 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBin Zhao
CrossMatch: Enhance Semi-Supervised Medical Image Segmentation with Perturbation Strategies and Knowledge Distillation
May 01, 2024
Semi-supervised learning for medical image segmentation presents a unique challenge of efficiently using limited labeled data while leveraging abundant unlabeled data. Despite advancements, existing methods often do not fully exploit the potential of the unlabeled data for enhancing model robustness and accuracy. In this paper, we introduce CrossMatch, a novel framework that integrates knowledge distillation with dual perturbation strategies-image-level and feature-level-to improve the model's learning from both labeled and unlabeled data. CrossMatch employs multiple encoders and decoders to generate diverse data streams, which undergo self-knowledge distillation to enhance consistency and reliability of predictions across varied perturbations. Our method significantly surpasses other state-of-the-art techniques in standard benchmarks by effectively minimizing the gap between training on labeled and unlabeled data and improving edge accuracy and generalization in medical image segmentation. The efficacy of CrossMatch is demonstrated through extensive experimental validations, showing remarkable performance improvements without increasing computational costs. Code for this implementation is made available at https://github.com/AiEson/CrossMatch.git.
Pessimistic Value Iteration for Multi-Task Data Sharing in Offline Reinforcement Learning
Apr 30, 2024Offline Reinforcement Learning (RL) has shown promising results in learning a task-specific policy from a fixed dataset. However, successful offline RL often relies heavily on the coverage and quality of the given dataset. In scenarios where the dataset for a specific task is limited, a natural approach is to improve offline RL with datasets from other tasks, namely, to conduct Multi-Task Data Sharing (MTDS). Nevertheless, directly sharing datasets from other tasks exacerbates the distribution shift in offline RL. In this paper, we propose an uncertainty-based MTDS approach that shares the entire dataset without data selection. Given ensemble-based uncertainty quantification, we perform pessimistic value iteration on the shared offline dataset, which provides a unified framework for single- and multi-task offline RL. We further provide theoretical analysis, which shows that the optimality gap of our method is only related to the expected data coverage of the shared dataset, thus resolving the distribution shift issue in data sharing. Empirically, we release an MTDS benchmark and collect datasets from three challenging domains. The experimental results show our algorithm outperforms the previous state-of-the-art methods in challenging MTDS problems. See https://github.com/Baichenjia/UTDS for the datasets and code.
S3-SLAM: Sparse Tri-plane Encoding for Neural Implicit SLAM
Apr 28, 2024With the emergence of Neural Radiance Fields (NeRF), neural implicit representations have gained widespread applications across various domains, including simultaneous localization and mapping. However, current neural implicit SLAM faces a challenging trade-off problem between performance and the number of parameters. To address this problem, we propose sparse tri-plane encoding, which efficiently achieves scene reconstruction at resolutions up to 512 using only 2~4% of the commonly used tri-plane parameters (reduced from 100MB to 2~4MB). On this basis, we design S3-SLAM to achieve rapid and high-quality tracking and mapping through sparsifying plane parameters and integrating orthogonal features of tri-plane. Furthermore, we develop hierarchical bundle adjustment to achieve globally consistent geometric structures and reconstruct high-resolution appearance. Experimental results demonstrate that our approach achieves competitive tracking and scene reconstruction with minimal parameters on three datasets. Source code will soon be available.
Any2Point: Empowering Any-modality Large Models for Efficient 3D Understanding
Apr 11, 2024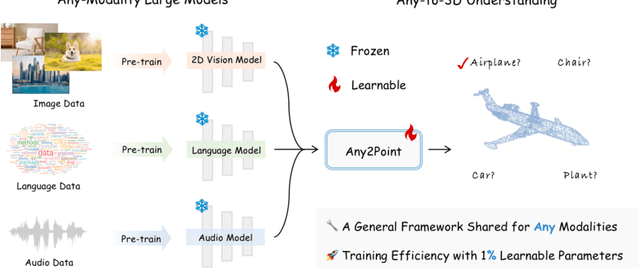
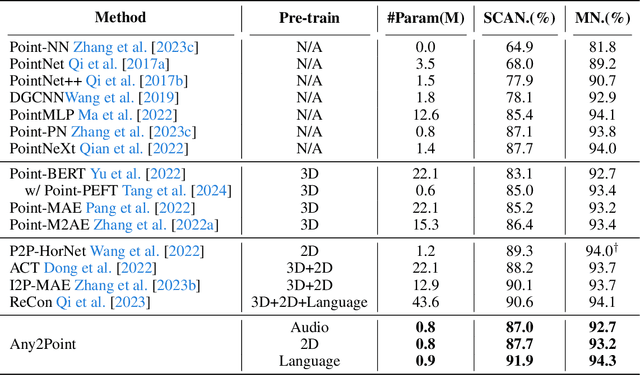
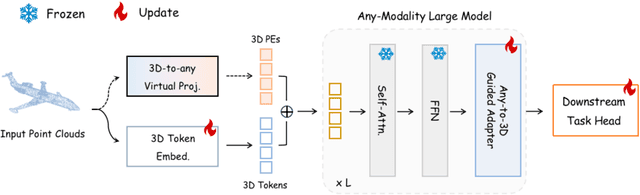

