 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQiyuan Chen
GeoGalactica: A Scientific Large Language Model in Geoscience
Dec 31, 2023
Large language models (LLMs) have achieved huge success for their general knowledge and ability to solve a wide spectrum of tasks in natural language processing (NLP). Due to their impressive abilities, LLMs have shed light on potential inter-discipline applications to foster scientific discoveries of a specific domain by using artificial intelligence (AI for science, AI4S). In the meantime, utilizing NLP techniques in geoscience research and practice is wide and convoluted, contributing from knowledge extraction and document classification to question answering and knowledge discovery. In this work, we take the initial step to leverage LLM for science, through a rather straightforward approach. We try to specialize an LLM into geoscience, by further pre-training the model with a vast amount of texts in geoscience, as well as supervised fine-tuning (SFT) the resulting model with our custom collected instruction tuning dataset. These efforts result in a model GeoGalactica consisting of 30 billion parameters. To our best knowledge, it is the largest language model for the geoscience domain. More specifically, GeoGalactica is from further pre-training of Galactica. We train GeoGalactica over a geoscience-related text corpus containing 65 billion tokens curated from extensive data sources in the big science project Deep-time Digital Earth (DDE), preserving as the largest geoscience-specific text corpus. Then we fine-tune the model with 1 million pairs of instruction-tuning data consisting of questions that demand professional geoscience knowledge to answer. In this technical report, we will illustrate in detail all aspects of GeoGalactica, including data collection, data cleaning, base model selection, pre-training, SFT, and evaluation. We open-source our data curation tools and the checkpoints of GeoGalactica during the first 3/4 of pre-training.
Mind's Mirror: Distilling Self-Evaluation Capability and Comprehensive Thinking from Large Language Models
Nov 15, 2023Large language models (LLMs) have achieved remarkable advancements in the field of natural language processing. However, the sheer scale and computational demands of these models present formidable challenges when considering their practical deployment in resource-constrained contexts. While techniques such as chain-of-thought (CoT) distillation have displayed promise in distilling LLMs into small language models (SLMs), there is a risk that distilled SLMs may still carry over flawed reasoning or hallucinations inherited from their LLM counterparts. To address these issues, we propose a twofold methodology: First, we introduce a novel method for distilling the self-evaluation capability inherent in LLMs into SLMs, which aims to mitigate the adverse effects of erroneous reasoning and reduce hallucinations. Second, we advocate for a comprehensive distillation process that incorporates multiple distinct chain-of-thought and self-evaluation paradigms and ensures a more holistic and robust knowledge transfer into SLMs. Experiments on three NLP benchmarks demonstrate that our method significantly improves the performance of distilled SLMs and sheds light on the path towards developing smaller models closely aligned with human cognition.
