 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJianghao Lin
Retrieval-Oriented Knowledge for Click-Through Rate Prediction
Apr 28, 2024




Click-through rate (CTR) prediction plays an important role in personalized recommendations. Recently, sample-level retrieval-based models (e.g., RIM) have achieved remarkable performance by retrieving and aggregating relevant samples. However, their inefficiency at the inference stage makes them impractical for industrial applications. To overcome this issue, this paper proposes a universal plug-and-play Retrieval-Oriented Knowledge (ROK) framework. Specifically, a knowledge base, consisting of a retrieval-oriented embedding layer and a knowledge encoder, is designed to preserve and imitate the retrieved & aggregated representations in a decomposition-reconstruction paradigm. Knowledge distillation and contrastive learning methods are utilized to optimize the knowledge base, and the learned retrieval-enhanced representations can be integrated with arbitrary CTR models in both instance-wise and feature-wise manners. Extensive experiments on three large-scale datasets show that ROK achieves competitive performance with the retrieval-based CTR models while reserving superior inference efficiency and model compatibility.
M-scan: A Multi-Scenario Causal-driven Adaptive Network for Recommendation
Apr 15, 2024We primarily focus on the field of multi-scenario recommendation, which poses a significant challenge in effectively leveraging data from different scenarios to enhance predictions in scenarios with limited data. Current mainstream efforts mainly center around innovative model network architectures, with the aim of enabling the network to implicitly acquire knowledge from diverse scenarios. However, the uncertainty of implicit learning in networks arises from the absence of explicit modeling, leading to not only difficulty in training but also incomplete user representation and suboptimal performance. Furthermore, through causal graph analysis, we have discovered that the scenario itself directly influences click behavior, yet existing approaches directly incorporate data from other scenarios during the training of the current scenario, leading to prediction biases when they directly utilize click behaviors from other scenarios to train models. To address these problems, we propose the Multi-Scenario Causal-driven Adaptive Network M-scan). This model incorporates a Scenario-Aware Co-Attention mechanism that explicitly extracts user interests from other scenarios that align with the current scenario. Additionally, it employs a Scenario Bias Eliminator module utilizing causal counterfactual inference to mitigate biases introduced by data from other scenarios. Extensive experiments on two public datasets demonstrate the efficacy of our M-scan compared to the existing baseline models.
Play to Your Strengths: Collaborative Intelligence of Conventional Recommender Models and Large Language Models
Mar 25, 2024The rise of large language models (LLMs) has opened new opportunities in Recommender Systems (RSs) by enhancing user behavior modeling and content understanding. However, current approaches that integrate LLMs into RSs solely utilize either LLM or conventional recommender model (CRM) to generate final recommendations, without considering which data segments LLM or CRM excel in. To fill in this gap, we conduct experiments on MovieLens-1M and Amazon-Books datasets, and compare the performance of a representative CRM (DCNv2) and an LLM (LLaMA2-7B) on various groups of data samples. Our findings reveal that LLMs excel in data segments where CRMs exhibit lower confidence and precision, while samples where CRM excels are relatively challenging for LLM, requiring substantial training data and a long training time for comparable performance. This suggests potential synergies in the combination between LLM and CRM. Motivated by these insights, we propose Collaborative Recommendation with conventional Recommender and Large Language Model (dubbed \textit{CoReLLa}). In this framework, we first jointly train LLM and CRM and address the issue of decision boundary shifts through alignment loss. Then, the resource-efficient CRM, with a shorter inference time, handles simple and moderate samples, while LLM processes the small subset of challenging samples for CRM. Our experimental results demonstrate that CoReLLa outperforms state-of-the-art CRM and LLM methods significantly, underscoring its effectiveness in recommendation tasks.
