 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHongwen Zhang
Lodge: A Coarse to Fine Diffusion Network for Long Dance Generation Guided by the Characteristic Dance Primitives
Mar 26, 2024
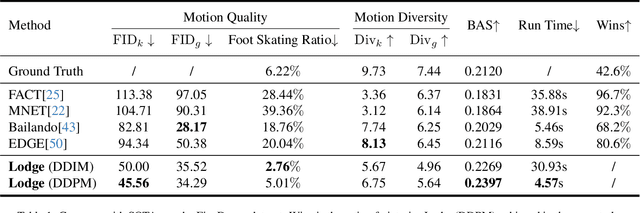
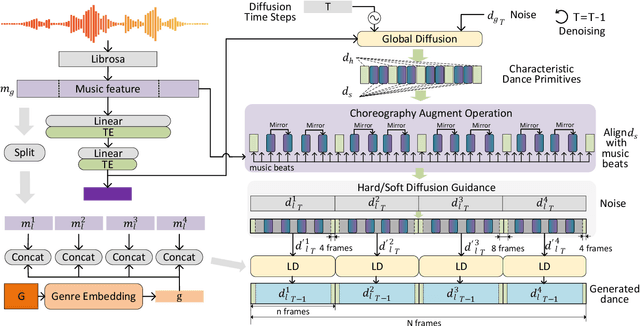
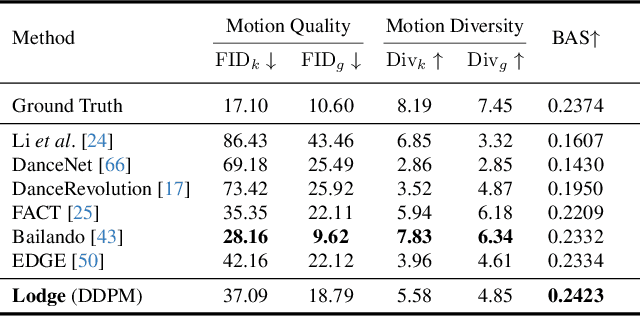
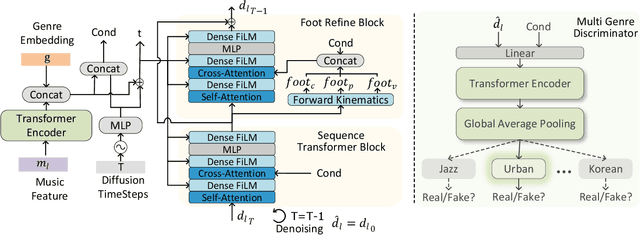
We propose Lodge, a network capable of generating extremely long dance sequences conditioned on given music. We design Lodge as a two-stage coarse to fine diffusion architecture, and propose the characteristic dance primitives that possess significant expressiveness as intermediate representations between two diffusion models. The first stage is global diffusion, which focuses on comprehending the coarse-level music-dance correlation and production characteristic dance primitives. In contrast, the second-stage is the local diffusion, which parallelly generates detailed motion sequences under the guidance of the dance primitives and choreographic rules. In addition, we propose a Foot Refine Block to optimize the contact between the feet and the ground, enhancing the physical realism of the motion. Our approach can parallelly generate dance sequences of extremely long length, striking a balance between global choreographic patterns and local motion quality and expressiveness. Extensive experiments validate the efficacy of our method.
STAF: 3D Human Mesh Recovery from Video with Spatio-Temporal Alignment Fusion
Jan 03, 2024The recovery of 3D human mesh from monocular images has significantly been developed in recent years. However, existing models usually ignore spatial and temporal information, which might lead to mesh and image misalignment and temporal discontinuity. For this reason, we propose a novel Spatio-Temporal Alignment Fusion (STAF) model. As a video-based model, it leverages coherence clues from human motion by an attention-based Temporal Coherence Fusion Module (TCFM). As for spatial mesh-alignment evidence, we extract fine-grained local information through predicted mesh projection on the feature maps. Based on the spatial features, we further introduce a multi-stage adjacent Spatial Alignment Fusion Module (SAFM) to enhance the feature representation of the target frame. In addition to the above, we propose an Average Pooling Module (APM) to allow the model to focus on the entire input sequence rather than just the target frame. This method can remarkably improve the smoothness of recovery results from video. Extensive experiments on 3DPW, MPII3D, and H36M demonstrate the superiority of STAF. We achieve a state-of-the-art trade-off between precision and smoothness. Our code and more video results are on the project page https://yw0208.github.io/staf/
Ins-HOI: Instance Aware Human-Object Interactions Recovery
Dec 15, 2023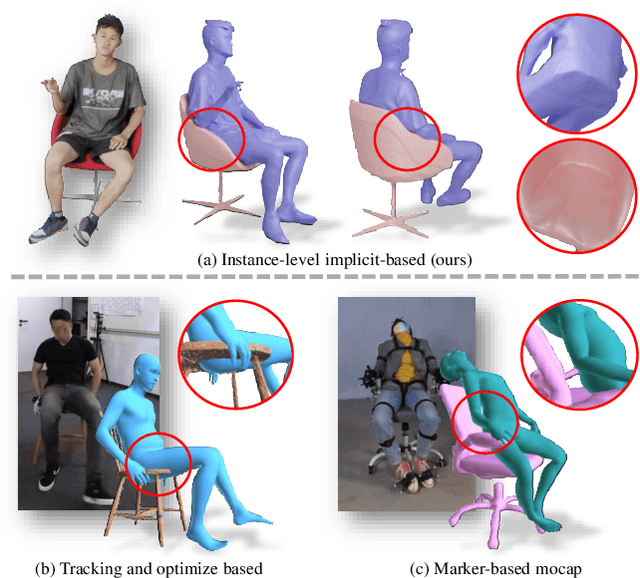
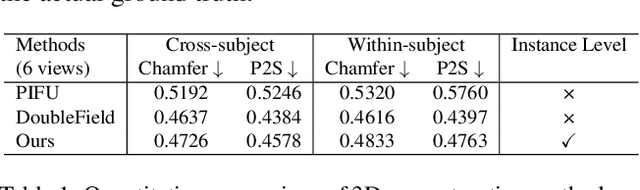


