 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXinbing Wang
Characterizing the Influence of Topology on Graph Learning Tasks
Apr 11, 2024
Graph neural networks (GNN) have achieved remarkable success in a wide range of tasks by encoding features combined with topology to create effective representations. However, the fundamental problem of understanding and analyzing how graph topology influences the performance of learning models on downstream tasks has not yet been well understood. In this paper, we propose a metric, TopoInf, which characterizes the influence of graph topology by measuring the level of compatibility between the topological information of graph data and downstream task objectives. We provide analysis based on the decoupled GNNs on the contextual stochastic block model to demonstrate the effectiveness of the metric. Through extensive experiments, we demonstrate that TopoInf is an effective metric for measuring topological influence on corresponding tasks and can be further leveraged to enhance graph learning.
Temporal Generalization Estimation in Evolving Graphs
Apr 07, 2024Graph Neural Networks (GNNs) are widely deployed in vast fields, but they often struggle to maintain accurate representations as graphs evolve. We theoretically establish a lower bound, proving that under mild conditions, representation distortion inevitably occurs over time. To estimate the temporal distortion without human annotation after deployment, one naive approach is to pre-train a recurrent model (e.g., RNN) before deployment and use this model afterwards, but the estimation is far from satisfactory. In this paper, we analyze the representation distortion from an information theory perspective, and attribute it primarily to inaccurate feature extraction during evolution. Consequently, we introduce Smart, a straightforward and effective baseline enhanced by an adaptive feature extractor through self-supervised graph reconstruction. In synthetic random graphs, we further refine the former lower bound to show the inevitable distortion over time and empirically observe that Smart achieves good estimation performance. Moreover, we observe that Smart consistently shows outstanding generalization estimation on four real-world evolving graphs. The ablation studies underscore the necessity of graph reconstruction. For example, on OGB-arXiv dataset, the estimation metric MAPE deteriorates from 2.19% to 8.00% without reconstruction.
