 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWenjie Wang
A Taxation Perspective for Fair Re-ranking
Apr 27, 2024
Fair re-ranking aims to redistribute ranking slots among items more equitably to ensure responsibility and ethics. The exploration of redistribution problems has a long history in economics, offering valuable insights for conceptualizing fair re-ranking as a taxation process. Such a formulation provides us with a fresh perspective to re-examine fair re-ranking and inspire the development of new methods. From a taxation perspective, we theoretically demonstrate that most previous fair re-ranking methods can be reformulated as an item-level tax policy. Ideally, a good tax policy should be effective and conveniently controllable to adjust ranking resources. However, both empirical and theoretical analyses indicate that the previous item-level tax policy cannot meet two ideal controllable requirements: (1) continuity, ensuring minor changes in tax rates result in small accuracy and fairness shifts; (2) controllability over accuracy loss, ensuring precise estimation of the accuracy loss under a specific tax rate. To overcome these challenges, we introduce a new fair re-ranking method named Tax-rank, which levies taxes based on the difference in utility between two items. Then, we efficiently optimize such an objective by utilizing the Sinkhorn algorithm in optimal transport. Upon a comprehensive analysis, Our model Tax-rank offers a superior tax policy for fair re-ranking, theoretically demonstrating both continuity and controllability over accuracy loss. Experimental results show that Tax-rank outperforms all state-of-the-art baselines in terms of effectiveness and efficiency on recommendation and advertising tasks.
Don't Say No: Jailbreaking LLM by Suppressing Refusal
Apr 25, 2024Ensuring the safety alignment of Large Language Models (LLMs) is crucial to generating responses consistent with human values. Despite their ability to recognize and avoid harmful queries, LLMs are vulnerable to "jailbreaking" attacks, where carefully crafted prompts elicit them to produce toxic content. One category of jailbreak attacks is reformulating the task as adversarial attacks by eliciting the LLM to generate an affirmative response. However, the typical attack in this category GCG has very limited attack success rate. In this study, to better study the jailbreak attack, we introduce the DSN (Don't Say No) attack, which prompts LLMs to not only generate affirmative responses but also novelly enhance the objective to suppress refusals. In addition, another challenge lies in jailbreak attacks is the evaluation, as it is difficult to directly and accurately assess the harmfulness of the attack. The existing evaluation such as refusal keyword matching has its own limitation as it reveals numerous false positive and false negative instances. To overcome this challenge, we propose an ensemble evaluation pipeline incorporating Natural Language Inference (NLI) contradiction assessment and two external LLM evaluators. Extensive experiments demonstrate the potency of the DSN and the effectiveness of ensemble evaluation compared to baseline methods.
A Survey of Generative Search and Recommendation in the Era of Large Language Models
Apr 25, 2024With the information explosion on the Web, search and recommendation are foundational infrastructures to satisfying users' information needs. As the two sides of the same coin, both revolve around the same core research problem, matching queries with documents or users with items. In the recent few decades, search and recommendation have experienced synchronous technological paradigm shifts, including machine learning-based and deep learning-based paradigms. Recently, the superintelligent generative large language models have sparked a new paradigm in search and recommendation, i.e., generative search (retrieval) and recommendation, which aims to address the matching problem in a generative manner. In this paper, we provide a comprehensive survey of the emerging paradigm in information systems and summarize the developments in generative search and recommendation from a unified perspective. Rather than simply categorizing existing works, we abstract a unified framework for the generative paradigm and break down the existing works into different stages within this framework to highlight the strengths and weaknesses. And then, we distinguish generative search and recommendation with their unique challenges, identify open problems and future directions, and envision the next information-seeking paradigm.
