 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiu Li
Deep Pattern Network for Click-Through Rate Prediction
Apr 17, 2024
Click-through rate (CTR) prediction tasks play a pivotal role in real-world applications, particularly in recommendation systems and online advertising. A significant research branch in this domain focuses on user behavior modeling. Current research predominantly centers on modeling co-occurrence relationships between the target item and items previously interacted with by users in their historical data. However, this focus neglects the intricate modeling of user behavior patterns. In reality, the abundance of user interaction records encompasses diverse behavior patterns, indicative of a spectrum of habitual paradigms. These patterns harbor substantial potential to significantly enhance CTR prediction performance. To harness the informational potential within user behavior patterns, we extend Target Attention (TA) to Target Pattern Attention (TPA) to model pattern-level dependencies. Furthermore, three critical challenges demand attention: the inclusion of unrelated items within behavior patterns, data sparsity in behavior patterns, and computational complexity arising from numerous patterns. To address these challenges, we introduce the Deep Pattern Network (DPN), designed to comprehensively leverage information from user behavior patterns. DPN efficiently retrieves target-related user behavior patterns using a target-aware attention mechanism. Additionally, it contributes to refining user behavior patterns through a pre-training paradigm based on self-supervised learning while promoting dependency learning within sparse patterns. Our comprehensive experiments, conducted across three public datasets, substantiate the superior performance and broad compatibility of DPN.
AV-GAN: Attention-Based Varifocal Generative Adversarial Network for Uneven Medical Image Translation
Apr 16, 2024Different types of staining highlight different structures in organs, thereby assisting in diagnosis. However, due to the impossibility of repeated staining, we cannot obtain different types of stained slides of the same tissue area. Translating the slide that is easy to obtain (e.g., H&E) to slides of staining types difficult to obtain (e.g., MT, PAS) is a promising way to solve this problem. However, some regions are closely connected to other regions, and to maintain this connection, they often have complex structures and are difficult to translate, which may lead to wrong translations. In this paper, we propose the Attention-Based Varifocal Generative Adversarial Network (AV-GAN), which solves multiple problems in pathologic image translation tasks, such as uneven translation difficulty in different regions, mutual interference of multiple resolution information, and nuclear deformation. Specifically, we develop an Attention-Based Key Region Selection Module, which can attend to regions with higher translation difficulty. We then develop a Varifocal Module to translate these regions at multiple resolutions. Experimental results show that our proposed AV-GAN outperforms existing image translation methods with two virtual kidney tissue staining tasks and improves FID values by 15.9 and 4.16 respectively in the H&E-MT and H&E-PAS tasks.