Recovering detailed interactions between humans/hands and objects is an appealing yet challenging task. Existing methods typically use template-based representations to track human/hand and objects in interactions. Despite the progress, they fail to handle the invisible contact surfaces. In this paper, we propose Ins-HOI, an end-to-end solution to recover human/hand-object reconstruction via instance-level implicit reconstruction. To this end, we introduce an instance-level occupancy field to support simultaneous human/hand and object representation, and a complementary training strategy to handle the lack of instance-level ground truths. Such a representation enables learning a contact prior implicitly from sparse observations. During the complementary training, we augment the real-captured data with synthesized data by randomly composing individual scans of humans/hands and objects and intentionally allowing for penetration. In this way, our network learns to recover individual shapes as completely as possible from the synthesized data, while being aware of the contact constraints and overall reasonability based on real-captured scans. As demonstrated in experiments, our method Ins-HOI can produce reasonable and realistic non-visible contact surfaces even in cases of extremely close interaction. To facilitate the research of this task, we collect a large-scale, high-fidelity 3D scan dataset, including 5.2k high-quality scans with real-world human-chair and hand-object interactions. We will release our dataset and source codes. Data examples and the video results of our method can be found on the project page.
Gaussian Head Avatar: Ultra High-fidelity Head Avatar via Dynamic Gaussians
Dec 05, 2023
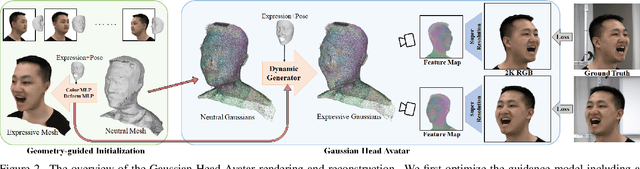
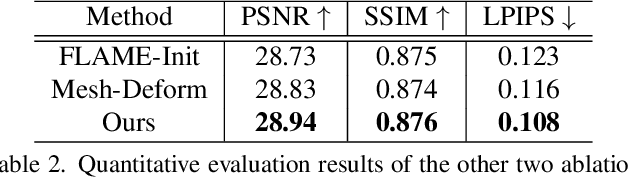
Creating high-fidelity 3D head avatars has always been a research hotspot, but there remains a great challenge under lightweight sparse view setups. In this paper, we propose Gaussian Head Avatar represented by controllable 3D Gaussians for high-fidelity head avatar modeling. We optimize the neutral 3D Gaussians and a fully learned MLP-based deformation field to capture complex expressions. The two parts benefit each other, thereby our method can model fine-grained dynamic details while ensuring expression accuracy. Furthermore, we devise a well-designed geometry-guided initialization strategy based on implicit SDF and Deep Marching Tetrahedra for the stability and convergence of the training procedure. Experiments show our approach outperforms other state-of-the-art sparse-view methods, achieving ultra high-fidelity rendering quality at 2K resolution even under exaggerated expressions.
Generating Fine-Grained Human Motions Using ChatGPT-Refined Descriptions
Dec 05, 2023Recently, significant progress has been made in text-based motion generation, enabling the generation of diverse and high-quality human motions that conform to textual descriptions. However, it remains challenging to generate fine-grained or stylized motions due to the lack of datasets annotated with detailed textual descriptions. By adopting a divide-and-conquer strategy, we propose a new framework named Fine-Grained Human Motion Diffusion Model (FG-MDM) for human motion generation. Specifically, we first parse previous vague textual annotation into fine-grained description of different body parts by leveraging a large language model (GPT-3.5). We then use these fine-grained descriptions to guide a transformer-based diffusion model. FG-MDM can generate fine-grained and stylized motions even outside of the distribution of the training data. Our experimental results demonstrate the superiority of FG-MDM over previous methods, especially the strong generalization capability. We will release our fine-grained textual annotations for HumanML3D and KIT.
