 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiao Li
NewsBench: Systematic Evaluation of LLMs for Writing Proficiency and Safety Adherence in Chinese Journalistic Editorial Applications
Feb 29, 2024
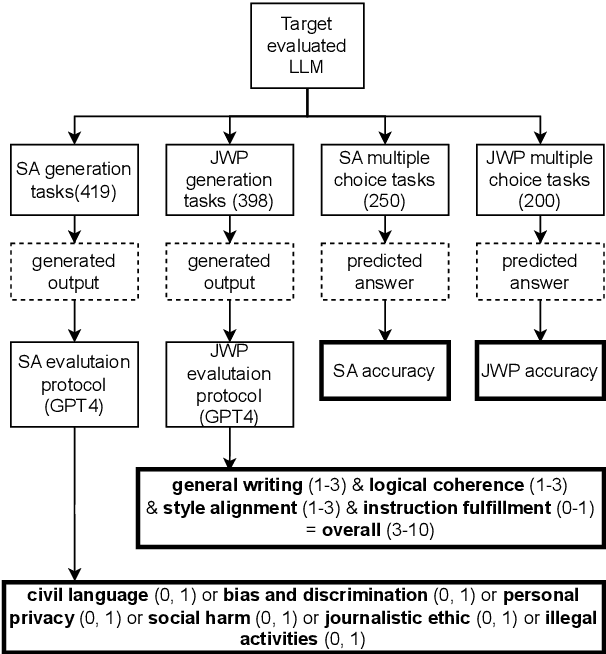
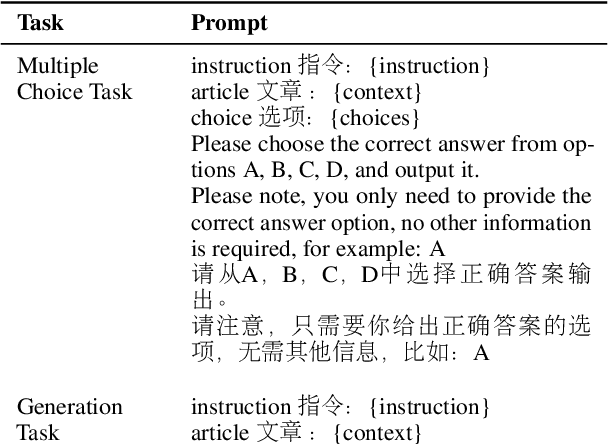
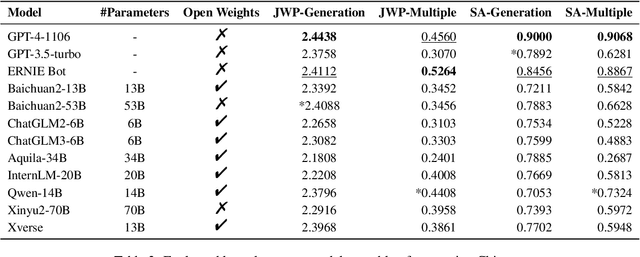
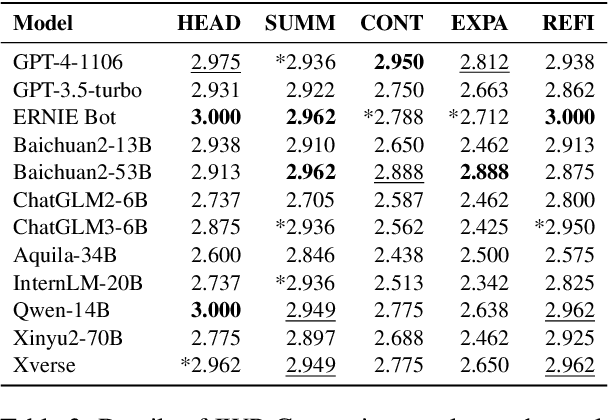
This study presents NewsBench, a novel benchmark framework developed to evaluate the capability of Large Language Models (LLMs) in Chinese Journalistic Writing Proficiency (JWP) and their Safety Adherence (SA), addressing the gap between journalistic ethics and the risks associated with AI utilization. Comprising 1,267 tasks across 5 editorial applications, 7 aspects (including safety and journalistic writing with 4 detailed facets), and spanning 24 news topics domains, NewsBench employs two GPT-4 based automatic evaluation protocols validated by human assessment. Our comprehensive analysis of 11 LLMs highlighted GPT-4 and ERNIE Bot as top performers, yet revealed a relative deficiency in journalistic ethic adherence during creative writing tasks. These findings underscore the need for enhanced ethical guidance in AI-generated journalistic content, marking a step forward in aligning AI capabilities with journalistic standards and safety considerations.