Lodge: A Coarse to Fine Diffusion Network for Long Dance Generation Guided by the Characteristic Dance Primitives
Mar 26, 2024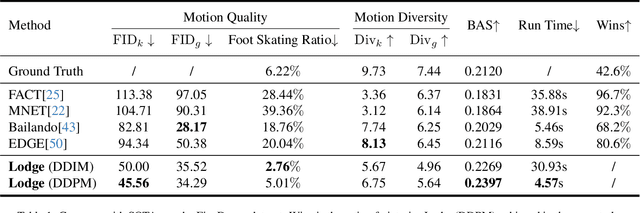
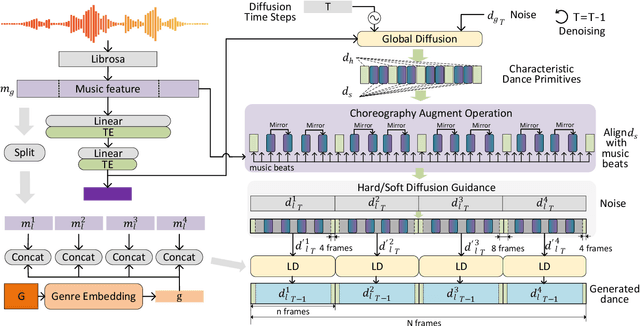
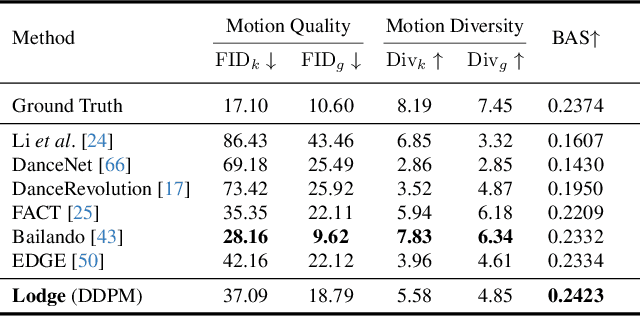
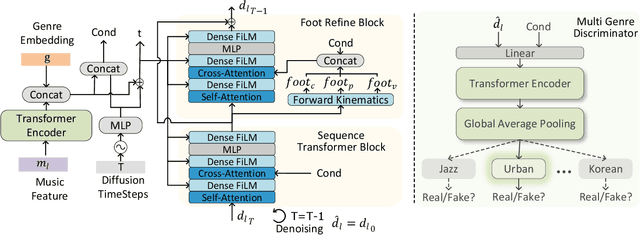
We propose Lodge, a network capable of generating extremely long dance sequences conditioned on given music. We design Lodge as a two-stage coarse to fine diffusion architecture, and propose the characteristic dance primitives that possess significant expressiveness as intermediate representations between two diffusion models. The first stage is global diffusion, which focuses on comprehending the coarse-level music-dance correlation and production characteristic dance primitives. In contrast, the second-stage is the local diffusion, which parallelly generates detailed motion sequences under the guidance of the dance primitives and choreographic rules. In addition, we propose a Foot Refine Block to optimize the contact between the feet and the ground, enhancing the physical realism of the motion. Our approach can parallelly generate dance sequences of extremely long length, striking a balance between global choreographic patterns and local motion quality and expressiveness. Extensive experiments validate the efficacy of our method.
GRA: Detecting Oriented Objects through Group-wise Rotating and Attention
Mar 19, 2024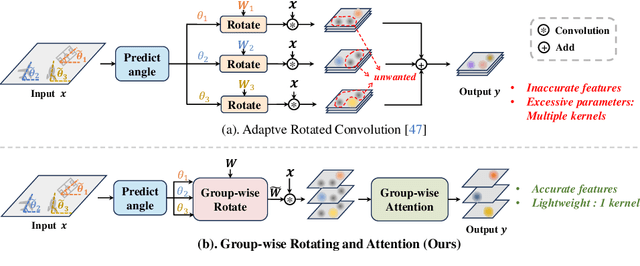
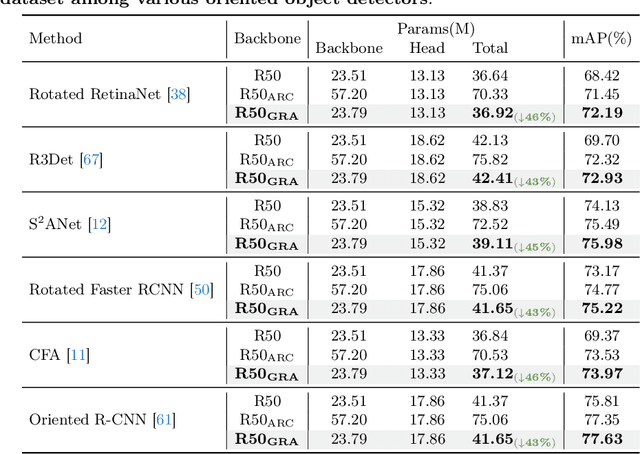
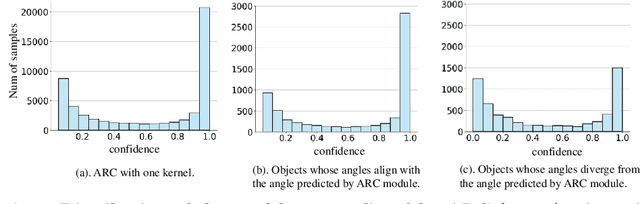
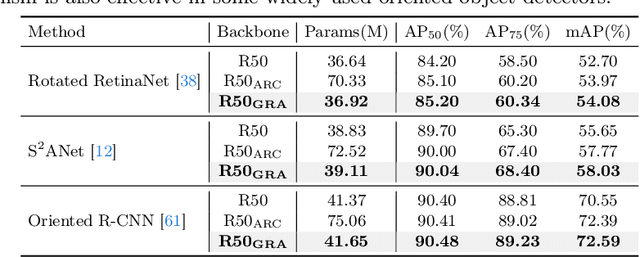
Oriented object detection, an emerging task in recent years, aims to identify and locate objects across varied orientations. This requires the detector to accurately capture the orientation information, which varies significantly within and across images. Despite the existing substantial efforts, simultaneously ensuring model effectiveness and parameter efficiency remains challenging in this scenario. In this paper, we propose a lightweight yet effective Group-wise Rotating and Attention (GRA) module to replace the convolution operations in backbone networks for oriented object detection. GRA can adaptively capture fine-grained features of objects with diverse orientations, comprising two key components: Group-wise Rotating and Group-wise Attention. Group-wise Rotating first divides the convolution kernel into groups, where each group extracts different object features by rotating at a specific angle according to the object orientation. Subsequently, Group-wise Attention is employed to adaptively enhance the object-related regions in the feature. The collaborative effort of these components enables GRA to effectively capture the various orientation information while maintaining parameter efficiency. Extensive experimental results demonstrate the superiority of our method. For example, GRA achieves a new state-of-the-art (SOTA) on the DOTA-v2.0 benchmark, while saving the parameters by nearly 50% compared to the previous SOTA method. Code will be released.
