 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeinan Zhang
DRepMRec: A Dual Representation Learning Framework for Multimodal Recommendation
Apr 17, 2024
Multimodal Recommendation focuses mainly on how to effectively integrate behavior and multimodal information in the recommendation task. Previous works suffer from two major issues. Firstly, the training process tightly couples the behavior module and multimodal module by jointly optimizing them using the sharing model parameters, which leads to suboptimal performance since behavior signals and modality signals often provide opposite guidance for the parameters updates. Secondly, previous approaches fail to take into account the significant distribution differences between behavior and modality when they attempt to fuse behavior and modality information. This resulted in a misalignment between the representations of behavior and modality. To address these challenges, in this paper, we propose a novel Dual Representation learning framework for Multimodal Recommendation called DRepMRec, which introduce separate dual lines for coupling problem and Behavior-Modal Alignment (BMA) for misalignment problem. Specifically, DRepMRec leverages two independent lines of representation learning to calculate behavior and modal representations. After obtaining separate behavior and modal representations, we design a Behavior-Modal Alignment Module (BMA) to align and fuse the dual representations to solve the misalignment problem. Furthermore, we integrate the BMA into other recommendation models, resulting in consistent performance improvements. To ensure dual representations maintain their semantic independence during alignment, we introduce Similarity-Supervised Signal (SSS) for representation learning. We conduct extensive experiments on three public datasets and our method achieves state-of-the-art (SOTA) results. The source code will be available upon acceptance.
Recall-Augmented Ranking: Enhancing Click-Through Rate Prediction Accuracy with Cross-Stage Data
Apr 15, 2024Click-through rate (CTR) prediction plays an indispensable role in online platforms. Numerous models have been proposed to capture users' shifting preferences by leveraging user behavior sequences. However, these historical sequences often suffer from severe homogeneity and scarcity compared to the extensive item pool. Relying solely on such sequences for user representations is inherently restrictive, as user interests extend beyond the scope of items they have previously engaged with. To address this challenge, we propose a data-driven approach to enrich user representations. We recognize user profiling and recall items as two ideal data sources within the cross-stage framework, encompassing the u2u (user-to-user) and i2i (item-to-item) aspects respectively. In this paper, we propose a novel architecture named Recall-Augmented Ranking (RAR). RAR consists of two key sub-modules, which synergistically gather information from a vast pool of look-alike users and recall items, resulting in enriched user representations. Notably, RAR is orthogonal to many existing CTR models, allowing for consistent performance improvements in a plug-and-play manner. Extensive experiments are conducted, which verify the efficacy and compatibility of RAR against the SOTA methods.
M-scan: A Multi-Scenario Causal-driven Adaptive Network for Recommendation
Apr 15, 2024We primarily focus on the field of multi-scenario recommendation, which poses a significant challenge in effectively leveraging data from different scenarios to enhance predictions in scenarios with limited data. Current mainstream efforts mainly center around innovative model network architectures, with the aim of enabling the network to implicitly acquire knowledge from diverse scenarios. However, the uncertainty of implicit learning in networks arises from the absence of explicit modeling, leading to not only difficulty in training but also incomplete user representation and suboptimal performance. Furthermore, through causal graph analysis, we have discovered that the scenario itself directly influences click behavior, yet existing approaches directly incorporate data from other scenarios during the training of the current scenario, leading to prediction biases when they directly utilize click behaviors from other scenarios to train models. To address these problems, we propose the Multi-Scenario Causal-driven Adaptive Network M-scan). This model incorporates a Scenario-Aware Co-Attention mechanism that explicitly extracts user interests from other scenarios that align with the current scenario. Additionally, it employs a Scenario Bias Eliminator module utilizing causal counterfactual inference to mitigate biases introduced by data from other scenarios. Extensive experiments on two public datasets demonstrate the efficacy of our M-scan compared to the existing baseline models.