Exploring Multi-Document Information Consolidation for Scientific Sentiment Summarization
Feb 28, 2024Modern natural language generation systems with LLMs exhibit the capability to generate a plausible summary of multiple documents; however, it is uncertain if models truly possess the ability of information consolidation to generate summaries, especially on those source documents with opinionated information. To make scientific sentiment summarization more grounded, we hypothesize that in peer review human meta-reviewers follow a three-layer framework of sentiment consolidation to write meta-reviews and it represents the logic of summarizing scientific sentiments in meta-review generation. The framework is validated via human annotation. Based on the framework, we propose evaluation metrics to assess the quality of generated meta-reviews, and we find that the hypothesis of the sentiment consolidation framework works out empirically when we incorporate it as prompts for LLMs to generate meta-reviews in extensive experiments.
Neural Network-Based Histologic Remission Prediction In Ulcerative Colitis
Aug 28, 2023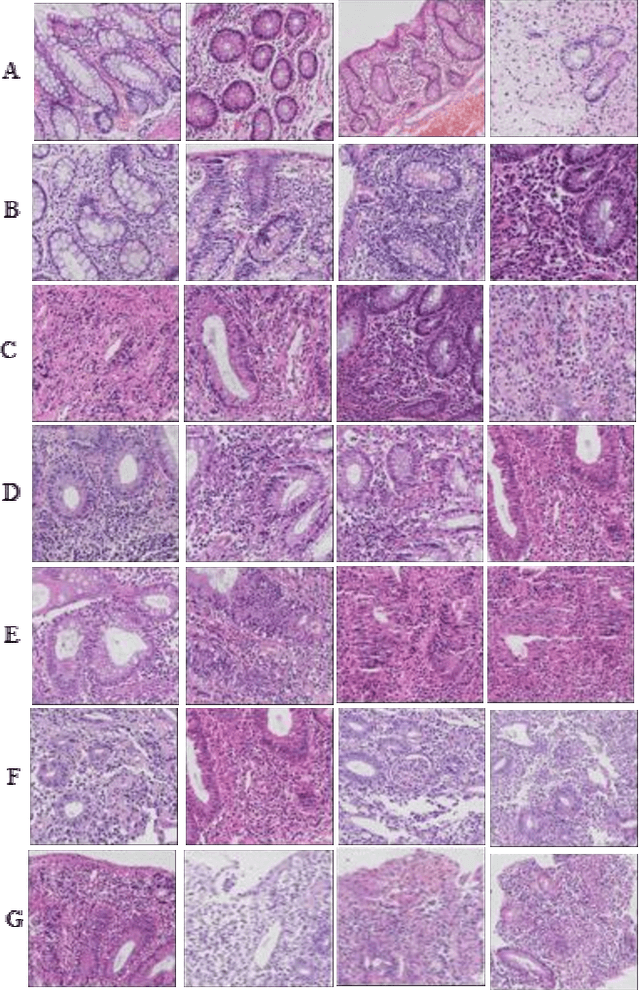
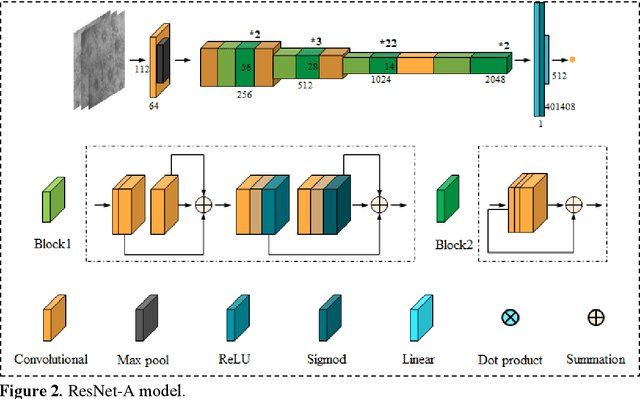
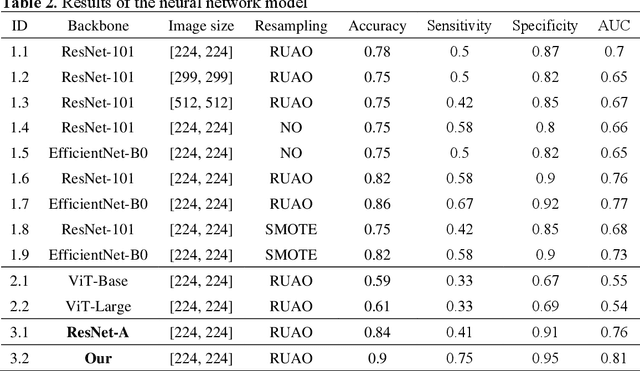
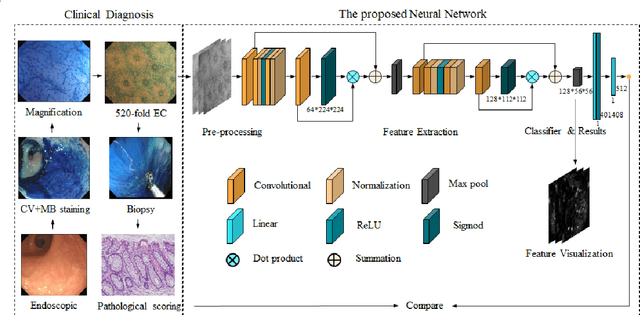
BACKGROUND & AIMS: Histological remission (HR) is advocated and considered as a new therapeutic target in ulcerative colitis (UC). Diagnosis of histologic remission currently relies on biopsy; during this process, patients are at risk for bleeding, infection, and post-biopsy fibrosis. In addition, histologic response scoring is complex and time-consuming, and there is heterogeneity among pathologists. Endocytoscopy (EC) is a novel ultra-high magnification endoscopic technique that can provide excellent in vivo assessment of glands. Based on the EC technique, we propose a neural network model that can assess histological disease activity in UC using EC images to address the above issues. The experiment results demonstrate that the