 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiangyang Li
Multi-view Content-aware Indexing for Long Document Retrieval
Apr 23, 2024
Long document question answering (DocQA) aims to answer questions from long documents over 10k words. They usually contain content structures such as sections, sub-sections, and paragraph demarcations. However, the indexing methods of long documents remain under-explored, while existing systems generally employ fixed-length chunking. As they do not consider content structures, the resultant chunks can exclude vital information or include irrelevant content. Motivated by this, we propose the Multi-view Content-aware indexing (MC-indexing) for more effective long DocQA via (i) segment structured document into content chunks, and (ii) represent each content chunk in raw-text, keywords, and summary views. We highlight that MC-indexing requires neither training nor fine-tuning. Having plug-and-play capability, it can be seamlessly integrated with any retrievers to boost their performance. Besides, we propose a long DocQA dataset that includes not only question-answer pair, but also document structure and answer scope. When compared to state-of-art chunking schemes, MC-indexing has significantly increased the recall by 42.8%, 30.0%, 23.9%, and 16.3% via top k= 1.5, 3, 5, and 10 respectively. These improved scores are the average of 8 widely used retrievers (2 sparse and 6 dense) via extensive experiments.
Tired of Plugins? Large Language Models Can Be End-To-End Recommenders
Apr 07, 2024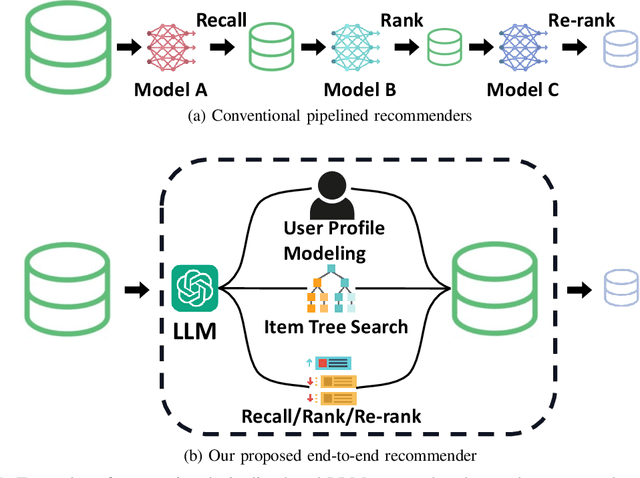
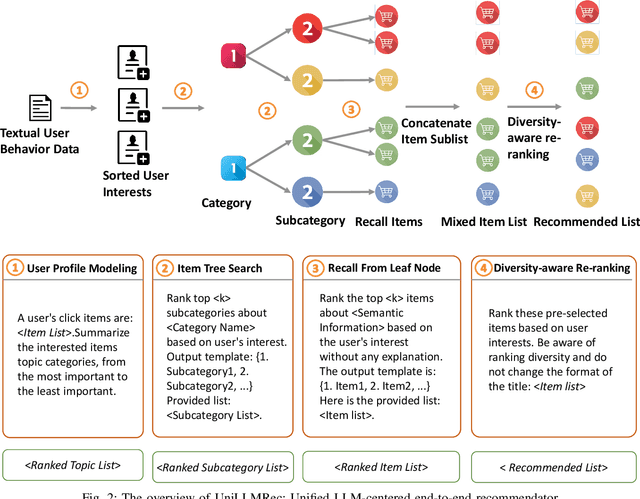
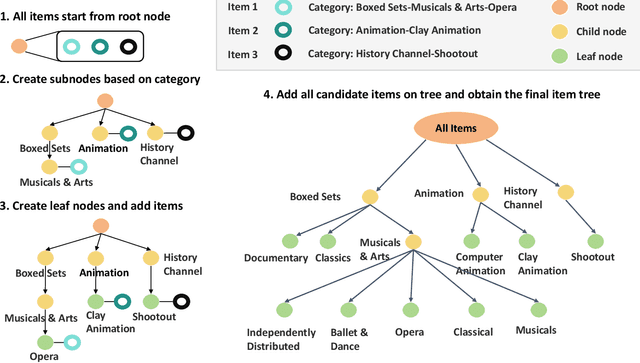
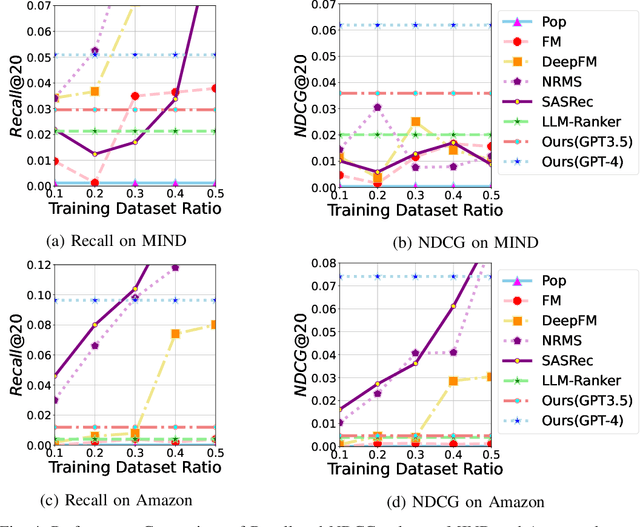
Recommender systems aim to predict user interest based on historical behavioral data. They are mainly designed in sequential pipelines, requiring lots of data to train different sub-systems, and are hard to scale to new domains. Recently, Large Language Models (LLMs) have demonstrated remarkable generalized capabilities, enabling a singular model to tackle diverse recommendation tasks across various scenarios. Nonetheless, existing LLM-based recommendation systems utilize LLM purely for a single task of the