 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuizhi Shao
Ins-HOI: Instance Aware Human-Object Interactions Recovery
Dec 15, 2023
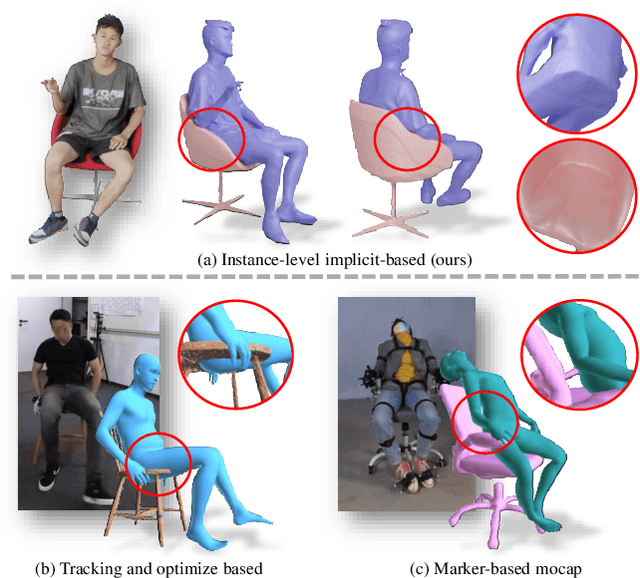
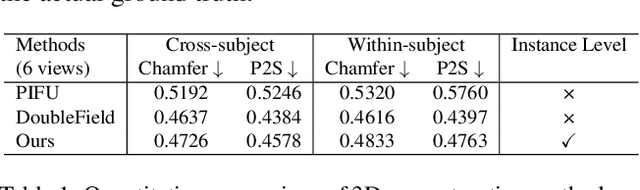


Recovering detailed interactions between humans/hands and objects is an appealing yet challenging task. Existing methods typically use template-based representations to track human/hand and objects in interactions. Despite the progress, they fail to handle the invisible contact surfaces. In this paper, we propose Ins-HOI, an end-to-end solution to recover human/hand-object reconstruction via instance-level implicit reconstruction. To this end, we introduce an instance-level occupancy field to support simultaneous human/hand and object representation, and a complementary training strategy to handle the lack of instance-level ground truths. Such a representation enables learning a contact prior implicitly from sparse observations. During the complementary training, we augment the real-captured data with synthesized data by randomly composing individual scans of humans/hands and objects and intentionally allowing for penetration. In this way, our network learns to recover individual shapes as completely as possible from the synthesized data, while being aware of the contact constraints and overall reasonability based on real-captured scans. As demonstrated in experiments, our method Ins-HOI can produce reasonable and realistic non-visible contact surfaces even in cases of extremely close interaction. To facilitate the research of this task, we collect a large-scale, high-fidelity 3D scan dataset, including 5.2k high-quality scans with real-world human-chair and hand-object interactions. We will release our dataset and source codes. Data examples and the video results of our method can be found on the project page.