Towards Efficient and Effective Unlearning of Large Language Models for Recommendation
Mar 06, 2024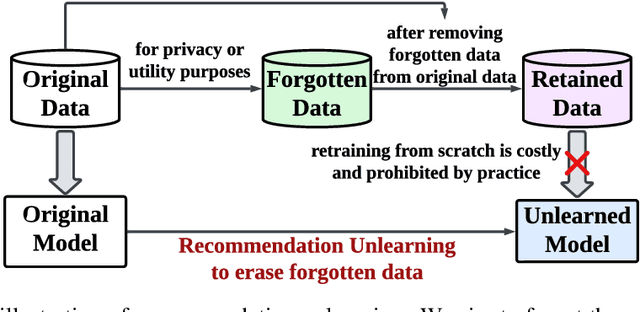
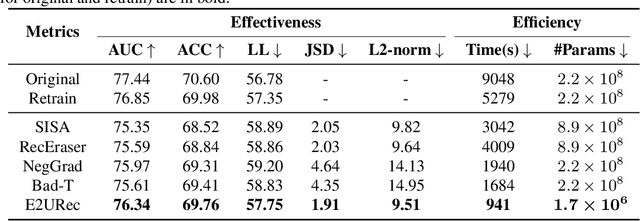
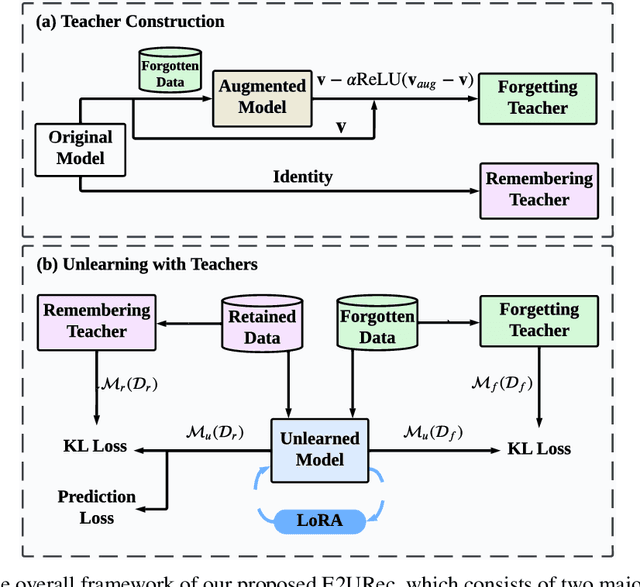
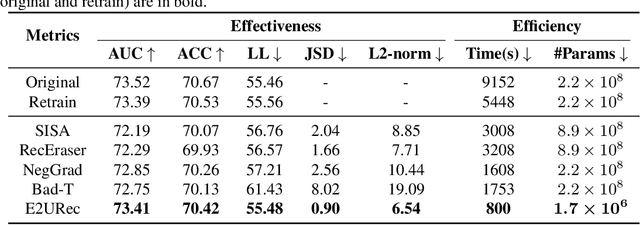
The significant advancements in large language models (LLMs) give rise to a promising research direction, i.e., leveraging LLMs as recommenders (LLMRec). The efficacy of LLMRec arises from the open-world knowledge and reasoning capabilities inherent in LLMs. LLMRec acquires the recommendation capabilities through instruction tuning based on user interaction data. However, in order to protect user privacy and optimize utility, it is also crucial for LLMRec to intentionally forget specific user data, which is generally referred to as recommendation unlearning. In the era of LLMs, recommendation unlearning poses new challenges for LLMRec in terms of \textit{inefficiency} and \textit{ineffectiveness}. Existing unlearning methods require updating billions of parameters in LLMRec, which is costly and time-consuming. Besides, they always impact the model utility during the unlearning process. To this end, we propose \textbf{E2URec}, the first \underline{E}fficient and \underline{E}ffective \underline{U}nlearning method for LLM\underline{Rec}. Our proposed E2URec enhances the unlearning efficiency by updating only a few additional LoRA parameters, and improves the unlearning effectiveness by employing a teacher-student framework, where we maintain multiple teacher networks to guide the unlearning process. Extensive experiments show that E2URec outperforms state-of-the-art baselines on two real-world datasets. Specifically, E2URec can efficiently forget specific data without affecting recommendation performance. The source code is at \url{https://github.com/justarter/E2URec}.