recommendation pipeline. Besides, these systems face challenges in presenting large-scale item sets to LLMs in natural language format, due to the constraint of input length. To address these challenges, we introduce an LLM-based end-to-end recommendation framework: UniLLMRec. Specifically, UniLLMRec integrates multi-stage tasks (e.g. recall, ranking, re-ranking) via chain-of-recommendations. To deal with large-scale items, we propose a novel strategy to structure all items into an item tree, which can be dynamically updated and effectively retrieved. UniLLMRec shows promising zero-shot results in comparison with conventional supervised models. Additionally, it boasts high efficiency, reducing the input token need by 86% compared to existing LLM-based models. Such efficiency not only accelerates task completion but also optimizes resource utilization. To facilitate model understanding and to ensure reproducibility, we have made our code publicly available.
Lookahead Exploration with Neural Radiance Representation for Continuous Vision-Language Navigation
Apr 02, 2024Vision-and-language navigation (VLN) enables the agent to navigate to a remote location following the natural language instruction in 3D environments. At each navigation step, the agent selects from possible candidate locations and then makes the move. For better navigation planning, the lookahead exploration strategy aims to effectively evaluate the agent's next action by accurately anticipating the future environment of candidate locations. To this end, some existing works predict RGB images for future environments, while this strategy suffers from image distortion and high computational cost. To address these issues, we propose the pre-trained hierarchical neural radiance representation model (HNR) to produce multi-level semantic features for future environments, which are more robust and efficient than pixel-wise RGB reconstruction. Furthermore, with the predicted future environmental representations, our lookahead VLN model is able to construct the navigable future path tree and select the optimal path via efficient parallel evaluation. Extensive experiments on the VLN-CE datasets confirm the effectiveness of our method.
