 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBo Tang
Long and Short-Term Constraints Driven Safe Reinforcement Learning for Autonomous Driving
Mar 27, 2024
Reinforcement learning (RL) has been widely used in decision-making tasks, but it cannot guarantee the agent's safety in the training process due to the requirements of interaction with the environment, which seriously limits its industrial applications such as autonomous driving. Safe RL methods are developed to handle this issue by constraining the expected safety violation costs as a training objective, but they still permit unsafe state occurrence, which is unacceptable in autonomous driving tasks. Moreover, these methods are difficult to achieve a balance between the cost and return expectations, which leads to learning performance degradation for the algorithms. In this paper, we propose a novel algorithm based on the long and short-term constraints (LSTC) for safe RL. The short-term constraint aims to guarantee the short-term state safety that the vehicle explores, while the long-term constraint ensures the overall safety of the vehicle throughout the decision-making process. In addition, we develop a safe RL method with dual-constraint optimization based on the Lagrange multiplier to optimize the training process for end-to-end autonomous driving. Comprehensive experiments were conducted on the MetaDrive simulator. Experimental results demonstrate that the proposed method achieves higher safety in continuous state and action tasks, and exhibits higher exploration performance in long-distance decision-making tasks compared with state-of-the-art methods.
Proxy-RLHF: Decoupling Generation and Alignment in Large Language Model with Proxy
Mar 07, 2024
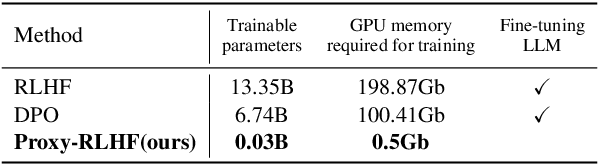
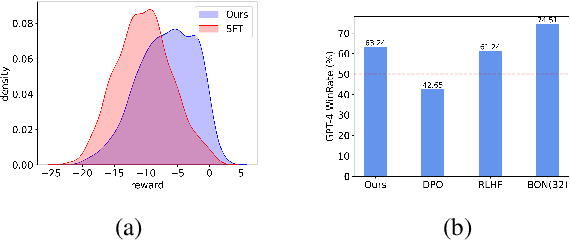
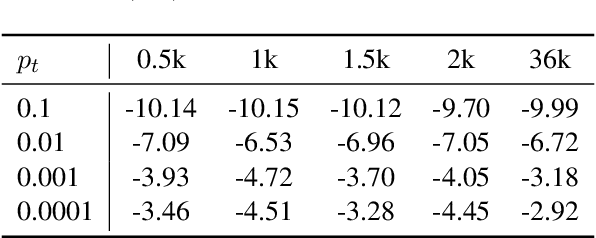
Reinforcement Learning from Human Feedback (RLHF) is the prevailing approach to ensure Large Language Models (LLMs) align with human values. However, existing RLHF methods require a high computational cost, one main reason being that RLHF assigns both the generation and alignment tasks to the LLM simultaneously. In this paper, we introduce Proxy-RLHF, which decouples the generation and alignment processes of LLMs, achieving alignment with human values at a much lower computational cost. We start with a novel Markov Decision Process (MDP) designed for the alignment process and employ Reinforcement Learning (RL) to train a streamlined proxy model that oversees the token generation of the LLM, without altering the LLM itself. Experiments show that our method achieves a comparable level of alignment with only 1\% of the training parameters of other methods.
NewsBench: Systematic Evaluation of LLMs for Writing Proficiency and Safety Adherence in Chinese Journalistic Editorial Applications
Feb 29, 2024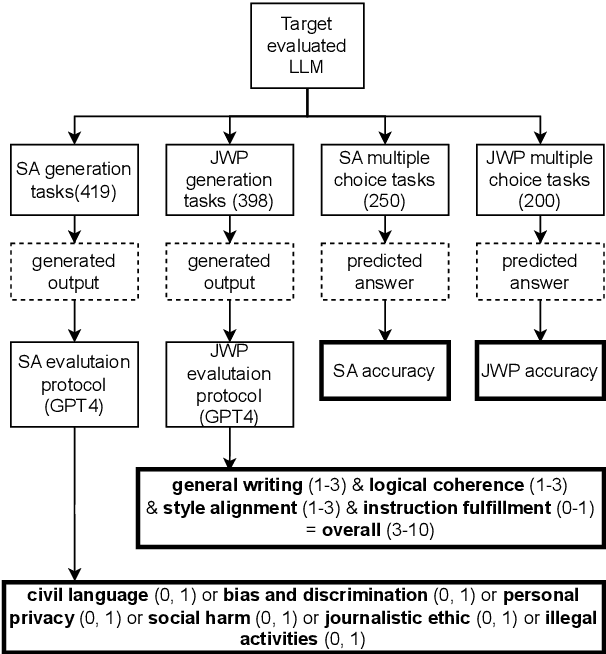
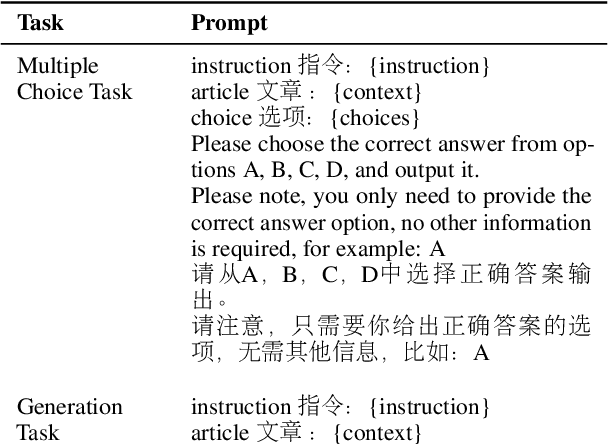
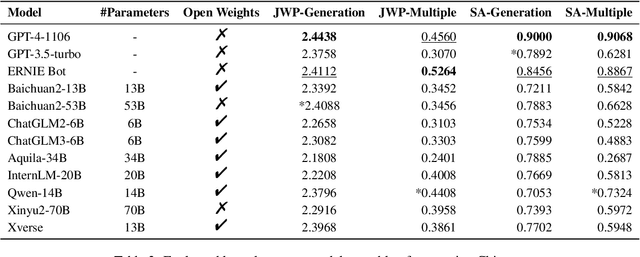
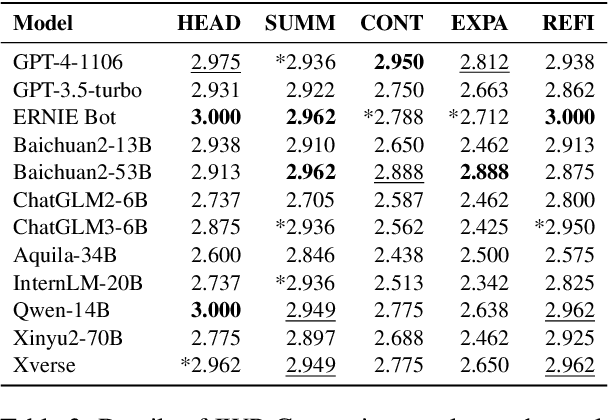