GaussianAvatar: Towards Realistic Human Avatar Modeling from a Single Video via Animatable 3D Gaussians
Dec 04, 2023We present GaussianAvatar, an efficient approach to creating realistic human avatars with dynamic 3D appearances from a single video. We start by introducing animatable 3D Gaussians to explicitly represent humans in various poses and clothing styles. Such an explicit and animatable representation can fuse 3D appearances more efficiently and consistently from 2D observations. Our representation is further augmented with dynamic properties to support pose-dependent appearance modeling, where a dynamic appearance network along with an optimizable feature tensor is designed to learn the motion-to-appearance mapping. Moreover, by leveraging the differentiable motion condition, our method enables a joint optimization of motions and appearances during avatar modeling, which helps to tackle the long-standing issue of inaccurate motion estimation in monocular settings. The efficacy of GaussianAvatar is validated on both the public dataset and our collected dataset, demonstrating its superior performances in terms of appearance quality and rendering efficiency.
W-HMR: Human Mesh Recovery in World Space with Weak-supervised Camera Calibration and Orientation Correction
Nov 30, 2023For a long time, in the field of reconstructing 3D human bodies from monocular images, most methods opted to simplify the task by minimizing the influence of the camera. Using a coarse focal length setting results in the reconstructed bodies not aligning well with distorted images. Ignoring camera rotation leads to an unrealistic reconstructed body pose in world space. Consequently, existing methods' application scenarios are confined to controlled environments. And they struggle to achieve accurate and reasonable reconstruction in world space when confronted with complex and diverse in-the-wild images. To address the above issues, we propose W-HMR, which decouples global body recovery into camera calibration, local body recovery and global body orientation correction. We design the first weak-supervised camera calibration method for body distortion, eliminating dependence on focal length labels and achieving finer mesh-image alignment. We propose a novel orientation correction module to allow the reconstructed human body to remain normal in world space. Decoupling body orientation and body pose enables our model to consider the accuracy in camera coordinate and the reasonableness in world coordinate simultaneously, expanding the range of applications. As a result, W-HMR achieves high-quality reconstruction in dual coordinate systems, particularly in challenging scenes. Codes will be released on https://yw0208.github.io/w-hmr/ after publication.
HumanNorm: Learning Normal Diffusion Model for High-quality and Realistic 3D Human Generation
Oct 02, 2023
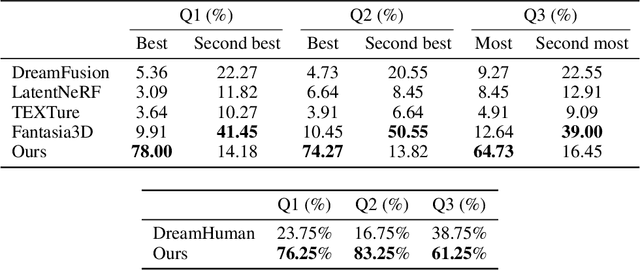

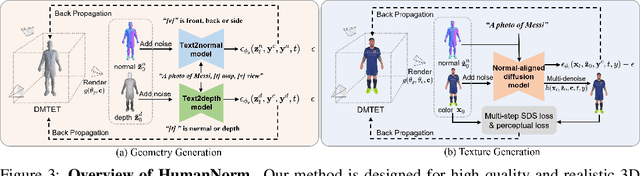
Recent text-to-3D methods employing diffusion models have made significant advancements in 3D human generation. However, these approaches face challenges due to the limitations of the text-to-image diffusion model, which lacks an understanding of 3D structures. Consequently, these methods struggle to achieve high-quality human generation, resulting in smooth geometry and cartoon-like appearances. In this paper, we observed that fine-tuning text-to-image diffusion models with normal maps enables their adaptation into text-to-normal diffusion models, which enhances the 2D perception of 3D geometry while preserving the priors learned from large-scale datasets. Therefore, we propose HumanNorm, a novel approach for high-quality and realistic 3D human generation by learning the normal diffusion model including a normal-adapted diffusion model and a normal-aligned diffusion model. The normal-adapted diffusion model can generate high-fidelity normal maps corresponding to prompts with view-dependent text. The normal-aligned diffusion model learns to generate color images aligned with the normal maps, thereby transforming physical geometry details into realistic appearance. Leveraging the proposed normal diffusion model, we devise a progressive geometry generation strategy and coarse-to-fine texture generation strategy to enhance the efficiency and robustness of 3D human generation. Comprehensive experiments substantiate our method's ability to generate 3D humans with intricate geometry and realistic appearances, significantly outperforming existing text-to-3D methods in both geometry and texture quality. The project page of HumanNorm is https://humannorm.github.io/.