PNAS-MOT: Multi-Modal Object Tracking with Pareto Neural Architecture Search
Mar 23, 2024Multiple object tracking is a critical task in autonomous driving. Existing works primarily focus on the heuristic design of neural networks to obtain high accuracy. As tracking accuracy improves, however, neural networks become increasingly complex, posing challenges for their practical application in real driving scenarios due to the high level of latency. In this paper, we explore the use of the neural architecture search (NAS) methods to search for efficient architectures for tracking, aiming for low real-time latency while maintaining relatively high accuracy. Another challenge for object tracking is the unreliability of a single sensor, therefore, we propose a multi-modal framework to improve the robustness. Experiments demonstrate that our algorithm can run on edge devices within lower latency constraints, thus greatly reducing the computational requirements for multi-modal object tracking while keeping lower latency.
* IEEE Robotics and Automation Letters 2024. Code is available at https://github.com/PholyPeng/PNAS-MOT
Is Reference Necessary in the Evaluation of NLG Systems? When and Where?
Mar 21, 2024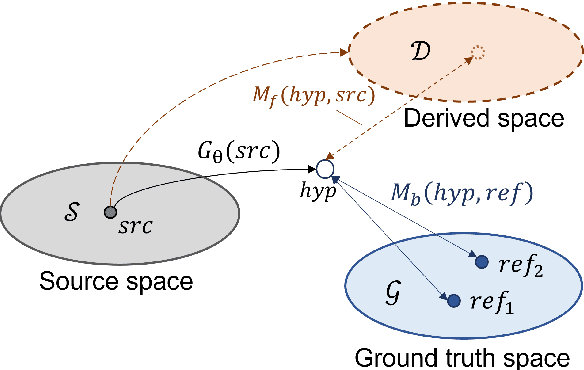
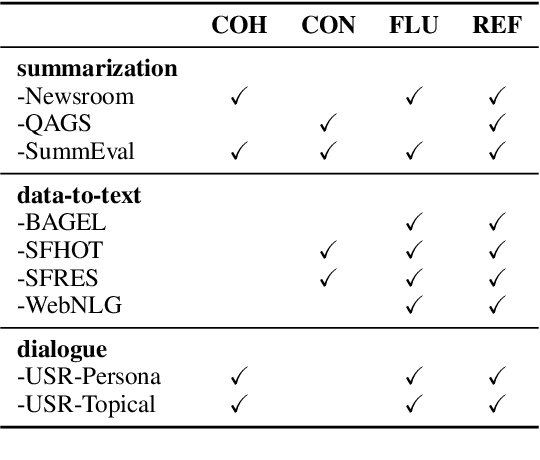
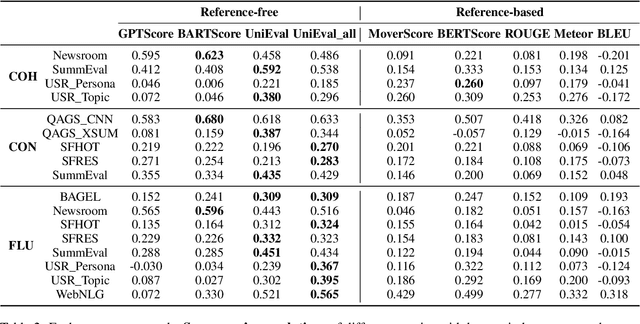
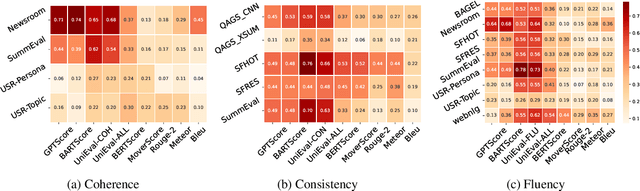
The majority of automatic metrics for evaluating NLG systems are reference-based. However, the challenge of collecting human annotation results in a lack of reliable references in numerous application scenarios. Despite recent advancements in reference-free metrics, it has not been well understood when and where they can be used as an alternative to reference-based metrics. In this study, by employing diverse analytical approaches, we comprehensively assess the performance of both metrics across a wide range of NLG tasks, encompassing eight datasets and eight evaluation models. Based on solid experiments, the results show that reference-free metrics exhibit a higher correlation with human judgment and greater sensitivity to deficiencies in language quality. However, their effectiveness varies across tasks and is influenced by the quality of candidate texts. Therefore, it's important to assess the performance of reference-free metrics before applying them to a new task, especially when inputs are in uncommon form or when the answer space is highly variable. Our study can provide insight into the appropriate application of automatic metrics and the impact of metric choice on evaluation performance.