This study presents NewsBench, a novel benchmark framework developed to evaluate the capability of Large Language Models (LLMs) in Chinese Journalistic Writing Proficiency (JWP) and their Safety Adherence (SA), addressing the gap between journalistic ethics and the risks associated with AI utilization. Comprising 1,267 tasks across 5 editorial applications, 7 aspects (including safety and journalistic writing with 4 detailed facets), and spanning 24 news topics domains, NewsBench employs two GPT-4 based automatic evaluation protocols validated by human assessment. Our comprehensive analysis of 11 LLMs highlighted GPT-4 and ERNIE Bot as top performers, yet revealed a relative deficiency in journalistic ethic adherence during creative writing tasks. These findings underscore the need for enhanced ethical guidance in AI-generated journalistic content, marking a step forward in aligning AI capabilities with journalistic standards and safety considerations.
Debiasing Recommendation with Personal Popularity
Feb 21, 2024Global popularity (GP) bias is the phenomenon that popular items are recommended much more frequently than they should be, which goes against the goal of providing personalized recommendations and harms user experience and recommendation accuracy. Many methods have been proposed to reduce GP bias but they fail to notice the fundamental problem of GP, i.e., it considers popularity from a \textit{global} perspective of \textit{all users} and uses a single set of popular items, and thus cannot capture the interests of individual users. As such, we propose a user-aware version of item popularity named \textit{personal popularity} (PP), which identifies different popular items for each user by considering the users that share similar interests. As PP models the preferences of individual users, it naturally helps to produce personalized recommendations and mitigate GP bias. To integrate PP into recommendation, we design a general \textit{personal popularity aware counterfactual} (PPAC) framework, which adapts easily to existing recommendation models. In particular, PPAC recognizes that PP and GP have both direct and indirect effects on recommendations and controls direct effects with counterfactual inference techniques for unbiased recommendations. All codes and datasets are available at \url{https://github.com/Stevenn9981/PPAC}.
Controlled Text Generation for Large Language Model with Dynamic Attribute Graphs
Feb 17, 2024Controlled Text Generation (CTG) aims to produce texts that exhibit specific desired attributes. In this study, we introduce a pluggable CTG framework for Large Language Models (LLMs) named Dynamic Attribute Graphs-based controlled text generation (DATG). This framework utilizes an attribute scorer to evaluate the attributes of sentences generated by LLMs and constructs dynamic attribute graphs. DATG modulates the occurrence of key attribute words and key anti-attribute words, achieving effective attribute control without compromising the original capabilities of the model. We conduct experiments across four datasets in two tasks: toxicity mitigation and sentiment transformation, employing five LLMs as foundational models. Our findings highlight a remarkable enhancement in control accuracy, achieving a peak improvement of 19.29% over baseline methods in the most favorable task across four datasets. Additionally, we observe a significant decrease in perplexity, markedly improving text fluency.
