 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYing Wen
DS-Agent: Automated Data Science by Empowering Large Language Models with Case-Based Reasoning
Mar 13, 2024
In this work, we investigate the potential of large language models (LLMs) based agents to automate data science tasks, with the goal of comprehending task requirements, then building and training the best-fit machine learning models. Despite their widespread success, existing LLM agents are hindered by generating unreasonable experiment plans within this scenario. To this end, we present DS-Agent, a novel automatic framework that harnesses LLM agent and case-based reasoning (CBR). In the development stage, DS-Agent follows the CBR framework to structure an automatic iteration pipeline, which can flexibly capitalize on the expert knowledge from Kaggle, and facilitate consistent performance improvement through the feedback mechanism. Moreover, DS-Agent implements a low-resource deployment stage with a simplified CBR paradigm to adapt past successful solutions from the development stage for direct code generation, significantly reducing the demand on foundational capabilities of LLMs. Empirically, DS-Agent with GPT-4 achieves an unprecedented 100% success rate in the development stage, while attaining 36% improvement on average one pass rate across alternative LLMs in the deployment stage. In both stages, DS-Agent achieves the best rank in performance, costing \$1.60 and \$0.13 per run with GPT-4, respectively. Our code is open-sourced at https://github.com/guosyjlu/DS-Agent.
TRAD: Enhancing LLM Agents with Step-Wise Thought Retrieval and Aligned Decision
Mar 10, 2024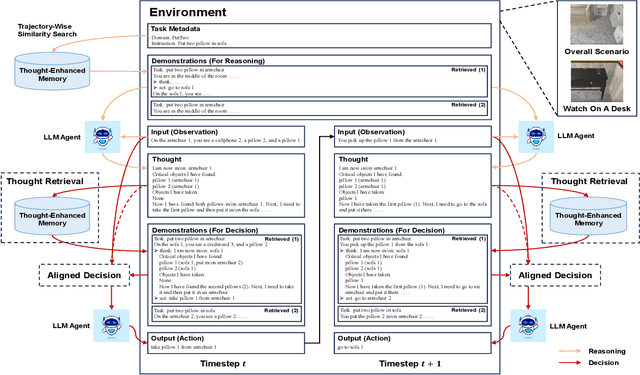

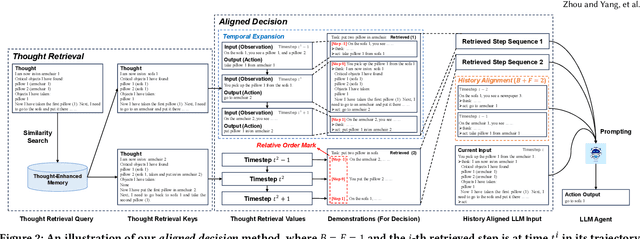

Numerous large language model (LLM) agents have been built for different tasks like web navigation and online shopping due to LLM's wide knowledge and text-understanding ability. Among these works, many of them utilize in-context examples to achieve generalization without the need for fine-tuning, while few of them have considered the problem of how to select and effectively utilize these examples. Recently, methods based on trajectory-level retrieval with task meta-data and using trajectories as in-context examples have been proposed to improve the agent's overall performance in some sequential decision making tasks. However, these methods can be problematic due to plausible examples retrieved without task-specific state transition dynamics and long input with plenty of irrelevant context. In this paper, we propose a novel framework (TRAD) to address these issues. TRAD first conducts Thought Retrieval, achieving step-level demonstration selection via thought matching, leading to more helpful demonstrations and less irrelevant input noise. Then, TRAD introduces Aligned Decision, complementing retrieved demonstration steps with their previous or subsequent steps, which enables tolerance for imperfect thought and provides a choice for balance between more context and less noise. Extensive experiments on ALFWorld and Mind2Web benchmarks show that TRAD not only outperforms state-of-the-art models but also effectively helps in reducing noise and promoting generalization. Furthermore, TRAD has been deployed in real-world scenarios of a global business insurance company and improves the success rate of robotic process automation.
