 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimin Niu
Fake Artificial Intelligence Generated Contents (FAIGC): A Survey of Theories, Detection Methods, and Opportunities
Apr 25, 2024
In recent years, generative artificial intelligence models, represented by Large Language Models (LLMs) and Diffusion Models (DMs), have revolutionized content production methods. These artificial intelligence-generated content (AIGC) have become deeply embedded in various aspects of daily life and work, spanning texts, images, videos, and audio. The authenticity of AI-generated content is progressively enhancing, approaching human-level creative standards. However, these technologies have also led to the emergence of Fake Artificial Intelligence Generated Content (FAIGC), posing new challenges in distinguishing genuine information. It is crucial to recognize that AIGC technology is akin to a double-edged sword; its potent generative capabilities, while beneficial, also pose risks for the creation and dissemination of FAIGC. In this survey, We propose a new taxonomy that provides a more comprehensive breakdown of the space of FAIGC methods today. Next, we explore the modalities and generative technologies of FAIGC, categorized under AI-generated disinformation and AI-generated misinformation. From various perspectives, we then introduce FAIGC detection methods, including Deceptive FAIGC Detection, Deepfake Detection, and Hallucination-based FAIGC Detection. Finally, we discuss outstanding challenges and promising areas for future research.
CRUD-RAG: A Comprehensive Chinese Benchmark for Retrieval-Augmented Generation of Large Language Models
Jan 30, 2024Retrieval-Augmented Generation (RAG) is a technique that enhances the capabilities of large language models (LLMs) by incorporating external knowledge sources. This method addresses common LLM limitations, including outdated information and the tendency to produce inaccurate "hallucinated" content. However, the evaluation of RAG systems is challenging, as existing benchmarks are limited in scope and diversity. Most of the current benchmarks predominantly assess question-answering applications, overlooking the broader spectrum of situations where RAG could prove advantageous. Moreover, they only evaluate the performance of the LLM component of the RAG pipeline in the experiments, and neglect the influence of the retrieval component and the external knowledge database. To address these issues, this paper constructs a large-scale and more comprehensive benchmark, and evaluates all the components of RAG systems in various RAG application scenarios. Specifically, we have categorized the range of RAG applications into four distinct types-Create, Read, Update, and Delete (CRUD), each representing a unique use case. "Create" refers to scenarios requiring the generation of original, varied content. "Read" involves responding to intricate questions in knowledge-intensive situations. "Update" focuses on revising and rectifying inaccuracies or inconsistencies in pre-existing texts. "Delete" pertains to the task of summarizing extensive texts into more concise forms. For each of these CRUD categories, we have developed comprehensive datasets to evaluate the performance of RAG systems. We also analyze the effects of various components of the RAG system, such as the retriever, the context length, the knowledge base construction, and the LLM. Finally, we provide useful insights for optimizing the RAG technology for different scenarios.
UHGEval: Benchmarking the Hallucination of Chinese Large Language Models via Unconstrained Generation
Nov 26, 2023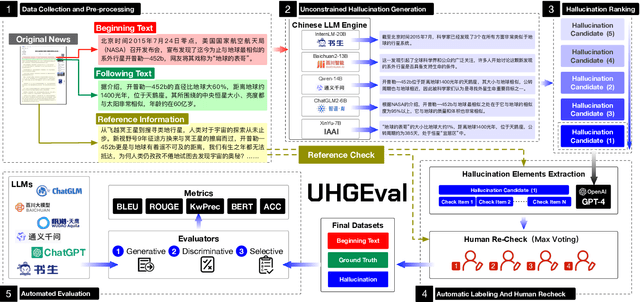
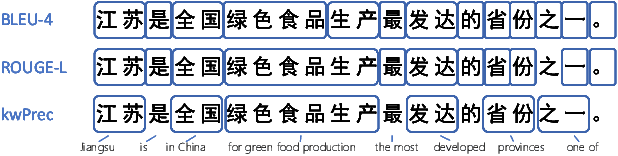

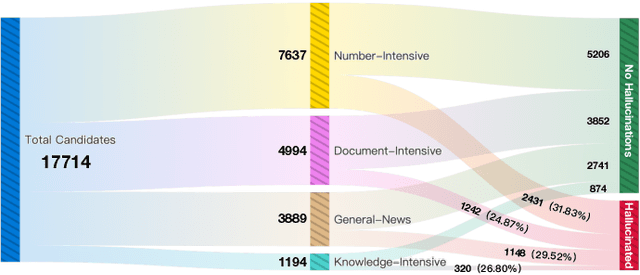
Large language models (LLMs) have emerged as pivotal contributors in contemporary natural language processing and are increasingly being applied across a diverse range of industries. However, these large-scale probabilistic statistical models cannot currently ensure the requisite quality in professional content generation. These models often produce hallucinated text, compromising their practical utility in professional contexts. To assess the authentic reliability of LLMs in text generation, numerous initiatives have developed benchmark evaluations for hallucination phenomena. Nevertheless, these benchmarks frequently utilize constrained generation techniques due to cost and temporal constraints. These techniques encompass the use of directed hallucination induction and strategies that deliberately alter authentic text to produce hallucinations. These approaches are not congruent with the unrestricted text generation demanded by real-world applications. Furthermore, a well-established Chinese-language dataset dedicated to the evaluation of hallucinations in text generation is presently lacking. Consequently, we have developed an Unconstrained Hallucination Generation Evaluation (UHGEval) benchmark, designed to compile outputs produced with minimal restrictions by LLMs. Concurrently, we have established a comprehensive benchmark evaluation framework to aid subsequent researchers in undertaking scalable and reproducible experiments. We have also executed extensive experiments, evaluating prominent Chinese language models and the GPT series models to derive professional performance insights regarding hallucination challenges.