Exact and Efficient Unlearning for Large Language Model-based Recommendation
Apr 16, 2024The evolving paradigm of Large Language Model-based Recommendation (LLMRec) customizes Large Language Models (LLMs) through parameter-efficient fine-tuning (PEFT) using recommendation data. The inclusion of user data in LLMs raises privacy concerns. To protect users, the unlearning process in LLMRec, specifically removing unusable data (e.g., historical behaviors) from established LLMRec models, becomes crucial. However, existing unlearning methods are insufficient for the unique characteristics of LLM-Rec, mainly due to high computational costs or incomplete data erasure. In this study, we introduce the Adapter Partition and Aggregation (APA) framework for exact and efficient unlearning while maintaining recommendation performance. APA achieves this by establishing distinct adapters for partitioned training data shards and retraining only the adapters impacted by unusable data for unlearning. To preserve recommendation performance and mitigate considerable inference costs, APA employs parameter-level adapter aggregation with sample-adaptive attention for individual testing samples. Extensive experiments substantiate the effectiveness and efficiency of our proposed framework
$\textit{LinkPrompt}$: Natural and Universal Adversarial Attacks on Prompt-based Language Models
Apr 09, 2024Prompt-based learning is a new language model training paradigm that adapts the Pre-trained Language Models (PLMs) to downstream tasks, which revitalizes the performance benchmarks across various natural language processing (NLP) tasks. Instead of using a fixed prompt template to fine-tune the model, some research demonstrates the effectiveness of searching for the prompt via optimization. Such prompt optimization process of prompt-based learning on PLMs also gives insight into generating adversarial prompts to mislead the model, raising concerns about the adversarial vulnerability of this paradigm. Recent studies have shown that universal adversarial triggers (UATs) can be generated to alter not only the predictions of the target PLMs but also the prediction of corresponding Prompt-based Fine-tuning Models (PFMs) under the prompt-based learning paradigm. However, UATs found in previous works are often unreadable tokens or characters and can be easily distinguished from natural texts with adaptive defenses. In this work, we consider the naturalness of the UATs and develop $\textit{LinkPrompt}$, an adversarial attack algorithm to generate UATs by a gradient-based beam search algorithm that not only effectively attacks the target PLMs and PFMs but also maintains the naturalness among the trigger tokens. Extensive results demonstrate the effectiveness of $\textit{LinkPrompt}$, as well as the transferability of UATs generated by $\textit{LinkPrompt}$ to open-sourced Large Language Model (LLM) Llama2 and API-accessed LLM GPT-3.5-turbo. The resource is available at $\href{https://github.com/SavannahXu79/LinkPrompt}{https://github.com/SavannahXu79/LinkPrompt}$.
Certified PEFTSmoothing: Parameter-Efficient Fine-Tuning with Randomized Smoothing
Apr 08, 2024Randomized smoothing is the primary certified robustness method for accessing the robustness of deep learning models to adversarial perturbations in the l2-norm, by adding isotropic Gaussian noise to the input image and returning the majority votes over the base classifier. Theoretically, it provides a certified norm bound, ensuring predictions of adversarial examples are stable within this bound. A notable constraint limiting widespread adoption is the necessity to retrain base models entirely from scratch to attain a robust version. This is because the base model fails to learn the noise-augmented data distribution to give an accurate vote. One intuitive way to overcome this challenge is to involve a custom-trained denoiser to eliminate the noise. However, this approach is inefficient and sub-optimal. Inspired by recent large model training procedures, we explore an alternative way named PEFTSmoothing to adapt the base model to learn the Gaussian noise-augmented data with Parameter-Efficient Fine-Tuning (PEFT) methods in both white-box and black-box settings. Extensive results demonstrate the effectiveness and efficiency of PEFTSmoothing, which allow us to certify over 98% accuracy for ViT on CIFAR-10, 20% higher than SoTA denoised smoothing, and over 61% accuracy on ImageNet which is 30% higher than CNN-based denoiser and comparable to the Diffusion-based denoiser.
