 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChen Xu
A Taxation Perspective for Fair Re-ranking
Apr 27, 2024
Fair re-ranking aims to redistribute ranking slots among items more equitably to ensure responsibility and ethics. The exploration of redistribution problems has a long history in economics, offering valuable insights for conceptualizing fair re-ranking as a taxation process. Such a formulation provides us with a fresh perspective to re-examine fair re-ranking and inspire the development of new methods. From a taxation perspective, we theoretically demonstrate that most previous fair re-ranking methods can be reformulated as an item-level tax policy. Ideally, a good tax policy should be effective and conveniently controllable to adjust ranking resources. However, both empirical and theoretical analyses indicate that the previous item-level tax policy cannot meet two ideal controllable requirements: (1) continuity, ensuring minor changes in tax rates result in small accuracy and fairness shifts; (2) controllability over accuracy loss, ensuring precise estimation of the accuracy loss under a specific tax rate. To overcome these challenges, we introduce a new fair re-ranking method named Tax-rank, which levies taxes based on the difference in utility between two items. Then, we efficiently optimize such an objective by utilizing the Sinkhorn algorithm in optimal transport. Upon a comprehensive analysis, Our model Tax-rank offers a superior tax policy for fair re-ranking, theoretically demonstrating both continuity and controllability over accuracy loss. Experimental results show that Tax-rank outperforms all state-of-the-art baselines in terms of effectiveness and efficiency on recommendation and advertising tasks.
Beyond Traditional Threats: A Persistent Backdoor Attack on Federated Learning
Apr 26, 2024Backdoors on federated learning will be diluted by subsequent benign updates. This is reflected in the significant reduction of attack success rate as iterations increase, ultimately failing. We use a new metric to quantify the degree of this weakened backdoor effect, called attack persistence. Given that research to improve this performance has not been widely noted,we propose a Full Combination Backdoor Attack (FCBA) method. It aggregates more combined trigger information for a more complete backdoor pattern in the global model. Trained backdoored global model is more resilient to benign updates, leading to a higher attack success rate on the test set. We test on three datasets and evaluate with two models across various settings. FCBA's persistence outperforms SOTA federated learning backdoor attacks. On GTSRB, postattack 120 rounds, our attack success rate rose over 50% from baseline. The core code of our method is available at https://github.com/PhD-TaoLiu/FCBA.
Accelerating Image Generation with Sub-path Linear Approximation Model
Apr 23, 2024Diffusion models have significantly advanced the state of the art in image, audio, and video generation tasks. However, their applications in practical scenarios are hindered by slow inference speed. Drawing inspiration from the approximation strategies utilized in consistency models, we propose the Sub-path Linear Approximation Model (SLAM), which accelerates diffusion models while maintaining high-quality image generation. SLAM treats the PF-ODE trajectory as a series of PF-ODE sub-paths divided by sampled points, and harnesses sub-path linear (SL) ODEs to form a progressive and continuous error estimation along each individual PF-ODE sub-path. The optimization on such SL-ODEs allows SLAM to construct denoising mappings with smaller cumulative approximated errors. An efficient distillation method is also developed to facilitate the incorporation of more advanced diffusion models, such as latent diffusion models. Our extensive experimental results demonstrate that SLAM achieves an efficient training regimen, requiring only 6 A100 GPU days to produce a high-quality generative model capable of 2 to 4-step generation with high performance. Comprehensive evaluations on LAION, MS COCO 2014, and MS COCO 2017 datasets also illustrate that SLAM surpasses existing acceleration methods in few-step generation tasks, achieving state-of-the-art performance both on FID and the quality of the generated images.
Unifying Bias and Unfairness in Information Retrieval: A Survey of Challenges and Opportunities with Large Language Models
Apr 17, 2024With the rapid advancement of large language models (LLMs), information retrieval (IR) systems, such as search engines and recommender systems, have undergone a significant paradigm shift. This evolution, while heralding new opportunities, introduces emerging challenges, particularly in terms of biases and unfairness, which may threaten the information ecosystem. In this paper, we present a comprehensive survey of existing works on emerging and pressing bias and unfairness issues in IR systems when the integration of LLMs. We first unify bias and unfairness issues as distribution mismatch problems, providing a groundwork for categorizing various mitigation strategies through distribution alignment. Subsequently, we systematically delve into the specific bias and unfairness issues arising from three critical stages of LLMs integration into IR systems: data collection, model development, and result evaluation. In doing so, we meticulously review and analyze recent literature, focusing on the definitions, characteristics, and corresponding mitigation strategies associated with these issues. Finally, we identify and highlight some open problems and challenges for future work, aiming to inspire researchers and stakeholders in the IR field and beyond to better understand and mitigate bias and unfairness issues of IR in this LLM era. We also consistently maintain a GitHub repository for the relevant papers and resources in this rising direction at https://github.com/KID-22/LLM-IR-Bias-Fairness-Survey.
