 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaoran He
Regularized Conditional Diffusion Model for Multi-Task Preference Alignment
Apr 07, 2024
Sequential decision-making is desired to align with human intents and exhibit versatility across various tasks. Previous methods formulate it as a conditional generation process, utilizing return-conditioned diffusion models to directly model trajectory distributions. Nevertheless, the return-conditioned paradigm relies on pre-defined reward functions, facing challenges when applied in multi-task settings characterized by varying reward functions (versatility) and showing limited controllability concerning human preferences (alignment). In this work, we adopt multi-task preferences as a unified condition for both single- and multi-task decision-making, and propose preference representations aligned with preference labels. The learned representations are used to guide the conditional generation process of diffusion models, and we introduce an auxiliary objective to maximize the mutual information between representations and corresponding generated trajectories, improving alignment between trajectories and preferences. Extensive experiments in D4RL and Meta-World demonstrate that our method presents favorable performance in single- and multi-task scenarios, and exhibits superior alignment with preferences.
Large-Scale Actionless Video Pre-Training via Discrete Diffusion for Efficient Policy Learning
Feb 22, 2024Learning a generalist embodied agent capable of completing multiple tasks poses challenges, primarily stemming from the scarcity of action-labeled robotic datasets. In contrast, a vast amount of human videos exist, capturing intricate tasks and interactions with the physical world. Promising prospects arise for utilizing actionless human videos for pre-training and transferring the knowledge to facilitate robot policy learning through limited robot demonstrations. In this paper, we introduce a novel framework that leverages a unified discrete diffusion to combine generative pre-training on human videos and policy fine-tuning on a small number of action-labeled robot videos. We start by compressing both human and robot videos into unified video tokens. In the pre-training stage, we employ a discrete diffusion model with a mask-and-replace diffusion strategy to predict future video tokens in the latent space. In the fine-tuning stage, we harness the imagined future videos to guide low-level action learning trained on a limited set of robot data. Experiments demonstrate that our method generates high-fidelity future videos for planning and enhances the fine-tuned policies compared to previous state-of-the-art approaches with superior generalization ability. Our project website is available at https://video-diff.github.io/.
Diffusion Models for Reinforcement Learning: A Survey
Nov 02, 2023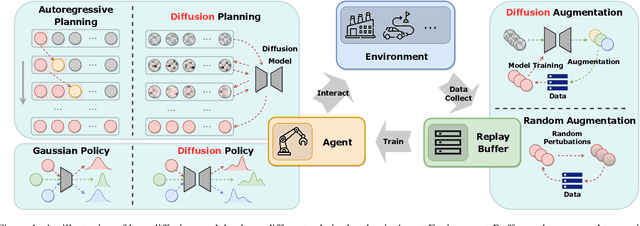


Diffusion models have emerged as a prominent class of generative models, surpassing previous methods regarding sample quality and training stability. Recent works have shown the advantages of diffusion models in improving reinforcement learning (RL) solutions, including as trajectory planners, expressive policy classes, data synthesizers, etc. This survey aims to provide an overview of the advancements in this emerging field and hopes to inspire new avenues of research. First, we examine several challenges encountered by current RL algorithms. Then, we present a taxonomy of existing methods based on the roles played by diffusion models in RL and explore how the existing challenges are addressed. We further outline successful applications of diffusion models in various RL-related tasks while discussing the limitations of current approaches. Finally, we conclude the survey and offer insights into future research directions, focusing on enhancing model performance and applying diffusion models to broader tasks. We are actively maintaining a GitHub repository for papers and other related resources in applying diffusion models in RL: https://github.com/apexrl/Diff4RLSurvey .
Robust Quadrupedal Locomotion via Risk-Averse Policy Learning
Sep 01, 2023
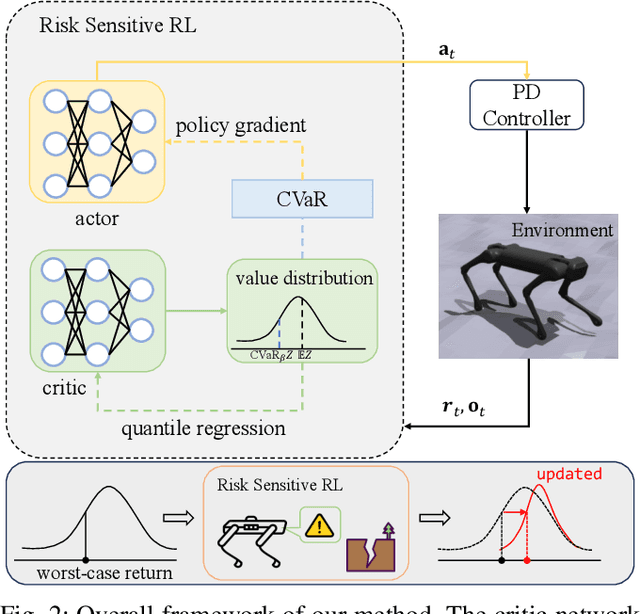
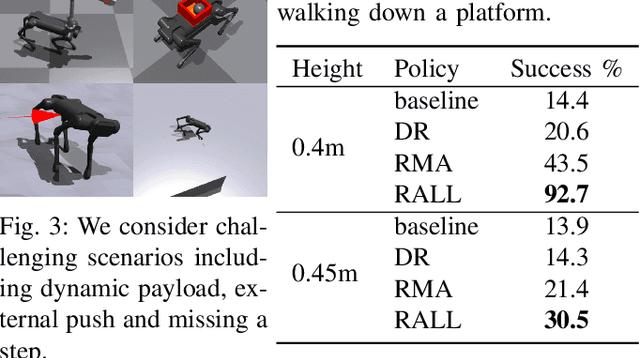

