 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhenhua Dong
Contrastive Quantization based Semantic Code for Generative Recommendation
Apr 23, 2024
With the success of large language models, generative retrieval has emerged as a new retrieval technique for recommendation. It can be divided into two stages: the first stage involves constructing discrete Codes (i.e., codes), and the second stage involves decoding the code sequentially via the transformer architecture. Current methods often construct item semantic codes by reconstructing based quantization on item textual representation, but they fail to capture item discrepancy that is essential in modeling item relationships in recommendation sytems. In this paper, we propose to construct the code representation of items by simultaneously considering both item relationships and semantic information. Specifically, we employ a pre-trained language model to extract item's textual description and translate it into item's embedding. Then we propose to enhance the encoder-decoder based RQVAE model with contrastive objectives to learn item code. To be specific, we employ the embeddings generated by the decoder from the samples themselves as positive instances and those from other samples as negative instances. Thus we effectively enhance the item discrepancy across all items, better preserving the item neighbourhood. Finally, we train and test semantic code with with generative retrieval on a sequential recommendation model. Our experiments demonstrate that our method improves NDCG@5 with 43.76% on the MIND dataset and Recall@10 with 80.95% on the Office dataset compared to the previous baselines.
A Survey on the Memory Mechanism of Large Language Model based Agents
Apr 21, 2024Large language model (LLM) based agents have recently attracted much attention from the research and industry communities. Compared with original LLMs, LLM-based agents are featured in their self-evolving capability, which is the basis for solving real-world problems that need long-term and complex agent-environment interactions. The key component to support agent-environment interactions is the memory of the agents. While previous studies have proposed many promising memory mechanisms, they are scattered in different papers, and there lacks a systematical review to summarize and compare these works from a holistic perspective, failing to abstract common and effective designing patterns for inspiring future studies. To bridge this gap, in this paper, we propose a comprehensive survey on the memory mechanism of LLM-based agents. In specific, we first discuss ''what is'' and ''why do we need'' the memory in LLM-based agents. Then, we systematically review previous studies on how to design and evaluate the memory module. In addition, we also present many agent applications, where the memory module plays an important role. At last, we analyze the limitations of existing work and show important future directions. To keep up with the latest advances in this field, we create a repository at \url{https://github.com/nuster1128/LLM_Agent_Memory_Survey}.
Unifying Bias and Unfairness in Information Retrieval: A Survey of Challenges and Opportunities with Large Language Models
Apr 17, 2024With the rapid advancement of large language models (LLMs), information retrieval (IR) systems, such as search engines and recommender systems, have undergone a significant paradigm shift. This evolution, while heralding new opportunities, introduces emerging challenges, particularly in terms of biases and unfairness, which may threaten the information ecosystem. In this paper, we present a comprehensive survey of existing works on emerging and pressing bias and unfairness issues in IR systems when the integration of LLMs. We first unify bias and unfairness issues as distribution mismatch problems, providing a groundwork for categorizing various mitigation strategies through distribution alignment. Subsequently, we systematically delve into the specific bias and unfairness issues arising from three critical stages of LLMs integration into IR systems: data collection, model development, and result evaluation. In doing so, we meticulously review and analyze recent literature, focusing on the definitions, characteristics, and corresponding mitigation strategies associated with these issues. Finally, we identify and highlight some open problems and challenges for future work, aiming to inspire researchers and stakeholders in the IR field and beyond to better understand and mitigate bias and unfairness issues of IR in this LLM era. We also consistently maintain a GitHub repository for the relevant papers and resources in this rising direction at https://github.com/KID-22/LLM-IR-Bias-Fairness-Survey.