Large foundation models have recently emerged as a prominent focus of interest, attaining superior performance in widespread scenarios. Due to the scarcity of 3D data, many efforts have been made to adapt pre-trained transformers from vision to 3D domains. However, such 2D-to-3D approaches are still limited, due to the potential loss of spatial geometries and high computation cost. More importantly, their frameworks are mainly designed for 2D models, lacking a general any-to-3D paradigm. In this paper, we introduce Any2Point, a parameter-efficient method to empower any-modality large models (vision, language, audio) for 3D understanding. Given a frozen transformer from any source modality, we propose a 3D-to-any (1D or 2D) virtual projection strategy that correlates the input 3D points to the original 1D or 2D positions within the source modality. This mechanism enables us to assign each 3D token with a positional encoding paired with the pre-trained model, which avoids 3D geometry loss caused by the true projection and better motivates the transformer for 3D learning with 1D/2D positional priors. Then, within each transformer block, we insert an any-to-3D guided adapter module for parameter-efficient fine-tuning. The adapter incorporates prior spatial knowledge from the source modality to guide the local feature aggregation of 3D tokens, compelling the semantic adaption of any-modality transformers. We conduct extensive experiments to showcase the effectiveness and efficiency of our method. Code and models are released at https://github.com/Ivan-Tang-3D/Any2Point.
HPL-ESS: Hybrid Pseudo-Labeling for Unsupervised Event-based Semantic Segmentation
Mar 25, 2024Event-based semantic segmentation has gained popularity due to its capability to deal with scenarios under high-speed motion and extreme lighting conditions, which cannot be addressed by conventional RGB cameras. Since it is hard to annotate event data, previous approaches rely on event-to-image reconstruction to obtain pseudo labels for training. However, this will inevitably introduce noise, and learning from noisy pseudo labels, especially when generated from a single source, may reinforce the errors. This drawback is also called confirmation bias in pseudo-labeling. In this paper, we propose a novel hybrid pseudo-labeling framework for unsupervised event-based semantic segmentation, HPL-ESS, to alleviate the influence of noisy pseudo labels. In particular, we first employ a plain unsupervised domain adaptation framework as our baseline, which can generate a set of pseudo labels through self-training. Then, we incorporate offline event-to-image reconstruction into the framework, and obtain another set of pseudo labels by predicting segmentation maps on the reconstructed images. A noisy label learning strategy is designed to mix the two sets of pseudo labels and enhance the quality. Moreover, we propose a soft prototypical alignment module to further improve the consistency of target domain features. Extensive experiments show that our proposed method outperforms existing state-of-the-art methods by a large margin on the DSEC-Semantic dataset (+5.88% accuracy, +10.32% mIoU), which even surpasses several supervised methods.
Large-Scale Actionless Video Pre-Training via Discrete Diffusion for Efficient Policy Learning
Feb 22, 2024Learning a generalist embodied agent capable of completing multiple tasks poses challenges, primarily stemming from the scarcity of action-labeled robotic datasets. In contrast, a vast amount of human videos exist, capturing intricate tasks and interactions with the physical world. Promising prospects arise for utilizing actionless human videos for pre-training and transferring the knowledge to facilitate robot policy learning through limited robot demonstrations. In this paper, we introduce a novel framework that leverages a unified discrete diffusion to combine generative pre-training on human videos and policy fine-tuning on a small number of action-labeled robot videos. We start by compressing both human and robot videos into unified video tokens. In the pre-training stage, we employ a discrete diffusion model with a mask-and-replace diffusion strategy to predict future video tokens in the latent space. In the fine-tuning stage, we harness the imagined future videos to guide low-level action learning trained on a limited set of robot data. Experiments demonstrate that our method generates high-fidelity future videos for planning and enhances the fine-tuned policies compared to previous state-of-the-art approaches with superior generalization ability. Our project website is available at https://video-diff.github.io/.