Video Object Segmentation with Dynamic Query Modulation
Mar 18, 2024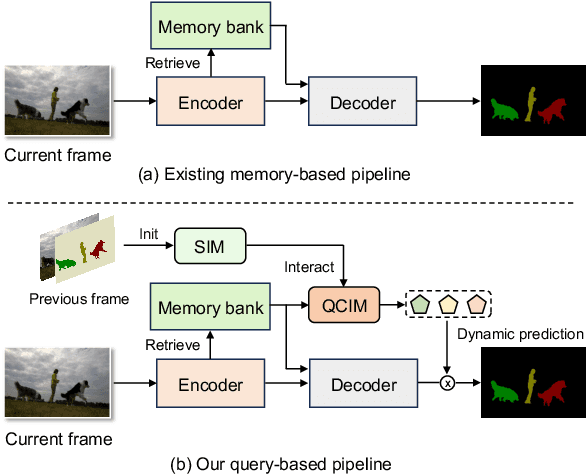
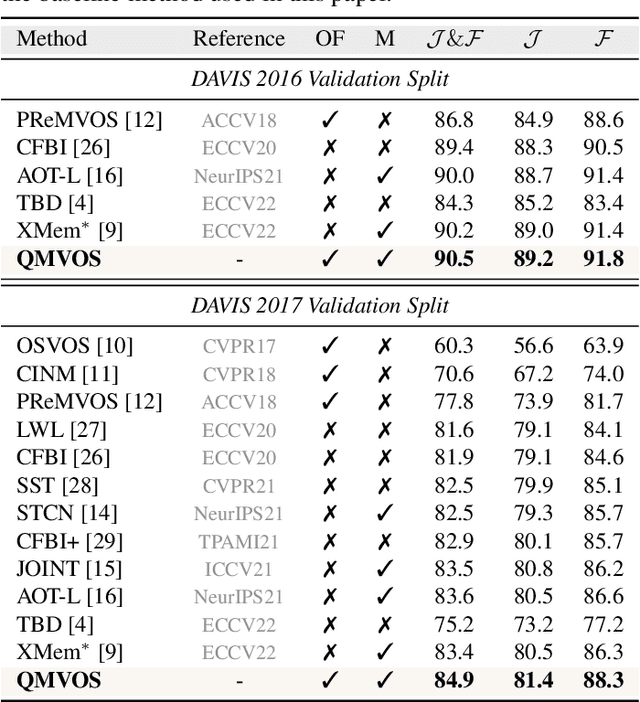
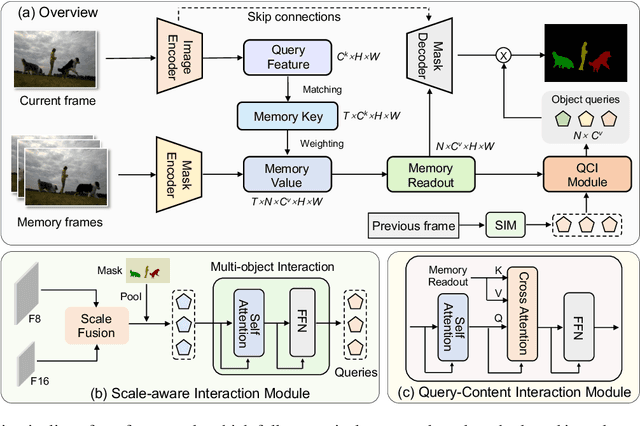
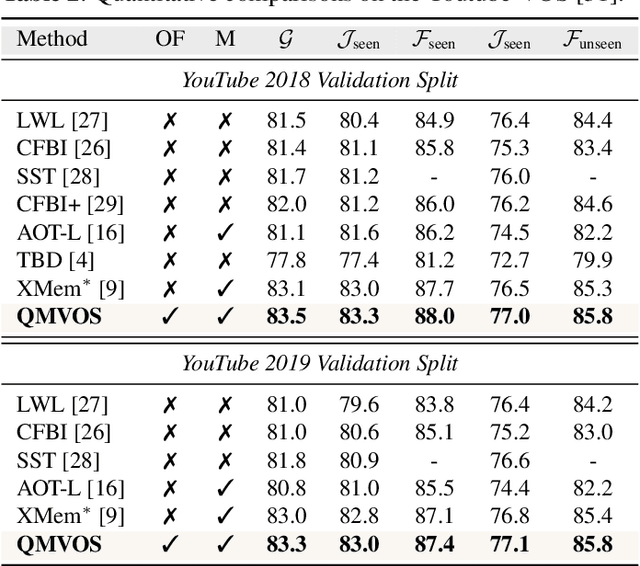
Storing intermediate frame segmentations as memory for long-range context modeling, spatial-temporal memory-based methods have recently showcased impressive results in semi-supervised video object segmentation (SVOS). However, these methods face two key limitations: 1) relying on non-local pixel-level matching to read memory, resulting in noisy retrieved features for segmentation; 2) segmenting each object independently without interaction. These shortcomings make the memory-based methods struggle in similar object and multi-object segmentation. To address these issues, we propose a query modulation method, termed QMVOS. This method summarizes object features into dynamic queries and then treats them as dynamic filters for mask prediction, thereby providing high-level descriptions and object-level perception for the model. Efficient and effective multi-object interactions are realized through inter-query attention. Extensive experiments demonstrate that our method can bring significant improvements to the memory-based SVOS method and achieve competitive performance on standard SVOS benchmarks. The code is available at https://github.com/zht8506/QMVOS.