Play to Your Strengths: Collaborative Intelligence of Conventional Recommender Models and Large Language Models
Mar 25, 2024The rise of large language models (LLMs) has opened new opportunities in Recommender Systems (RSs) by enhancing user behavior modeling and content understanding. However, current approaches that integrate LLMs into RSs solely utilize either LLM or conventional recommender model (CRM) to generate final recommendations, without considering which data segments LLM or CRM excel in. To fill in this gap, we conduct experiments on MovieLens-1M and Amazon-Books datasets, and compare the performance of a representative CRM (DCNv2) and an LLM (LLaMA2-7B) on various groups of data samples. Our findings reveal that LLMs excel in data segments where CRMs exhibit lower confidence and precision, while samples where CRM excels are relatively challenging for LLM, requiring substantial training data and a long training time for comparable performance. This suggests potential synergies in the combination between LLM and CRM. Motivated by these insights, we propose Collaborative Recommendation with conventional Recommender and Large Language Model (dubbed \textit{CoReLLa}). In this framework, we first jointly train LLM and CRM and address the issue of decision boundary shifts through alignment loss. Then, the resource-efficient CRM, with a shorter inference time, handles simple and moderate samples, while LLM processes the small subset of challenging samples for CRM. Our experimental results demonstrate that CoReLLa outperforms state-of-the-art CRM and LLM methods significantly, underscoring its effectiveness in recommendation tasks.
An Aligning and Training Framework for Multimodal Recommendations
Mar 20, 2024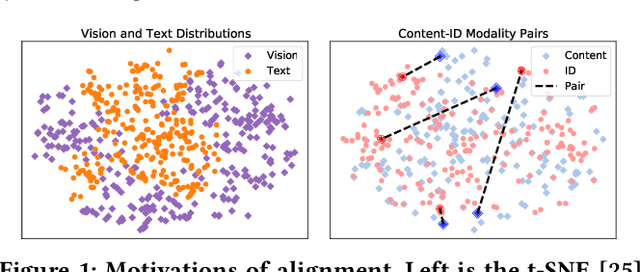
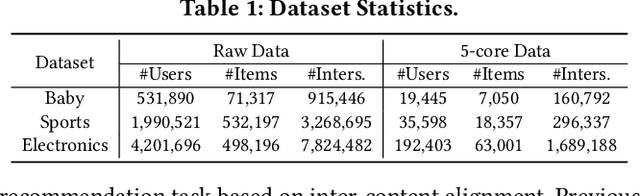
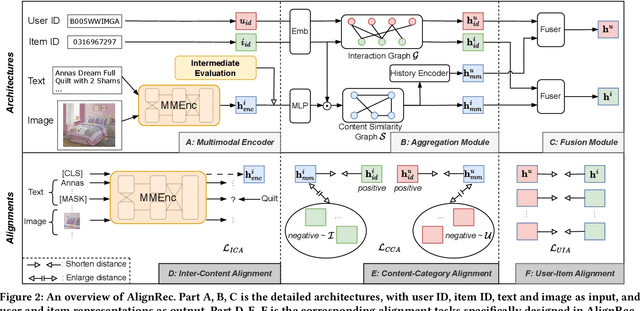
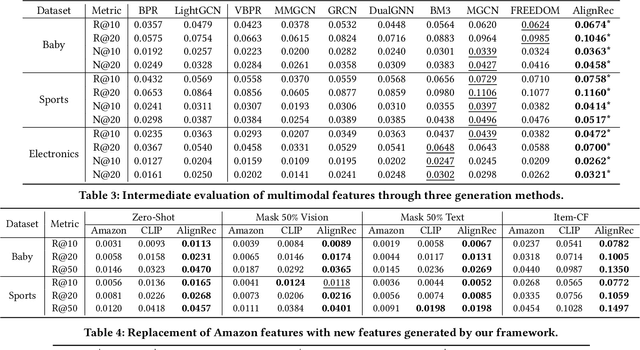
With the development of multimedia applications, multimodal recommendations are playing an essential role, as they can leverage rich contexts beyond user interactions. Existing methods mainly regard multimodal information as an auxiliary, using them to help learn ID features; however, there exist semantic gaps among multimodal content features and ID features, for which directly using multimodal information as an auxiliary would lead to misalignment in representations of users and items. In this paper, we first systematically investigate the misalignment issue in multimodal recommendations, and propose a solution named AlignRec. In AlignRec, the recommendation objective is decomposed into three alignments, namely alignment within contents, alignment between