 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWei Bi
DECIDER: A Rule-Controllable Decoding Strategy for Language Generation by Imitating Dual-System Cognitive Theory
Mar 04, 2024
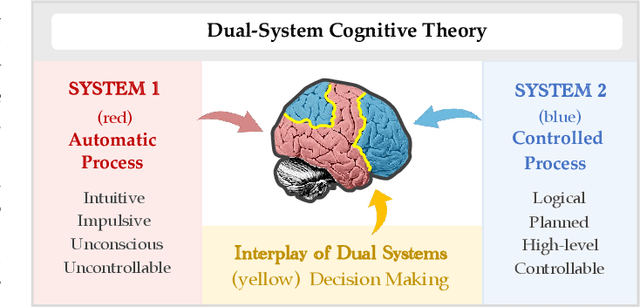
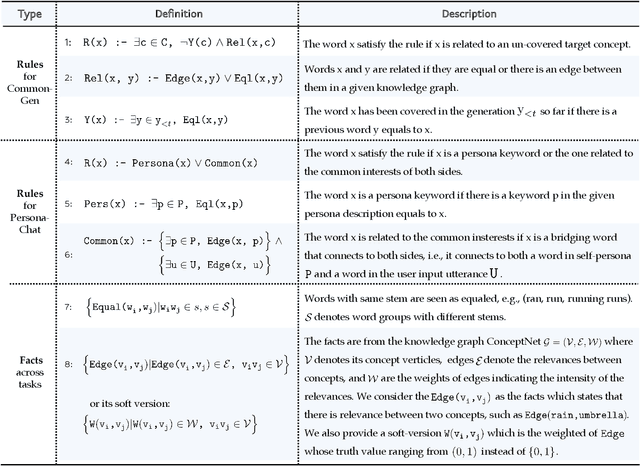
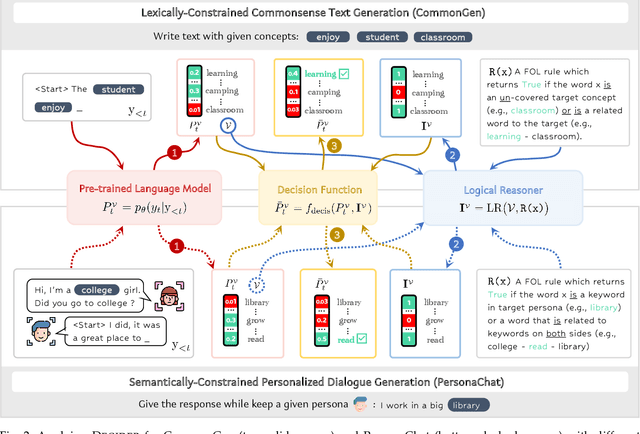
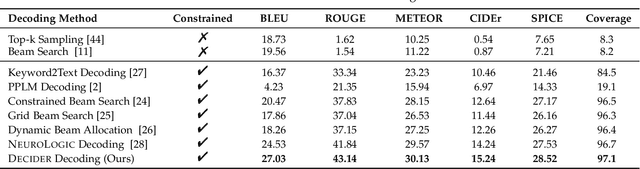
Lexicon-based constrained decoding approaches aim to control the meaning or style of the generated text through certain target concepts. Existing approaches over-focus the targets themselves, leading to a lack of high-level reasoning about how to achieve them. However, human usually tackles tasks by following certain rules that not only focuses on the targets but also on semantically relevant concepts that induce the occurrence of targets. In this work, we present DECIDER, a rule-controllable decoding strategy for constrained language generation inspired by dual-system cognitive theory. Specifically, in DECIDER, a pre-trained language model (PLM) is equiped with a logic reasoner that takes high-level rules as input. Then, the DECIDER allows rule signals to flow into the PLM at each decoding step. Extensive experimental results demonstrate that DECIDER can effectively follow given rules to guide generation direction toward the targets in a more human-like manner.