AceMap: Knowledge Discovery through Academic Graph
Mar 05, 2024
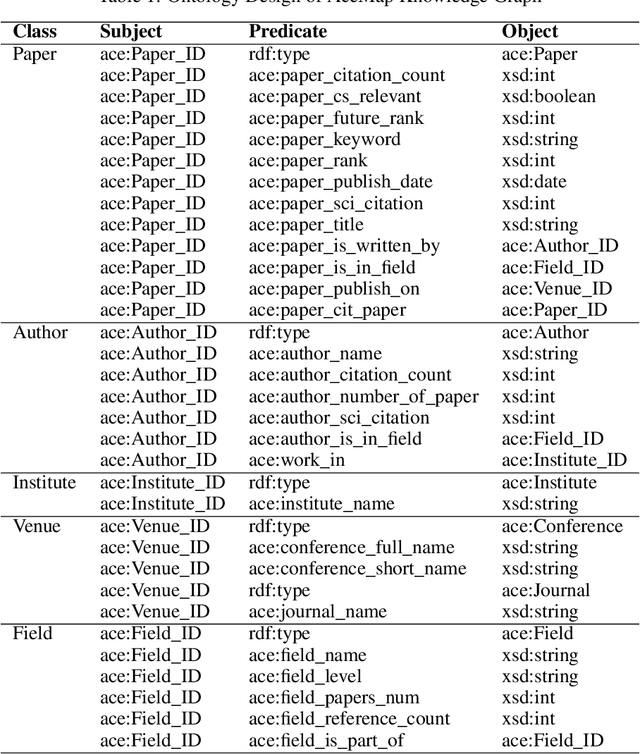
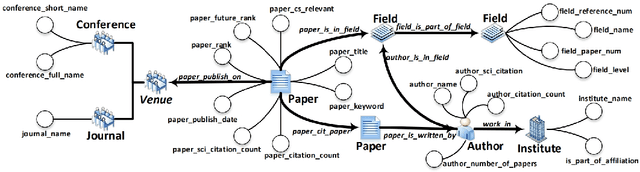
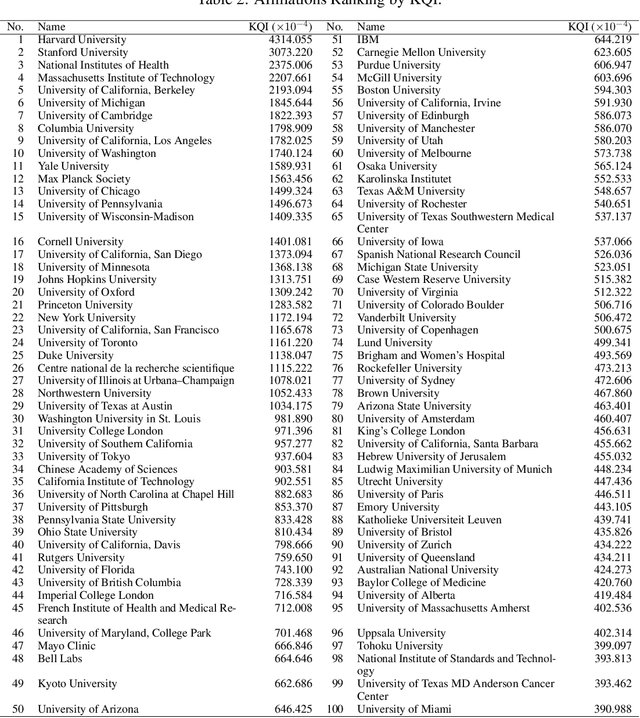
The exponential growth of scientific literature requires effective management and extraction of valuable insights. While existing scientific search engines excel at delivering search results based on relational databases, they often neglect the analysis of collaborations between scientific entities and the evolution of ideas, as well as the in-depth analysis of content within scientific publications. The representation of heterogeneous graphs and the effective measurement, analysis, and mining of such graphs pose significant challenges. To address these challenges, we present AceMap, an academic system designed for knowledge discovery through academic graph. We present advanced database construction techniques to build the comprehensive AceMap database with large-scale academic publications that contain rich visual, textual, and numerical information. AceMap also employs innovative visualization, quantification, and analysis methods to explore associations and logical relationships among academic entities. AceMap introduces large-scale academic network visualization techniques centered on nebular graphs, providing a comprehensive view of academic networks from multiple perspectives. In addition, AceMap proposes a unified metric based on structural entropy to quantitatively measure the knowledge content of different academic entities. Moreover, AceMap provides advanced analysis capabilities, including tracing the evolution of academic ideas through citation relationships and concept co-occurrence, and generating concise summaries informed by this evolutionary process. In addition, AceMap uses machine reading methods to generate potential new ideas at the intersection of different fields. Exploring the integration of large language models and knowledge graphs is a promising direction for future research in idea evolution. Please visit \url{https://www.acemap.info} for further exploration.