content and categorical ID, and alignment between users and items. Each alignment is characterized by a specific objective function and is integrated into our multimodal recommendation framework. To effectively train our AlignRec, we propose starting from pre-training the first alignment to obtain unified multimodal features and subsequently training the following two alignments together with these features as input. As it is essential to analyze whether each multimodal feature helps in training, we design three new classes of metrics to evaluate intermediate performance. Our extensive experiments on three real-world datasets consistently verify the superiority of AlignRec compared to nine baselines. We also find that the multimodal features generated by AlignRec are better than currently used ones, which are to be open-sourced.
TRAD: Enhancing LLM Agents with Step-Wise Thought Retrieval and Aligned Decision
Mar 10, 2024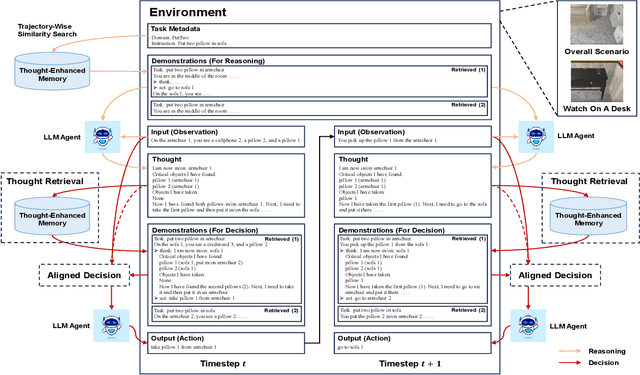

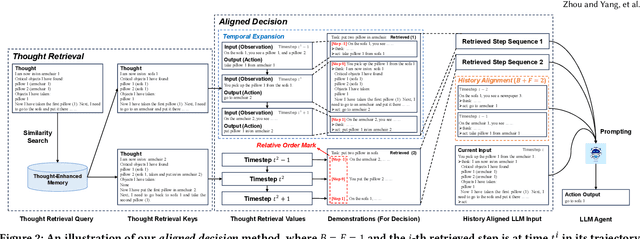

Numerous large language model (LLM) agents have been built for different tasks like web navigation and online shopping due to LLM's wide knowledge and text-understanding ability. Among these works, many of them utilize in-context examples to achieve generalization without the need for fine-tuning, while few of them have considered the problem of how to select and effectively utilize these examples. Recently, methods based on trajectory-level retrieval with task meta-data and using trajectories as in-context examples have been proposed to improve the agent's overall performance in some sequential decision making tasks. However, these methods can be problematic due to plausible examples retrieved without task-specific state transition dynamics and long input with plenty of irrelevant context. In this paper, we propose a novel framework (TRAD) to address these issues. TRAD first conducts Thought Retrieval, achieving step-level demonstration selection via thought matching, leading to more helpful demonstrations and less irrelevant input noise. Then, TRAD introduces Aligned Decision, complementing retrieved demonstration steps with their previous or subsequent steps, which enables tolerance for imperfect thought and provides a choice for balance between more context and less noise. Extensive experiments on ALFWorld and Mind2Web benchmarks show that TRAD not only outperforms state-of-the-art models but also effectively helps in reducing noise and promoting generalization. Furthermore, TRAD has been deployed in real-world scenarios of a global business insurance company and improves the success rate of robotic process automation.