Recall-Augmented Ranking: Enhancing Click-Through Rate Prediction Accuracy with Cross-Stage Data
Apr 15, 2024Click-through rate (CTR) prediction plays an indispensable role in online platforms. Numerous models have been proposed to capture users' shifting preferences by leveraging user behavior sequences. However, these historical sequences often suffer from severe homogeneity and scarcity compared to the extensive item pool. Relying solely on such sequences for user representations is inherently restrictive, as user interests extend beyond the scope of items they have previously engaged with. To address this challenge, we propose a data-driven approach to enrich user representations. We recognize user profiling and recall items as two ideal data sources within the cross-stage framework, encompassing the u2u (user-to-user) and i2i (item-to-item) aspects respectively. In this paper, we propose a novel architecture named Recall-Augmented Ranking (RAR). RAR consists of two key sub-modules, which synergistically gather information from a vast pool of look-alike users and recall items, resulting in enriched user representations. Notably, RAR is orthogonal to many existing CTR models, allowing for consistent performance improvements in a plug-and-play manner. Extensive experiments are conducted, which verify the efficacy and compatibility of RAR against the SOTA methods.
Multimodal Pretraining, Adaptation, and Generation for Recommendation: A Survey
Mar 31, 2024Personalized recommendation serves as a ubiquitous channel for users to discover information or items tailored to their interests. However, traditional recommendation models primarily rely on unique IDs and categorical features for user-item matching, potentially overlooking the nuanced essence of raw item contents across multiple modalities such as text, image, audio, and video. This underutilization of multimodal data poses a limitation to recommender systems, especially in multimedia services like news, music, and short-video platforms. The recent advancements in pretrained multimodal models offer new opportunities and challenges in developing content-aware recommender systems. This survey seeks to provide a comprehensive exploration of the latest advancements and future trajectories in multimodal pretraining, adaptation, and generation techniques, as well as their applications to recommender systems. Furthermore, we discuss open challenges and opportunities for future research in this domain. We hope that this survey, along with our tutorial materials, will inspire further research efforts to advance this evolving landscape.