HRLAIF: Improvements in Helpfulness and Harmlessness in Open-domain Reinforcement Learning From AI Feedback
Mar 14, 2024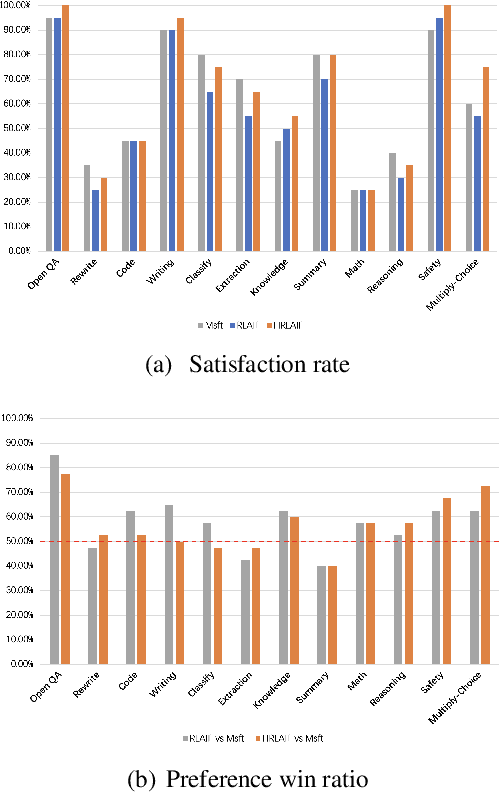
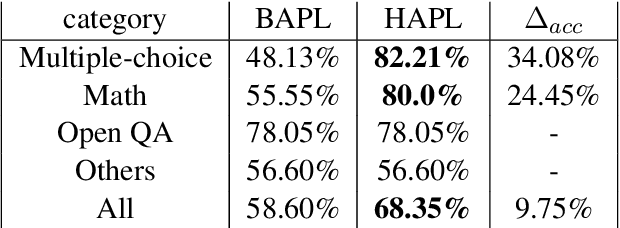
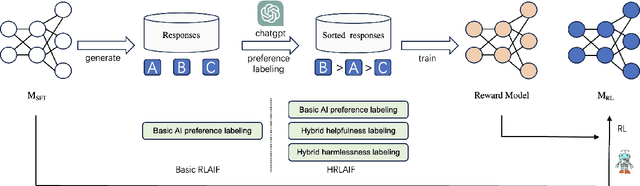

Reinforcement Learning from AI Feedback (RLAIF) has the advantages of shorter annotation cycles and lower costs over Reinforcement Learning from Human Feedback (RLHF), making it highly efficient during the rapid strategy iteration periods of large language model (LLM) training. Using ChatGPT as a labeler to provide feedback on open-domain prompts in RLAIF training, we observe an increase in human evaluators' preference win ratio for model responses, but a decrease in evaluators' satisfaction rate. Analysis suggests that the decrease in satisfaction rate is mainly due to some responses becoming less helpful, particularly in terms of correctness and truthfulness, highlighting practical limitations of basic RLAIF. In this paper, we propose Hybrid Reinforcement Learning from AI Feedback (HRLAIF). This method enhances the accuracy of AI annotations for responses, making the model's helpfulness more robust in training process. Additionally, it employs AI for Red Teaming, further improving the model's harmlessness. Human evaluation results show that HRLAIF inherits the ability of RLAIF to enhance human preference for outcomes at a low cost while also improving the satisfaction rate of responses. Compared to the policy model before Reinforcement Learning (RL), it achieves an increase of 2.08\% in satisfaction rate, effectively addressing the issue of a decrease of 4.58\% in satisfaction rate after basic RLAIF.
Instruction Fusion: Advancing Prompt Evolution through Hybridization
Dec 27, 2023The fine-tuning of Large Language Models (LLMs) specialized in code generation has seen notable advancements through the use of open-domain coding queries. Despite the successes, existing methodologies like Evol-Instruct encounter performance limitations, impeding further enhancements in code generation tasks. This paper examines the constraints of existing prompt evolution techniques and introduces a novel approach, Instruction Fusion (IF). IF innovatively combines two distinct prompts through a hybridization process, thereby enhancing the evolution of training prompts for code LLMs. Our experimental results reveal that the proposed novel method effectively addresses the shortcomings of prior methods, significantly improving the performance of Code LLMs across five code generation benchmarks, namely HumanEval, HumanEval+, MBPP, MBPP+ and MultiPL-E, which underscore the effectiveness of Instruction Fusion in advancing the capabilities of LLMs in code generation.