proposed method can assist patients in precise treatment and prognostic assessment. METHODS: We construct a neural network model for UC evaluation. A total of 5105 images of 154 intestinal segments from 87 patients undergoing EC treatment at a center in China between March 2022 and March 2023 are scored according to the Geboes score. Subsequently, 103 intestinal segments are used as the training set, 16 intestinal segments are used as the validation set for neural network training, and the remaining 35 intestinal segments are used as the test set to measure the model performance together with the validation set. RESULTS: By treating HR as a negative category and histologic activity as a positive category, the proposed neural network model can achieve an accuracy of 0.9, a specificity of 0.95, a sensitivity of 0.75, and an area under the curve (AUC) of 0.81. CONCLUSION: We develop a specific neural network model that can distinguish histologic remission/activity in EC images of UC, which helps to accelerate clinical histological diagnosis. keywords: ulcerative colitis; Endocytoscopy; Geboes score; neural network.
A novel tactile palm for robotic object manipulation
Aug 10, 2023
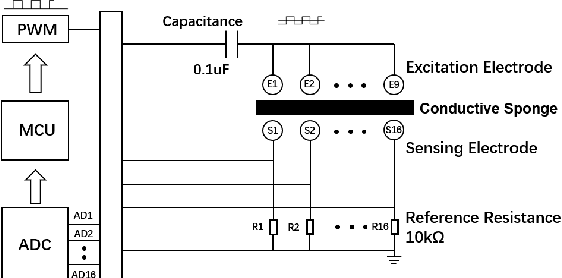
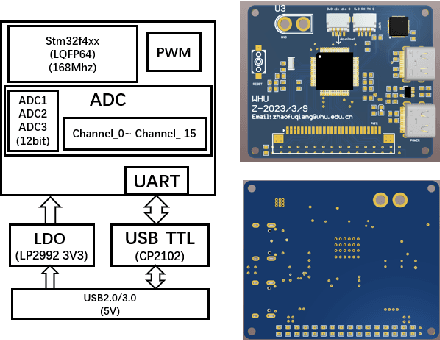
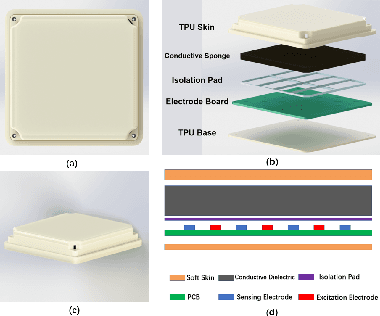
Tactile sensing is of great importance during human hand usage such as object exploration, grasping and manipulation. Different types of tactile sensors have been designed during the past decades, which are mainly focused on either the fingertips for grasping or the upper-body for human-robot interaction. In this paper, a novel soft tactile sensor has been designed to mimic the functionality of human palm that can estimate the contact state of different objects. The tactile palm mainly consists of three parts including an electrode array, a soft cover skin and the conductive sponge. The design principle are described in details, with a number of experiments showcasing the effectiveness of the proposed design.