FuseChat: Knowledge Fusion of Chat Models
Mar 03, 2024While training large language models (LLMs) from scratch can indeed lead to models with distinct capabilities and strengths, this approach incurs substantial costs and may lead to potential redundancy in competencies. An alternative strategy is to combine existing LLMs into a more robust LLM, thereby diminishing the necessity for expensive pre-training. However, due to the diverse architectures of LLMs, direct parameter blending proves to be unfeasible. Recently, \textsc{FuseLLM} introduced the concept of knowledge fusion to transfer the collective knowledge of multiple structurally varied LLMs into a target LLM through lightweight continual training. In this report, we extend the scalability and flexibility of the \textsc{FuseLLM} framework to realize the fusion of chat LLMs, resulting in \textsc{FuseChat}. \textsc{FuseChat} comprises two main stages. Firstly, we undertake knowledge fusion for structurally and scale-varied source LLMs to derive multiple target LLMs of identical structure and size via lightweight fine-tuning. Then, these target LLMs are merged within the parameter space, wherein we propose a novel method for determining the merging weights based on the variation ratio of parameter matrices before and after fine-tuning. We validate our approach using three prominent chat LLMs with diverse architectures and scales, namely \texttt{NH2-Mixtral-8x7B}, \texttt{NH2-Solar-10.7B}, and \texttt{OpenChat-3.5-7B}. Experimental results spanning various chat domains demonstrate the superiority of \texttt{\textsc{FuseChat}-7B} across a broad spectrum of chat LLMs at 7B and 34B scales, even surpassing \texttt{GPT-3.5 (March)} and approaching \texttt{Mixtral-8x7B-Instruct}. Our code, model weights, and data are openly accessible at \url{https://github.com/fanqiwan/FuseLLM}.
Retrieval is Accurate Generation
Feb 29, 2024Standard language models generate text by selecting tokens from a fixed, finite, and standalone vocabulary. We introduce a novel method that selects context-aware phrases from a collection of supporting documents. One of the most significant challenges for this paradigm shift is determining the training oracles, because a string of text can be segmented in various ways and each segment can be retrieved from numerous possible documents. To address this, we propose to initialize the training oracles using linguistic heuristics and, more importantly, bootstrap the oracles through iterative self-reinforcement. Extensive experiments show that our model not only outperforms standard language models on a variety of knowledge-intensive tasks but also demonstrates improved generation quality in open-ended text generation. For instance, compared to the standard language model counterpart, our model raises the accuracy from 23.47% to 36.27% on OpenbookQA, and improves the MAUVE score from 42.61% to 81.58% in open-ended text generation. Remarkably, our model also achieves the best performance and the lowest latency among several retrieval-augmented baselines. In conclusion, we assert that retrieval is more accurate generation and hope that our work will encourage further research on this new paradigm shift.
GSM-Plus: A Comprehensive Benchmark for Evaluating the Robustness of LLMs as Mathematical Problem Solvers
Feb 29, 2024Large language models (LLMs) have achieved impressive performance across various mathematical reasoning benchmarks. However, there are increasing debates regarding whether these models truly understand and apply mathematical knowledge or merely rely on shortcuts for mathematical reasoning. One essential and frequently occurring evidence is that when the math questions are slightly changed, LLMs can behave incorrectly. This motivates us to evaluate the robustness of LLMs' math reasoning capability by testing a wide range of question variations. We introduce the adversarial grade school math (\datasetname) dataset, an extension of GSM8K augmented with various mathematical perturbations. Our experiments on 25 LLMs and 4 prompting techniques show that while LLMs exhibit different levels of math reasoning abilities, their performances are far from robust. In particular, even for problems that have been solved in GSM8K, LLMs can make mistakes when new statements are added or the question targets are altered. We also explore whether more robust performance can be achieved by composing existing prompting methods, in which we try an iterative method that generates and verifies each intermediate thought based on its reasoning goal and calculation result. Code and data are available at \url{https://github.com/qtli/GSM-Plus}.
BBA: Bi-Modal Behavioral Alignment for Reasoning with Large Vision-Language Models
Feb 21, 2024Multimodal reasoning stands as a pivotal capability for large vision-language models (LVLMs). The integration with Domain-Specific Languages (DSL), offering precise visual representations, equips these models with the opportunity to execute more accurate reasoning in complex and professional domains. However, the vanilla Chain-of-Thought (CoT) prompting method faces challenges in effectively leveraging the unique strengths of visual and DSL representations, primarily due to their differing reasoning mechanisms. Additionally, it often falls short in addressing critical steps in multi-step reasoning tasks. To mitigate these challenges, we introduce the \underline{B}i-Modal \underline{B}ehavioral \underline{A}lignment (BBA) prompting method, designed to maximize the potential of DSL in augmenting complex multi-modal reasoning tasks. This method initiates by guiding LVLMs to create separate reasoning chains for visual and DSL representations. Subsequently, it aligns these chains by addressing any inconsistencies, thus achieving a cohesive integration of behaviors from different modalities. Our experiments demonstrate that BBA substantially improves the performance of GPT-4V(ision) on geometry problem solving ($28.34\% \to 34.22\%$), chess positional advantage prediction ($42.08\% \to 46.99\%$) and molecular property prediction ($77.47\% \to 83.52\%$).