Mamba4Rec: Towards Efficient Sequential Recommendation with Selective State Space Models
Mar 06, 2024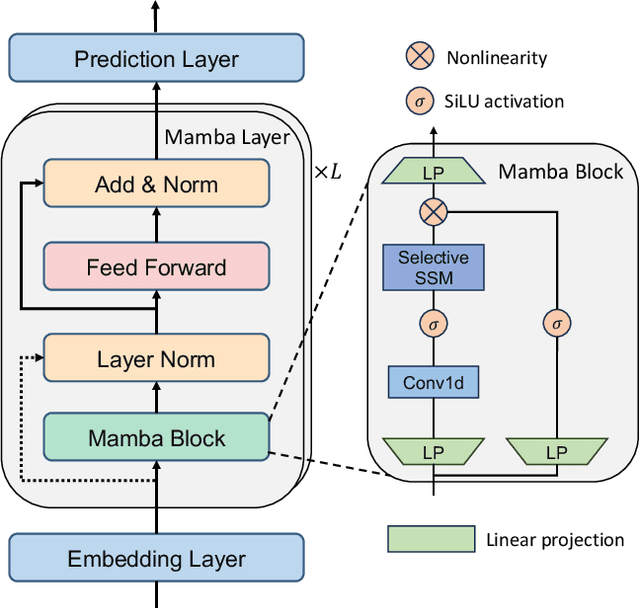



Sequential recommendation aims to estimate the dynamic user preferences and sequential dependencies among historical user behaviors. Although Transformer-based models have proven to be effective for sequential recommendation, they suffer from the inference inefficiency problem stemming from the quadratic computational complexity of attention operators, especially for long-range behavior sequences. Inspired by the recent success of state space models (SSMs), we propose Mamba4Rec, which is the first work to explore the potential of selective SSMs for efficient sequential recommendation. Built upon the basic Mamba block which is a selective SSM with an efficient hardware-aware parallel algorithm, we incorporate a series of sequential modeling techniques to further promote the model performance and meanwhile maintain the inference efficiency. Experiments on two public datasets demonstrate that Mamba4Rec is able to well address the effectiveness-efficiency dilemma, and defeat both RNN- and attention-based baselines in terms of both effectiveness and efficiency.
ALT: Towards Fine-grained Alignment between Language and CTR Models for Click-Through Rate Prediction
Oct 30, 2023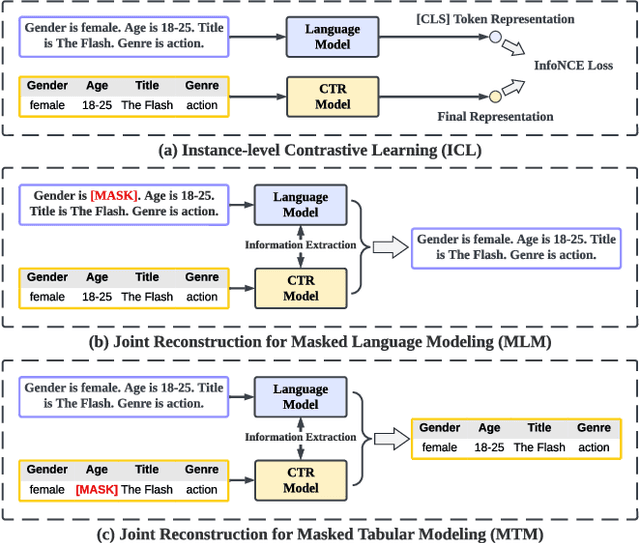
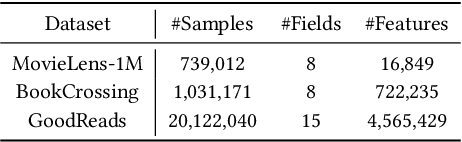

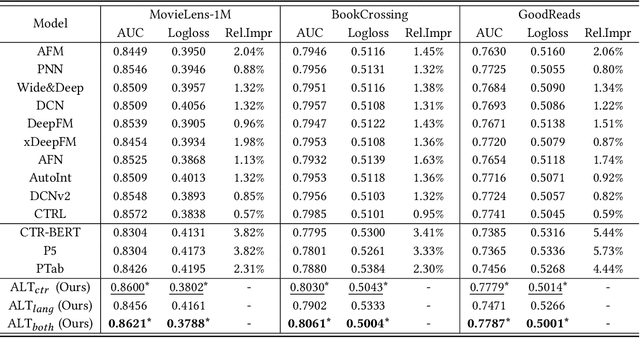
Click-through rate (CTR) prediction plays as a core function module in various personalized online services. According to the data modality and input format, the models for CTR prediction can be mainly classified into two categories. The first one is the traditional CTR models that take as inputs the one-hot encoded ID features of tabular modality, which aims to capture the collaborative signals via feature interaction modeling. The second category takes as inputs the sentences of textual modality obtained by hard prompt templates, where pretrained language models (PLMs) are adopted to extract the semantic knowledge. These two lines of research generally focus on different characteristics of the same input data (i.e., textual and tabular modalities), forming a