 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiheng Chen
LoRA Meets Dropout under a Unified Framework
Feb 25, 2024
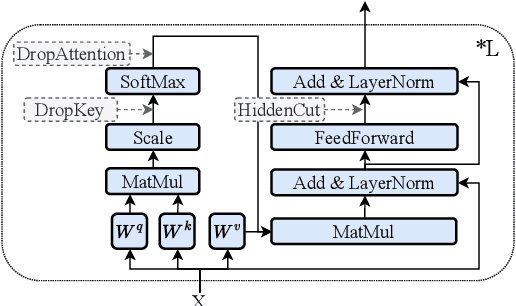
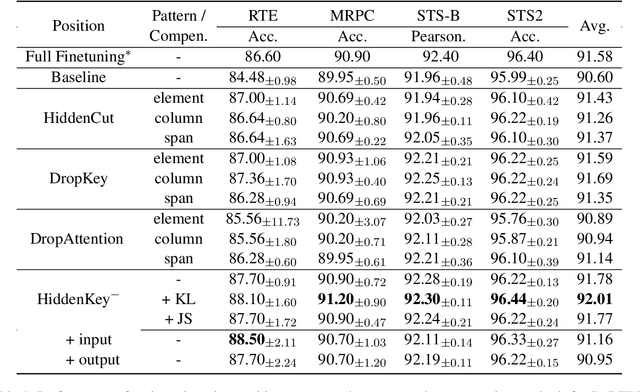
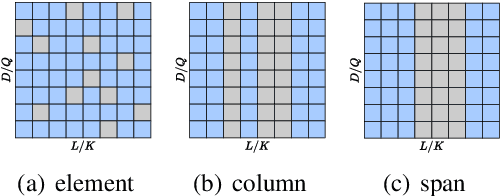
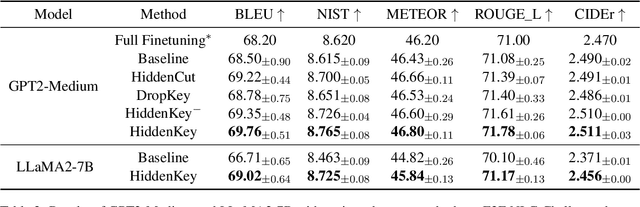
With the remarkable capabilities, large language models (LLMs) have emerged as essential elements in numerous NLP applications, while parameter-efficient finetuning, especially LoRA, has gained popularity as a lightweight approach for model customization. Meanwhile, various dropout methods, initially designed for full finetuning with all the parameters updated, alleviates overfitting associated with excessive parameter redundancy. Hence, a possible contradiction arises from negligible trainable parameters of LoRA and the effectiveness of previous dropout methods, which has been largely overlooked. To fill this gap, we first confirm that parameter-efficient LoRA is also overfitting-prone. We then revisit transformer-specific dropout methods, and establish their equivalence and distinctions mathematically and empirically. Building upon this comparative analysis, we introduce a unified framework for a comprehensive investigation, which instantiates these methods based on dropping position, structural pattern and compensation measure. Through this framework, we reveal the new preferences and performance comparisons of them when involved with limited trainable parameters. This framework also allows us to amalgamate the most favorable aspects into a novel dropout method named HiddenKey. Extensive experiments verify the remarkable superiority and sufficiency of HiddenKey across multiple models and tasks, which highlights it as the preferred approach for high-performance and parameter-efficient finetuning of LLMs.
PRoLoRA: Partial Rotation Empowers More Parameter-Efficient LoRA
Feb 24, 2024With the rapid scaling of large language models (LLMs), serving numerous LoRAs concurrently has become increasingly impractical, leading to unaffordable costs and necessitating more parameter-efficient finetuning methods. In this work, we introduce Partially Rotation-enhanced Low-Rank Adaptation (PRoLoRA), an intra-layer sharing mechanism comprising four essential components: broadcast reduction, rotation enhancement, partially-sharing refinement, and rectified initialization strategy. As a superset of LoRA, PRoLoRA pertains its advantages, and effectively circumvent the drawbacks of peer parameter-sharing methods with superior model capacity, practical feasibility, and broad applicability. Empirical experiments demonstrate the remarkably higher parameter efficiency of PRoLoRA in both specific parameter budget and performance target scenarios, and its scalability to larger LLMs. Notably, with one time less trainable parameters, PRoLoRA still outperforms LoRA on multiple instruction tuning datasets. Subsequently, an ablation study is conducted to validate the necessity of individual components and highlight the superiority of PRoLoRA over three potential variants. Hopefully, the conspicuously higher parameter efficiency can establish PRoLoRA as a resource-friendly alternative to LoRA.
Diffusion of Thoughts: Chain-of-Thought Reasoning in Diffusion Language Models
Feb 12, 2024Diffusion models have gained attention in text processing, offering many potential advantages over traditional autoregressive models. This work explores the integration of diffusion models and Chain-of-Thought (CoT), a well-established technique to improve the reasoning ability in autoregressive language models. We propose Diffusion-of-Thought (DoT), allowing reasoning steps to diffuse over time through the diffusion process. In contrast to traditional autoregressive language models that make decisions in a left-to-right, token-by-token manner, DoT offers more flexibility in the trade-off between computation and reasoning performance. Our experimental results demonstrate the effectiveness of DoT in multi-digit multiplication and grade school math problems. Additionally, DoT showcases promising self-correction abilities and benefits from existing reasoning-enhancing techniques like self-consistency decoding. Our findings contribute to the understanding and development of reasoning capabilities in diffusion language models.
Multi-Agent Determinantal Q-Learning
Jun 09, 2020