Pushing Large Language Models to the 6G Edge: Vision, Challenges, and Opportunities
Sep 28, 2023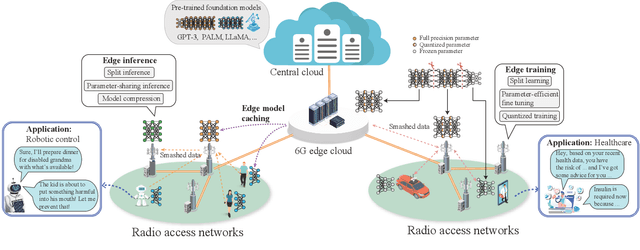
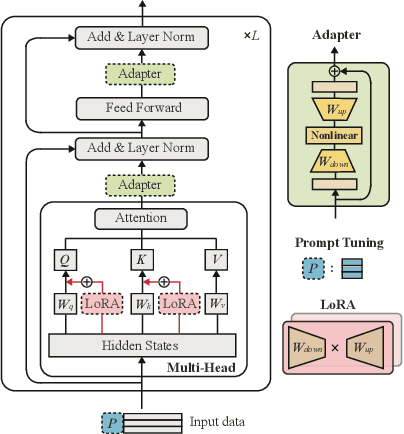
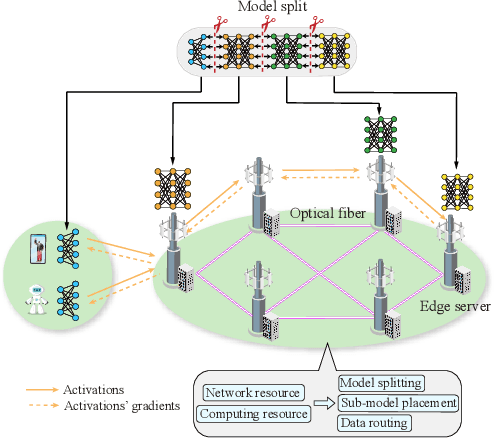
Large language models (LLMs), which have shown remarkable capabilities, are revolutionizing AI development and potentially shaping our future. However, given their multimodality, the status quo cloud-based deployment faces some critical challenges: 1) long response time; 2) high bandwidth costs; and 3) the violation of data privacy. 6G mobile edge computing (MEC) systems may resolve these pressing issues. In this article, we explore the potential of deploying LLMs at the 6G edge. We start by introducing killer applications powered by multimodal LLMs, including robotics and healthcare, to highlight the need for deploying LLMs in the vicinity of end users. Then, we identify the critical challenges for LLM deployment at the edge and envision the 6G MEC architecture for LLMs. Furthermore, we delve into two design aspects, i.e., edge training and edge inference for LLMs. In both aspects, considering the inherent resource limitations at the edge, we discuss various cutting-edge techniques, including split learning/inference, parameter-efficient fine-tuning, quantization, and parameter-sharing inference, to facilitate the efficient deployment of LLMs. This article serves as a position paper for thoroughly identifying the motivation, challenges, and pathway for empowering LLMs at the 6G edge.
Learning A Foundation Language Model for Geoscience Knowledge Understanding and Utilization
Jun 08, 2023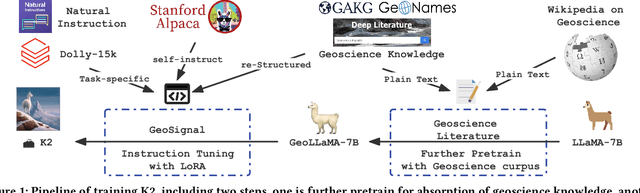

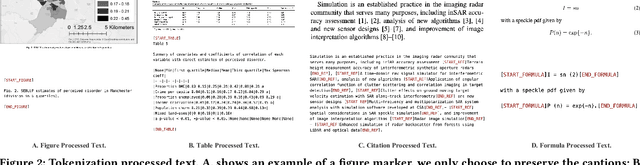
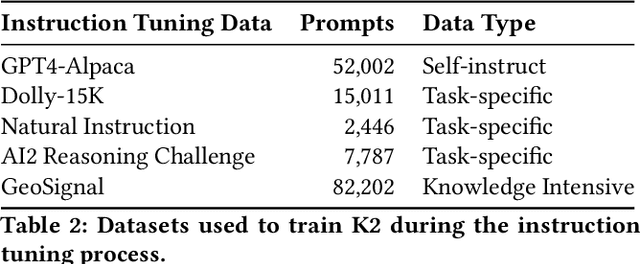
Large language models (LLMs)have achieved great success in general domains of natural language processing. In this paper, we bring LLMs to the realm of geoscience, with the objective of advancing research and applications in this field. To this end, we present the first-ever LLM in geoscience, K2, alongside a suite of resources developed to further promote LLM research within geoscience. For instance, we have curated the first geoscience instruction tuning dataset, GeoSignal, which aims to align LLM responses to geoscience-related user queries. Additionally, we have established the first geoscience benchmark, GeoBenchmark, to evaluate LLMs in the context of geoscience. In this work, we experiment with a complete recipe to adapt a pretrained general-domain LLM to the geoscience domain. Specifically, we further train the LLaMA-7B model on over 1 million pieces of geoscience literature and utilize GeoSignal's supervised data to fine-tune the model. Moreover, we share a protocol that can efficiently gather domain-specific data and construct domain-supervised data, even in situations where manpower is scarce. Experiments conducted on the GeoBenchmark demonstrate the the effectiveness of our approach and datasets.
