 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiao-Ming Wu
Dexterous Grasp Transformer
Apr 28, 2024
In this work, we propose a novel discriminative framework for dexterous grasp generation, named Dexterous Grasp TRansformer (DGTR), capable of predicting a diverse set of feasible grasp poses by processing the object point cloud with only one forward pass. We formulate dexterous grasp generation as a set prediction task and design a transformer-based grasping model for it. However, we identify that this set prediction paradigm encounters several optimization challenges in the field of dexterous grasping and results in restricted performance. To address these issues, we propose progressive strategies for both the training and testing phases. First, the dynamic-static matching training (DSMT) strategy is presented to enhance the optimization stability during the training phase. Second, we introduce the adversarial-balanced test-time adaptation (AB-TTA) with a pair of adversarial losses to improve grasping quality during the testing phase. Experimental results on the DexGraspNet dataset demonstrate the capability of DGTR to predict dexterous grasp poses with both high quality and diversity. Notably, while keeping high quality, the diversity of grasp poses predicted by DGTR significantly outperforms previous works in multiple metrics without any data pre-processing. Codes are available at https://github.com/iSEE-Laboratory/DGTR .
Single-View Scene Point Cloud Human Grasp Generation
Apr 24, 2024In this work, we explore a novel task of generating human grasps based on single-view scene point clouds, which more accurately mirrors the typical real-world situation of observing objects from a single viewpoint. Due to the incompleteness of object point clouds and the presence of numerous scene points, the generated hand is prone to penetrating into the invisible parts of the object and the model is easily affected by scene points. Thus, we introduce S2HGrasp, a framework composed of two key modules: the Global Perception module that globally perceives partial object point clouds, and the DiffuGrasp module designed to generate high-quality human grasps based on complex inputs that include scene points. Additionally, we introduce S2HGD dataset, which comprises approximately 99,000 single-object single-view scene point clouds of 1,668 unique objects, each annotated with one human grasp. Our extensive experiments demonstrate that S2HGrasp can not only generate natural human grasps regardless of scene points, but also effectively prevent penetration between the hand and invisible parts of the object. Moreover, our model showcases strong generalization capability when applied to unseen objects. Our code and dataset are available at https://github.com/iSEE-Laboratory/S2HGrasp.
VI-OOD: A Unified Representation Learning Framework for Textual Out-of-distribution Detection
Apr 09, 2024Out-of-distribution (OOD) detection plays a crucial role in ensuring the safety and reliability of deep neural networks in various applications. While there has been a growing focus on OOD detection in visual data, the field of textual OOD detection has received less attention. Only a few attempts have been made to directly apply general OOD detection methods to natural language processing (NLP) tasks, without adequately considering the characteristics of textual data. In this paper, we delve into textual OOD detection with Transformers. We first identify a key problem prevalent in existing OOD detection methods: the biased representation learned through the maximization of the conditional likelihood $p(y\mid x)$ can potentially result in subpar performance. We then propose a novel variational inference framework for OOD detection (VI-OOD), which maximizes the likelihood of the joint distribution $p(x, y)$ instead of $p(y\mid x)$. VI-OOD is tailored for textual OOD detection by efficiently exploiting the representations of pre-trained Transformers. Through comprehensive experiments on various text classification tasks, VI-OOD demonstrates its effectiveness and wide applicability. Our code has been released at \url{https://github.com/liam0949/LLM-OOD}.
Multimodal Pretraining, Adaptation, and Generation for Recommendation: A Survey
Mar 31, 2024Personalized recommendation serves as a ubiquitous channel for users to discover information or items tailored to their interests. However, traditional recommendation models primarily rely on unique IDs and categorical features for user-item matching, potentially overlooking the nuanced essence of raw item contents across multiple modalities such as text, image, audio, and video. This underutilization of multimodal data poses a limitation to recommender systems, especially in multimedia services like news, music, and short-video platforms. The recent advancements in pretrained multimodal models offer new opportunities and challenges in developing content-aware recommender systems. This survey seeks to provide a comprehensive exploration of the latest advancements and future trajectories in multimodal pretraining, adaptation, and generation techniques, as well as their applications to recommender systems. Furthermore, we discuss open challenges and opportunities for future research in this domain. We hope that this survey, along with our tutorial materials, will inspire further research efforts to advance this evolving landscape.