Looking Ahead to Avoid Being Late: Solving Hard-Constrained Traveling Salesman Problem
Mar 08, 2024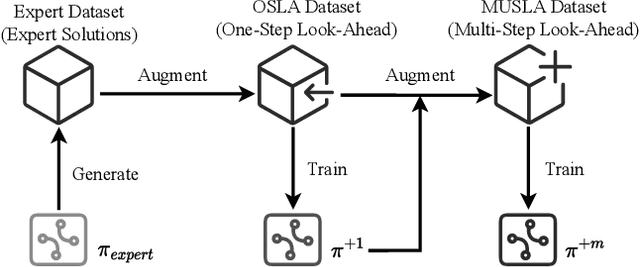
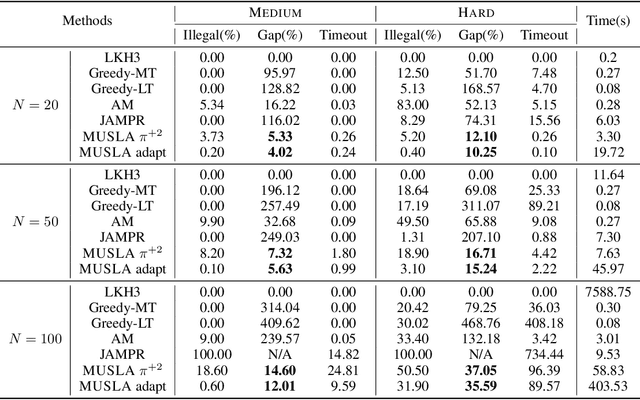
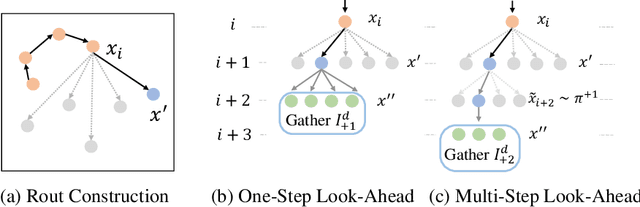
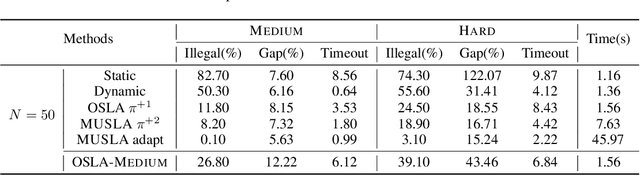
Many real-world problems can be formulated as a constrained Traveling Salesman Problem (TSP). However, the constraints are always complex and numerous, making the TSPs challenging to solve. When the number of complicated constraints grows, it is time-consuming for traditional heuristic algorithms to avoid illegitimate outcomes. Learning-based methods provide an alternative to solve TSPs in a soft manner, which also supports GPU acceleration to generate solutions quickly. Nevertheless, the soft manner inevitably results in difficulty solving hard-constrained problems with learning algorithms, and the conflicts between legality and optimality may substantially affect the optimality of the solution. To overcome this problem and to have an effective solution against hard constraints, we proposed a novel learning-based method that uses looking-ahead information as the feature to improve the legality of TSP with Time Windows (TSPTW) solutions. Besides, we constructed TSPTW datasets with hard constraints in order to accurately evaluate and benchmark the statistical performance of various approaches, which can serve the community for future research. With comprehensive experiments on diverse datasets, MUSLA outperforms existing baselines and shows generalizability potential.