Diffusion of Thoughts: Chain-of-Thought Reasoning in Diffusion Language Models
Feb 12, 2024Diffusion models have gained attention in text processing, offering many potential advantages over traditional autoregressive models. This work explores the integration of diffusion models and Chain-of-Thought (CoT), a well-established technique to improve the reasoning ability in autoregressive language models. We propose Diffusion-of-Thought (DoT), allowing reasoning steps to diffuse over time through the diffusion process. In contrast to traditional autoregressive language models that make decisions in a left-to-right, token-by-token manner, DoT offers more flexibility in the trade-off between computation and reasoning performance. Our experimental results demonstrate the effectiveness of DoT in multi-digit multiplication and grade school math problems. Additionally, DoT showcases promising self-correction abilities and benefits from existing reasoning-enhancing techniques like self-consistency decoding. Our findings contribute to the understanding and development of reasoning capabilities in diffusion language models.
Mitigating Hallucinations of Large Language Models via Knowledge Consistent Alignment
Jan 28, 2024While Large Language Models (LLMs) have proven to be exceptional on a variety of tasks after alignment, they may still produce responses that contradict the context or world knowledge confidently, a phenomenon known as ``hallucination''. In this paper, we demonstrate that reducing the inconsistency between the external knowledge encapsulated in the training data and the intrinsic knowledge inherited in the pretraining corpus could mitigate hallucination in alignment. Specifically, we introduce a novel knowledge consistent alignment (KCA) approach, which involves automatically formulating examinations based on external knowledge for accessing the comprehension of LLMs. For data encompassing knowledge inconsistency, KCA implements several simple yet efficient strategies for processing. We illustrate the superior performance of the proposed KCA approach in mitigating hallucinations across six benchmarks using LLMs of different backbones and scales. Furthermore, we confirm the correlation between knowledge inconsistency and hallucination, signifying the effectiveness of reducing knowledge inconsistency in alleviating hallucinations. Our code, model weights, and data are public at \url{https://github.com/fanqiwan/KCA}.
Knowledge Fusion of Large Language Models
Jan 22, 2024While training large language models (LLMs) from scratch can generate models with distinct functionalities and strengths, it comes at significant costs and may result in redundant capabilities. Alternatively, a cost-effective and compelling approach is to merge existing pre-trained LLMs into a more potent model. However, due to the varying architectures of these LLMs, directly blending their weights is impractical. In this paper, we introduce the notion of knowledge fusion for LLMs, aimed at combining the capabilities of existing LLMs and transferring them into a single LLM. By leveraging the generative distributions of source LLMs, we externalize their collective knowledge and unique strengths, thereby potentially elevating the capabilities of the target model beyond those of any individual source LLM. We validate our approach using three popular LLMs with different architectures--Llama-2, MPT, and OpenLLaMA--across various benchmarks and tasks. Our findings confirm that the fusion of LLMs can improve the performance of the target model across a range of capabilities such as reasoning, commonsense, and code generation. Our code, model weights, and data are public at \url{https://github.com/fanqiwan/FuseLLM}.
Alleviating Hallucinations of Large Language Models through Induced Hallucinations
Dec 25, 2023Despite their impressive capabilities, large language models (LLMs) have been observed to generate responses that include inaccurate or fabricated information, a phenomenon commonly known as ``hallucination''. In this work, we propose a simple \textit{Induce-then-Contrast} Decoding (ICD) strategy to alleviate hallucinations. We first construct a factually weak LLM by inducing hallucinations from the original LLMs. Then, we penalize these induced hallucinations during decoding to enhance the factuality of the generated content. Concretely, we determine the final next-token predictions by amplifying the predictions from the original model and downplaying the induced untruthful predictions via contrastive decoding. Experimental results on both discrimination-based and generation-based hallucination evaluation benchmarks, such as TruthfulQA and \textsc{FActScore}, demonstrate that our proposed ICD methods can effectively enhance the factuality of LLMs across various model sizes and families. For example, when equipped with ICD, Llama2-7B-Chat and Mistral-7B-Instruct achieve performance comparable to ChatGPT and GPT4 on TruthfulQA, respectively.
TRAMS: Training-free Memory Selection for Long-range Language Modeling
Nov 05, 2023The Transformer architecture is crucial for numerous AI models, but it still faces challenges in long-range language modeling. Though several specific transformer architectures have been designed to tackle issues of long-range dependencies, existing methods like Transformer-XL are plagued by a high percentage of ineffective memories. In this study, we present a plug-and-play strategy, known as TRAining-free Memory Selection (TRAMS), that selects tokens participating in attention calculation based on one simple metric. This strategy allows us to keep tokens that are likely to have a high attention score with the current queries and ignore the other ones. We have tested our approach on the word-level benchmark (WikiText-103) and the character-level benchmark (enwik8), and the results indicate an improvement without having additional training or adding additional parameters.