Offline Fictitious Self-Play for Competitive Games
Feb 29, 2024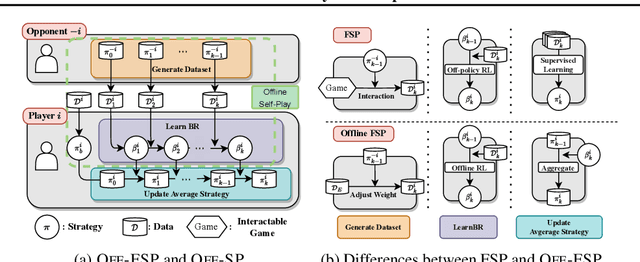
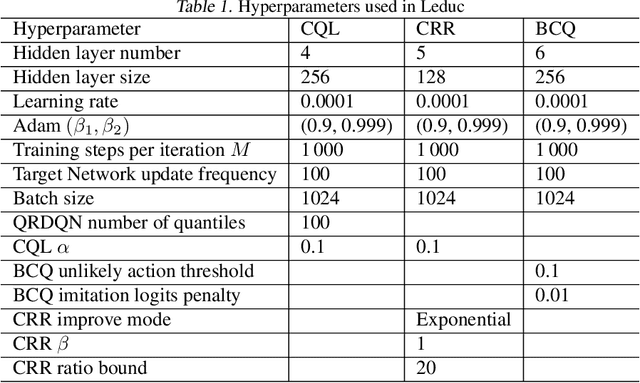
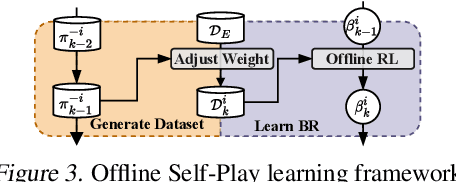
Offline Reinforcement Learning (RL) has received significant interest due to its ability to improve policies in previously collected datasets without online interactions. Despite its success in the single-agent setting, offline multi-agent RL remains a challenge, especially in competitive games. Firstly, unaware of the game structure, it is impossible to interact with the opponents and conduct a major learning paradigm, self-play, for competitive games. Secondly, real-world datasets cannot cover all the state and action space in the game, resulting in barriers to identifying Nash equilibrium (NE). To address these issues, this paper introduces Off-FSP, the first practical model-free offline RL algorithm for competitive games. We start by simulating interactions with various opponents by adjusting the weights of the fixed dataset with importance sampling. This technique allows us to learn best responses to different opponents and employ the Offline Self-Play learning framework. In this framework, we further implement Fictitious Self-Play (FSP) to approximate NE. In partially covered real-world datasets, our methods show the potential to approach NE by incorporating any single-agent offline RL method. Experimental results in Leduc Hold'em Poker show that our method significantly improves performances compared with state-of-the-art baselines.