Unlocking the Potential of Multimodal Unified Discrete Representation through Training-Free Codebook Optimization and Hierarchical Alignment
Mar 08, 2024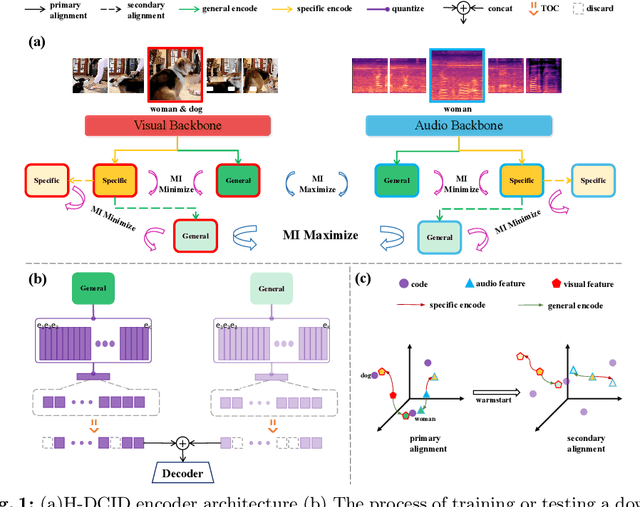
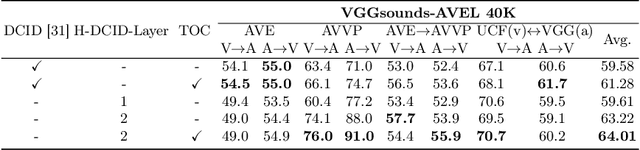
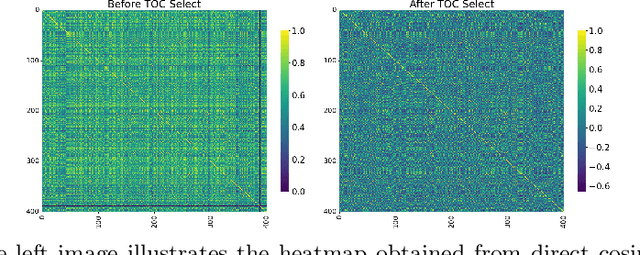
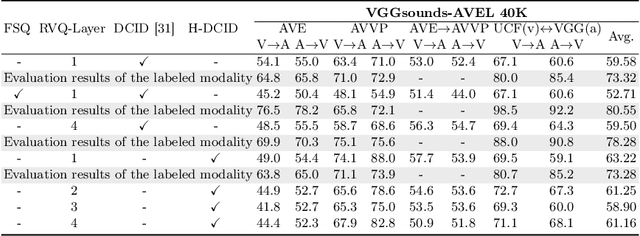
Recent advances in representation learning have demonstrated the significance of multimodal alignment. The Dual Cross-modal Information Disentanglement (DCID) model, utilizing a unified codebook, shows promising results in achieving fine-grained representation and cross-modal generalization. However, it is still hindered by equal treatment of all channels and neglect of minor event information, resulting in interference from irrelevant channels and limited performance in fine-grained tasks. Thus, in this work, We propose a Training-free Optimization of Codebook (TOC) method to enhance model performance by selecting important channels in the unified space without retraining. Additionally, we introduce the Hierarchical Dual Cross-modal Information Disentanglement (H-DCID) approach to extend information separation and alignment to two levels, capturing more cross-modal details. The experiment results demonstrate significant improvements across various downstream tasks, with TOC contributing to an average improvement of 1.70% for DCID on four tasks, and H-DCID surpassing DCID by an average of 3.64%. The combination of TOC and H-DCID further enhances performance, exceeding DCID by 4.43%. These findings highlight the effectiveness of our methods in facilitating robust and nuanced cross-modal learning, opening avenues for future enhancements. The source code and pre-trained models can be accessed at https://github.com/haihuangcode/TOC_H-DCID.
Confidence-Aware Multi-Field Model Calibration
Feb 27, 2024Accurately predicting the probabilities of user feedback, such as clicks and conversions, is critical for ad ranking and bidding. However, there often exist unwanted mismatches between predicted probabilities and true likelihoods due to the shift of data distributions and intrinsic model biases. Calibration aims to address this issue by post-processing model predictions, and field-aware calibration can adjust model output on different feature field values to satisfy fine-grained advertising demands. Unfortunately, the observed samples corresponding to certain field values can be too limited to make confident calibrations, which may yield bias amplification and online disturbance. In this paper, we propose a confidence-aware multi-field calibration method, which adaptively adjusts the calibration intensity based on the confidence levels derived from sample statistics. It also utilizes multiple feature fields for joint model calibration with awareness of their importance to mitigate the data sparsity effect of a single field. Extensive offline and online experiments show the superiority of our method in boosting advertising performance and reducing prediction deviations.