Fast calibration for ultrasound imaging guidance based on depth camera
Aug 10, 2023
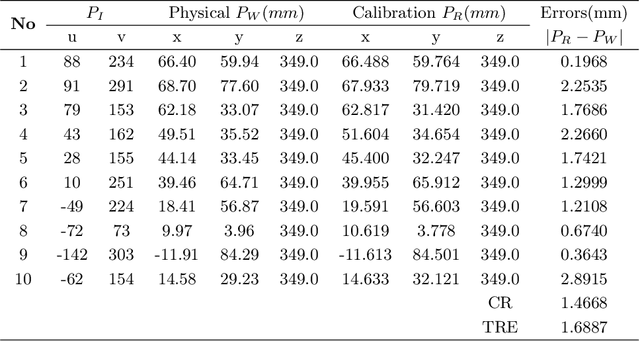


During the process of robot-assisted ultrasound(US) puncture, it is important to estimate the location of the puncture from the 2D US images. To this end, the calibration of the US image becomes an important issue. In this paper, we proposed a depth camera-based US calibration method, where an easy-to-deploy device is designed for the calibration. With this device, the coordinates of the puncture needle tip are collected respectively in US image and in the depth camera, upon which a correspondence matrix is built for calibration. Finally, a number of experiments are conducted to validate the effectiveness of our calibration method.
Learning Autonomous Ultrasound via Latent Task Representation and Robotic Skills Adaptation
Jul 25, 2023As medical ultrasound is becoming a prevailing examination approach nowadays, robotic ultrasound systems can facilitate the scanning process and prevent professional sonographers from repetitive and tedious work. Despite the recent progress, it is still a challenge to enable robots to autonomously accomplish the ultrasound examination, which is largely due to the lack of a proper task representation method, and also an adaptation approach to generalize learned skills across different patients. To solve these problems, we propose the latent task representation and the robotic skills adaptation for autonomous ultrasound in this paper. During the offline stage, the multimodal ultrasound skills are merged and encapsulated into a low-dimensional probability model through a fully self-supervised framework, which takes clinically demonstrated ultrasound images, probe orientations, and contact forces into account. During the online stage, the probability model will select and evaluate the optimal prediction. For unstable singularities, the adaptive optimizer fine-tunes them to near and stable predictions in high-confidence regions. Experimental results show that the proposed approach can generate complex ultrasound strategies for diverse populations and achieve significantly better quantitative results than our previous method.