Decentralizing Coherent Joint Transmission Precoding via Fast ADMM with Deterministic Equivalents
Mar 28, 2024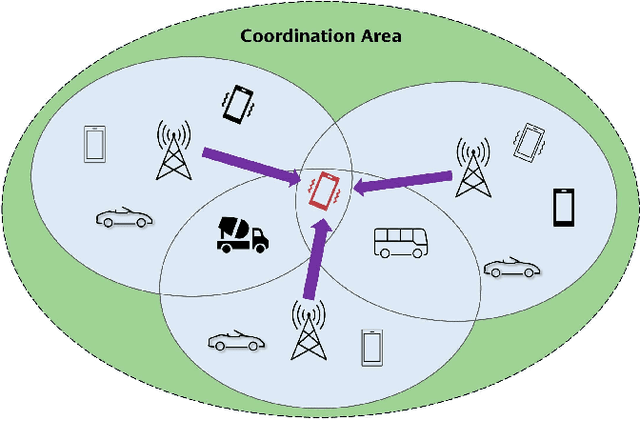
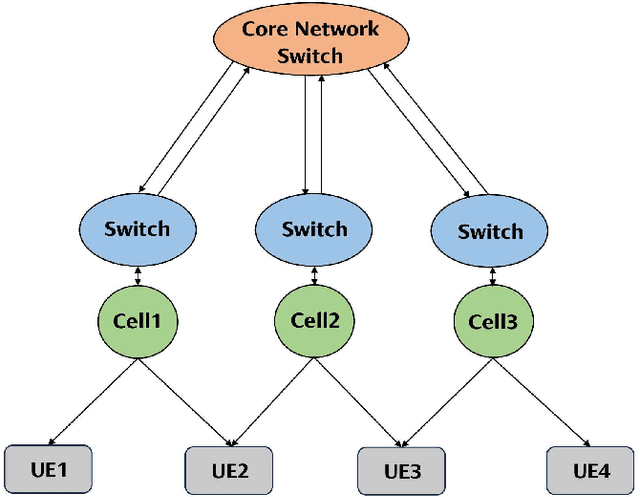
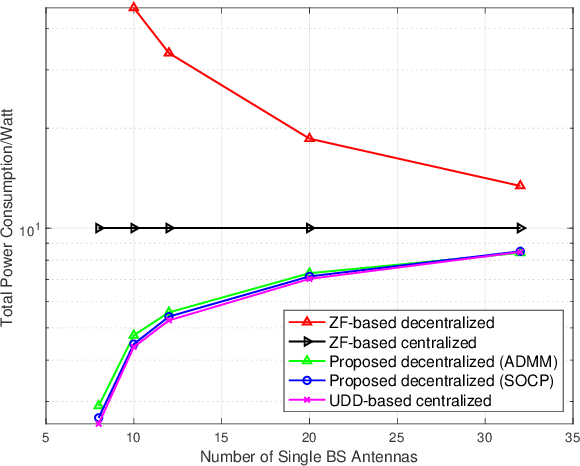
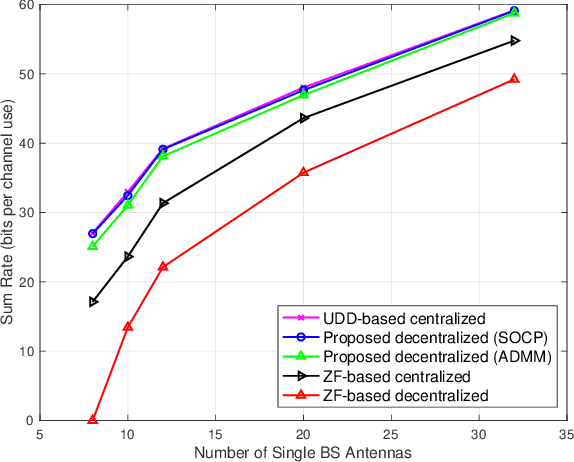
Inter-cell interference (ICI) suppression is critical for multi-cell multi-user networks. In this paper, we investigate advanced precoding techniques for coordinated multi-point (CoMP) with downlink coherent joint transmission, an effective approach for ICI suppression. Different from the centralized precoding schemes that require frequent information exchange among the cooperating base stations, we propose a decentralized scheme to minimize the total power consumption. In particular, based on the covariance matrices of global channel state information, we estimate the ICI bounds via the deterministic equivalents and decouple the original design problem into sub-problems, each of which can be solved in a decentralized manner. To solve the sub-problems at each base station, we develop a low-complexity solver based on the alternating direction method of multipliers (ADMM) in conjunction with the convex-concave procedure (CCCP). Simulation results demonstrate the effectiveness of our proposed decentralized precoding scheme, which achieves performance similar to the optimal centralized precoding scheme. Besides, our proposed ADMM solver can substantially reduce the computational complexity, while maintaining outstanding performance.
