 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeiwen Liu
WESE: Weak Exploration to Strong Exploitation for LLM Agents
Apr 11, 2024
Recently, large language models (LLMs) have demonstrated remarkable potential as an intelligent agent. However, existing researches mainly focus on enhancing the agent's reasoning or decision-making abilities through well-designed prompt engineering or task-specific fine-tuning, ignoring the procedure of exploration and exploitation. When addressing complex tasks within open-world interactive environments, these methods exhibit limitations. Firstly, the lack of global information of environments leads to greedy decisions, resulting in sub-optimal solutions. On the other hand, irrelevant information acquired from the environment not only adversely introduces noise, but also incurs additional cost. This paper proposes a novel approach, Weak Exploration to Strong Exploitation (WESE), to enhance LLM agents in solving open-world interactive tasks. Concretely, WESE involves decoupling the exploration and exploitation process, employing a cost-effective weak agent to perform exploration tasks for global knowledge. A knowledge graph-based strategy is then introduced to store the acquired knowledge and extract task-relevant knowledge, enhancing the stronger agent in success rate and efficiency for the exploitation task. Our approach is flexible enough to incorporate diverse tasks, and obtains significant improvements in both success rates and efficiency across four interactive benchmarks.
Play to Your Strengths: Collaborative Intelligence of Conventional Recommender Models and Large Language Models
Mar 25, 2024The rise of large language models (LLMs) has opened new opportunities in Recommender Systems (RSs) by enhancing user behavior modeling and content understanding. However, current approaches that integrate LLMs into RSs solely utilize either LLM or conventional recommender model (CRM) to generate final recommendations, without considering which data segments LLM or CRM excel in. To fill in this gap, we conduct experiments on MovieLens-1M and Amazon-Books datasets, and compare the performance of a representative CRM (DCNv2) and an LLM (LLaMA2-7B) on various groups of data samples. Our findings reveal that LLMs excel in data segments where CRMs exhibit lower confidence and precision, while samples where CRM excels are relatively challenging for LLM, requiring substantial training data and a long training time for comparable performance. This suggests potential synergies in the combination between LLM and CRM. Motivated by these insights, we propose Collaborative Recommendation with conventional Recommender and Large Language Model (dubbed \textit{CoReLLa}). In this framework, we first jointly train LLM and CRM and address the issue of decision boundary shifts through alignment loss. Then, the resource-efficient CRM, with a shorter inference time, handles simple and moderate samples, while LLM processes the small subset of challenging samples for CRM. Our experimental results demonstrate that CoReLLa outperforms state-of-the-art CRM and LLM methods significantly, underscoring its effectiveness in recommendation tasks.
The 2nd Workshop on Recommendation with Generative Models
Mar 07, 2024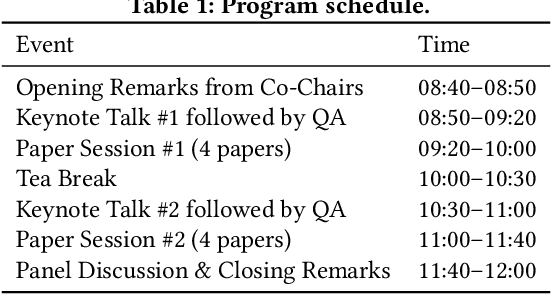
The rise of generative models has driven significant advancements in recommender systems, leaving unique opportunities for enhancing users' personalized recommendations. This workshop serves as a platform for researchers to explore and exchange innovative concepts related to the integration of generative models into recommender systems. It primarily focuses on five key perspectives: (i) improving recommender algorithms, (ii) generating personalized content, (iii) evolving the user-system interaction paradigm, (iv) enhancing trustworthiness checks, and (v) refining evaluation methodologies for generative recommendations. With generative models advancing rapidly, an increasing body of research is emerging in these domains, underscoring the timeliness and critical importance of this workshop. The related research will introduce innovative technologies to recommender systems and contribute to fresh challenges in both academia and industry. In the long term, this research direction has the potential to revolutionize the traditional recommender paradigms and foster the development of next-generation recommender systems.