HumanCoser: Layered 3D Human Generation via Semantic-Aware Diffusion Model
Dec 10, 2023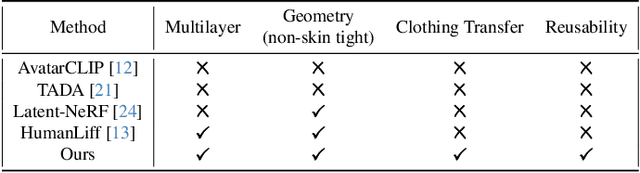
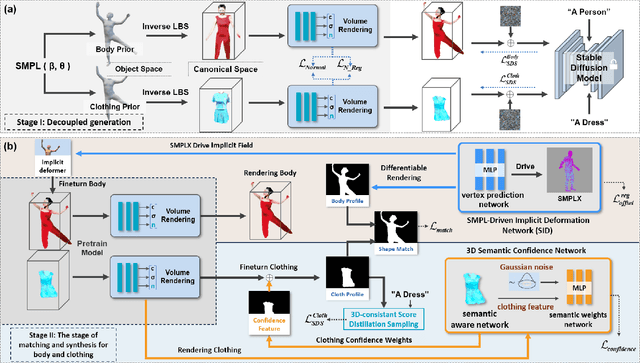
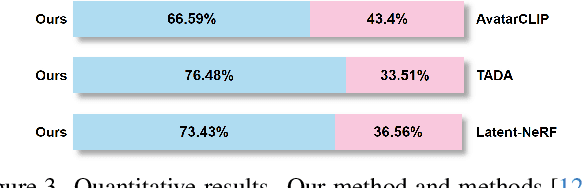
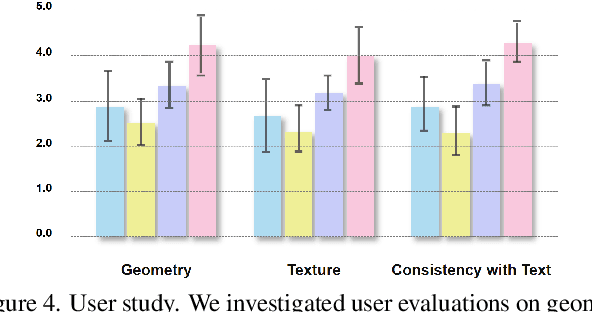
The generation of 3D clothed humans has attracted increasing attention in recent years. However, existing work cannot generate layered high-quality 3D humans with consistent body structures. As a result, these methods are unable to arbitrarily and separately change and edit the body and clothing of the human. In this paper, we propose a text-driven layered 3D human generation framework based on a novel physically-decoupled semantic-aware diffusion model. To keep the generated clothing consistent with the target text, we propose a semantic-confidence strategy for clothing that can eliminate the non-clothing content generated by the model. To match the clothing with different body shapes, we propose a SMPL-driven implicit field deformation network that enables the free transfer and reuse of clothing. Besides, we introduce uniform shape priors based on the SMPL model for body and clothing, respectively, which generates more diverse 3D content without being constrained by specific templates. The experimental results demonstrate that the proposed method not only generates 3D humans with consistent body structures but also allows free editing in a layered manner. The source code will be made public.
GPS-Gaussian: Generalizable Pixel-wise 3D Gaussian Splatting for Real-time Human Novel View Synthesis
Dec 04, 2023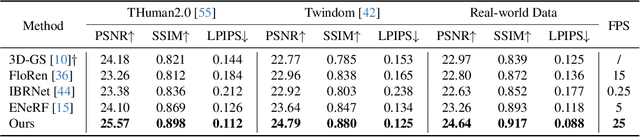
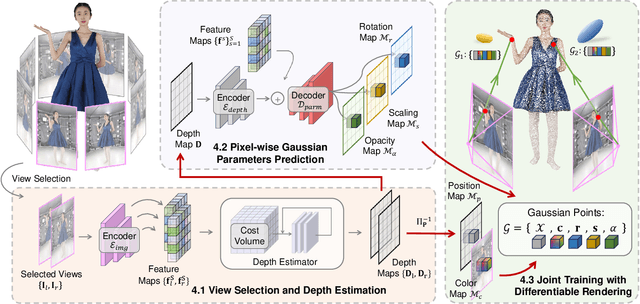
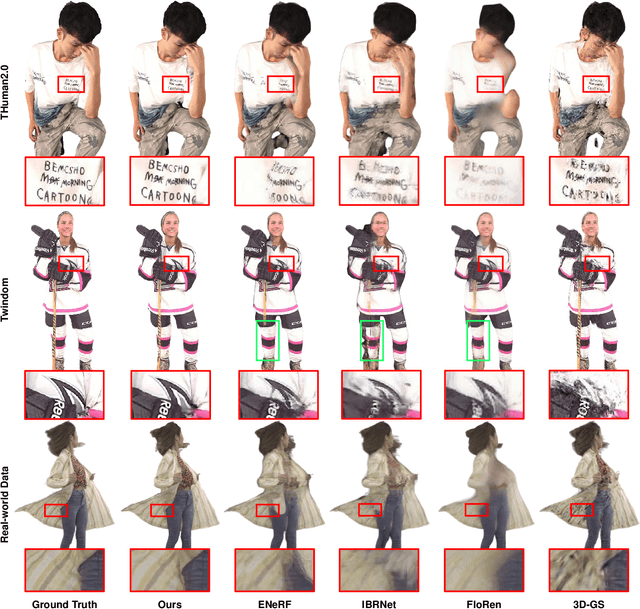
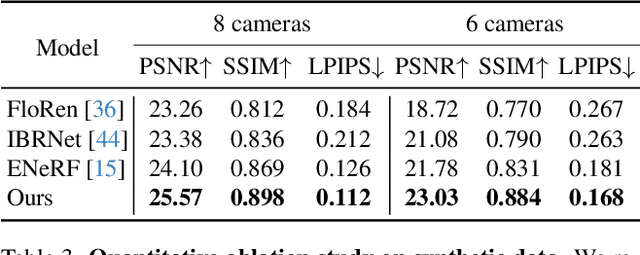
We present a new approach, termed GPS-Gaussian, for synthesizing novel views of a character in a real-time manner. The proposed method enables 2K-resolution rendering under a sparse-view camera setting. Unlike the original Gaussian Splatting or neural implicit rendering methods that necessitate per-subject optimizations, we introduce Gaussian parameter maps defined on the source views and regress directly Gaussian Splatting properties for instant novel view synthesis without any fine-tuning or optimization. To this end, we train our Gaussian parameter regression module on a large amount of human scan data, jointly with a depth estimation module to lift 2D parameter maps to 3D space. The proposed framework is fully differentiable and experiments on several datasets demonstrate that our method outperforms state-of-the-art methods while achieving an exceeding rendering speed.
DreamCraft3D: Hierarchical 3D Generation with Bootstrapped Diffusion Prior