Decoy Effect In Search Interaction: Understanding User Behavior and Measuring System Vulnerability
Mar 27, 2024

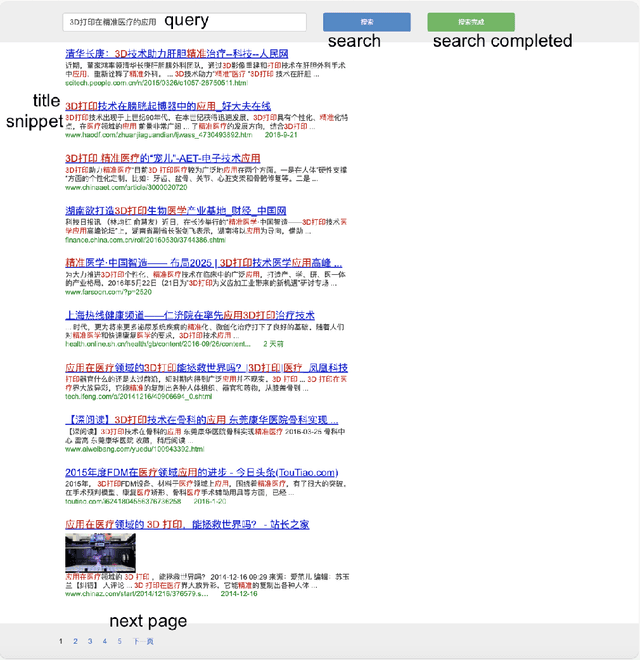
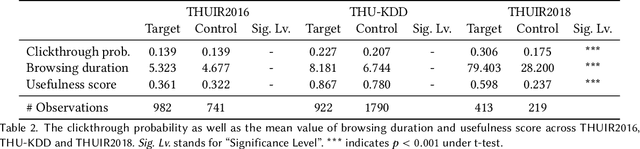
This study examines the decoy effect's underexplored influence on user search interactions and methods for measuring information retrieval (IR) systems' vulnerability to this effect. It explores how decoy results alter users' interactions on search engine result pages, focusing on metrics like click-through likelihood, browsing time, and perceived document usefulness. By analyzing user interaction logs from multiple datasets, the study demonstrates that decoy results significantly affect users' behavior and perceptions. Furthermore, it investigates how different levels of task difficulty and user knowledge modify the decoy effect's impact, finding that easier tasks and lower knowledge levels lead to higher engagement with target documents. In terms of IR system evaluation, the study introduces the DEJA-VU metric to assess systems' susceptibility to the decoy effect, testing it on specific retrieval tasks. The results show differences in systems' effectiveness and vulnerability, contributing to our understanding of cognitive biases in search behavior and suggesting pathways for creating more balanced and bias-aware IR evaluations.
Discrete Semantic Tokenization for Deep CTR Prediction
Mar 21, 2024Incorporating item content information into click-through rate (CTR) prediction models remains a challenge, especially with the time and space constraints of industrial scenarios. The content-encoding paradigm, which integrates user and item encoders directly into CTR models, prioritizes space over time. In contrast, the embedding-based paradigm transforms item and user semantics into latent embeddings, subsequently caching them to optimize processing time at the expense of space. In this paper, we introduce a new semantic-token paradigm and propose a discrete semantic tokenization approach, namely UIST, for user and item representation. UIST facilitates swift training and inference while maintaining a conservative memory footprint. Specifically, UIST quantizes dense embedding vectors into discrete tokens with shorter lengths and employs a hierarchical mixture inference module to weigh the contribution of each user--item token pair. Our experimental results on news recommendation showcase the effectiveness and efficiency (about 200-fold space compression) of UIST for CTR prediction.
Selective Hourglass Mapping for Universal Image Restoration Based on Diffusion Model
Mar 17, 2024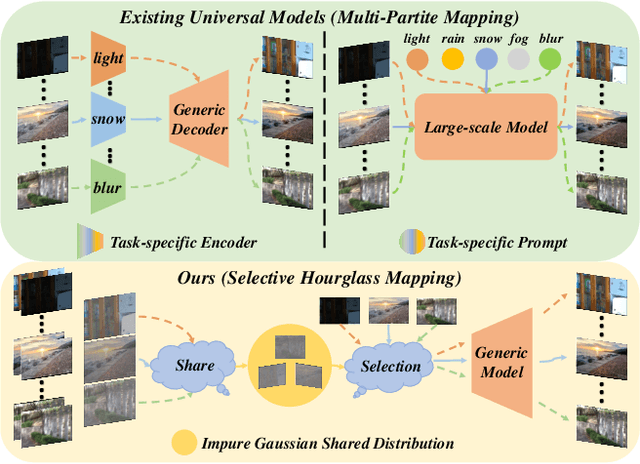


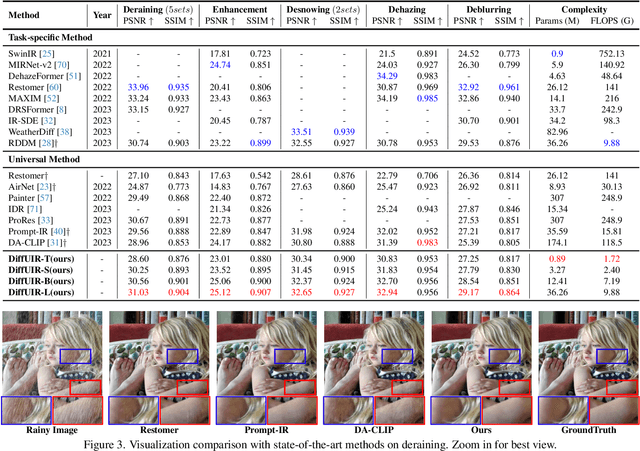
Universal image restoration is a practical and potential computer vision task for real-world applications. The main challenge of this task is handling the different degradation distributions at once. Existing methods mainly utilize task-specific conditions (e.g., prompt) to guide the model to learn different distributions separately, named multi-partite mapping. However, it is not suitable for universal model learning as it ignores the shared information between different tasks. In this work, we propose an advanced selective hourglass mapping strategy based on diffusion model, termed DiffUIR. Two novel considerations make our DiffUIR non-trivial. Firstly, we equip the model with strong condition guidance to obtain accurate generation direction of diffusion model (selective). More importantly, DiffUIR integrates a flexible shared distribution term (SDT) into the diffusion algorithm elegantly and naturally, which gradually maps different distributions into a shared one. In the reverse process, combined with SDT and strong condition guidance, DiffUIR iteratively guides the shared distribution to the task-specific distribution with high image quality (hourglass). Without bells and whistles, by only modifying the mapping strategy, we achieve state-of-the-art performance on five image restoration tasks, 22 benchmarks in the universal setting and zero-shot generalization setting. Surprisingly, by only using a lightweight model (only 0.89M), we could achieve outstanding performance. The source code and pre-trained models are available at https://github.com/iSEE-Laboratory/DiffUIR