Decentralizing Coherent Joint Transmission Precoding via Deterministic Equivalents
Mar 15, 2024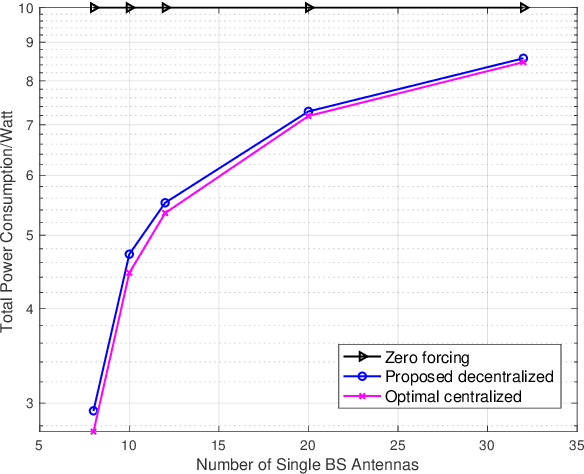
In order to control the inter-cell interference for a multi-cell multi-user multiple-input multiple-output network, we consider the precoder design for coordinated multi-point with downlink coherent joint transmission. To avoid costly information exchange among the cooperating base stations in a centralized precoding scheme, we propose a decentralized one by considering the power minimization problem. By approximating the inter-cell interference using the deterministic equivalents, this problem is decoupled to sub-problems which are solved in a decentralized manner at different base stations. Simulation results demonstrate the effectiveness of our proposed decentralized precoding scheme, where only 2 ~ 7% more transmit power is needed compared with the optimal centralized precoder.
Think Twice Before Assure: Confidence Estimation for Large Language Models through Reflection on Multiple Answers
Mar 15, 2024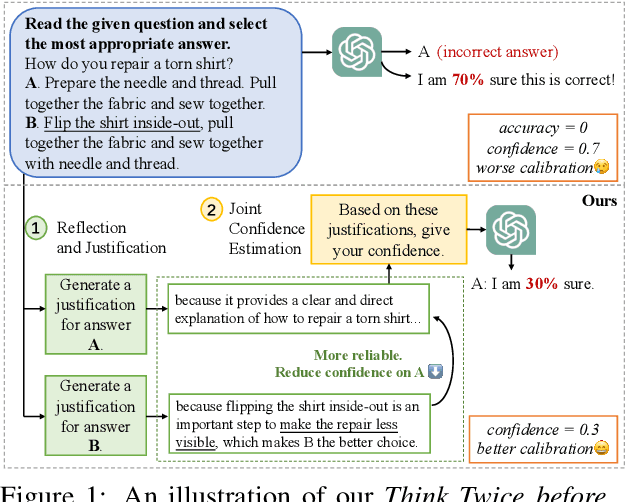

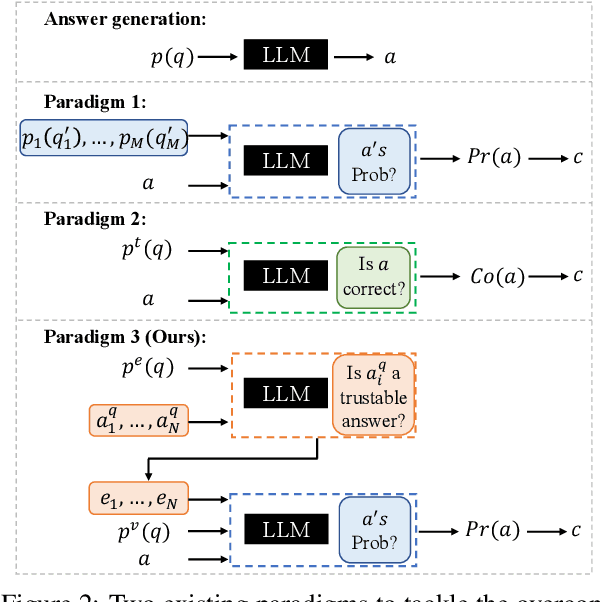
