 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChensheng Peng
Joint Pedestrian Trajectory Prediction through Posterior Sampling
Mar 30, 2024
Joint pedestrian trajectory prediction has long grappled with the inherent unpredictability of human behaviors. Recent investigations employing variants of conditional diffusion models in trajectory prediction have exhibited notable success. Nevertheless, the heavy dependence on accurate historical data results in their vulnerability to noise disturbances and data incompleteness. To improve the robustness and reliability, we introduce the Guided Full Trajectory Diffuser (GFTD), a novel diffusion model framework that captures the joint full (historical and future) trajectory distribution. By learning from the full trajectory, GFTD can recover the noisy and missing data, hence improving the robustness. In addition, GFTD can adapt to data imperfections without additional training requirements, leveraging posterior sampling for reliable prediction and controllable generation. Our approach not only simplifies the prediction process but also enhances generalizability in scenarios with noise and incomplete inputs. Through rigorous experimental evaluation, GFTD exhibits superior performance in both trajectory prediction and controllable generation.
DVLO: Deep Visual-LiDAR Odometry with Local-to-Global Feature Fusion and Bi-Directional Structure Alignment
Mar 27, 2024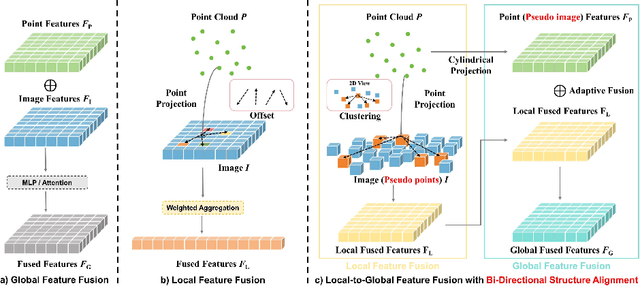
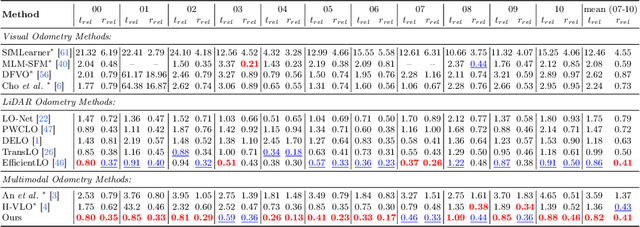
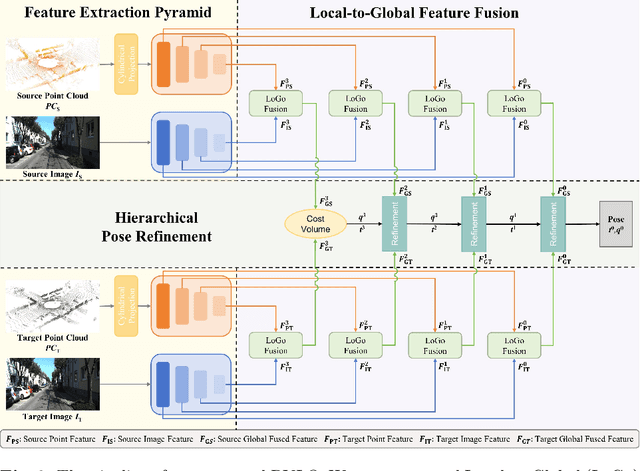

Information inside visual and LiDAR data is well complementary derived from the fine-grained texture of images and massive geometric information in point clouds. However, it remains challenging to explore effective visual-LiDAR fusion, mainly due to the intrinsic data structure inconsistency between two modalities: Images are regular and dense, but LiDAR points are unordered and sparse. To address the problem, we propose a local-to-global fusion network with bi-directional structure alignment. To obtain locally fused features, we project points onto image plane as cluster centers and cluster image pixels around each center. Image pixels are pre-organized as pseudo points for image-to-point structure alignment. Then, we convert points to pseudo images by cylindrical projection (point-to-image structure alignment) and perform adaptive global feature fusion between point features with local fused features. Our method achieves state-of-the-art performance on KITTI odometry and FlyingThings3D scene flow datasets compared to both single-modal and multi-modal methods. Codes will be released later.