MambaTalk: Efficient Holistic Gesture Synthesis with Selective State Space Models
Mar 14, 2024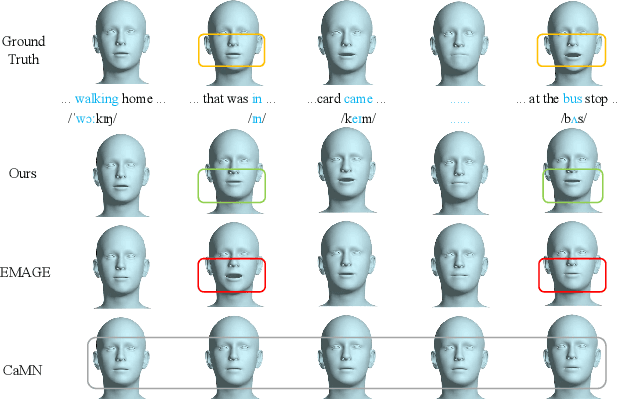

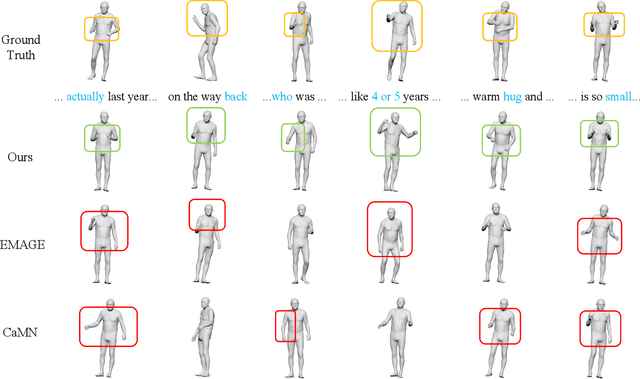
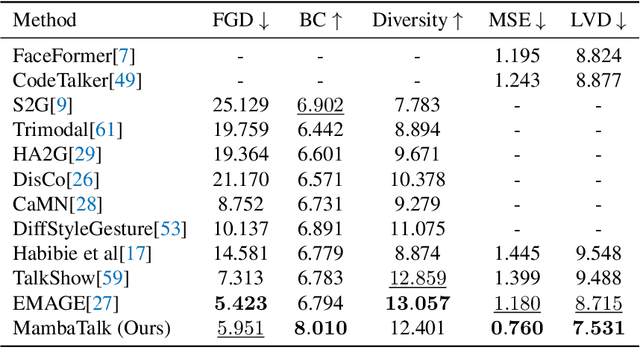
Gesture synthesis is a vital realm of human-computer interaction, with wide-ranging applications across various fields like film, robotics, and virtual reality. Recent advancements have utilized the diffusion model and attention mechanisms to improve gesture synthesis. However, due to the high computational complexity of these techniques, generating long and diverse sequences with low latency remains a challenge. We explore the potential of state space models (SSMs) to address the challenge, implementing a two-stage modeling strategy with discrete motion priors to enhance the quality of gestures. Leveraging the foundational Mamba block, we introduce MambaTalk, enhancing gesture diversity and rhythm through multimodal integration. Extensive experiments demonstrate that our method matches or exceeds the performance of state-of-the-art models.