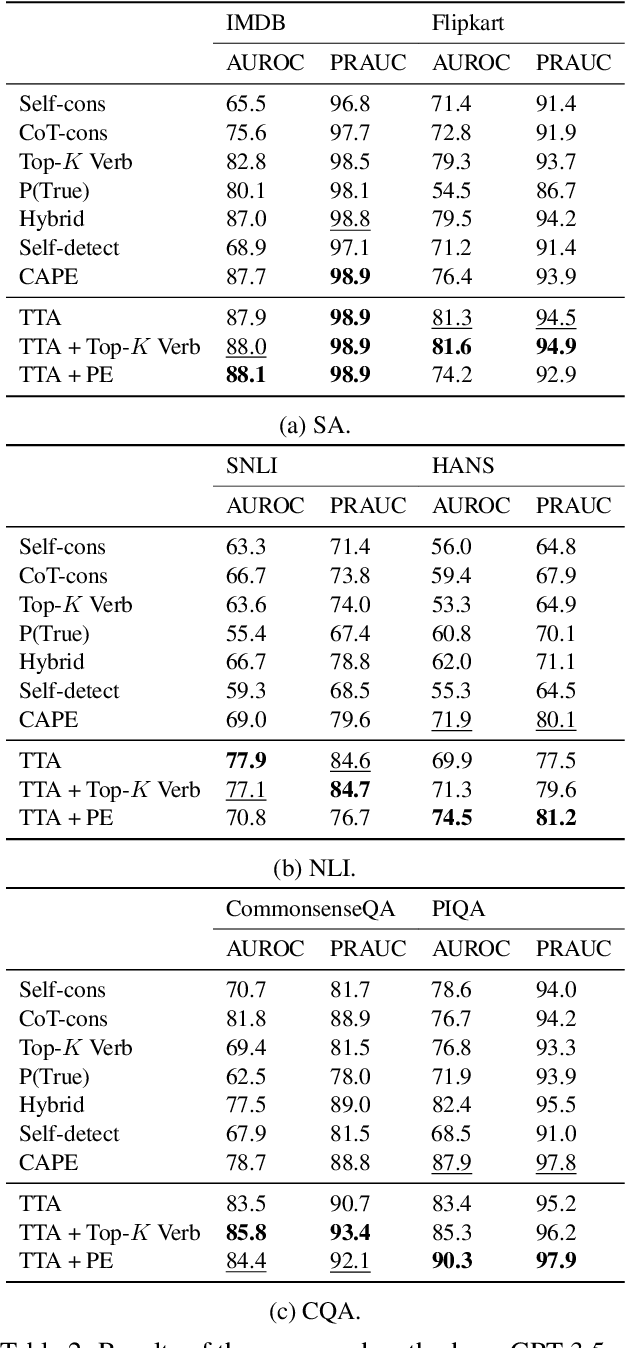
Confidence estimation aiming to evaluate output trustability is crucial for the application of large language models (LLM), especially the black-box ones. Existing confidence estimation of LLM is typically not calibrated due to the overconfidence of LLM on its generated incorrect answers. Existing approaches addressing the overconfidence issue are hindered by a significant limitation that they merely consider the confidence of one answer generated by LLM. To tackle this limitation, we propose a novel paradigm that thoroughly evaluates the trustability of multiple candidate answers to mitigate the overconfidence on incorrect answers. Building upon this paradigm, we introduce a two-step framework, which firstly instructs LLM to reflect and provide justifications for each answer, and then aggregates the justifications for comprehensive confidence estimation. This framework can be integrated with existing confidence estimation approaches for superior calibration. Experimental results on six datasets of three tasks demonstrate the rationality and effectiveness of the proposed framework.