A Unified Framework for Multi-Domain CTR Prediction via Large Language Models
Dec 20, 2023Click-Through Rate (CTR) prediction is a crucial task in online recommendation platforms as it involves estimating the probability of user engagement with advertisements or items by clicking on them. Given the availability of various services like online shopping, ride-sharing, food delivery, and professional services on commercial platforms, recommendation systems in these platforms are required to make CTR predictions across multiple domains rather than just a single domain. However, multi-domain click-through rate (MDCTR) prediction remains a challenging task in online recommendation due to the complex mutual influence between domains. Traditional MDCTR models typically encode domains as discrete identifiers, ignoring rich semantic information underlying. Consequently, they can hardly generalize to new domains. Besides, existing models can be easily dominated by some specific domains, which results in significant performance drops in the other domains (\ie the ``seesaw phenomenon``). In this paper, we propose a novel solution Uni-CTR to address the above challenges. Uni-CTR leverages a backbone Large Language Model (LLM) to learn layer-wise semantic representations that capture commonalities between domains. Uni-CTR also uses several domain-specific networks to capture the characteristics of each domain. Note that we design a masked loss strategy so that these domain-specific networks are decoupled from backbone LLM. This allows domain-specific networks to remain unchanged when incorporating new or removing domains, thereby enhancing the flexibility and scalability of the system significantly. Experimental results on three public datasets show that Uni-CTR outperforms the state-of-the-art (SOTA) MDCTR models significantly. Furthermore, Uni-CTR demonstrates remarkable effectiveness in zero-shot prediction. We have applied Uni-CTR in industrial scenarios, confirming its efficiency.
ALT: Towards Fine-grained Alignment between Language and CTR Models for Click-Through Rate Prediction
Oct 30, 2023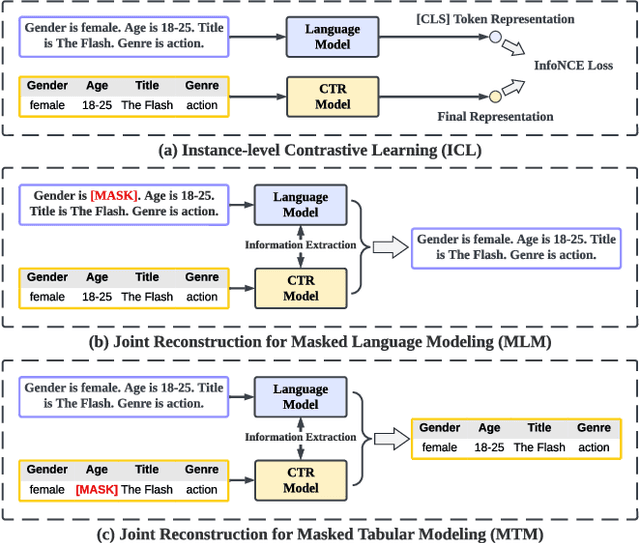
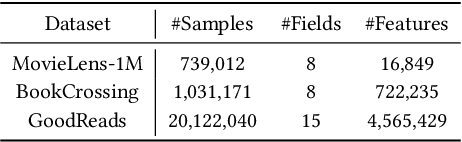

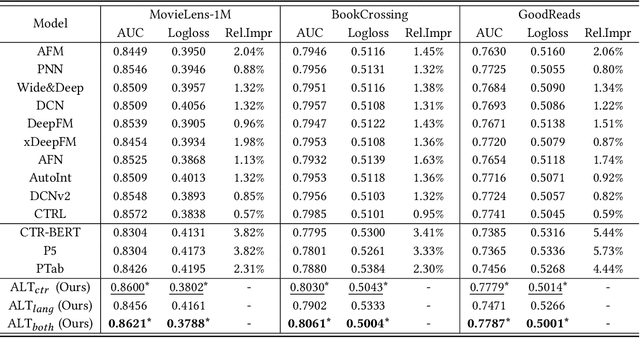
Click-through rate (CTR) prediction plays as a core function module in various personalized online services. According to the data modality and input format, the models for CTR prediction can be mainly classified into two categories. The first one is the traditional CTR models that take as inputs the one-hot encoded ID features of tabular modality, which aims to capture the collaborative signals via feature interaction modeling. The second category takes as inputs the sentences of textual modality obtained by hard prompt templates, where pretrained language models (PLMs) are adopted to extract the semantic knowledge. These two lines of research generally focus on different characteristics of the same input data (i.e., textual and tabular modalities), forming a distinct complementary relationship with each other. Therefore, in this paper, we propose to conduct fine-grained feature-level Alignment between Language and CTR models (ALT) for CTR prediction. Apart from the common CLIP-like instance-level contrastive learning, we further design a novel joint reconstruction pretraining task for both masked language and tabular modeling. Specifically, the masked data of one modality (i.e., tokens or features) has to be recovered with the help of the other modality, which establishes the feature-level interaction and alignment via sufficient mutual information extraction between dual modalities. Moreover, we propose three different finetuning strategies with the option to train the aligned language and CTR models separately or jointly for downstream CTR prediction tasks, thus accommodating the varying efficacy and efficiency requirements for industrial applications. Extensive experiments on three real-world datasets demonstrate that ALT outperforms SOTA baselines, and is highly compatible for various language and CTR models.