PNAS-MOT: Multi-Modal Object Tracking with Pareto Neural Architecture Search
Mar 23, 2024Multiple object tracking is a critical task in autonomous driving. Existing works primarily focus on the heuristic design of neural networks to obtain high accuracy. As tracking accuracy improves, however, neural networks become increasingly complex, posing challenges for their practical application in real driving scenarios due to the high level of latency. In this paper, we explore the use of the neural architecture search (NAS) methods to search for efficient architectures for tracking, aiming for low real-time latency while maintaining relatively high accuracy. Another challenge for object tracking is the unreliability of a single sensor, therefore, we propose a multi-modal framework to improve the robustness. Experiments demonstrate that our algorithm can run on edge devices within lower latency constraints, thus greatly reducing the computational requirements for multi-modal object tracking while keeping lower latency.
* IEEE Robotics and Automation Letters 2024. Code is available at https://github.com/PholyPeng/PNAS-MOT
Q-SLAM: Quadric Representations for Monocular SLAM
Mar 12, 2024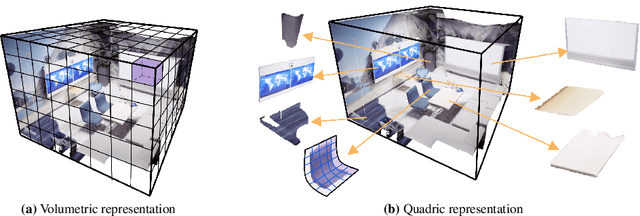
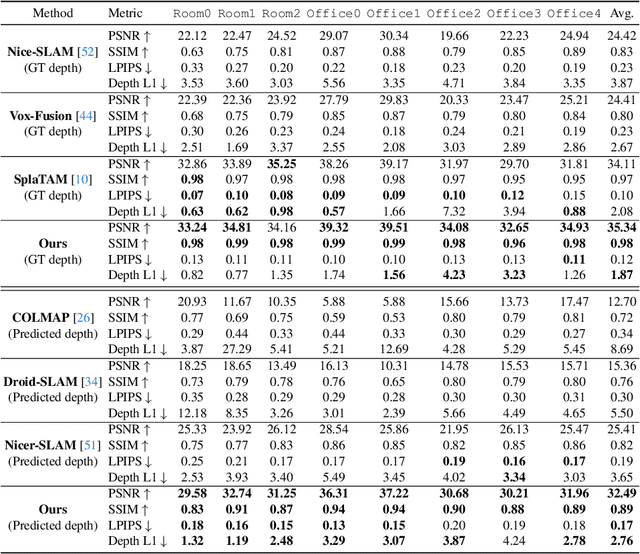
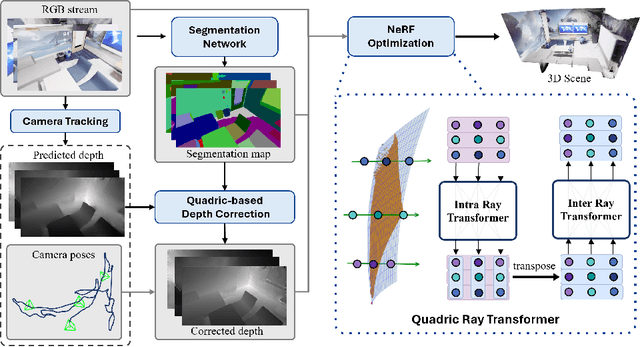
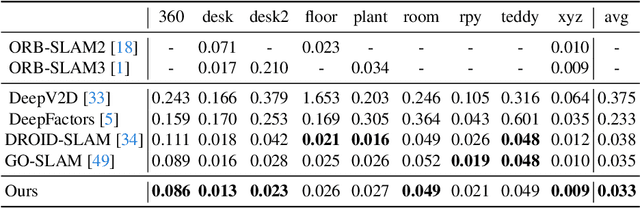
Monocular SLAM has long grappled with the challenge of accurately modeling 3D geometries. Recent advances in Neural Radiance Fields (NeRF)-based monocular SLAM have shown promise, yet these methods typically focus on novel view synthesis rather than precise 3D geometry modeling. This focus results in a significant disconnect between NeRF applications, i.e., novel-view synthesis and the requirements of SLAM. We identify that the gap results from the volumetric representations used in NeRF, which are often dense and noisy. In this study, we propose a novel approach that reimagines volumetric representations through the lens of quadric forms. We posit that most scene components can be effectively represented as quadric planes. Leveraging this assumption, we reshape the volumetric representations with million of cubes by several quadric planes, which leads to more accurate and efficient modeling of 3D scenes in SLAM contexts. Our method involves two key steps: First, we use the quadric assumption to enhance coarse depth estimations obtained from tracking modules, e.g., Droid-SLAM. This step alone significantly improves depth estimation accuracy. Second, in the subsequent mapping phase, we diverge from previous NeRF-based SLAM methods that distribute sampling points across the entire volume space. Instead, we concentrate sampling points around quadric planes and aggregate them using a novel quadric-decomposed Transformer. Additionally, we introduce an end-to-end joint optimization strategy that synchronizes pose estimation with 3D reconstruction.
DELFlow: Dense Efficient Learning of Scene Flow for Large-Scale Point Clouds
Aug 09, 2023