Rethinking Cost-sensitive Classification in Deep Learning via Adversarial Data Augmentation
Aug 24, 2022



Cost-sensitive classification is critical in applications where misclassification errors widely vary in cost. However, over-parameterization poses fundamental challenges to the cost-sensitive modeling of deep neural networks (DNNs). The ability of a DNN to fully interpolate a training dataset can render a DNN, evaluated purely on the training set, ineffective in distinguishing a cost-sensitive solution from its overall accuracy maximization counterpart. This necessitates rethinking cost-sensitive classification in DNNs. To address this challenge, this paper proposes a cost-sensitive adversarial data augmentation (CSADA) framework to make over-parameterized models cost-sensitive. The overarching idea is to generate targeted adversarial examples that push the decision boundary in cost-aware directions. These targeted adversarial samples are generated by maximizing the probability of critical misclassifications and used to train a model with more conservative decisions on costly pairs. Experiments on well-known datasets and a pharmacy medication image (PMI) dataset made publicly available show that our method can effectively minimize the overall cost and reduce critical errors, while achieving comparable performance in terms of overall accuracy.
Reprint: a randomized extrapolation based on principal components for data augmentation
Apr 26, 2022
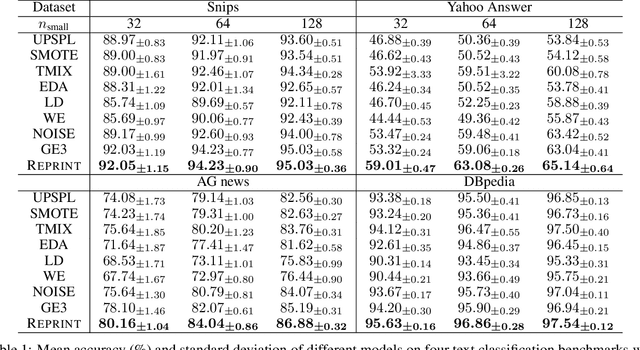
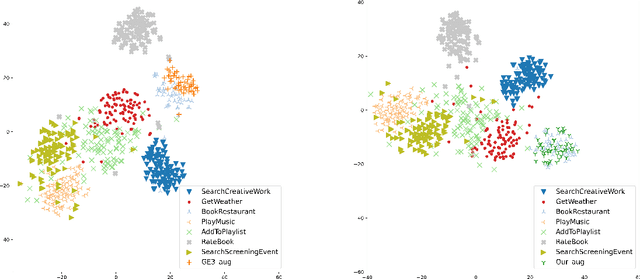

Data scarcity and data imbalance have attracted a lot of attention in many fields. Data augmentation, explored as an effective approach to tackle them, can improve the robustness and efficiency of classification models by generating new samples. This paper presents REPRINT, a simple and effective hidden-space data augmentation method for imbalanced data classification. Given hidden-space representations of samples in each class, REPRINT extrapolates, in a randomized fashion, augmented examples for target class by using subspaces spanned by principal components to summarize distribution structure of both source and target class. Consequently, the examples generated would diversify the target while maintaining the original geometry of target distribution. Besides, this method involves a label refinement component which allows to synthesize new soft labels for augmented examples. Compared with different NLP data augmentation approaches under a range of data imbalanced scenarios on four text classification benchmark, REPRINT shows prominent improvements. Moreover, through comprehensive ablation studies, we show that label refinement is better than label-preserving for augmented examples, and that our method suggests stable and consistent improvements in terms of suitable choices of principal components. Moreover, REPRINT is appealing for its easy-to-use since it contains only one hyperparameter determining the dimension of subspace and requires low computational resource.