distinct complementary relationship with each other. Therefore, in this paper, we propose to conduct fine-grained feature-level Alignment between Language and CTR models (ALT) for CTR prediction. Apart from the common CLIP-like instance-level contrastive learning, we further design a novel joint reconstruction pretraining task for both masked language and tabular modeling. Specifically, the masked data of one modality (i.e., tokens or features) has to be recovered with the help of the other modality, which establishes the feature-level interaction and alignment via sufficient mutual information extraction between dual modalities. Moreover, we propose three different finetuning strategies with the option to train the aligned language and CTR models separately or jointly for downstream CTR prediction tasks, thus accommodating the varying efficacy and efficiency requirements for industrial applications. Extensive experiments on three real-world datasets demonstrate that ALT outperforms SOTA baselines, and is highly compatible for various language and CTR models.
ClickPrompt: CTR Models are Strong Prompt Generators for Adapting Language Models to CTR Prediction
Oct 17, 2023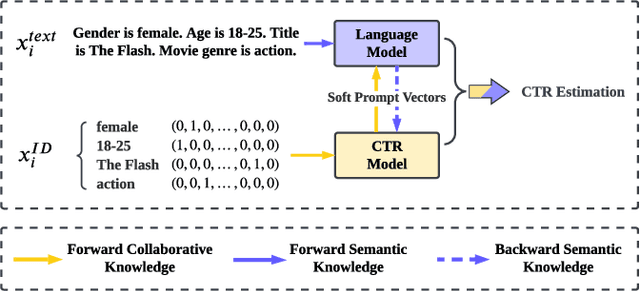
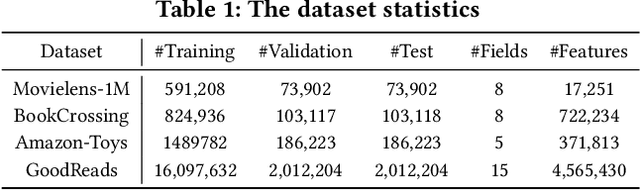
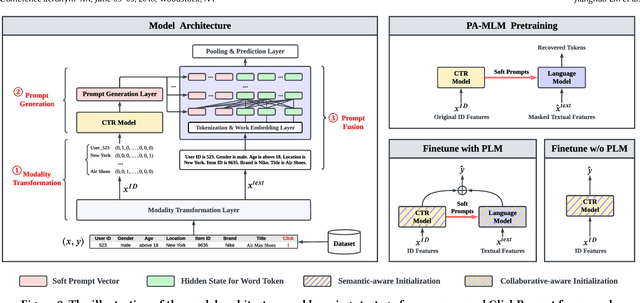
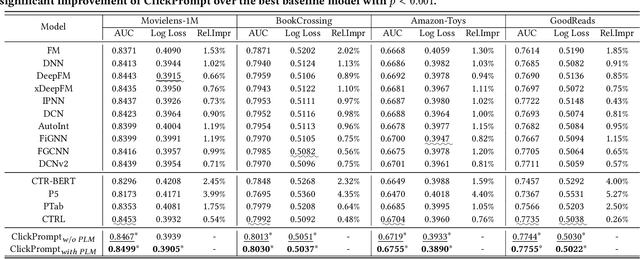
Click-through rate (CTR) prediction has become increasingly indispensable for various Internet applications. Traditional CTR models convert the multi-field categorical data into ID features via one-hot encoding, and extract the collaborative signals among features. Such a paradigm suffers from the problem of semantic information loss. Another line of research explores the potential of pretrained language models (PLMs) for CTR prediction by converting input data into textual sentences through hard prompt templates. Although semantic signals are preserved, they generally fail to capture the collaborative information (e.g., feature interactions, pure ID features), not to mention the unacceptable inference overhead brought by the huge model size. In this paper, we aim to model both the semantic knowledge and collaborative knowledge for accurate CTR estimation, and meanwhile