Entity Alignment with Unlabeled Dangling Cases
Mar 16, 2024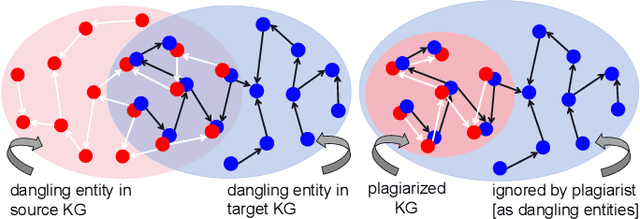
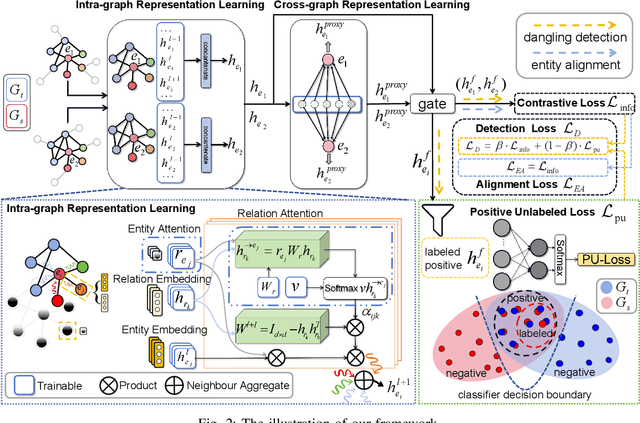
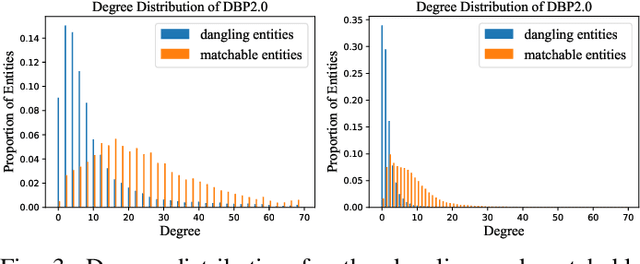
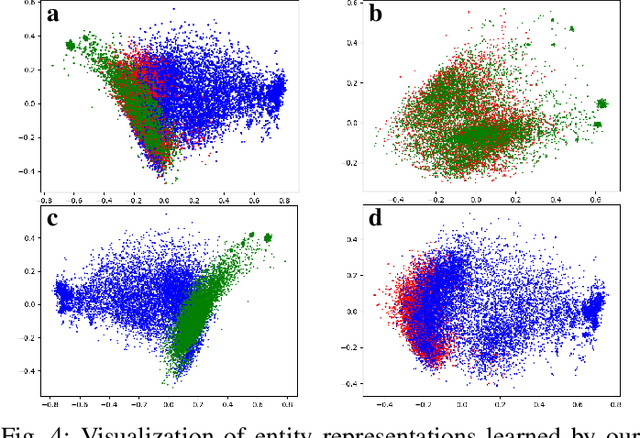
We investigate the entity alignment problem with unlabeled dangling cases, meaning that there are entities in the source or target graph having no counterparts in the other, and those entities remain unlabeled. The problem arises when the source and target graphs are of different scales, and it is much cheaper to label the matchable pairs than the dangling entities. To solve the issue, we propose a novel GNN-based dangling detection and entity alignment framework. While the two tasks share the same GNN and are trained together, the detected dangling entities are removed in the alignment. Our framework is featured by a designed entity and relation attention mechanism for selective neighborhood aggregation in representation learning, as well as a positive-unlabeled learning loss for an unbiased estimation of dangling entities. Experimental results have shown that each component of our design contributes to the overall alignment performance which is comparable or superior to baselines, even if the baselines additionally have 30\% of the dangling entities labeled as training data.
AceMap: Knowledge Discovery through Academic Graph
Mar 05, 2024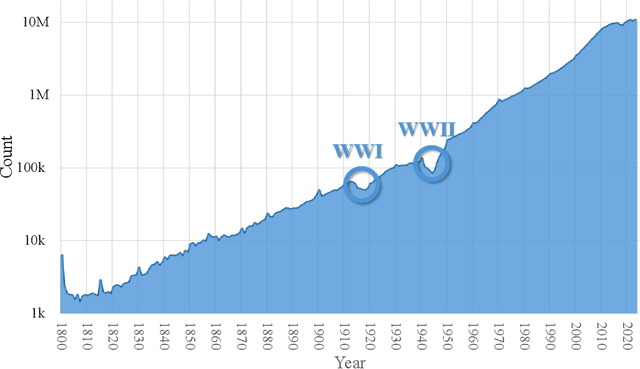
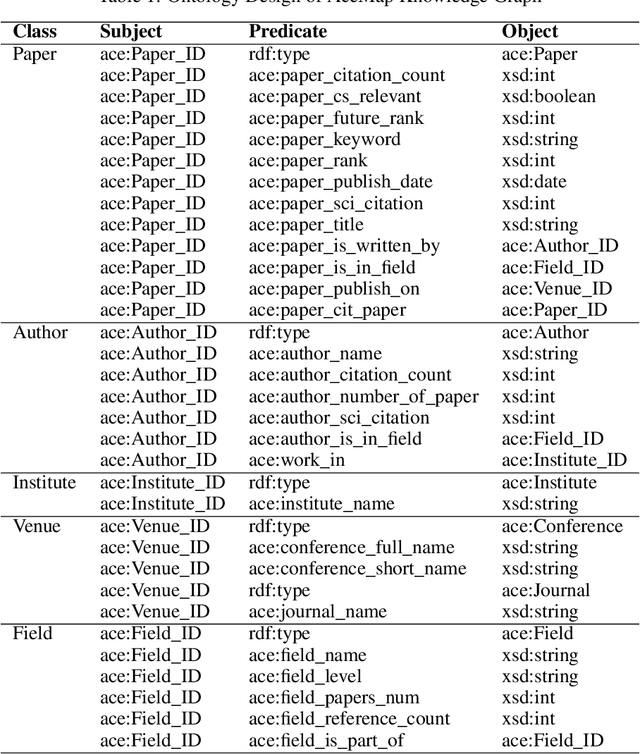
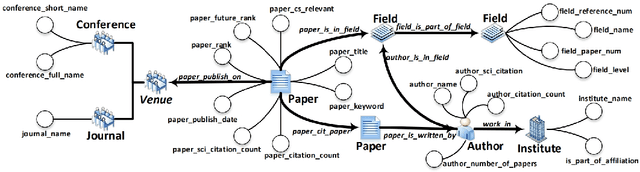
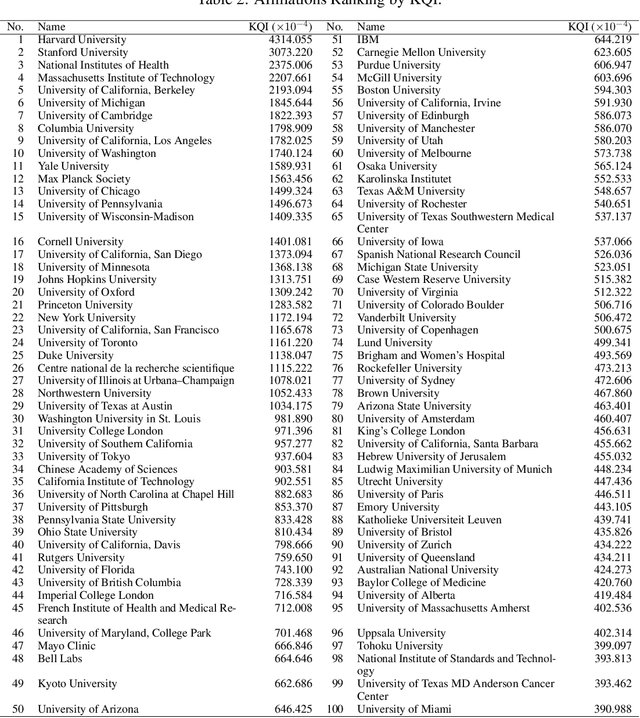
The exponential growth of scientific literature requires effective management and extraction of valuable insights. While existing scientific search engines excel at delivering search results based on relational databases, they often neglect the analysis of collaborations between scientific entities and the evolution of ideas, as well as the in-depth analysis of content within scientific publications. The representation of heterogeneous graphs and the effective measurement, analysis, and mining of such graphs pose significant challenges. To address these challenges, we present AceMap, an academic system designed for knowledge discovery through academic graph. We present advanced database construction techniques to build the comprehensive AceMap database with large-scale academic publications that contain rich visual, textual, and