate new lyrics based on the text of source lyrics. To address the issue of lacking a parallel training corpus for lyrics imitation, we propose a novel framework to construct a parallel corpus based on a keyword-based lyrics model from source lyrics. Then the pairs \textit{(new lyrics, source lyrics)} are used to train the lyrics imitation model. During the inference process, we utilize a post-processing module to filter and rank the generated lyrics, selecting the highest-quality ones. We incorporated audio information and aligned the lyrics with the audio to form the songs as a bonus. The human evaluation results show that our framework can perform better lyric imitation. Meanwhile, the \textit{Sudowoodo} system and demo video of the system is available at \href{https://Sudowoodo.apps-hp.danlu.netease.com/}{Sudowoodo} and \href{https://youtu.be/u5BBT_j1L5M}{https://youtu.be/u5BBT\_j1L5M}.
I-WAS: a Data Augmentation Method with GPT-2 for Simile Detection
Aug 08, 2023



Simile detection is a valuable task for many natural language processing (NLP)-based applications, particularly in the field of literature. However, existing research on simile detection often relies on corpora that are limited in size and do not adequately represent the full range of simile forms. To address this issue, we propose a simile data augmentation method based on \textbf{W}ord replacement And Sentence completion using the GPT-2 language model. Our iterative process called I-WAS, is designed to improve the quality of the augmented sentences. To better evaluate the performance of our method in real-world applications, we have compiled a corpus containing a more diverse set of simile forms for experimentation. Our experimental results demonstrate the effectiveness of our proposed data augmentation method for simile detection.
* 15 pages, 1 figure
Beyond First Impressions: Integrating Joint Multi-modal Cues for Comprehensive 3D Representation
Aug 06, 2023



In recent years, 3D representation learning has turned to 2D vision-language pre-trained models to overcome data scarcity challenges. However, existing methods simply transfer 2D alignment strategies, aligning 3D representations with single-view 2D images and coarse-grained parent category text. These approaches introduce information degradation and insufficient synergy issues, leading to performance loss. Information degradation arises from overlooking the fact that a 3D representation should be equivalent to a series of multi-view images and more fine-grained subcategory text. Insufficient synergy neglects the idea that a robust 3D representation should align with the joint vision-language space, rather than independently aligning with each modality. In this paper, we propose a multi-view joint modality modeling approach, termed JM3D, to obtain a unified representation for point cloud, text, and image. Specifically, a novel Structured Multimodal Organizer (SMO) is proposed to address the information degradation issue, which introduces contiguous multi-view images and hierarchical text to enrich the representation of vision and language modalities. A Joint Multi-modal Alignment (JMA) is designed to tackle the insufficient synergy problem, which models the joint modality by incorporating language knowledge into the visual modality. Extensive experiments on ModelNet40 and ScanObjectNN demonstrate the effectiveness of our proposed method, JM3D, which achieves state-of-the-art performance in zero-shot 3D classification. JM3D outperforms ULIP by approximately 4.3% on PointMLP and achieves an improvement of up to 6.5% accuracy on PointNet++ in top-1 accuracy for zero-shot 3D classification on ModelNet40. The source code and trained models for all our experiments are publicly available at https://github.com/Mr-Neko/JM3D.
Neighborhood-based Hard Negative Mining for Sequential Recommendation
Jun 12, 2023



Negative sampling plays a crucial role in training successful sequential recommendation models. Instead of merely employing random negative sample selection, numerous strategies have been proposed to mine informative negative samples to enhance training and performance. However, few of these approaches utilize structural information. In this work, we observe that as training progresses, the distributions of node-pair similarities in different groups with varying degrees of neighborhood overlap change significantly, suggesting that item pairs in distinct groups may possess different negative relationships. Motivated by this observation, we propose a Graph-based Negative sampling approach based on Neighborhood Overlap (GNNO) to exploit structural information hidden in user behaviors for negative mining. GNNO first constructs a global weighted item transition graph using training sequences. Subsequently, it mines hard negative samples based on the degree of overlap with the target item on the graph. Furthermore, GNNO employs curriculum learning to control the hardness of negative samples, progressing from easy to difficult. Extensive experiments on three Amazon benchmarks demonstrate GNNO's effectiveness in consistently enhancing the performance of various state-of-the-art models and surpassing existing negative sampling strategies. The code will be released at \url{https://github.com/floatSDSDS/GNNO}.
Adapting Pre-trained Language Models to Vision-Language Tasks via Dynamic Visual Prompting
Jun 01, 2023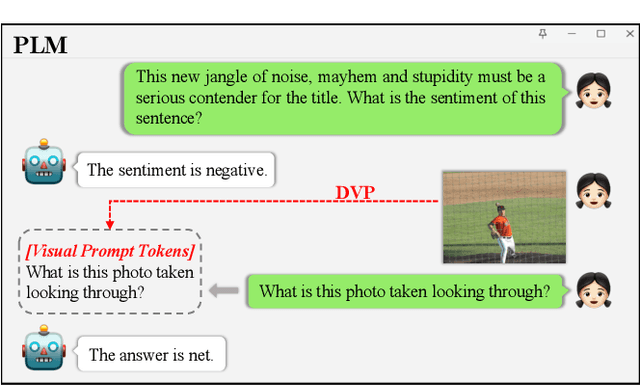