Towards Efficient and Effective Unlearning of Large Language Models for Recommendation
Mar 06, 2024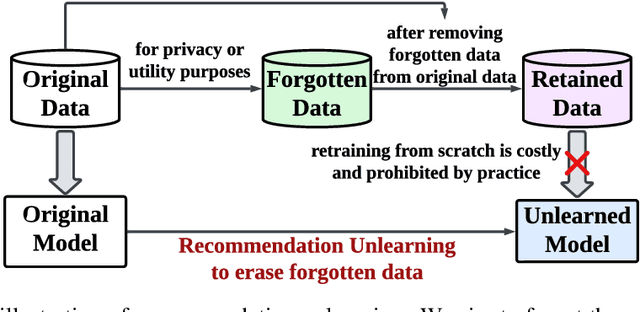
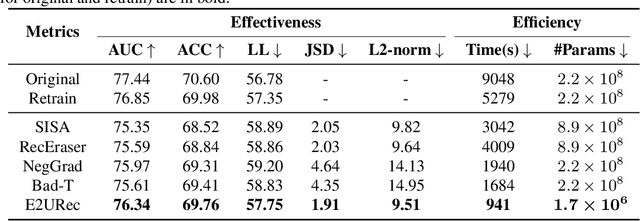
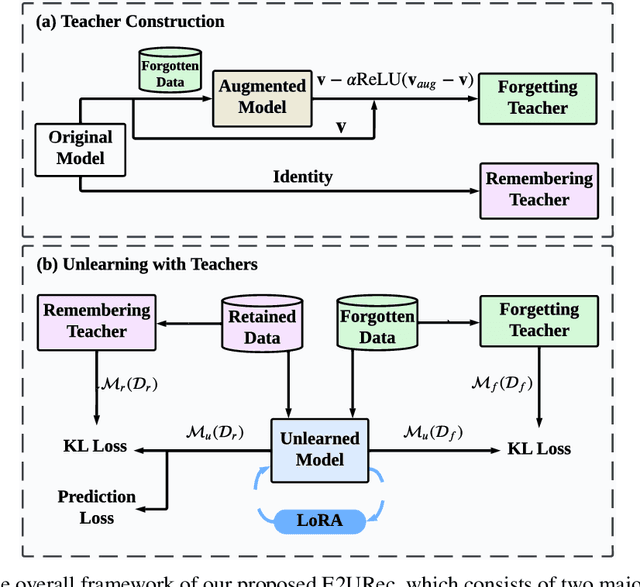
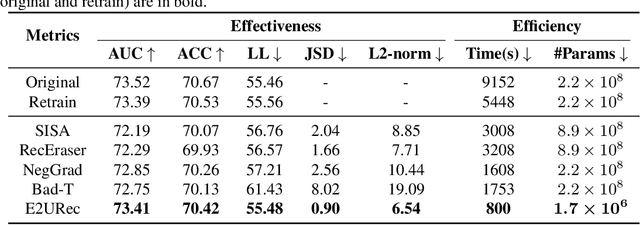
The significant advancements in large language models (LLMs) give rise to a promising research direction, i.e., leveraging LLMs as recommenders (LLMRec). The efficacy of LLMRec arises from the open-world knowledge and reasoning capabilities inherent in LLMs. LLMRec acquires the recommendation capabilities through instruction tuning based on user interaction data. However, in order to protect user privacy and optimize utility, it is also crucial for LLMRec to intentionally forget specific user data, which is generally referred to as recommendation unlearning. In the era of LLMs, recommendation unlearning poses new challenges for LLMRec in terms of \textit{inefficiency} and \textit{ineffectiveness}. Existing unlearning methods require updating billions of parameters in LLMRec, which is costly and time-consuming. Besides, they always impact the model utility during the unlearning process. To this end, we propose \textbf{E2URec}, the first \underline{E}fficient and \underline{E}ffective \underline{U}nlearning method for LLM\underline{Rec}. Our proposed E2URec enhances the unlearning efficiency by updating only a few additional LoRA parameters, and improves the unlearning effectiveness by employing a teacher-student framework, where we maintain multiple teacher networks to guide the unlearning process. Extensive experiments show that E2URec outperforms state-of-the-art baselines on two real-world datasets. Specifically, E2URec can efficiently forget specific data without affecting recommendation performance. The source code is at \url{https://github.com/justarter/E2URec}.