Point clouds are naturally sparse, while image pixels are dense. The inconsistency limits feature fusion from both modalities for point-wise scene flow estimation. Previous methods rarely predict scene flow from the entire point clouds of the scene with one-time inference due to the memory inefficiency and heavy overhead from distance calculation and sorting involved in commonly used farthest point sampling, KNN, and ball query algorithms for local feature aggregation. To mitigate these issues in scene flow learning, we regularize raw points to a dense format by storing 3D coordinates in 2D grids. Unlike the sampling operation commonly used in existing works, the dense 2D representation 1) preserves most points in the given scene, 2) brings in a significant boost of efficiency, and 3) eliminates the density gap between points and pixels, allowing us to perform effective feature fusion. We also present a novel warping projection technique to alleviate the information loss problem resulting from the fact that multiple points could be mapped into one grid during projection when computing cost volume. Sufficient experiments demonstrate the efficiency and effectiveness of our method, outperforming the prior-arts on the FlyingThings3D and KITTI dataset.
Interactive Multi-scale Fusion of 2D and 3D Features for Multi-object Tracking
Mar 30, 2022



Multiple object tracking (MOT) is a significant task in achieving autonomous driving. Traditional works attempt to complete this task, either based on point clouds (PC) collected by LiDAR, or based on images captured from cameras. However, relying on one single sensor is not robust enough, because it might fail during the tracking process. On the other hand, feature fusion from multiple modalities contributes to the improvement of accuracy. As a result, new techniques based on different sensors integrating features from multiple modalities are being developed. Texture information from RGB cameras and 3D structure information from Lidar have respective advantages under different circumstances. However, it's not easy to achieve effective feature fusion because of completely distinct information modalities. Previous fusion methods usually fuse the top-level features after the backbones extract the features from different modalities. In this paper, we first introduce PointNet++ to obtain multi-scale deep representations of point cloud to make it adaptive to our proposed Interactive Feature Fusion between multi-scale features of images and point clouds. Specifically, through multi-scale interactive query and fusion between pixel-level and point-level features, our method, can obtain more distinguishing features to improve the performance of multiple object tracking. Besides, we explore the effectiveness of pre-training on each single modality and fine-tuning on the fusion-based model. The experimental results demonstrate that our method can achieve good performance on the KITTI benchmark and outperform other approaches without using multi-scale feature fusion. Moreover, the ablation studies indicates the effectiveness of multi-scale feature fusion and pre-training on single modality.