Music-PAW: Learning Music Representations via Hierarchical Part-whole Interaction and Contrast
Dec 11, 2023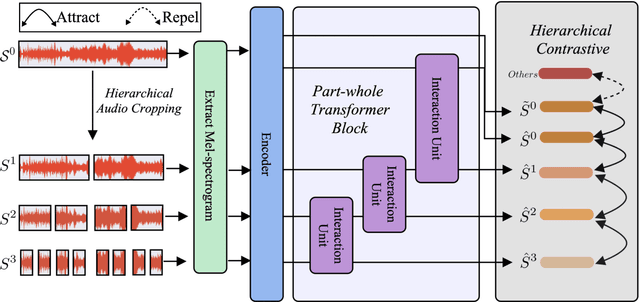
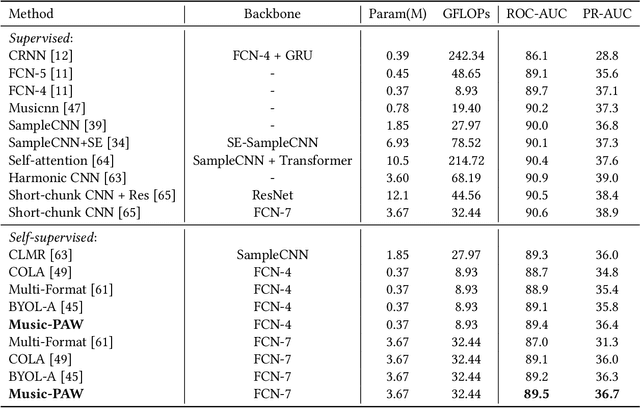
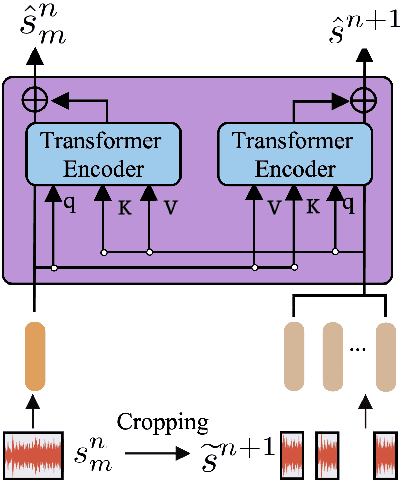
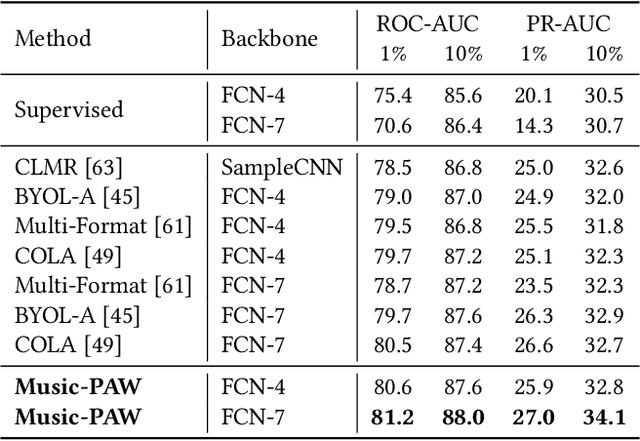
The excellent performance of recent self-supervised learning methods on various downstream tasks has attracted great attention from academia and industry. Some recent research efforts have been devoted to self-supervised music representation learning. Nevertheless, most of them learn to represent equally-sized music clips in the waveform or a spectrogram. Despite being effective in some tasks, learning music representations in such a manner largely neglect the inherent part-whole hierarchies of music. Due to the hierarchical nature of the auditory cortex [24], understanding the bottom-up structure of music, i.e., how different parts constitute the whole at different levels, is essential for music understanding and representation learning. This work pursues hierarchical music representation learning and introduces the Music-PAW framework, which enables feature interactions of cropped music clips with part-whole hierarchies. From a technical perspective, we propose a transformer-based part-whole interaction module to progressively reason the structural relationships between part-whole music clips at adjacent levels. Besides, to create a multi-hierarchy representation space, we devise a hierarchical contrastive learning objective to align part-whole music representations in adjacent hierarchies. The merits of audio representation learning from part-whole hierarchies have been validated on various downstream tasks, including music classification (single-label and multi-label), cover song identification and acoustic scene classification.
Beyond Two-Tower Matching: Learning Sparse Retrievable Cross-Interactions for Recommendation
Nov 30, 2023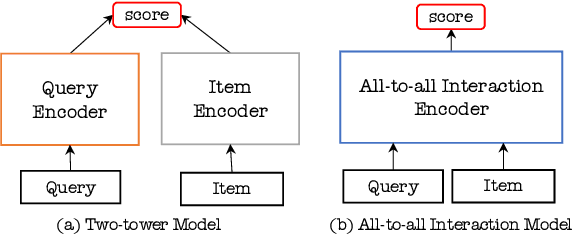
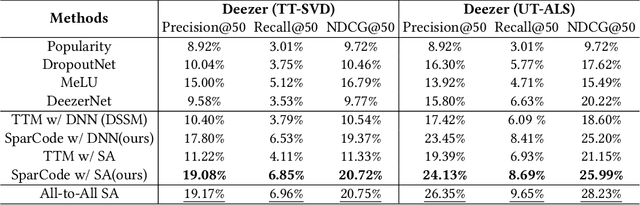
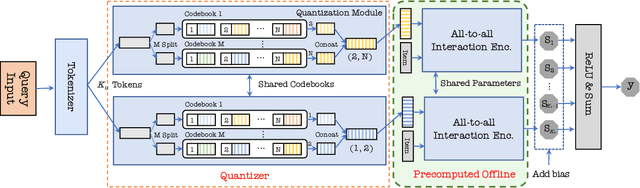
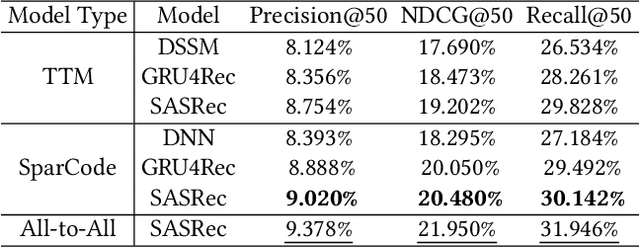