3D-SeqMOS: A Novel Sequential 3D Moving Object Segmentation in Autonomous Driving
Jul 18, 2023
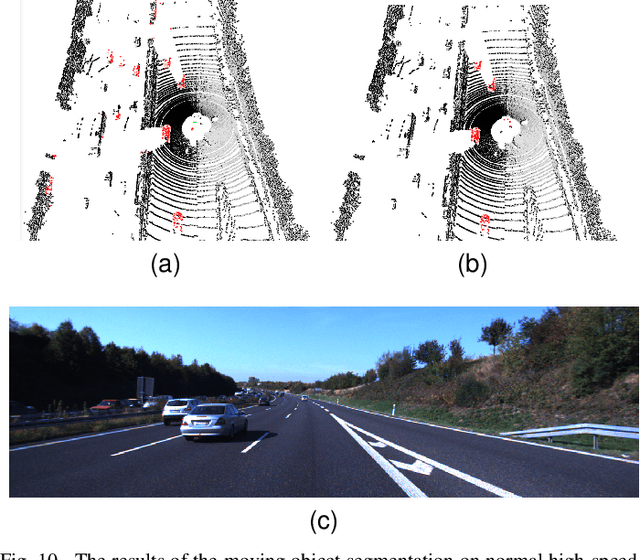
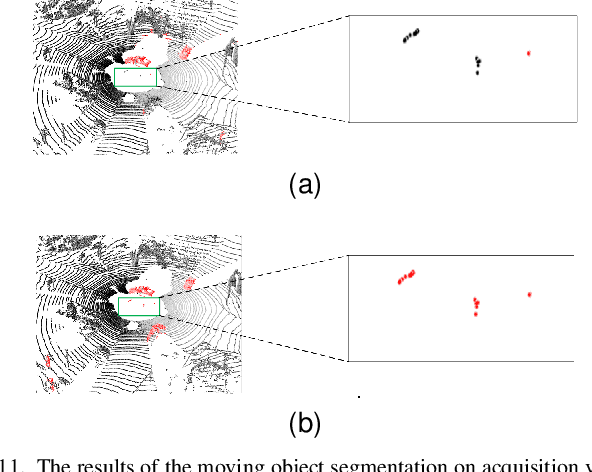
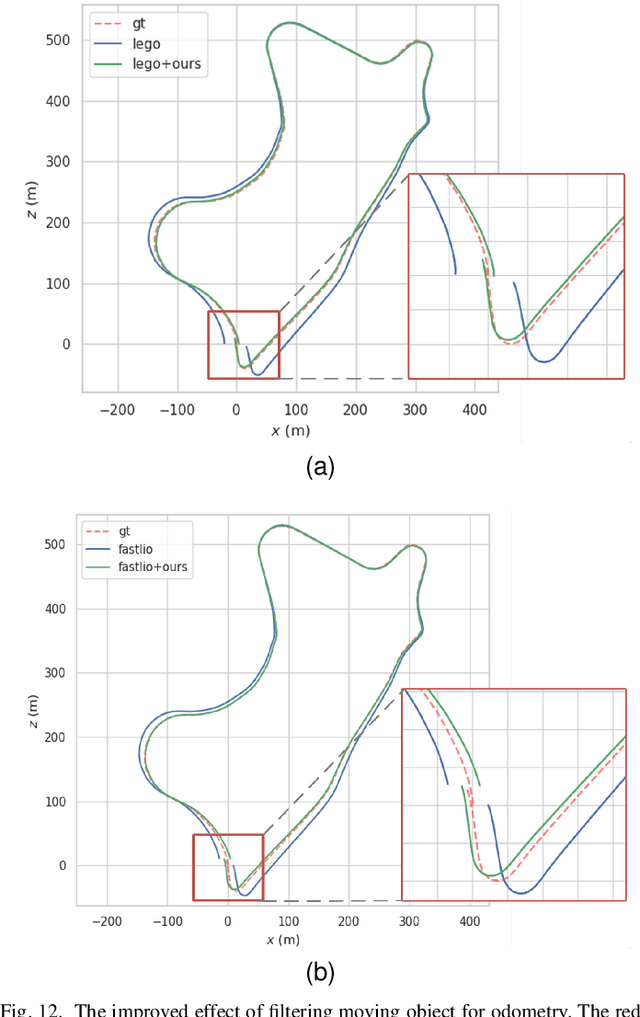
For the SLAM system in robotics and autonomous driving, the accuracy of front-end odometry and back-end loop-closure detection determine the whole intelligent system performance. But the LiDAR-SLAM could be disturbed by current scene moving objects, resulting in drift errors and even loop-closure failure. Thus, the ability to detect and segment moving objects is essential for high-precision positioning and building a consistent map. In this paper, we address the problem of moving object segmentation from 3D LiDAR scans to improve the odometry and loop-closure accuracy of SLAM. We propose a novel 3D Sequential Moving-Object-Segmentation (3D-SeqMOS) method that can accurately segment the scene into moving and static objects, such as moving and static cars. Different from the existing projected-image method, we process the raw 3D point cloud and build a 3D convolution neural network for MOS task. In addition, to make full use of the spatio-temporal information of point cloud, we propose a point cloud residual mechanism using the spatial features of current scan and the temporal features of previous residual scans. Besides, we build a complete SLAM framework to verify the effectiveness and accuracy of 3D-SeqMOS. Experiments on SemanticKITTI dataset show that our proposed 3D-SeqMOS method can effectively detect moving objects and improve the accuracy of LiDAR odometry and loop-closure detection. The test results show our 3D-SeqMOS outperforms the state-of-the-art method by 12.4%. We extend the proposed method to the SemanticKITTI: Moving Object Segmentation competition and achieve the 2nd in the leaderboard, showing its effectiveness.