Discriminative Probing and Tuning for Text-to-Image Generation
Mar 14, 2024
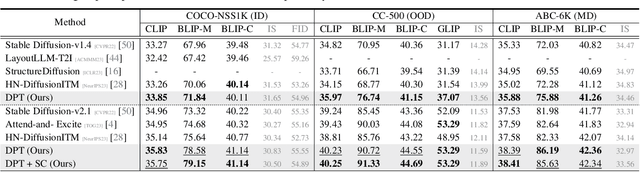
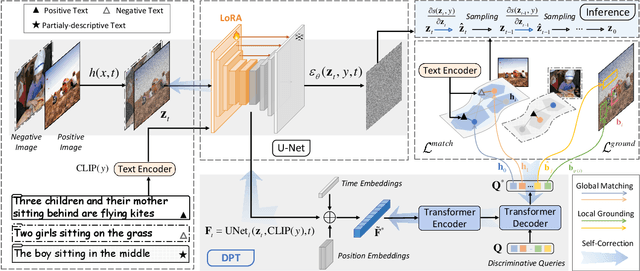
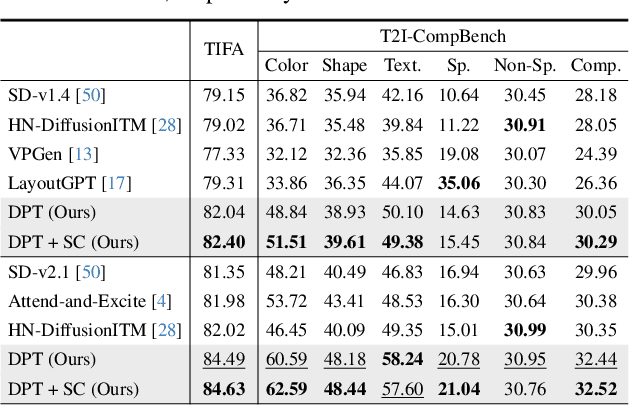
Despite advancements in text-to-image generation (T2I), prior methods often face text-image misalignment problems such as relation confusion in generated images. Existing solutions involve cross-attention manipulation for better compositional understanding or integrating large language models for improved layout planning. However, the inherent alignment capabilities of T2I models are still inadequate. By reviewing the link between generative and discriminative modeling, we posit that T2I models' discriminative abilities may reflect their text-image alignment proficiency during generation. In this light, we advocate bolstering the discriminative abilities of T2I models to achieve more precise text-to-image alignment for generation. We present a discriminative adapter built on T2I models to probe their discriminative abilities on two representative tasks and leverage discriminative fine-tuning to improve their text-image alignment. As a bonus of the discriminative adapter, a self-correction mechanism can leverage discriminative gradients to better align generated images to text prompts during inference. Comprehensive evaluations across three benchmark datasets, including both in-distribution and out-of-distribution scenarios, demonstrate our method's superior generation performance. Meanwhile, it achieves state-of-the-art discriminative performance on the two discriminative tasks compared to other generative models.