Understanding the planning of LLM agents: A survey
Feb 05, 2024As Large Language Models (LLMs) have shown significant intelligence, the progress to leverage LLMs as planning modules of autonomous agents has attracted more attention. This survey provides the first systematic view of LLM-based agents planning, covering recent works aiming to improve planning ability. We provide a taxonomy of existing works on LLM-Agent planning, which can be categorized into Task Decomposition, Plan Selection, External Module, Reflection and Memory. Comprehensive analyses are conducted for each direction, and further challenges for the field of research are discussed.
Planning, Creation, Usage: Benchmarking LLMs for Comprehensive Tool Utilization in Real-World Complex Scenarios
Jan 30, 2024The recent trend of using Large Language Models (LLMs) as intelligent agents in real-world applications underscores the necessity for comprehensive evaluations of their capabilities, particularly in complex scenarios involving planning, creating, and using tools. However, existing benchmarks typically focus on simple synthesized queries that do not reflect real-world complexity, thereby offering limited perspectives in evaluating tool utilization. To address this issue, we present UltraTool, a novel benchmark designed to improve and evaluate LLMs' ability in tool utilization within real-world scenarios. UltraTool focuses on the entire process of using tools - from planning and creating to applying them in complex tasks. It emphasizes real-world complexities, demanding accurate, multi-step planning for effective problem-solving. A key feature of UltraTool is its independent evaluation of planning with natural language, which happens before tool usage and simplifies the task solving by mapping out the intermediate steps. Thus, unlike previous work, it eliminates the restriction of pre-defined toolset during planning. Through extensive experiments on various LLMs, we offer novel insights into the evaluation of capabilities of LLMs in tool utilization, thereby contributing a fresh perspective to this rapidly evolving field. The benchmark is publicly available at https://github.com/JoeYing1019/UltraTool.
D2K: Turning Historical Data into Retrievable Knowledge for Recommender Systems
Jan 23, 2024A vast amount of user behavior data is constantly accumulating on today's large recommendation platforms, recording users' various interests and tastes. Preserving knowledge from the old data while new data continually arrives is a vital problem for recommender systems. Existing approaches generally seek to save the knowledge implicitly in the model parameters. However, such a parameter-centric approach lacks scalability and flexibility -- the capacity is hard to scale, and the knowledge is inflexible to utilize. Hence, in this work, we propose a framework that turns massive user behavior data to retrievable knowledge (D2K). It is a data-centric approach that is model-agnostic and easy to scale up. Different from only storing unary knowledge such as the user-side or item-side information, D2K propose to store ternary knowledge for recommendation, which is determined by the complete recommendation factors -- user, item, and context. The knowledge retrieved by target samples can be directly used to enhance the performance of any recommendation algorithms. Specifically, we introduce a Transformer-based knowledge encoder to transform the old data into knowledge with the user-item-context cross features. A personalized knowledge adaptation unit is devised to effectively exploit the information from the knowledge base by adapting the retrieved knowledge to the target samples. Extensive experiments on two public datasets show that D2K significantly outperforms existing baselines and is compatible with a major collection of recommendation algorithms.
Ten Challenges in Industrial Recommender Systems
Oct 07, 2023Huawei's vision and mission is to build a fully connected intelligent world. Since 2013, Huawei Noah's Ark Lab has helped many products build recommender systems and search engines for getting the right information to the right users. Every day, our recommender systems serve hundreds of millions of mobile phone users and recommend different kinds of content and services such as apps, news feeds, songs, videos, books, themes, and instant services. The big data and various scenarios provide us with great opportunities to develop advanced recommendation technologies. Furthermore, we have witnessed the technical trend of recommendation models in the past ten years, from the shallow and simple models like collaborative filtering, linear models, low rank models to deep and complex models like neural networks, pre-trained language models. Based on the mission, opportunities and technological trends, we have also met several hard problems in our recommender systems. In this talk, we will share ten important and interesting challenges and hope that the RecSys community can get inspired and create better recommender systems.