Your Room is not Private: Gradient Inversion Attack for Deep Q-Learning
Jun 15, 2023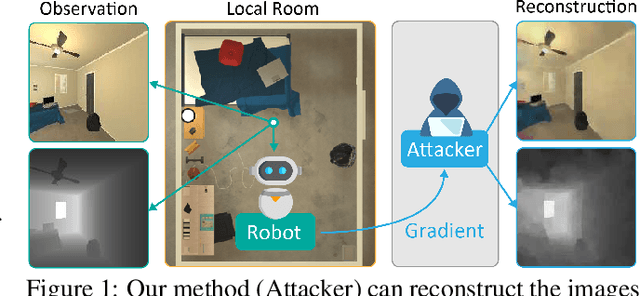
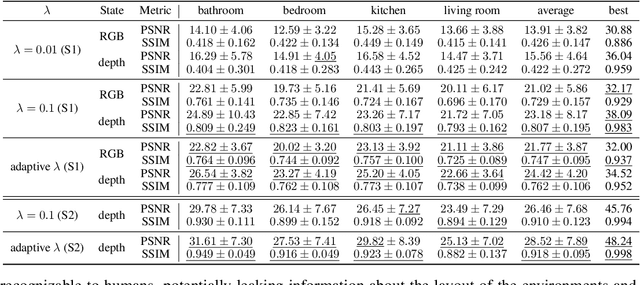
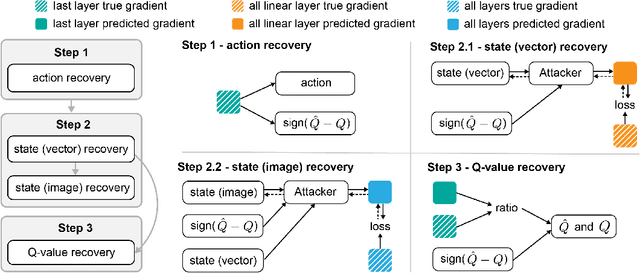

The prominence of embodied Artificial Intelligence (AI), which empowers robots to navigate, perceive, and engage within virtual environments, has attracted significant attention, owing to the remarkable advancements in computer vision and large language models. Privacy emerges as a pivotal concern within the realm of embodied AI, as the robot access substantial personal information. However, the issue of privacy leakage in embodied AI tasks, particularly in relation to decision-making algorithms, has not received adequate consideration in research. This paper aims to address this gap by proposing an attack on the Deep Q-Learning algorithm, utilizing gradient inversion to reconstruct states, actions, and Q-values. The choice of using gradients for the attack is motivated by the fact that commonly employed federated learning techniques solely utilize gradients computed based on private user data to optimize models, without storing or transmitting the data to public servers. Nevertheless, these gradients contain sufficient information to potentially expose private data. To validate our approach, we conduct experiments on the AI2THOR simulator and evaluate our algorithm on active perception, a prevalent task in embodied AI. The experimental results convincingly demonstrate the effectiveness of our method in successfully recovering all information from the data across all 120 room layouts.