GridMM: Grid Memory Map for Vision-and-Language Navigation
Jul 25, 2023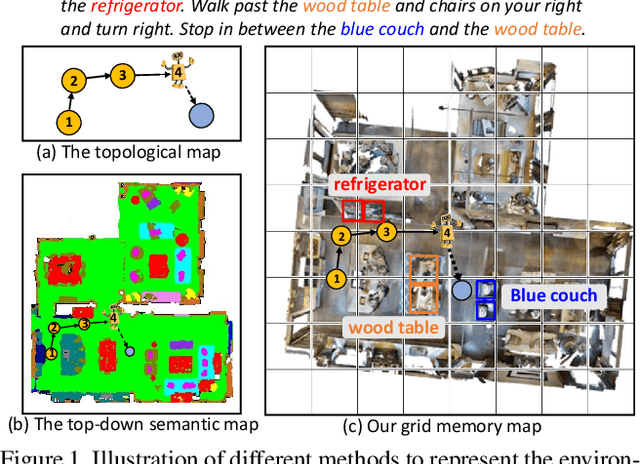
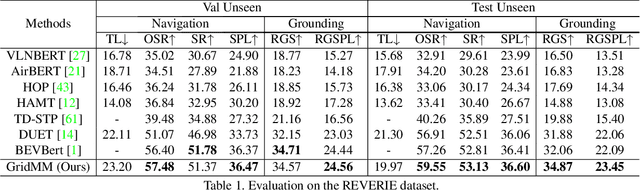
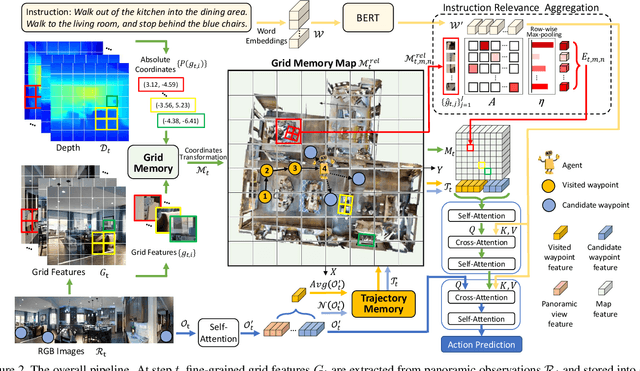
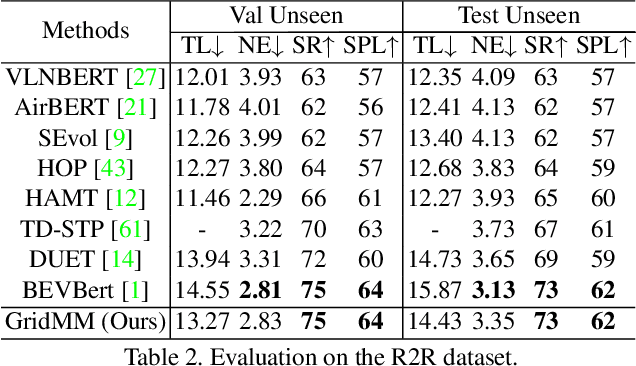
Vision-and-language navigation (VLN) enables the agent to navigate to a remote location following the natural language instruction in 3D environments. To represent the previously visited environment, most approaches for VLN implement memory using recurrent states, topological maps, or top-down semantic maps. In contrast to these approaches, we build the top-down egocentric and dynamically growing Grid Memory Map (i.e., GridMM) to structure the visited environment. From a global perspective, historical observations are projected into a unified grid map in a top-down view, which can better represent the spatial relations of the environment. From a local perspective, we further propose an instruction relevance aggregation method to capture fine-grained visual clues in each grid region. Extensive experiments are conducted on both the REVERIE, R2R, SOON datasets in the discrete environments, and the R2R-CE dataset in the continuous environments, showing the superiority of our proposed method.