Oct 26, 2023We present DreamCraft3D, a hierarchical 3D content generation method that produces high-fidelity and coherent 3D objects. We tackle the problem by leveraging a 2D reference image to guide the stages of geometry sculpting and texture boosting. A central focus of this work is to address the consistency issue that existing works encounter. To sculpt geometries that render coherently, we perform score distillation sampling via a view-dependent diffusion model. This 3D prior, alongside several training strategies, prioritizes the geometry consistency but compromises the texture fidelity. We further propose Bootstrapped Score Distillation to specifically boost the texture. We train a personalized diffusion model, Dreambooth, on the augmented renderings of the scene, imbuing it with 3D knowledge of the scene being optimized. The score distillation from this 3D-aware diffusion prior provides view-consistent guidance for the scene. Notably, through an alternating optimization of the diffusion prior and 3D scene representation, we achieve mutually reinforcing improvements: the optimized 3D scene aids in training the scene-specific diffusion model, which offers increasingly view-consistent guidance for 3D optimization. The optimization is thus bootstrapped and leads to substantial texture boosting. With tailored 3D priors throughout the hierarchical generation, DreamCraft3D generates coherent 3D objects with photorealistic renderings, advancing the state-of-the-art in 3D content generation. Code available at https://github.com/deepseek-ai/DreamCraft3D.
HumanNorm: Learning Normal Diffusion Model for High-quality and Realistic 3D Human Generation
Oct 02, 2023
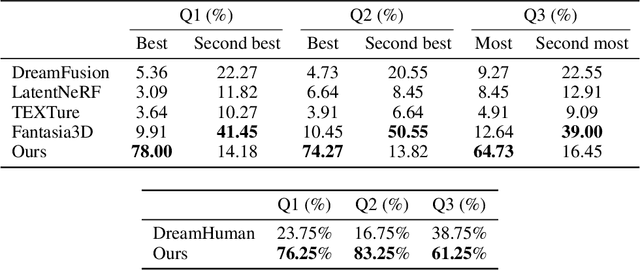

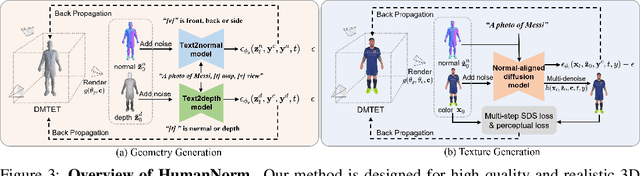
Recent text-to-3D methods employing diffusion models have made significant advancements in 3D human generation. However, these approaches face challenges due to the limitations of the text-to-image diffusion model, which lacks an understanding of 3D structures. Consequently, these methods struggle to achieve high-quality human generation, resulting in smooth geometry and cartoon-like appearances. In this paper, we observed that fine-tuning text-to-image diffusion models with normal maps enables their adaptation into text-to-normal diffusion models, which enhances the 2D perception of 3D geometry while preserving the priors learned from large-scale datasets. Therefore, we propose HumanNorm, a novel approach for high-quality and realistic 3D human generation by learning the normal diffusion model including a normal-adapted diffusion model and a normal-aligned diffusion model. The normal-adapted diffusion model can generate high-fidelity normal maps corresponding to prompts with view-dependent text. The normal-aligned diffusion model learns to generate color images aligned with the normal maps, thereby transforming physical geometry details into realistic appearance. Leveraging the proposed normal diffusion model, we devise a progressive geometry generation strategy and coarse-to-fine texture generation strategy to enhance the efficiency and robustness of 3D human generation. Comprehensive experiments substantiate our method's ability to generate 3D humans with intricate geometry and realistic appearances, significantly outperforming existing text-to-3D methods in both geometry and texture quality. The project page of HumanNorm is https://humannorm.github.io/.