Follow-Your-Click: Open-domain Regional Image Animation via Short Prompts
Mar 13, 2024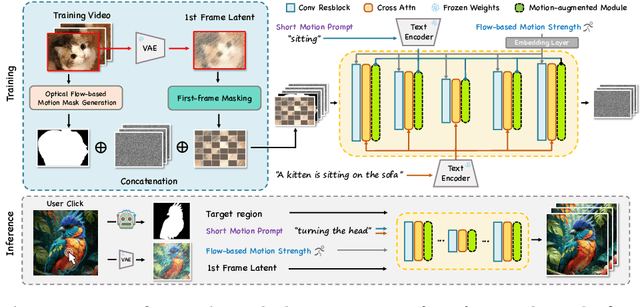
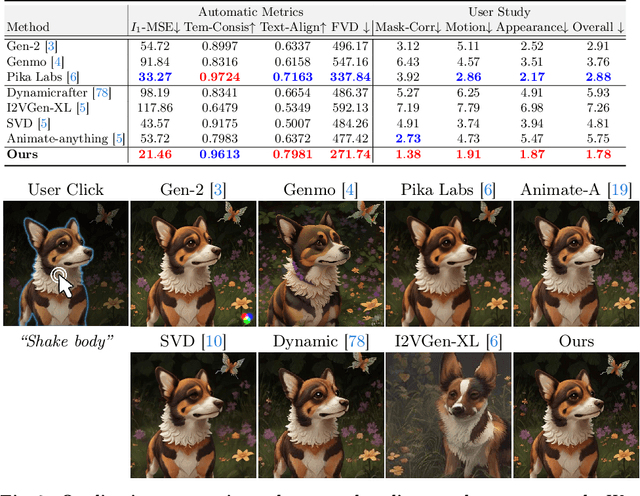
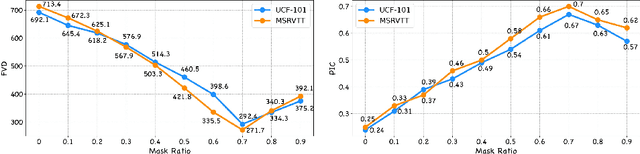

Despite recent advances in image-to-video generation, better controllability and local animation are less explored. Most existing image-to-video methods are not locally aware and tend to move the entire scene. However, human artists may need to control the movement of different objects or regions. Additionally, current I2V methods require users not only to describe the target motion but also to provide redundant detailed descriptions of frame contents. These two issues hinder the practical utilization of current I2V tools. In this paper, we propose a practical framework, named Follow-Your-Click, to achieve image animation with a simple user click (for specifying what to move) and a short motion prompt (for specifying how to move). Technically, we propose the first-frame masking strategy, which significantly improves the video generation quality, and a motion-augmented module equipped with a short motion prompt dataset to improve the short prompt following abilities of our model. To further control the motion speed, we propose flow-based motion magnitude control to control the speed of target movement more precisely. Our framework has simpler yet precise user control and better generation performance than previous methods. Extensive experiments compared with 7 baselines, including both commercial tools and research methods on 8 metrics, suggest the superiority of our approach. Project Page: https://follow-your-click.github.io/
Harmonious Group Choreography with Trajectory-Controllable Diffusion
Mar 10, 2024
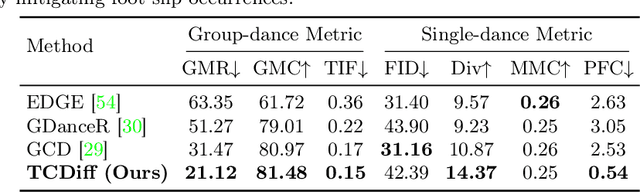
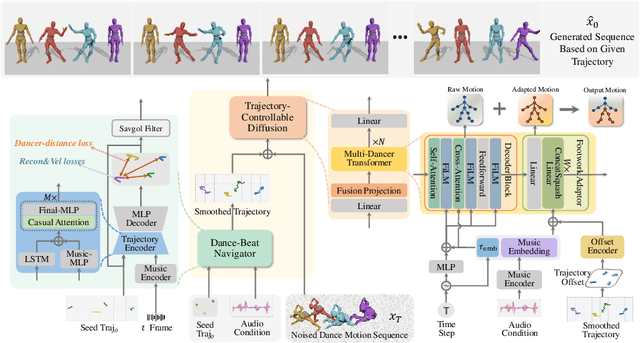
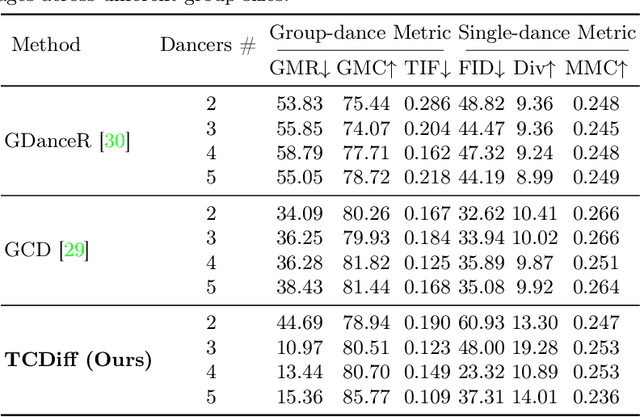
Creating group choreography from music has gained attention in cultural entertainment and virtual reality, aiming to coordinate visually cohesive and diverse group movements. Despite increasing interest, recent works face challenges in achieving aesthetically appealing choreography, primarily for two key issues: multi-dancer collision and single-dancer foot slide. To address these issues, we propose a Trajectory-Controllable Diffusion (TCDiff), a novel approach that harnesses non-overlapping trajectories to facilitate coherent dance movements. Specifically, to tackle dancer collisions, we introduce a Dance-Beat Navigator capable of generating trajectories for multiple dancers based on the music, complemented by a Distance-Consistency loss to maintain appropriate spacing among trajectories within a reasonable threshold. To mitigate foot sliding, we present a Footwork Adaptor that utilizes trajectory displacement from adjacent frames to enable flexible footwork, coupled with a Relative Forward-Kinematic loss to adjust the positioning of individual dancers' root nodes and joints. Extensive experiments demonstrate that our method achieves state-of-the-art results.