address the inference inefficiency issue. To benefit from both worlds and close their gaps, we propose a novel model-agnostic framework (i.e., ClickPrompt), where we incorporate CTR models to generate interaction-aware soft prompts for PLMs. We design a prompt-augmented masked language modeling (PA-MLM) pretraining task, where PLM has to recover the masked tokens based on the language context, as well as the soft prompts generated by CTR model. The collaborative and semantic knowledge from ID and textual features would be explicitly aligned and interacted via the prompt interface. Then, we can either tune the CTR model with PLM for superior performance, or solely tune the CTR model without PLM for inference efficiency. Experiments on four real-world datasets validate the effectiveness of ClickPrompt compared with existing baselines.
CodeApex: A Bilingual Programming Evaluation Benchmark for Large Language Models
Sep 10, 2023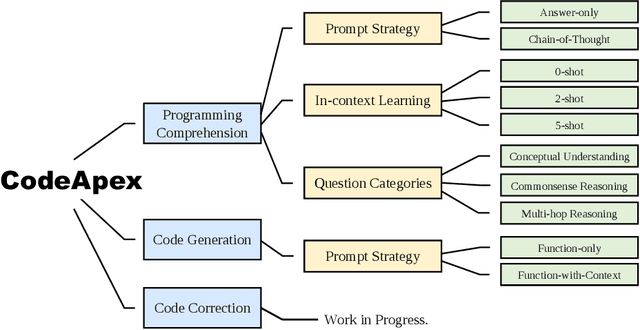

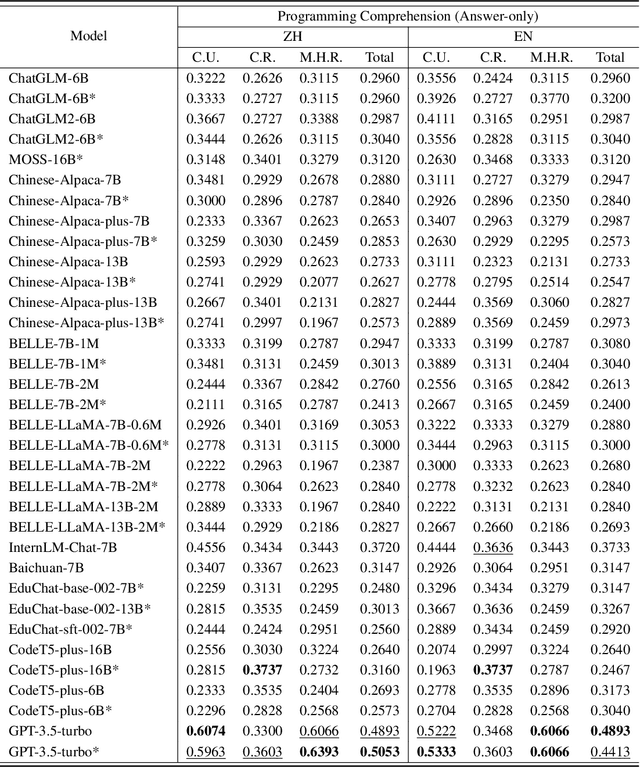
With the emergence of Large Language Models (LLMs), there has been a significant improvement in the programming capabilities of models, attracting growing attention from researchers. We propose CodeApex, a bilingual benchmark dataset focusing on the programming comprehension and code generation abilities of LLMs. CodeApex comprises three types of multiple-choice questions: conceptual understanding, commonsense reasoning, and multi-hop reasoning, designed to evaluate LLMs on programming comprehension tasks. Additionally, CodeApex utilizes algorithmic questions and corresponding test cases to assess the code quality generated by LLMs. We evaluate 14 state-of-the-art LLMs, including both general-purpose and specialized models. GPT exhibits the best programming capabilities, achieving approximate accuracies of 50% and 56% on the two tasks, respectively. There is still significant room for improvement in programming tasks. We hope that CodeApex can serve as a reference for evaluating the coding capabilities of LLMs, further promoting their development and growth. Datasets are released at https://github.com/APEXLAB/CodeApex.git. CodeApex submission website is https://apex.sjtu.edu.cn/codeapex/.