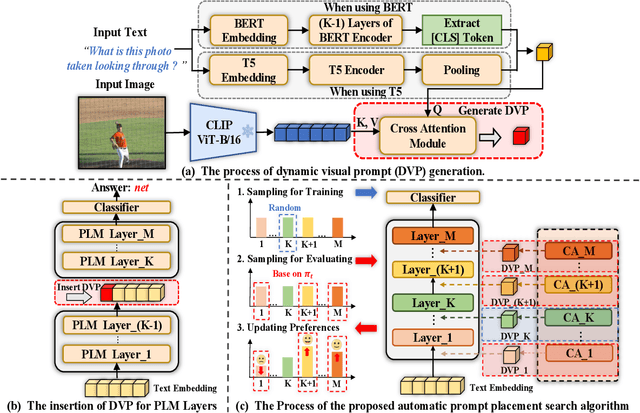

Pre-trained language models (PLMs) have played an increasing role in multimedia research. In terms of vision-language (VL) tasks, they often serve as a language encoder and still require an additional fusion network for VL reasoning, resulting in excessive memory overhead. In this paper, we focus on exploring PLMs as a stand-alone model for VL reasoning tasks. Inspired by the recently popular prompt tuning, we first prove that the processed visual features can be also projected onto the semantic space of PLMs and act as prompt tokens to bridge the gap between single- and multi-modal learning. However, this solution exhibits obvious redundancy in visual information and model inference, and the placement of prompt tokens also greatly affects the final performance. Based on these observations, we further propose a novel transfer learning approach for PLMs, termed Dynamic Visual Prompting (DVP). Concretely, DVP first deploys a cross-attention module to obtain text-related and compact visual prompt tokens, thereby greatly reducing the input length of PLMs. To obtain the optimal placement, we also equip DVP with a reinforcement-learning based search algorithm, which can automatically merge DVP with PLMs for different VL tasks via a very short search process. In addition, we also experiment DVP with the recently popular adapter approach to keep the most parameters of PLMs intact when adapting to VL tasks, helping PLMs achieve a quick shift between single- and multi-modal tasks. We apply DVP to two representative PLMs, namely BERT and T5, and conduct extensive experiments on a set of VL reasoning benchmarks including VQA2.0, GQA and SNLIVE. The experimental results not only show the advantage of DVP on efficiency and performance, but also confirm its superiority in adapting pre-trained language models to VL tasks.
PromptNER: Prompt Locating and Typing for Named Entity Recognition
May 26, 2023
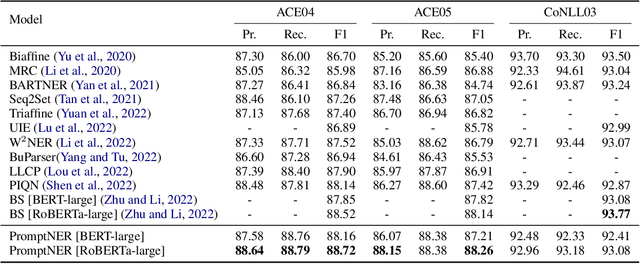


Prompt learning is a new paradigm for utilizing pre-trained language models and has achieved great success in many tasks. To adopt prompt learning in the NER task, two kinds of methods have been explored from a pair of symmetric perspectives, populating the template by enumerating spans to predict their entity types or constructing type-specific prompts to locate entities. However, these methods not only require a multi-round prompting manner with a high time overhead and computational cost, but also require elaborate prompt templates, that are difficult to apply in practical scenarios. In this paper, we unify entity locating and entity typing into prompt learning, and design a dual-slot multi-prompt template with the position slot and type slot to prompt locating and typing respectively. Multiple prompts can be input to the model simultaneously, and then the model extracts all entities by parallel predictions on the slots. To assign labels for the slots during training, we design a dynamic template filling mechanism that uses the extended bipartite graph matching between prompts and the ground-truth entities. We conduct experiments in various settings, including resource-rich flat and nested NER datasets and low-resource in-domain and cross-domain datasets. Experimental results show that the proposed model achieves a significant performance improvement, especially in the cross-domain few-shot setting, which outperforms the state-of-the-art model by +7.7% on average.