Benchmarking News Recommendation in the Era of Green AI
Mar 15, 2024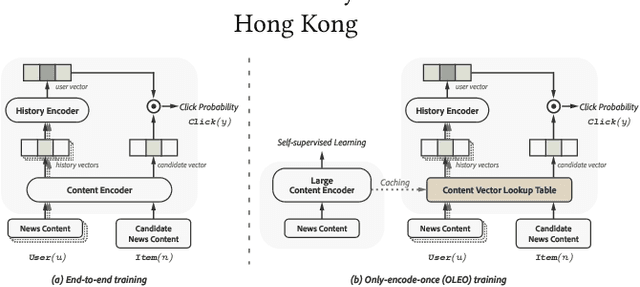

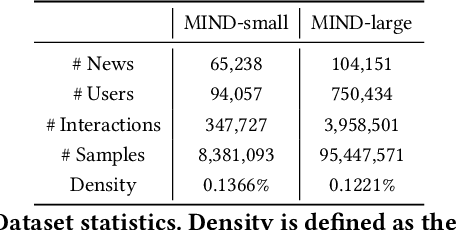

Over recent years, news recommender systems have gained significant attention in both academia and industry, emphasizing the need for a standardized benchmark to evaluate and compare the performance of these systems. Concurrently, Green AI advocates for reducing the energy consumption and environmental impact of machine learning. To address these concerns, we introduce the first Green AI benchmarking framework for news recommendation, known as GreenRec, and propose a metric for assessing the tradeoff between recommendation accuracy and efficiency. Our benchmark encompasses 30 base models and their variants, covering traditional end-to-end training paradigms as well as our proposed efficient only-encode-once (OLEO) paradigm. Through experiments consuming 2000 GPU hours, we observe that the OLEO paradigm achieves competitive accuracy compared to state-of-the-art end-to-end paradigms and delivers up to a 2992\% improvement in sustainability metrics.
Decoy Effect in Search Interaction: A Pilot Study
Nov 04, 2023In recent years, the influence of cognitive effects and biases on users' thinking, behaving, and decision-making has garnered increasing attention in the field of interactive information retrieval. The decoy effect, one of the main empirically confirmed cognitive biases, refers to the shift in preference between two choices when a third option (the decoy) which is inferior to one of the initial choices is introduced. However, it is not clear how the decoy effect influences user interactions with and evaluations on Search Engine Result Pages (SERPs). To bridge this gap, our study seeks to understand how the decoy effect at the document level influences users' interaction behaviors on SERPs, such as clicks, dwell time, and usefulness perceptions. We conducted experiments on two publicly available user behavior datasets and the findings reveal that, compared to cases where no decoy is present, the probability of a document being clicked could be improved and its usefulness score could be higher, should there be a decoy associated with the document.
Towards LLM-driven Dialogue State Tracking
Oct 23, 2023Dialogue State Tracking (DST) is of paramount importance in ensuring accurate tracking of user goals and system actions within task-oriented dialogue systems. The emergence of large language models (LLMs) such as GPT3 and ChatGPT has sparked considerable interest in assessing their efficacy across diverse applications. In this study, we conduct an initial examination of ChatGPT's capabilities in DST. Our evaluation uncovers the exceptional performance of ChatGPT in this task, offering valuable insights to researchers regarding its capabilities and providing useful directions for designing and enhancing dialogue systems. Despite its impressive performance, ChatGPT has significant limitations including its closed-source nature, request restrictions, raising data privacy concerns, and lacking local deployment capabilities. To address these concerns, we present LDST, an LLM-driven DST framework based on smaller, open-source foundation models. By utilizing a novel domain-slot instruction tuning method, LDST achieves performance on par with ChatGPT. Comprehensive evaluations across three distinct experimental settings, we find that LDST exhibits remarkable performance improvements in both zero-shot and few-shot setting compared to previous SOTA methods. The source code is provided for reproducibility.