ReLLa: Retrieval-enhanced Large Language Models for Lifelong Sequential Behavior Comprehension in Recommendation
Aug 22, 2023
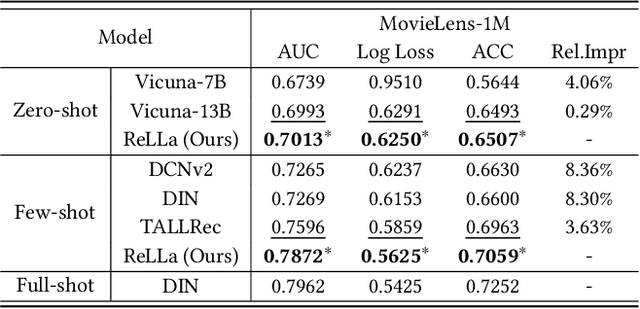

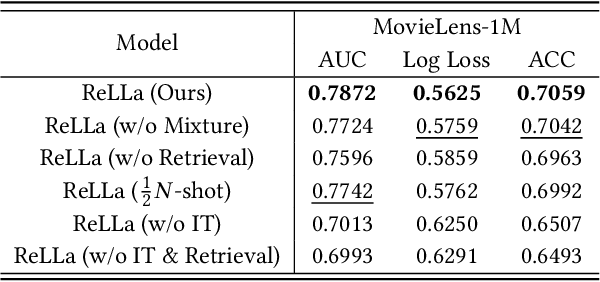
With large language models (LLMs) achieving remarkable breakthroughs in natural language processing (NLP) domains, LLM-enhanced recommender systems have received much attention and have been actively explored currently. In this paper, we focus on adapting and empowering a pure large language model for zero-shot and few-shot recommendation tasks. First and foremost, we identify and formulate the lifelong sequential behavior incomprehension problem for LLMs in recommendation domains, i.e., LLMs fail to extract useful information from a textual context of long user behavior sequence, even if the length of context is far from reaching the context limitation of LLMs. To address such an issue and improve the recommendation performance of LLMs, we propose a novel framework, namely Retrieval-enhanced Large Language models (ReLLa) for recommendation tasks in both zero-shot and few-shot settings. For zero-shot recommendation, we perform semantic user behavior retrieval (SUBR) to improve the data quality of testing samples, which greatly reduces the difficulty for LLMs to extract the essential knowledge from user behavior sequences. As for few-shot recommendation, we further design retrieval-enhanced instruction tuning (ReiT) by adopting SUBR as a data augmentation technique for training samples. Specifically, we develop a mixed training dataset consisting of both the original data samples and their retrieval-enhanced counterparts. We conduct extensive experiments on a real-world public dataset (i.e., MovieLens-1M) to demonstrate the superiority of ReLLa compared with existing baseline models, as well as its capability for lifelong sequential behavior comprehension.