Centralized training with decentralized execution has become an important paradigm in multi-agent learning. Though practical, current methods rely on restrictive assumptions to decompose the centralized value function across agents for execution. In this paper, we eliminate this restriction by proposing multi-agent determinantal Q-learning. Our method is established on Q-DPP, an extension of determinantal point process (DPP) with partition-matroid constraint to multi-agent setting. Q-DPP promotes agents to acquire diverse behavioral models; this allows a natural factorization of the joint Q-functions with no need for \emph{a priori} structural constraints on the value function or special network architectures. We demonstrate that Q-DPP generalizes major solutions including VDN, QMIX, and QTRAN on decentralizable cooperative tasks. To efficiently draw samples from Q-DPP, we adopt an existing sample-by-projection sampler with theoretical approximation guarantee. The sampler also benefits exploration by coordinating agents to cover orthogonal directions in the state space during multi-agent training. We evaluate our algorithm on various cooperative benchmarks; its effectiveness has been demonstrated when compared with the state-of-the-art.
Signal Instructed Coordination in Team Competition
Sep 10, 2019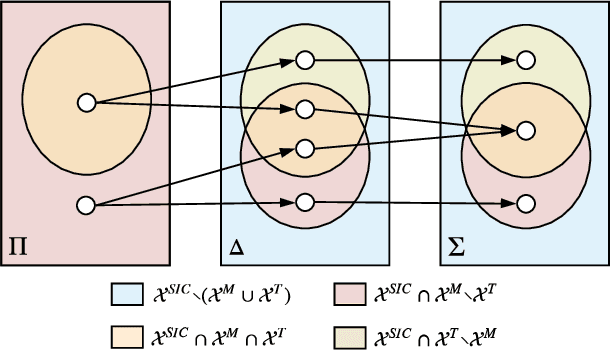