SEABO: A Simple Search-Based Method for Offline Imitation Learning
Feb 06, 2024Offline reinforcement learning (RL) has attracted much attention due to its ability in learning from static offline datasets and eliminating the need of interacting with the environment. Nevertheless, the success of offline RL relies heavily on the offline transitions annotated with reward labels. In practice, we often need to hand-craft the reward function, which is sometimes difficult, labor-intensive, or inefficient. To tackle this challenge, we set our focus on the offline imitation learning (IL) setting, and aim at getting a reward function based on the expert data and unlabeled data. To that end, we propose a simple yet effective search-based offline IL method, tagged SEABO. SEABO allocates a larger reward to the transition that is close to its closest neighbor in the expert demonstration, and a smaller reward otherwise, all in an unsupervised learning manner. Experimental results on a variety of D4RL datasets indicate that SEABO can achieve competitive performance to offline RL algorithms with ground-truth rewards, given only a single expert trajectory, and can outperform prior reward learning and offline IL methods across many tasks. Moreover, we demonstrate that SEABO also works well if the expert demonstrations contain only observations. Our code is publicly available at https://github.com/dmksjfl/SEABO.
Understanding What Affects Generalization Gap in Visual Reinforcement Learning: Theory and Empirical Evidence
Feb 05, 2024Recently, there are many efforts attempting to learn useful policies for continuous control in visual reinforcement learning (RL). In this scenario, it is important to learn a generalizable policy, as the testing environment may differ from the training environment, e.g., there exist distractors during deployment. Many practical algorithms are proposed to handle this problem. However, to the best of our knowledge, none of them provide a theoretical understanding of what affects the generalization gap and why their proposed methods work. In this paper, we bridge this issue by theoretically answering the key factors that contribute to the generalization gap when the testing environment has distractors. Our theories indicate that minimizing the representation distance between training and testing environments, which aligns with human intuition, is the most critical for the benefit of reducing the generalization gap. Our theoretical results are supported by the empirical evidence in the DMControl Generalization Benchmark (DMC-GB).