Offline Fictitious Self-Play for Competitive Games
Feb 29, 2024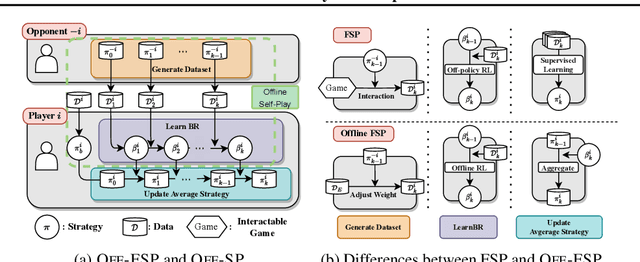
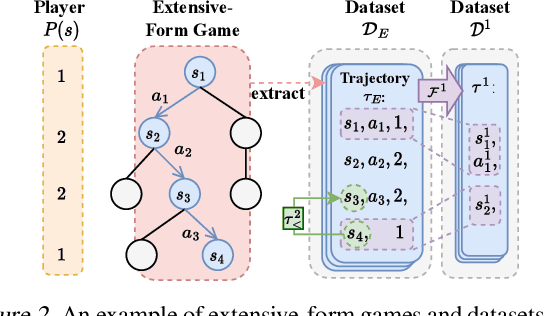
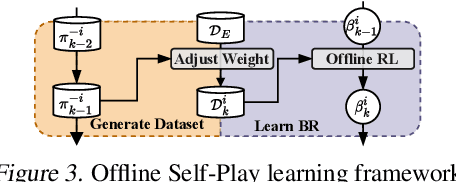
Offline Reinforcement Learning (RL) has received significant interest due to its ability to improve policies in previously collected datasets without online interactions. Despite its success in the single-agent setting, offline multi-agent RL remains a challenge, especially in competitive games. Firstly, unaware of the game structure, it is impossible to interact with the opponents and conduct a major learning paradigm, self-play, for competitive games. Secondly, real-world datasets cannot cover all the state and action space in the game, resulting in barriers to identifying Nash equilibrium (NE). To address these issues, this paper introduces Off-FSP, the first practical model-free offline RL algorithm for competitive games. We start by simulating interactions with various opponents by adjusting the weights of the fixed dataset with importance sampling. This technique allows us to learn best responses to different opponents and employ the Offline Self-Play learning framework. In this framework, we further implement Fictitious Self-Play (FSP) to approximate NE. In partially covered real-world datasets, our methods show the potential to approach NE by incorporating any single-agent offline RL method. Experimental results in Leduc Hold'em Poker show that our method significantly improves performances compared with state-of-the-art baselines.
Large-Scale Actionless Video Pre-Training via Discrete Diffusion for Efficient Policy Learning
Feb 22, 2024Learning a generalist embodied agent capable of completing multiple tasks poses challenges, primarily stemming from the scarcity of action-labeled robotic datasets. In contrast, a vast amount of human videos exist, capturing intricate tasks and interactions with the physical world. Promising prospects arise for utilizing actionless human videos for pre-training and transferring the knowledge to facilitate robot policy learning through limited robot demonstrations. In this paper, we introduce a novel framework that leverages a unified discrete diffusion to combine generative pre-training on human videos and policy fine-tuning on a small number of action-labeled robot videos. We start by compressing both human and robot videos into unified video tokens. In the pre-training stage, we employ a discrete diffusion model with a mask-and-replace diffusion strategy to predict future video tokens in the latent space. In the fine-tuning stage, we harness the imagined future videos to guide low-level action learning trained on a limited set of robot data. Experiments demonstrate that our method generates high-fidelity future videos for planning and enhances the fine-tuned policies compared to previous state-of-the-art approaches with superior generalization ability. Our project website is available at https://video-diff.github.io/.