numerical information. AceMap also employs innovative visualization, quantification, and analysis methods to explore associations and logical relationships among academic entities. AceMap introduces large-scale academic network visualization techniques centered on nebular graphs, providing a comprehensive view of academic networks from multiple perspectives. In addition, AceMap proposes a unified metric based on structural entropy to quantitatively measure the knowledge content of different academic entities. Moreover, AceMap provides advanced analysis capabilities, including tracing the evolution of academic ideas through citation relationships and concept co-occurrence, and generating concise summaries informed by this evolutionary process. In addition, AceMap uses machine reading methods to generate potential new ideas at the intersection of different fields. Exploring the integration of large language models and knowledge graphs is a promising direction for future research in idea evolution. Please visit \url{https://www.acemap.info} for further exploration.
Graph Parsing Networks
Feb 22, 2024Graph pooling compresses graph information into a compact representation. State-of-the-art graph pooling methods follow a hierarchical approach, which reduces the graph size step-by-step. These methods must balance memory efficiency with preserving node information, depending on whether they use node dropping or node clustering. Additionally, fixed pooling ratios or numbers of pooling layers are predefined for all graphs, which prevents personalized pooling structures from being captured for each individual graph. In this work, inspired by bottom-up grammar induction, we propose an efficient graph parsing algorithm to infer the pooling structure, which then drives graph pooling. The resulting Graph Parsing Network (GPN) adaptively learns personalized pooling structure for each individual graph. GPN benefits from the discrete assignments generated by the graph parsing algorithm, allowing good memory efficiency while preserving node information intact. Experimental results on standard benchmarks demonstrate that GPN outperforms state-of-the-art graph pooling methods in graph classification tasks while being able to achieve competitive performance in node classification tasks. We also conduct a graph reconstruction task to show GPN's ability to preserve node information and measure both memory and time efficiency through relevant tests.