THiFLY Research at SemEval-2023 Task 7: A Multi-granularity System for CTR-based Textual Entailment and Evidence Retrieval
Jun 02, 2023

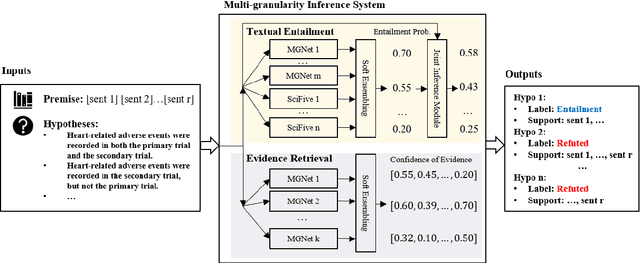
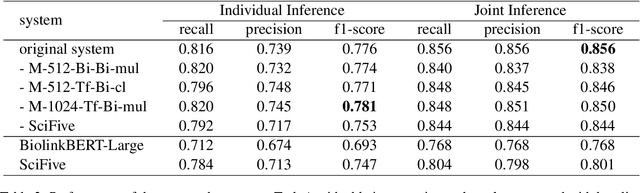
The NLI4CT task aims to entail hypotheses based on Clinical Trial Reports (CTRs) and retrieve the corresponding evidence supporting the justification. This task poses a significant challenge, as verifying hypotheses in the NLI4CT task requires the integration of multiple pieces of evidence from one or two CTR(s) and the application of diverse levels of reasoning, including textual and numerical. To address these problems, we present a multi-granularity system for CTR-based textual entailment and evidence retrieval in this paper. Specifically, we construct a Multi-granularity Inference Network (MGNet) that exploits sentence-level and token-level encoding to handle both textual entailment and evidence retrieval tasks. Moreover, we enhance the numerical inference capability of the system by leveraging a T5-based model, SciFive, which is pre-trained on the medical corpus. Model ensembling and a joint inference method are further utilized in the system to increase the stability and consistency of inference. The system achieves f1-scores of 0.856 and 0.853 on textual entailment and evidence retrieval tasks, resulting in the best performance on both subtasks. The experimental results corroborate the effectiveness of our proposed method. Our code is publicly available at https://github.com/THUMLP/NLI4CT.
Towards Summarizing Multiple Documents with Hierarchical Relationships
May 02, 2023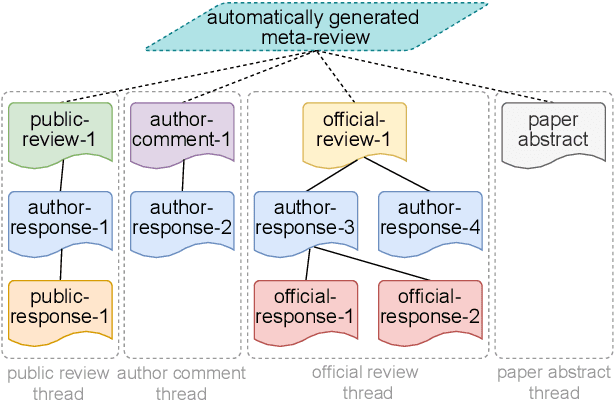

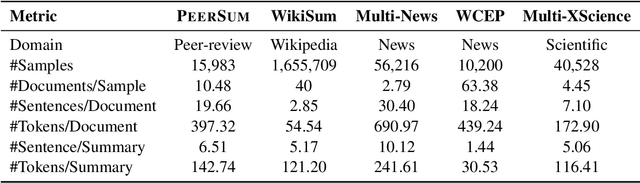
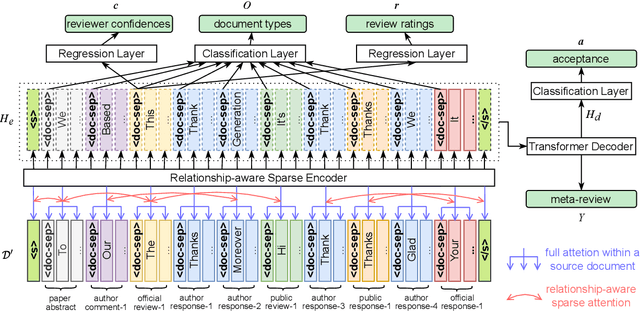
Most existing multi-document summarization (MDS) datasets lack human-generated and genuine (i.e., not synthetic) summaries or source documents with explicit inter-document relationships that a summary must capture. To enhance the capabilities of MDS systems we present PeerSum, a novel dataset for generating meta-reviews of scientific papers, where the meta-reviews are highly abstractive and genuine summaries of reviews and corresponding discussions. These source documents have rich inter-document relationships of an explicit hierarchical structure with cross-references and often feature conflicts. As there is a scarcity of research that incorporates hierarchical relationships into MDS systems through attention manipulation on pre-trained language models, we additionally present Rammer (Relationship-aware Multi-task Meta-review Generator), a meta-review generation model that uses sparse attention based on the hierarchical relationships and a multi-task objective that predicts several metadata features in addition to the standard text generation objective. Our experimental results show that PeerSum is a challenging dataset, and Rammer outperforms other strong baseline MDS models under various evaluation metrics.