The robustness of legged locomotion is crucial for quadrupedal robots in challenging terrains. Recently, Reinforcement Learning (RL) has shown promising results in legged locomotion and various methods try to integrate privileged distillation, scene modeling, and external sensors to improve the generalization and robustness of locomotion policies. However, these methods are hard to handle uncertain scenarios such as abrupt terrain changes or unexpected external forces. In this paper, we consider a novel risk-sensitive perspective to enhance the robustness of legged locomotion. Specifically, we employ a distributional value function learned by quantile regression to model the aleatoric uncertainty of environments, and perform risk-averse policy learning by optimizing the worst-case scenarios via a risk distortion measure. Extensive experiments in both simulation environments and a real Aliengo robot demonstrate that our method is efficient in handling various external disturbances, and the resulting policy exhibits improved robustness in harsh and uncertain situations in legged locomotion. Videos are available at https://risk-averse-locomotion.github.io/.
Privileged Knowledge Distillation for Sim-to-Real Policy Generalization
May 29, 2023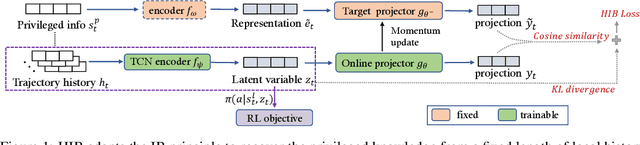
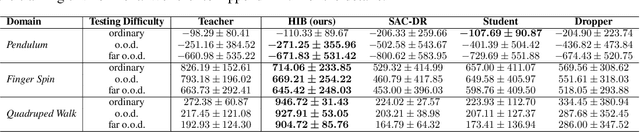


Reinforcement Learning (RL) has recently achieved remarkable success in robotic control. However, most RL methods operate in simulated environments where privileged knowledge (e.g., dynamics, surroundings, terrains) is readily available. Conversely, in real-world scenarios, robot agents usually rely solely on local states (e.g., proprioceptive feedback of robot joints) to select actions, leading to a significant sim-to-real gap. Existing methods address this gap by either gradually reducing the reliance on privileged knowledge or performing a two-stage policy imitation. However, we argue that these methods are limited in their ability to fully leverage the privileged knowledge, resulting in suboptimal performance. In this paper, we propose a novel single-stage privileged knowledge distillation method called the Historical Information Bottleneck (HIB) to narrow the sim-to-real gap. In particular, HIB learns a privileged knowledge representation from historical trajectories by capturing the underlying changeable dynamic information. Theoretical analysis shows that the learned privileged knowledge representation helps reduce the value discrepancy between the oracle and learned policies. Empirical experiments on both simulated and real-world tasks demonstrate that HIB yields improved generalizability compared to previous methods.
Diffusion Model is an Effective Planner and Data Synthesizer for Multi-Task Reinforcement Learning
May 29, 2023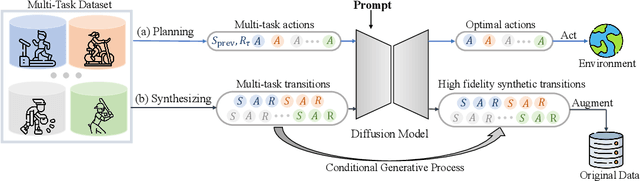



Diffusion models have demonstrated highly-expressive generative capabilities in vision and NLP. Recent studies in reinforcement learning (RL) have shown that diffusion models are also powerful in modeling complex policies or trajectories in offline datasets. However, these works have been limited to single-task settings where a generalist agent capable of addressing multi-task predicaments is absent. In this paper, we aim to investigate the effectiveness of a single diffusion model in modeling large-scale multi-task offline data, which can be challenging due to diverse and multimodal data distribution. Specifically, we propose Multi-Task Diffusion Model (\textsc{MTDiff}), a diffusion-based method that incorporates Transformer backbones and prompt learning for generative planning and data synthesis in multi-task offline settings. \textsc{MTDiff} leverages vast amounts of knowledge available in multi-task data and performs implicit knowledge sharing among tasks. For generative planning, we find \textsc{MTDiff} outperforms state-of-the-art algorithms across 50 tasks on Meta-World and 8 maps on Maze2D. For data synthesis, \textsc{MTDiff} generates high-quality data for testing tasks given a single demonstration as a prompt, which enhances the low-quality datasets for even unseen tasks.
On the Value of Myopic Behavior in Policy Reuse
May 28, 2023



Leveraging learned strategies in unfamiliar scenarios is fundamental to human intelligence. In reinforcement learning, rationally reusing the policies acquired from other tasks or human experts is critical for tackling problems that are difficult to learn from scratch. In this work, we present a framework called Selective Myopic bEhavior Control~(SMEC), which results from the insight that the short-term behaviors of prior policies are sharable across tasks. By evaluating the behaviors of prior policies via a hybrid value function architecture, SMEC adaptively aggregates the sharable short-term behaviors of prior policies and the long-term behaviors of the task policy, leading to coordinated decisions. Empirical results on a collection of manipulation and locomotion tasks demonstrate that SMEC outperforms existing methods, and validate the ability of SMEC to leverage related prior policies.