How Can Recommender Systems Benefit from Large Language Models: A Survey
Jun 28, 2023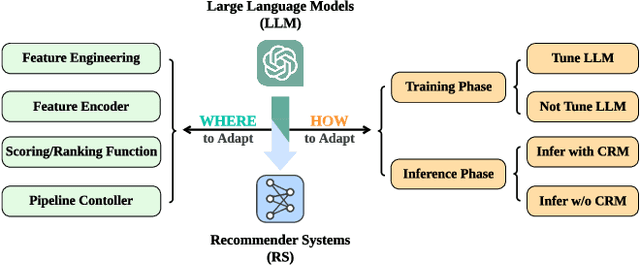
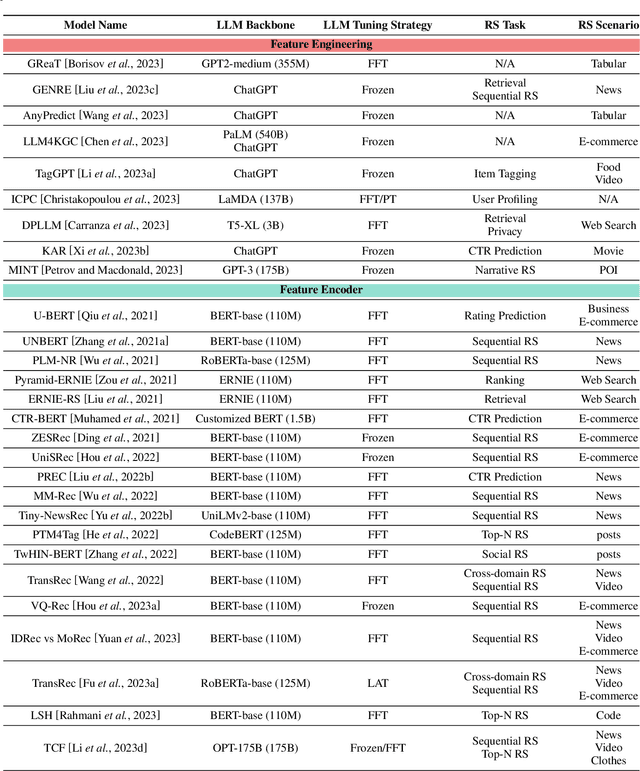
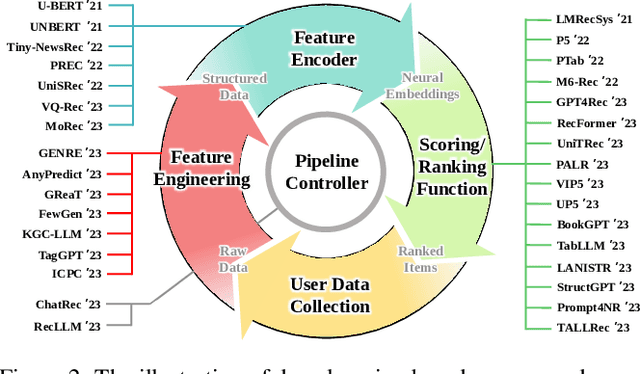
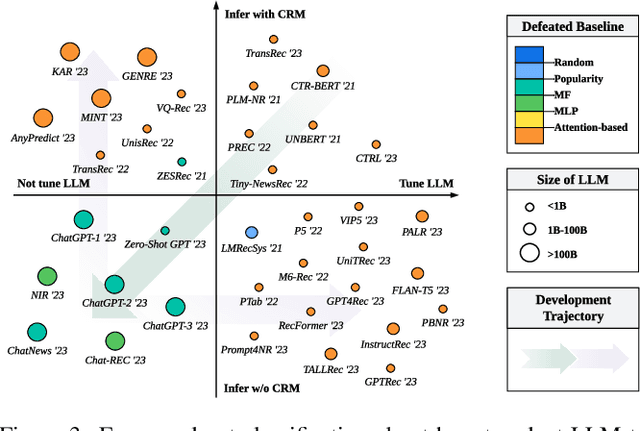
Recommender systems (RS) play important roles to match users' information needs for Internet applications. In natural language processing (NLP) domains, large language model (LLM) has shown astonishing emergent abilities (e.g., instruction following, reasoning), thus giving rise to the promising research direction of adapting LLM to RS for performance enhancements and user experience improvements. In this paper, we conduct a comprehensive survey on this research direction from an application-oriented view. We first summarize existing research works from two orthogonal perspectives: where and how to adapt LLM to RS. For the "WHERE" question, we discuss the roles that LLM could play in different stages of the recommendation pipeline, i.e., feature engineering, feature encoder, scoring/ranking function, and pipeline controller. For the "HOW" question, we investigate the training and inference strategies, resulting in two fine-grained taxonomy criteria, i.e., whether to tune LLMs or not, and whether to involve conventional recommendation model (CRM) for inference. Detailed analysis and general development trajectories are provided for both questions, respectively. Then, we highlight key challenges in adapting LLM to RS from three aspects, i.e., efficiency, effectiveness, and ethics. Finally, we summarize the survey and discuss the future prospects. We also actively maintain a GitHub repository for papers and other related resources in this rising direction: https://github.com/CHIANGEL/Awesome-LLM-for-RecSys.