Control4D: Dynamic Portrait Editing by Learning 4D GAN from 2D Diffusion-based Editor
May 31, 2023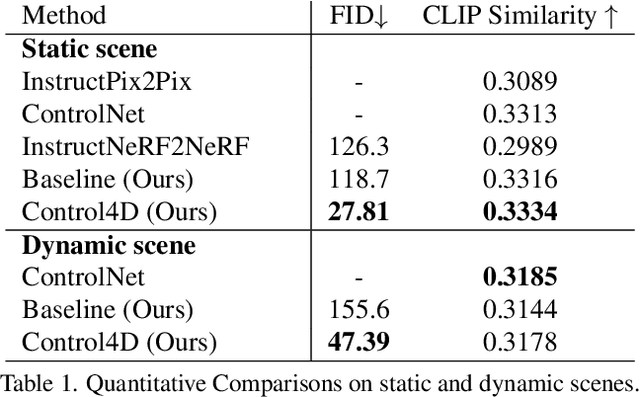
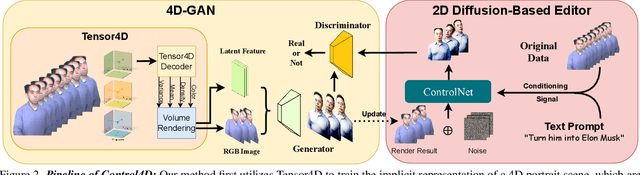
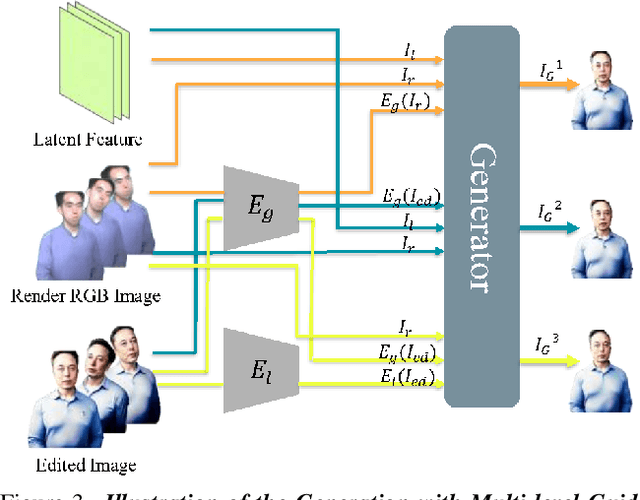

Recent years have witnessed considerable achievements in editing images with text instructions. When applying these editors to dynamic scene editing, the new-style scene tends to be temporally inconsistent due to the frame-by-frame nature of these 2D editors. To tackle this issue, we propose Control4D, a novel approach for high-fidelity and temporally consistent 4D portrait editing. Control4D is built upon an efficient 4D representation with a 2D diffusion-based editor. Instead of using direct supervisions from the editor, our method learns a 4D GAN from it and avoids the inconsistent supervision signals. Specifically, we employ a discriminator to learn the generation distribution based on the edited images and then update the generator with the discrimination signals. For more stable training, multi-level information is extracted from the edited images and used to facilitate the learning of the generator. Experimental results show that Control4D surpasses previous approaches and achieves more photo-realistic and consistent 4D editing performances. The link to our project website is https://control4darxiv.github.io.