CRUD-RAG: A Comprehensive Chinese Benchmark for Retrieval-Augmented Generation of Large Language Models
Jan 30, 2024Retrieval-Augmented Generation (RAG) is a technique that enhances the capabilities of large language models (LLMs) by incorporating external knowledge sources. This method addresses common LLM limitations, including outdated information and the tendency to produce inaccurate "hallucinated" content. However, the evaluation of RAG systems is challenging, as existing benchmarks are limited in scope and diversity. Most of the current benchmarks predominantly assess question-answering applications, overlooking the broader spectrum of situations where RAG could prove advantageous. Moreover, they only evaluate the performance of the LLM component of the RAG pipeline in the experiments, and neglect the influence of the retrieval component and the external knowledge database. To address these issues, this paper constructs a large-scale and more comprehensive benchmark, and evaluates all the components of RAG systems in various RAG application scenarios. Specifically, we have categorized the range of RAG applications into four distinct types-Create, Read, Update, and Delete (CRUD), each representing a unique use case. "Create" refers to scenarios requiring the generation of original, varied content. "Read" involves responding to intricate questions in knowledge-intensive situations. "Update" focuses on revising and rectifying inaccuracies or inconsistencies in pre-existing texts. "Delete" pertains to the task of summarizing extensive texts into more concise forms. For each of these CRUD categories, we have developed comprehensive datasets to evaluate the performance of RAG systems. We also analyze the effects of various components of the RAG system, such as the retriever, the context length, the knowledge base construction, and the LLM. Finally, we provide useful insights for optimizing the RAG technology for different scenarios.
Off-Policy Primal-Dual Safe Reinforcement Learning
Jan 26, 2024Primal-dual safe RL methods commonly perform iterations between the primal update of the policy and the dual update of the Lagrange Multiplier. Such a training paradigm is highly susceptible to the error in cumulative cost estimation since this estimation serves as the key bond connecting the primal and dual update processes. We show that this problem causes significant underestimation of cost when using off-policy methods, leading to the failure to satisfy the safety constraint. To address this issue, we propose \textit{conservative policy optimization}, which learns a policy in a constraint-satisfying area by considering the uncertainty in cost estimation. This improves constraint satisfaction but also potentially hinders reward maximization. We then introduce \textit{local policy convexification} to help eliminate such suboptimality by gradually reducing the estimation uncertainty. We provide theoretical interpretations of the joint coupling effect of these two ingredients and further verify them by extensive experiments. Results on benchmark tasks show that our method not only achieves an asymptotic performance comparable to state-of-the-art on-policy methods while using much fewer samples, but also significantly reduces constraint violation during training. Our code is available at https://github.com/ZifanWu/CAL.
Grimoire is All You Need for Enhancing Large Language Models
Jan 10, 2024In-context Learning (ICL) is one of the key methods for enhancing the performance of large language models on specific tasks by providing a set of few-shot examples. However, the ICL capability of different types of models shows significant variation due to factors such as model architecture, volume of learning data, and the size of parameters. Generally, the larger the model's parameter size and the more extensive the learning data, the stronger its ICL capability. In this paper, we propose a method SLEICL that involves learning from examples using strong language models and then summarizing and transferring these learned skills to weak language models for inference and application. This ensures the stability and effectiveness of ICL. Compared to directly enabling weak language models to learn from prompt examples, SLEICL reduces the difficulty of ICL for these models. Our experiments, conducted on up to eight datasets with five language models, demonstrate that weak language models achieve consistent improvement over their own zero-shot or few-shot capabilities using the SLEICL method. Some weak language models even surpass the performance of GPT4-1106-preview (zero-shot) with the aid of SLEICL.
HiBid: A Cross-Channel Constrained Bidding System with Budget Allocation by Hierarchical Offline Deep Reinforcement Learning
Dec 29, 2023Online display advertising platforms service numerous advertisers by providing real-time bidding (RTB) for the scale of billions of ad requests every day. The bidding strategy handles ad requests cross multiple channels to maximize the number of clicks under the set financial constraints, i.e., total budget and cost-per-click (CPC), etc. Different from existing works mainly focusing on single channel bidding, we explicitly consider cross-channel constrained bidding with budget allocation. Specifically, we propose a hierarchical offline deep reinforcement learning (DRL) framework called ``HiBid'', consisted of a high-level planner equipped with auxiliary loss for non-competitive budget allocation, and a data augmentation enhanced low-level executor for adaptive bidding strategy in response to allocated budgets. Additionally, a CPC-guided action selection mechanism is introduced to satisfy the cross-channel CPC constraint. Through extensive experiments on both the large-scale log data and online A/B testing, we confirm that HiBid outperforms six baselines in terms of the number of clicks, CPC satisfactory ratio, and return-on-investment (ROI). We also deploy HiBid on Meituan advertising platform to already service tens of thousands of advertisers every day.