G-NAS: Generalizable Neural Architecture Search for Single Domain Generalization Object Detection
Feb 07, 2024In this paper, we focus on a realistic yet challenging task, Single Domain Generalization Object Detection (S-DGOD), where only one source domain's data can be used for training object detectors, but have to generalize multiple distinct target domains. In S-DGOD, both high-capacity fitting and generalization abilities are needed due to the task's complexity. Differentiable Neural Architecture Search (NAS) is known for its high capacity for complex data fitting and we propose to leverage Differentiable NAS to solve S-DGOD. However, it may confront severe over-fitting issues due to the feature imbalance phenomenon, where parameters optimized by gradient descent are biased to learn from the easy-to-learn features, which are usually non-causal and spuriously correlated to ground truth labels, such as the features of background in object detection data. Consequently, this leads to serious performance degradation, especially in generalizing to unseen target domains with huge domain gaps between the source domain and target domains. To address this issue, we propose the Generalizable loss (G-loss), which is an OoD-aware objective, preventing NAS from over-fitting by using gradient descent to optimize parameters not only on a subset of easy-to-learn features but also the remaining predictive features for generalization, and the overall framework is named G-NAS. Experimental results on the S-DGOD urban-scene datasets demonstrate that the proposed G-NAS achieves SOTA performance compared to baseline methods. Codes are available at https://github.com/wufan-cse/G-NAS.
Crafter: Facial Feature Crafting against Inversion-based Identity Theft on Deep Models
Jan 14, 2024With the increased capabilities at the edge (e.g., mobile device) and more stringent privacy requirement, it becomes a recent trend for deep learning-enabled applications to pre-process sensitive raw data at the edge and transmit the features to the backend cloud for further processing. A typical application is to run machine learning (ML) services on facial images collected from different individuals. To prevent identity theft, conventional methods commonly rely on an adversarial game-based approach to shed the identity information from the feature. However, such methods can not defend against adaptive attacks, in which an attacker takes a countermove against a known defence strategy. We propose Crafter, a feature crafting mechanism deployed at the edge, to protect the identity information from adaptive model inversion attacks while ensuring the ML tasks are properly carried out in the cloud. The key defence strategy is to mislead the attacker to a non-private prior from which the attacker gains little about the private identity. In this case, the crafted features act like poison training samples for attackers with adaptive model updates. Experimental results indicate that Crafter successfully defends both basic and possible adaptive attacks, which can not be achieved by state-of-the-art adversarial game-based methods.
GeoGalactica: A Scientific Large Language Model in Geoscience
Dec 31, 2023Large language models (LLMs) have achieved huge success for their general knowledge and ability to solve a wide spectrum of tasks in natural language processing (NLP). Due to their impressive abilities, LLMs have shed light on potential inter-discipline applications to foster scientific discoveries of a specific domain by using artificial intelligence (AI for science, AI4S). In the meantime, utilizing NLP techniques in geoscience research and practice is wide and convoluted, contributing from knowledge extraction and document classification to question answering and knowledge discovery. In this work, we take the initial step to leverage LLM for science, through a rather straightforward approach. We try to specialize an LLM into geoscience, by further pre-training the model with a vast amount of texts in geoscience, as well as supervised fine-tuning (SFT) the resulting model with our custom collected instruction tuning dataset. These efforts result in a model GeoGalactica consisting of 30 billion parameters. To our best knowledge, it is the largest language model for the geoscience domain. More specifically, GeoGalactica is from further pre-training of Galactica. We train GeoGalactica over a geoscience-related text corpus containing 65 billion tokens curated from extensive data sources in the big science project Deep-time Digital Earth (DDE), preserving as the largest geoscience-specific text corpus. Then we fine-tune the model with 1 million pairs of instruction-tuning data consisting of questions that demand professional geoscience knowledge to answer. In this technical report, we will illustrate in detail all aspects of GeoGalactica, including data collection, data cleaning, base model selection, pre-training, SFT, and evaluation. We open-source our data curation tools and the checkpoints of GeoGalactica during the first 3/4 of pre-training.