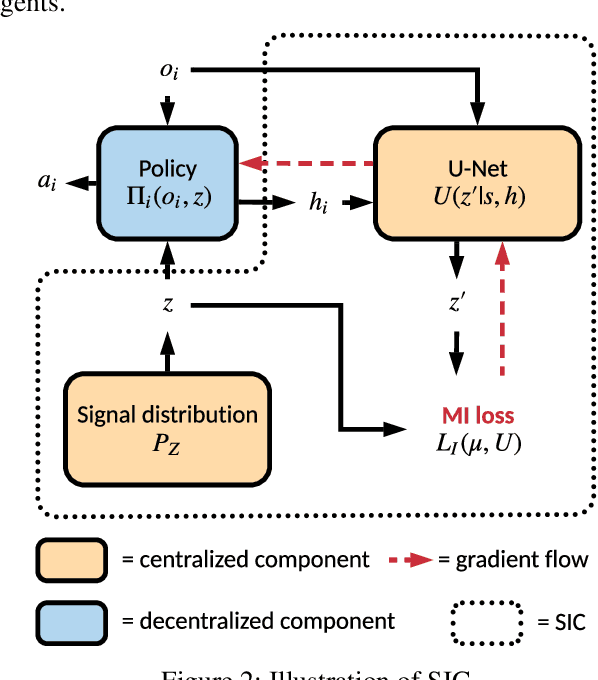

Most existing models of multi-agent reinforcement learning (MARL) adopt centralized training with decentralized execution framework. We demonstrate that the decentralized execution scheme restricts agents' capacity to find a better joint policy in team competition games, where each team of agents share the common rewards and cooperate to compete against other teams. To resolve this problem, we propose Signal Instructed Coordination (SIC), a novel coordination module that can be integrated with most existing models. SIC casts a common signal sampled from a pre-defined distribution to team members, and adopts an information-theoretic regularization to encourage agents to exploit in learning the instruction of centralized signals. Our experiments show that SIC can consistently improve team performance over well-recognized MARL models on matrix games and predator-prey games.
Triple-to-Text: Converting RDF Triples into High-Quality Natural Languages via Optimizing an Inverse KL Divergence
May 25, 2019



Knowledge base is one of the main forms to represent information in a structured way. A knowledge base typically consists of Resource Description Frameworks (RDF) triples which describe the entities and their relations. Generating natural language description of the knowledge base is an important task in NLP, which has been formulated as a conditional language generation task and tackled using the sequence-to-sequence framework. Current works mostly train the language models by maximum likelihood estimation, which tends to generate lousy sentences. In this paper, we argue that such a problem of maximum likelihood estimation is intrinsic, which is generally irrevocable via changing network structures. Accordingly, we propose a novel Triple-to-Text (T2T) framework, which approximately optimizes the inverse Kullback-Leibler (KL) divergence between the distributions of the real and generated sentences. Due to the nature that inverse KL imposes large penalty on fake-looking samples, the proposed method can significantly reduce the probability of generating low-quality sentences. Our experiments on three real-world datasets demonstrate that T2T can generate higher-quality sentences and outperform baseline models in several evaluation metrics.
TGE-PS: Text-driven Graph Embedding with Pairs Sampling
Sep 12, 2018



In graphs with rich text information, constructing expressive graph representations requires incorporating textual information with structural information. Graph embedding models are becoming more and more popular in representing graphs, yet they are faced with two issues: sampling efficiency and text utilization. Through analyzing existing models, we find their training objectives are composed of pairwise proximities, and there are large amounts of redundant node pairs in Random Walk-based methods. Besides, inferring graph structures directly from texts (also known as zero-shot scenario) is a problem that requires higher text utilization. To solve these problems, we propose a novel Text-driven Graph Embedding with Pairs Sampling (TGE-PS) framework. TGE-PS uses Pairs Sampling (PS) to generate training samples which reduces ~99% training samples and is competitive compared to Random Walk. TGE-PS uses Text-driven Graph Embedding (TGE) which adopts word- and character-level embeddings to generate node embeddings. We evaluate TGE-PS on several real-world datasets, and experimental results demonstrate that TGE-PS produces state-of-the-art results in traditional and zero-shot link prediction tasks.
Label-aware Double Transfer Learning for Cross-Specialty Medical Named Entity Recognition
Apr 28, 2018



We study the problem of named entity recognition (NER) from electronic medical records, which is one of the most fundamental and critical problems for medical text mining. Medical records which are written by clinicians from different specialties usually contain quite different terminologies and writing styles. The difference of specialties and the cost of human annotation makes it particularly difficult to train a universal medical NER system. In this paper, we propose a label-aware double transfer learning framework (La-DTL) for cross-specialty NER, so that a medical NER system designed for one specialty could be conveniently applied to another one with minimal annotation efforts. The transferability is guaranteed by two components: (i) we propose label-aware MMD for feature representation transfer, and (ii) we perform parameter transfer with a theoretical upper bound which is also label aware. We conduct extensive experiments on 12 cross-specialty NER tasks. The experimental results demonstrate that La-DTL provides consistent accuracy improvement over strong baselines. Besides, the promising experimental results on non-medical NER scenarios indicate that La-DTL is potential to be seamlessly adapted to a wide range of NER tasks.