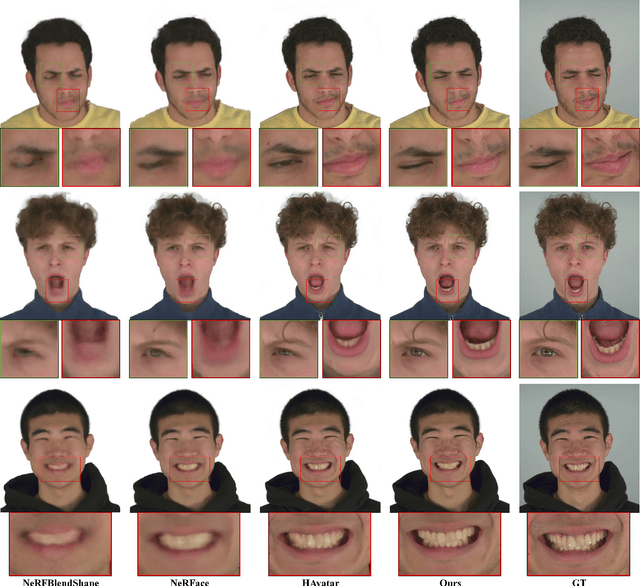
HAvatar: High-fidelity Head Avatar via Facial Model Conditioned Neural Radiance Field
Sep 29, 2023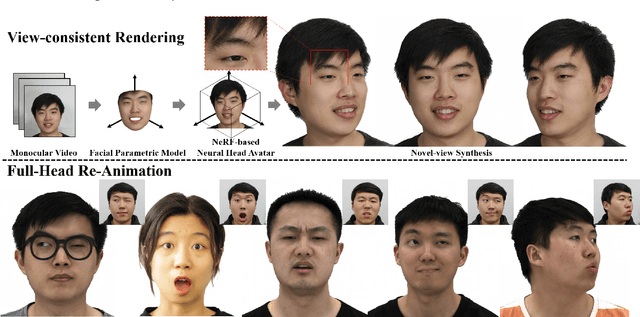

The problem of modeling an animatable 3D human head avatar under light-weight setups is of significant importance but has not been well solved. Existing 3D representations either perform well in the realism of portrait images synthesis or the accuracy of expression control, but not both. To address the problem, we introduce a novel hybrid explicit-implicit 3D representation, Facial Model Conditioned Neural Radiance Field, which integrates the expressiveness of NeRF and the prior information from the parametric template. At the core of our representation, a synthetic-renderings-based condition method is proposed to fuse the prior information from the parametric model into the implicit field without constraining its topological flexibility. Besides, based on the hybrid representation, we properly overcome the inconsistent shape issue presented in existing methods and improve the animation stability. Moreover, by adopting an overall GAN-based architecture using an image-to-image translation network, we achieve high-resolution, realistic and view-consistent synthesis of dynamic head appearance. Experiments demonstrate that our method can achieve state-of-the-art performance for 3D head avatar animation compared with previous methods.
Leveraging Intrinsic Properties for Non-Rigid Garment Alignment
Aug 18, 2023
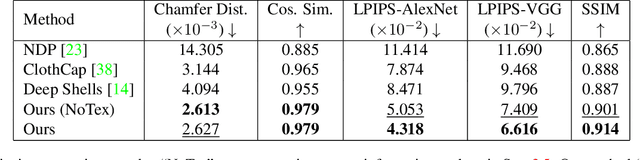


We address the problem of aligning real-world 3D data of garments, which benefits many applications such as texture learning, physical parameter estimation, generative modeling of garments, etc. Existing extrinsic methods typically perform non-rigid iterative closest point and struggle to align details due to incorrect closest matches and rigidity constraints. While intrinsic methods based on functional maps can produce high-quality correspondences, they work under isometric assumptions and become unreliable for garment deformations which are highly non-isometric. To achieve wrinkle-level as well as texture-level alignment, we present a novel coarse-to-fine two-stage method that leverages intrinsic manifold properties with two neural deformation fields, in the 3D space and the intrinsic space, respectively. The coarse stage performs a 3D fitting, where we leverage intrinsic manifold properties to define a manifold deformation field. The coarse fitting then induces a functional map that produces an alignment of intrinsic embeddings. We further refine the intrinsic alignment with a second neural deformation field for higher accuracy. We evaluate our method with our captured garment dataset, GarmCap. The method achieves accurate wrinkle-level and texture-level alignment and works for difficult garment types such as long coats. Our project page is https://jsnln.github.io/iccv2023_intrinsic/index.html.