Multi-domain Recommendation with Embedding Disentangling and Domain Alignment
Aug 14, 2023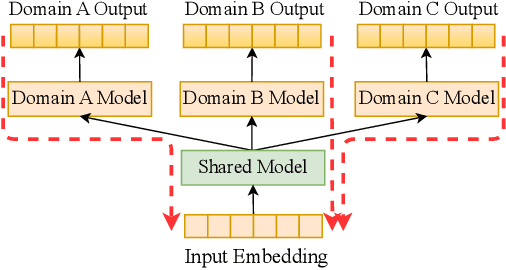
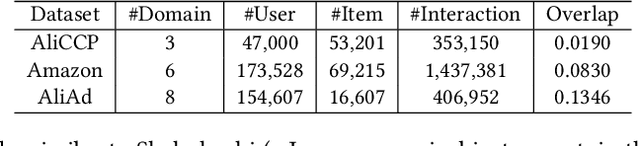
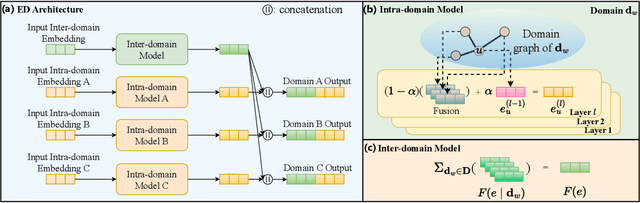
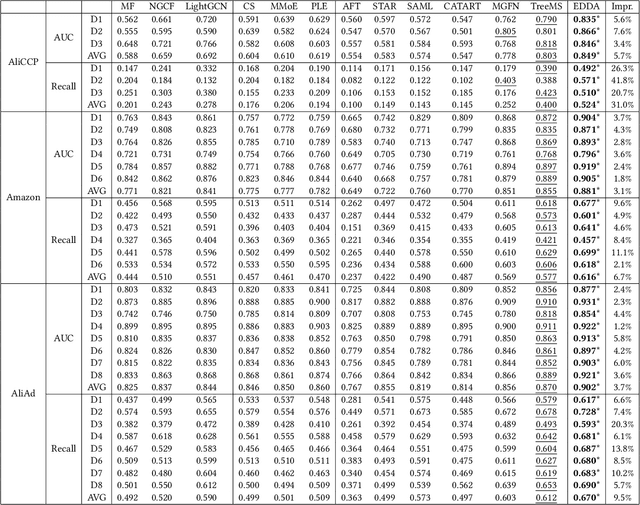
Multi-domain recommendation (MDR) aims to provide recommendations for different domains (e.g., types of products) with overlapping users/items and is common for platforms such as Amazon, Facebook, and LinkedIn that host multiple services. Existing MDR models face two challenges: First, it is difficult to disentangle knowledge that generalizes across domains (e.g., a user likes cheap items) and knowledge specific to a single domain (e.g., a user likes blue clothing but not blue cars). Second, they have limited ability to transfer knowledge across domains with small overlaps. We propose a new MDR method named EDDA with two key components, i.e., embedding disentangling recommender and domain alignment, to tackle the two challenges respectively. In particular, the embedding disentangling recommender separates both the model and embedding for the inter-domain part and the intra-domain part, while most existing MDR methods only focus on model-level disentangling. The domain alignment leverages random walks from graph processing to identify similar user/item pairs from different domains and encourages similar user/item pairs to have similar embeddings, enhancing knowledge transfer. We compare EDDA with 12 state-of-the-art baselines on 3 real datasets. The results show that EDDA consistently outperforms the baselines on all datasets and domains. All datasets and codes are available at https://github.com/Stevenn9981/EDDA.