Motion-Aware Video Frame Interpolation
Feb 05, 2024Video frame interpolation methodologies endeavor to create novel frames betwixt extant ones, with the intent of augmenting the video's frame frequency. However, current methods are prone to image blurring and spurious artifacts in challenging scenarios involving occlusions and discontinuous motion. Moreover, they typically rely on optical flow estimation, which adds complexity to modeling and computational costs. To address these issues, we introduce a Motion-Aware Video Frame Interpolation (MA-VFI) network, which directly estimates intermediate optical flow from consecutive frames by introducing a novel hierarchical pyramid module. It not only extracts global semantic relationships and spatial details from input frames with different receptive fields, enabling the model to capture intricate motion patterns, but also effectively reduces the required computational cost and complexity. Subsequently, a cross-scale motion structure is presented to estimate and refine intermediate flow maps by the extracted features. This approach facilitates the interplay between input frame features and flow maps during the frame interpolation process and markedly heightens the precision of the intervening flow delineations. Finally, a discerningly fashioned loss centered around an intermediate flow is meticulously contrived, serving as a deft rudder to skillfully guide the prognostication of said intermediate flow, thereby substantially refining the precision of the intervening flow mappings. Experiments illustrate that MA-VFI surpasses several representative VFI methods across various datasets, and can enhance efficiency while maintaining commendable efficacy.
Vehicle Perception from Satellite
Feb 01, 2024Satellites are capable of capturing high-resolution videos. It makes vehicle perception from satellite become possible. Compared to street surveillance, drive recorder or other equipments, satellite videos provide a much broader city-scale view, so that the global dynamic scene of the traffic are captured and displayed. Traffic monitoring from satellite is a new task with great potential applications, including traffic jams prediction, path planning, vehicle dispatching, \emph{etc.}. Practically, limited by the resolution and view, the captured vehicles are very tiny (a few pixels) and move slowly. Worse still, these satellites are in Low Earth Orbit (LEO) to capture such high-resolution videos, so the background is also moving. Under this circumstance, traffic monitoring from the satellite view is an extremely challenging task. To attract more researchers into this field, we build a large-scale benchmark for traffic monitoring from satellite. It supports several tasks, including tiny object detection, counting and density estimation. The dataset is constructed based on 12 satellite videos and 14 synthetic videos recorded from GTA-V. They are separated into 408 video clips, which contain 7,336 real satellite images and 1,960 synthetic images. 128,801 vehicles are annotated totally, and the number of vehicles in each image varies from 0 to 101. Several classic and state-of-the-art approaches in traditional computer vision are evaluated on the datasets, so as to compare the performance of different approaches, analyze the challenges in this task, and discuss the future prospects. The dataset is available at: https://github.com/Chenxi1510/Vehicle-Perception-from-Satellite-Videos.
X4D-SceneFormer: Enhanced Scene Understanding on 4D Point Cloud Videos through Cross-modal Knowledge Transfer
Dec 12, 2023The field of 4D point cloud understanding is rapidly developing with the goal of analyzing dynamic 3D point cloud sequences. However, it remains a challenging task due to the sparsity and lack of texture in point clouds. Moreover, the irregularity of point cloud poses a difficulty in aligning temporal information within video sequences. To address these issues, we propose a novel cross-modal knowledge transfer framework, called X4D-SceneFormer. This framework enhances 4D-Scene understanding by transferring texture priors from RGB sequences using a Transformer architecture with temporal relationship mining. Specifically, the framework is designed with a dual-branch architecture, consisting of an 4D point cloud transformer and a Gradient-aware Image Transformer (GIT). During training, we employ multiple knowledge transfer techniques, including temporal consistency losses and masked self-attention, to strengthen the knowledge transfer between modalities. This leads to enhanced performance during inference using single-modal 4D point cloud inputs. Extensive experiments demonstrate the superior performance of our framework on various 4D point cloud video understanding tasks, including action recognition, action segmentation and semantic segmentation. The results achieve 1st places, i.e., 85.3% (+7.9%) accuracy and 47.3% (+5.0%) mIoU for 4D action segmentation and semantic segmentation, on the HOI4D challenge\footnote{\url{http://www.hoi4d.top/}.}, outperforming previous state-of-the-art by a large margin. We release the code at https://github.com/jinglinglingling/X4D
Calibration-free quantitative phase imaging in multi-core fiber endoscopes using end-to-end deep learning
Dec 12, 2023Quantitative phase imaging (QPI) through multi-core fibers (MCFs) has been an emerging in vivo label-free endoscopic imaging modality with minimal invasiveness. However, the computational demands of conventional iterative phase retrieval algorithms have limited their real-time imaging potential. We demonstrate a learning-based MCF phase imaging method, that significantly reduced the phase reconstruction time to 5.5 ms, enabling video-rate imaging at 181 fps. Moreover, we introduce an innovative optical system that automatically generated the first open-source dataset tailored for MCF phase imaging, comprising 50,176 paired speckle and phase images. Our trained deep neural network (DNN) demonstrates robust phase reconstruction performance in experiments with a mean fidelity of up to 99.8\%. Such an efficient fiber phase imaging approach can broaden the applications of QPI in hard-to-reach areas.