Aligning Individual and Collective Objectives in Multi-Agent Cooperation
Feb 19, 2024In the field of multi-agent learning, the challenge of mixed-motive cooperation is pronounced, given the inherent contradictions between individual and collective goals. Current research in this domain primarily focuses on incorporating domain knowledge into rewards or introducing additional mechanisms to foster cooperation. However, many of these methods suffer from the drawbacks of manual design costs and the lack of a theoretical grounding convergence procedure to the solution. To address this gap, we approach the mixed-motive game by modeling it as a differentiable game to study learning dynamics. We introduce a novel optimization method named Altruistic Gradient Adjustment (AgA) that employs gradient adjustments to novelly align individual and collective objectives. Furthermore, we provide theoretical proof that the selection of an appropriate alignment weight in AgA can accelerate convergence towards the desired solutions while effectively avoiding the undesired ones. The visualization of learning dynamics effectively demonstrates that AgA successfully achieves alignment between individual and collective objectives. Additionally, through evaluations conducted on established mixed-motive benchmarks such as the public good game, Cleanup, Harvest, and our modified mixed-motive SMAC environment, we validate AgA's capability to facilitate altruistic and fair collaboration.
Natural Language Reinforcement Learning
Feb 14, 2024Reinforcement Learning (RL) has shown remarkable abilities in learning policies for decision-making tasks. However, RL is often hindered by issues such as low sample efficiency, lack of interpretability, and sparse supervision signals. To tackle these limitations, we take inspiration from the human learning process and introduce Natural Language Reinforcement Learning (NLRL), which innovatively combines RL principles with natural language representation. Specifically, NLRL redefines RL concepts like task objectives, policy, value function, Bellman equation, and policy iteration in natural language space. We present how NLRL can be practically implemented with the latest advancements in large language models (LLMs) like GPT-4. Initial experiments over tabular MDPs demonstrate the effectiveness, efficiency, and also interpretability of the NLRL framework.
Entropy-Regularized Token-Level Policy Optimization for Large Language Models
Feb 09, 2024Large Language Models (LLMs) have shown promise as intelligent agents in interactive decision-making tasks. Traditional approaches often depend on meticulously designed prompts, high-quality examples, or additional reward models for in-context learning, supervised fine-tuning, or RLHF. Reinforcement learning (RL) presents a dynamic alternative for LLMs to overcome these dependencies by engaging directly with task-specific environments. Nonetheless, it faces significant hurdles: 1) instability stemming from the exponentially vast action space requiring exploration; 2) challenges in assigning token-level credit based on action-level reward signals, resulting in discord between maximizing rewards and accurately modeling corpus data. In response to these challenges, we introduce Entropy-Regularized Token-level Policy Optimization (ETPO), an entropy-augmented RL method tailored for optimizing LLMs at the token level. At the heart of ETPO is our novel per-token soft Bellman update, designed to harmonize the RL process with the principles of language modeling. This methodology decomposes the Q-function update from a coarse action-level view to a more granular token-level perspective, backed by theoretical proof of optimization consistency. Crucially, this decomposition renders linear time complexity in action exploration. We assess the effectiveness of ETPO within a simulated environment that models data science code generation as a series of multi-step interactive tasks; results show that ETPO achieves effective performance improvement on the CodeLlama-7B model and surpasses a variant PPO baseline inherited from RLHF. This underlines ETPO's potential as a robust method for refining the interactive decision-making capabilities of LLMs.
Adaptive Control Strategy for Quadruped Robots in Actuator Degradation Scenarios
Dec 29, 2023Quadruped robots have strong adaptability to extreme environments but may also experience faults. Once these faults occur, robots must be repaired before returning to the task, reducing their practical feasibility. One prevalent concern among these faults is actuator degradation, stemming from factors like device aging or unexpected operational events. Traditionally, addressing this problem has relied heavily on intricate fault-tolerant design, which demands deep domain expertise from developers and lacks generalizability. Learning-based approaches offer effective ways to mitigate these limitations, but a research gap exists in effectively deploying such methods on real-world quadruped robots. This paper introduces a pioneering teacher-student framework rooted in reinforcement learning, named Actuator Degradation Adaptation Transformer (ADAPT), aimed at addressing this research gap. This framework produces a unified control strategy, enabling the robot to sustain its locomotion and perform tasks despite sudden joint actuator faults, relying exclusively on its internal sensors. Empirical evaluations on the Unitree A1 platform validate the deployability and effectiveness of Adapt on real-world quadruped robots, and affirm the robustness and practicality of our approach.