How Can Recommender Systems Benefit from Large Language Models: A Survey
Jun 28, 2023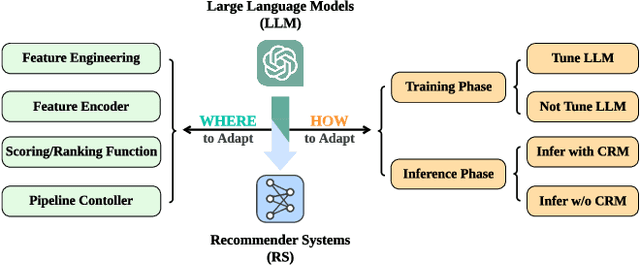
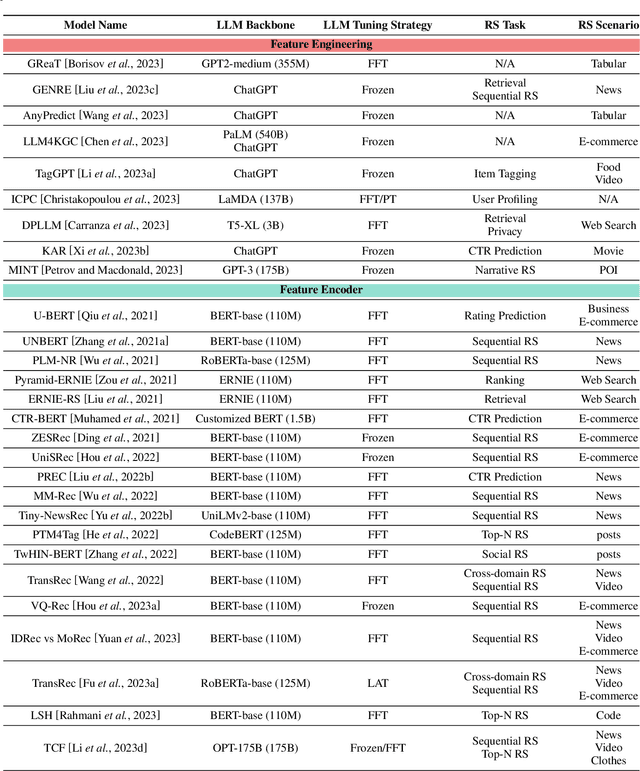
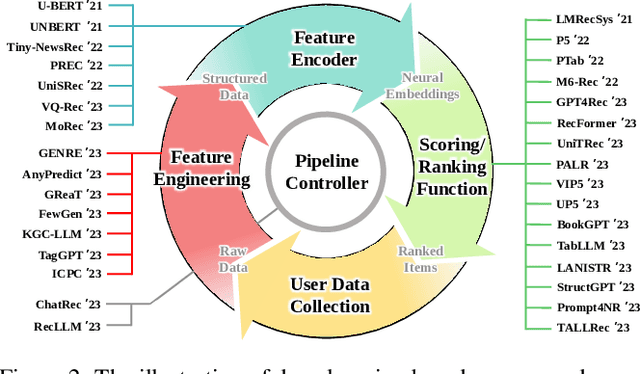
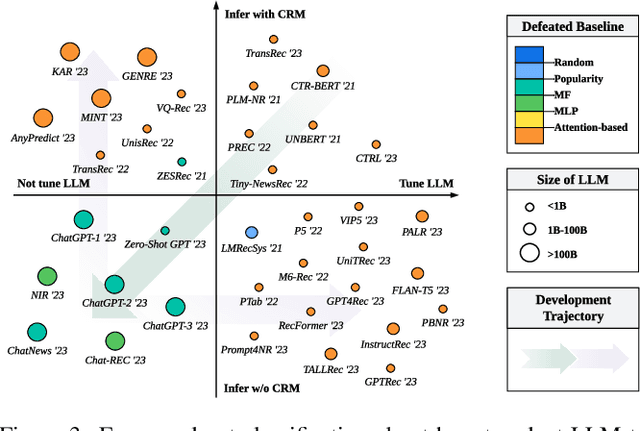
Recommender systems (RS) play important roles to match users' information needs for Internet applications. In natural language processing (NLP) domains, large language model (LLM) has shown astonishing emergent abilities (e.g., instruction following, reasoning), thus giving rise to the promising research direction of adapting LLM to RS for performance enhancements and user experience improvements. In this paper, we conduct a comprehensive survey on this research direction from an application-oriented view. We first summarize existing research works from two orthogonal perspectives: where and how to adapt LLM to RS. For the "WHERE" question, we discuss the roles that LLM could play in different stages of the recommendation pipeline, i.e., feature engineering, feature encoder, scoring/ranking function, and pipeline controller. For the "HOW" question, we investigate the training and inference strategies, resulting in two fine-grained taxonomy criteria, i.e., whether to tune LLMs or not, and whether to involve conventional recommendation model (CRM) for inference. Detailed analysis and general development trajectories are provided for both questions, respectively. Then, we highlight key challenges in adapting LLM to RS from three aspects, i.e., efficiency, effectiveness, and ethics. Finally, we summarize the survey and discuss the future prospects. We also actively maintain a GitHub repository for papers and other related resources in this rising direction: https://github.com/CHIANGEL/Awesome-LLM-for-RecSys.