CTRL: Connect Tabular and Language Model for CTR Prediction
Jun 08, 2023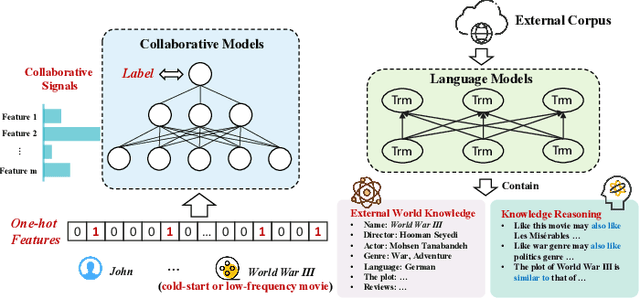

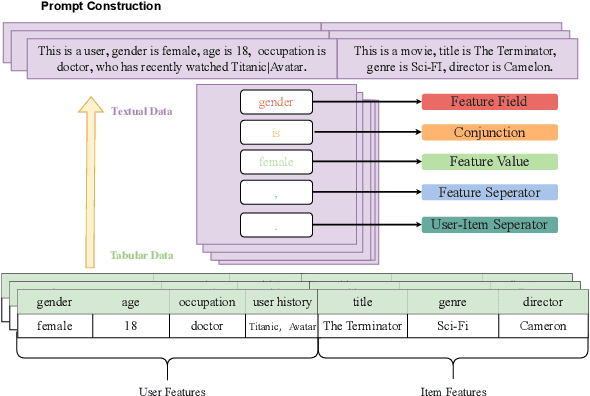

Traditional click-through rate (CTR) prediction models convert the tabular data into one-hot vectors and leverage the collaborative relations among features for inferring user's preference over items. This modeling paradigm discards the essential semantic information. Though some recent works like P5 and M6-Rec have explored the potential of using Pre-trained Language Models (PLMs) to extract semantic signals for CTR prediction, they are computationally expensive and suffer from low efficiency. Besides, the beneficial collaborative relations are not considered, hindering the recommendation performance. To solve these problems, in this paper, we propose a novel framework \textbf{CTRL}, which is industrial friendly and model-agnostic with high training and inference efficiency. Specifically, the original tabular data is first converted into textual data. Both tabular data and converted textual data are regarded as two different modalities and are separately fed into the collaborative CTR model and pre-trained language model. A cross-modal knowledge alignment procedure is performed to fine-grained align and integrate the collaborative and semantic signals, and the lightweight collaborative model can be deployed online for efficient serving after fine-tuned with supervised signals. Experimental results on three public datasets show that CTRL outperforms the SOTA CTR models significantly. Moreover, we further verify its effectiveness on a large-scale industrial recommender system.