MAP: A Model-agnostic Pretraining Framework for Click-through Rate Prediction
Aug 03, 2023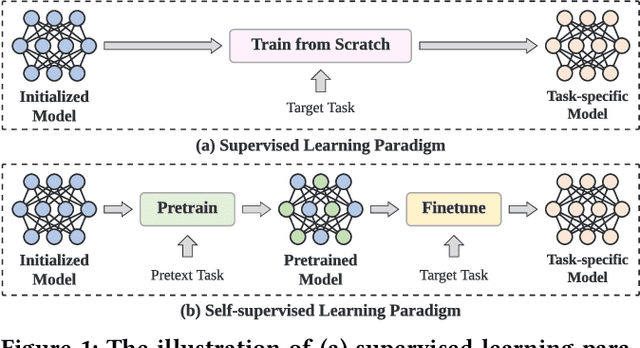
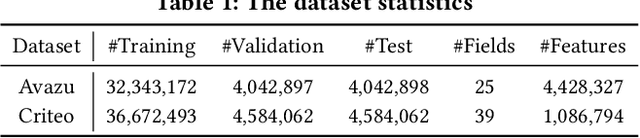
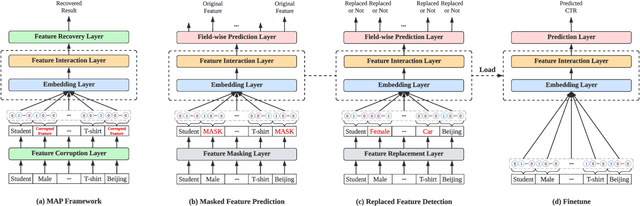
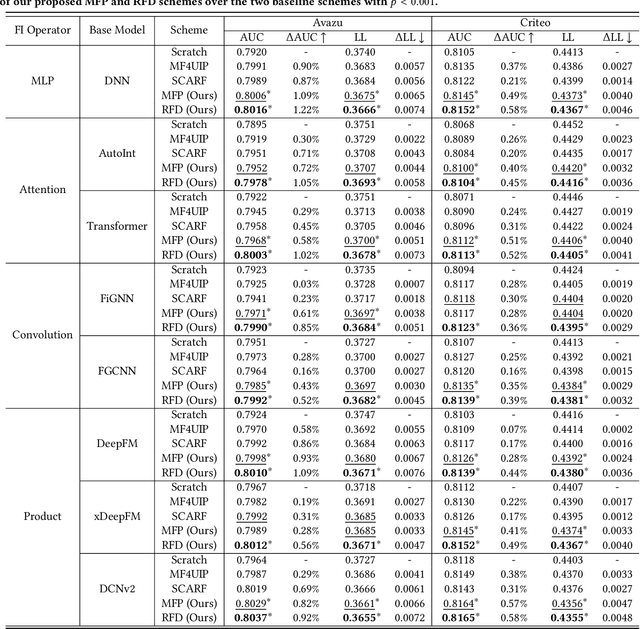
With the widespread application of personalized online services, click-through rate (CTR) prediction has received more and more attention and research. The most prominent features of CTR prediction are its multi-field categorical data format, and vast and daily-growing data volume. The large capacity of neural models helps digest such massive amounts of data under the supervised learning paradigm, yet they fail to utilize the substantial data to its full potential, since the 1-bit click signal is not sufficient to guide the model to learn capable representations of features and instances. The self-supervised learning paradigm provides a more promising pretrain-finetune solution to better exploit the large amount of user click logs, and learn more generalized and effective representations. However, self-supervised learning for CTR prediction is still an open question, since current works on this line are only preliminary and rudimentary. To this end, we propose a Model-agnostic pretraining (MAP) framework that applies feature corruption and recovery on multi-field categorical data, and more specifically, we derive two practical algorithms: masked feature prediction (MFP) and replaced feature detection (RFD). MFP digs into feature interactions within each instance through masking and predicting a small portion of input features, and introduces noise contrastive estimation (NCE) to handle large feature spaces. RFD further turns MFP into a binary classification mode through replacing and detecting changes in input features, making it even simpler and more effective for CTR pretraining. Our extensive experiments on two real-world large-scale datasets (i.e., Avazu, Criteo) demonstrate the advantages of these two methods on several strong backbones (e.g., DCNv2, DeepFM), and achieve new state-of-the-art performance in terms of both effectiveness and efficiency for CTR prediction.