Two-tower models are a prevalent matching framework for recommendation, which have been widely deployed in industrial applications. The success of two-tower matching attributes to its efficiency in retrieval among a large number of items, since the item tower can be precomputed and used for fast Approximate Nearest Neighbor (ANN) search. However, it suffers two main challenges, including limited feature interaction capability and reduced accuracy in online serving. Existing approaches attempt to design novel late interactions instead of dot products, but they still fail to support complex feature interactions or lose retrieval efficiency. To address these challenges, we propose a new matching paradigm named SparCode, which supports not only sophisticated feature interactions but also efficient retrieval. Specifically, SparCode introduces an all-to-all interaction module to model fine-grained query-item interactions. Besides, we design a discrete code-based sparse inverted index jointly trained with the model to achieve effective and efficient model inference. Extensive experiments have been conducted on open benchmark datasets to demonstrate the superiority of our framework. The results show that SparCode significantly improves the accuracy of candidate item matching while retaining the same level of retrieval efficiency with two-tower models. Our source code will be available at MindSpore/models.
Optimal Transport for Treatment Effect Estimation
Oct 27, 2023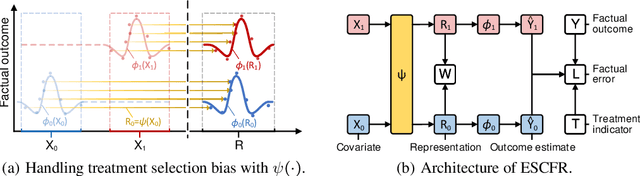
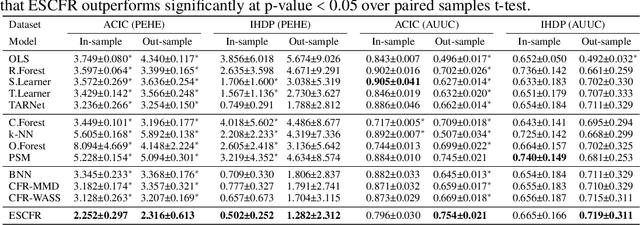
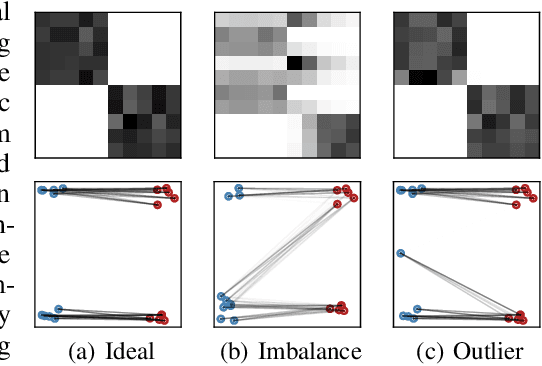

Estimating conditional average treatment effect from observational data is highly challenging due to the existence of treatment selection bias. Prevalent methods mitigate this issue by aligning distributions of different treatment groups in the latent space. However, there are two critical problems that these methods fail to address: (1) mini-batch sampling effects (MSE), which causes misalignment in non-ideal mini-batches with outcome imbalance and outliers; (2) unobserved confounder effects (UCE), which results in inaccurate discrepancy calculation due to the neglect of unobserved confounders. To tackle these problems, we propose a principled approach named Entire Space CounterFactual Regression (ESCFR), which is a new take on optimal transport in the context of causality. Specifically, based on the framework of stochastic optimal transport, we propose a relaxed mass-preserving regularizer to address the MSE issue and design a proximal factual outcome regularizer to handle the UCE issue. Extensive experiments demonstrate that our proposed ESCFR can successfully tackle the treatment selection bias and achieve significantly better performance than state-of-the-art methods.