Conformal prediction for multi-dimensional time series by ellipsoidal sets
Mar 06, 2024
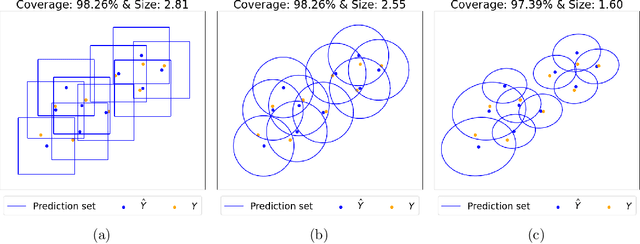
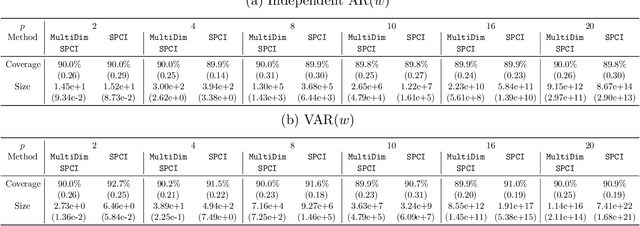

Conformal prediction (CP) has been a popular method for uncertainty quantification because it is distribution-free, model-agnostic, and theoretically sound. For forecasting problems in supervised learning, most CP methods focus on building prediction intervals for univariate responses. In this work, we develop a sequential CP method called $\texttt{MultiDimSPCI}$ that builds prediction regions for a multivariate response, especially in the context of multivariate time series, which are not exchangeable. Theoretically, we estimate finite-sample high-probability bounds on the conditional coverage gap. Empirically, we demonstrate that $\texttt{MultiDimSPCI}$ maintains valid coverage on a wide range of multivariate time series while producing smaller prediction regions than CP and non-CP baselines.
DECIDER: A Rule-Controllable Decoding Strategy for Language Generation by Imitating Dual-System Cognitive Theory
Mar 04, 2024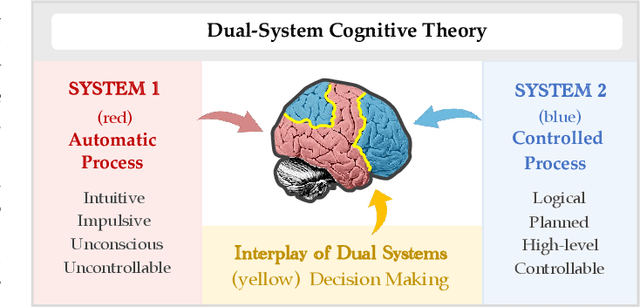
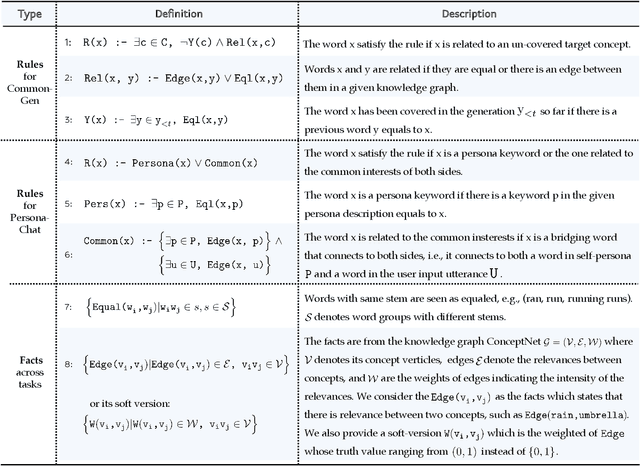
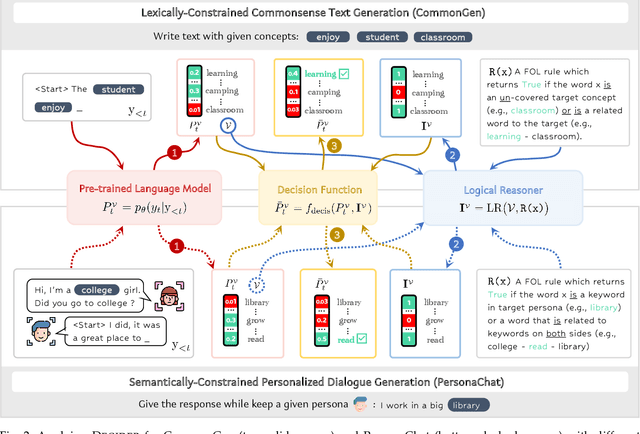
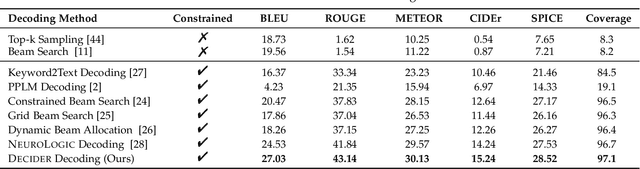
Lexicon-based constrained decoding approaches aim to control the meaning or style of the generated text through certain target concepts. Existing approaches over-focus the targets themselves, leading to a lack of high-level reasoning about how to achieve them. However, human usually tackles tasks by following certain rules that not only focuses on the targets but also on semantically relevant concepts that induce the occurrence of targets. In this work, we present DECIDER, a rule-controllable decoding strategy for constrained language generation inspired by dual-system cognitive theory. Specifically, in DECIDER, a pre-trained language model (PLM) is equiped with a logic reasoner that takes high-level rules as input. Then, the DECIDER allows rule signals to flow into the PLM at each decoding step. Extensive experimental results demonstrate that DECIDER can effectively follow given rules to guide generation direction toward the targets in a more human-like manner.