CloSET: Modeling Clothed Humans on Continuous Surface with Explicit Template Decomposition
Apr 06, 2023



Creating animatable avatars from static scans requires the modeling of clothing deformations in different poses. Existing learning-based methods typically add pose-dependent deformations upon a minimally-clothed mesh template or a learned implicit template, which have limitations in capturing details or hinder end-to-end learning. In this paper, we revisit point-based solutions and propose to decompose explicit garment-related templates and then add pose-dependent wrinkles to them. In this way, the clothing deformations are disentangled such that the pose-dependent wrinkles can be better learned and applied to unseen poses. Additionally, to tackle the seam artifact issues in recent state-of-the-art point-based methods, we propose to learn point features on a body surface, which establishes a continuous and compact feature space to capture the fine-grained and pose-dependent clothing geometry. To facilitate the research in this field, we also introduce a high-quality scan dataset of humans in real-world clothing. Our approach is validated on two existing datasets and our newly introduced dataset, showing better clothing deformation results in unseen poses. The project page with code and dataset can be found at https://www.liuyebin.com/closet.
Tensor4D : Efficient Neural 4D Decomposition for High-fidelity Dynamic Reconstruction and Rendering
Nov 21, 2022



We present Tensor4D, an efficient yet effective approach to dynamic scene modeling. The key of our solution is an efficient 4D tensor decomposition method so that the dynamic scene can be directly represented as a 4D spatio-temporal tensor. To tackle the accompanying memory issue, we decompose the 4D tensor hierarchically by projecting it first into three time-aware volumes and then nine compact feature planes. In this way, spatial information over time can be simultaneously captured in a compact and memory-efficient manner. When applying Tensor4D for dynamic scene reconstruction and rendering, we further factorize the 4D fields to different scales in the sense that structural motions and dynamic detailed changes can be learned from coarse to fine. The effectiveness of our method is validated on both synthetic and real-world scenes. Extensive experiments show that our method is able to achieve high-quality dynamic reconstruction and rendering from sparse-view camera rigs or even a monocular camera. The code and dataset will be released at https://liuyebin.com/tensor4d/tensor4d.html.
DiffuStereo: High Quality Human Reconstruction via Diffusion-based Stereo Using Sparse Cameras
Jul 20, 2022



We propose DiffuStereo, a novel system using only sparse cameras (8 in this work) for high-quality 3D human reconstruction. At its core is a novel diffusion-based stereo module, which introduces diffusion models, a type of powerful generative models, into the iterative stereo matching network. To this end, we design a new diffusion kernel and additional stereo constraints to facilitate stereo matching and depth estimation in the network. We further present a multi-level stereo network architecture to handle high-resolution (up to 4k) inputs without requiring unaffordable memory footprint. Given a set of sparse-view color images of a human, the proposed multi-level diffusion-based stereo network can produce highly accurate depth maps, which are then converted into a high-quality 3D human model through an efficient multi-view fusion strategy. Overall, our method enables automatic reconstruction of human models with quality on par to high-end dense-view camera rigs, and this is achieved using a much more light-weight hardware setup. Experiments show that our method outperforms state-of-the-art methods by a large margin both qualitatively and quantitatively.
Learning Implicit Templates for Point-Based Clothed Human Modeling
Jul 14, 2022



We present FITE, a First-Implicit-Then-Explicit framework for modeling human avatars in clothing. Our framework first learns implicit surface templates representing the coarse clothing topology, and then employs the templates to guide the generation of point sets which further capture pose-dependent clothing deformations such as wrinkles. Our pipeline incorporates the merits of both implicit and explicit representations, namely, the ability to handle varying topology and the ability to efficiently capture fine details. We also propose diffused skinning to facilitate template training especially for loose clothing, and projection-based pose-encoding to extract pose information from mesh templates without predefined UV map or connectivity. Our code is publicly available at https://github.com/jsnln/fite.