CriticBench: Evaluating Large Language Models as Critic
Feb 23, 2024Critique ability are crucial in the scalable oversight and self-improvement of Large Language Models (LLMs). While many recent studies explore the critique ability of LLMs to judge and refine flaws in generations, how to comprehensively and reliably measure the critique abilities of LLMs is under-explored. This paper introduces CriticBench, a novel benchmark designed to comprehensively and reliably evaluate four key critique ability dimensions of LLMs: feedback, comparison, refinement and meta-feedback. CriticBench encompasses nine diverse tasks, each assessing the LLMs' ability to critique responses at varying levels of quality granularity. Our extensive evaluations of open-source and closed-source LLMs reveal intriguing relationships between the critique ability and tasks, response qualities, and model scales. Datasets, resources and evaluation toolkit for CriticBench will be publicly released at https://github.com/open-compass/CriticBench.
LLM-based Federated Recommendation
Feb 17, 2024Large Language Models (LLMs), with their advanced contextual understanding abilities, have demonstrated considerable potential in enhancing recommendation systems via fine-tuning methods. However, fine-tuning requires users' behavior data, which poses considerable privacy risks due to the incorporation of sensitive user information. The unintended disclosure of such data could infringe upon data protection laws and give rise to ethical issues. To mitigate these privacy issues, Federated Learning for Recommendation (Fed4Rec) has emerged as a promising approach. Nevertheless, applying Fed4Rec to LLM-based recommendation presents two main challenges: first, an increase in the imbalance of performance across clients, affecting the system's efficiency over time, and second, a high demand on clients' computational and storage resources for local training and inference of LLMs. To address these challenges, we introduce a Privacy-Preserving LLM-based Recommendation (PPLR) framework. The PPLR framework employs two primary strategies. First, it implements a dynamic balance strategy, which involves the design of dynamic parameter aggregation and adjustment of learning speed for different clients during the training phase, to ensure relatively balanced performance across all clients. Second, PPLR adopts a flexible storage strategy, selectively retaining certain sensitive layers of the language model on the client side while offloading non-sensitive layers to the server. This approach aims to preserve user privacy while efficiently saving computational and storage resources. Experimental results demonstrate that PPLR not only achieves a balanced performance among clients but also enhances overall system performance in a manner that is both computationally and storage-efficient, while effectively protecting user privacy.
FairSync: Ensuring Amortized Group Exposure in Distributed Recommendation Retrieval
Feb 16, 2024In pursuit of fairness and balanced development, recommender systems (RS) often prioritize group fairness, ensuring that specific groups maintain a minimum level of exposure over a given period. For example, RS platforms aim to ensure adequate exposure for new providers or specific categories of items according to their needs. Modern industry RS usually adopts a two-stage pipeline: stage-1 (retrieval stage) retrieves hundreds of candidates from millions of items distributed across various servers, and stage-2 (ranking stage) focuses on presenting a small-size but accurate selection from items chosen in stage-1. Existing efforts for ensuring amortized group exposures focus on stage-2, however, stage-1 is also critical for the task. Without a high-quality set of candidates, the stage-2 ranker cannot ensure the required exposure of groups. Previous fairness-aware works designed for stage-2 typically require accessing and traversing all items. In stage-1, however, millions of items are distributively stored in servers, making it infeasible to traverse all of them. How to ensure group exposures in the distributed retrieval process is a challenging question. To address this issue, we introduce a model named FairSync, which transforms the problem into a constrained distributed optimization problem. Specifically, FairSync resolves the issue by moving it to the dual space, where a central node aggregates historical fairness data into a vector and distributes it to all servers. To trade off the efficiency and accuracy, the gradient descent technique is used to periodically update the parameter of the dual vector. The experiment results on two public recommender retrieval datasets showcased that FairSync outperformed all the baselines, achieving the desired minimum level of exposures while maintaining a high level of retrieval accuracy.
Soft Alignment of Modality Space for End-to-end Speech Translation
Dec 18, 2023End-to-end Speech Translation (ST) aims to convert speech into target text within a unified model. The inherent differences between speech and text modalities often impede effective cross-modal and cross-lingual transfer. Existing methods typically employ hard alignment (H-Align) of individual speech and text segments, which can degrade textual representations. To address this, we introduce Soft Alignment (S-Align), using adversarial training to align the representation spaces of both modalities. S-Align creates a modality-invariant space while preserving individual modality quality. Experiments on three languages from the MuST-C dataset show S-Align outperforms H-Align across multiple tasks and offers translation capabilities on par with specialized translation models.