 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYiwen Chen
ARO: Large Language Model Supervised Robotics Text2Skill Autonomous Learning
Mar 23, 2024
Robotics learning highly relies on human expertise and efforts, such as demonstrations, design of reward functions in reinforcement learning, performance evaluation using human feedback, etc. However, reliance on human assistance can lead to expensive learning costs and make skill learning difficult to scale. In this work, we introduce the Large Language Model Supervised Robotics Text2Skill Autonomous Learning (ARO) framework, which aims to replace human participation in the robot skill learning process with large-scale language models that incorporate reward function design and performance evaluation. We provide evidence that our approach enables fully autonomous robot skill learning, capable of completing partial tasks without human intervention. Furthermore, we also analyze the limitations of this approach in task understanding and optimization stability.
Learn to Optimize Denoising Scores for 3D Generation: A Unified and Improved Diffusion Prior on NeRF and 3D Gaussian Splatting
Dec 08, 2023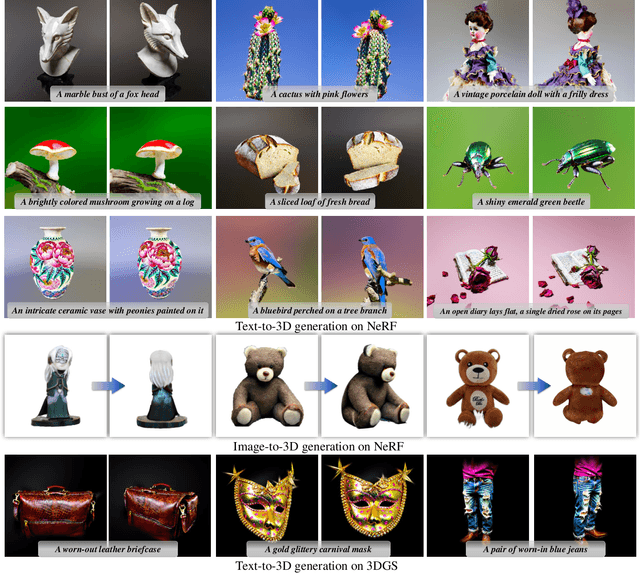
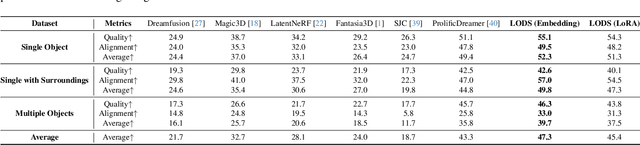
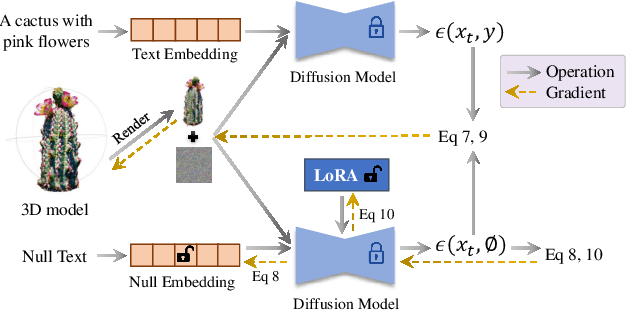

We propose a unified framework aimed at enhancing the diffusion priors for 3D generation tasks. Despite the critical importance of these tasks, existing methodologies often struggle to generate high-caliber results. We begin by examining the inherent limitations in previous diffusion priors. We identify a divergence between the diffusion priors and the training procedures of diffusion models that substantially impairs the quality of 3D generation. To address this issue, we propose a novel, unified framework that iteratively optimizes both the 3D model and the diffusion prior. Leveraging the different learnable parameters of the diffusion prior, our approach offers multiple configurations, affording various trade-offs between performance and implementation complexity. Notably, our experimental results demonstrate that our method markedly surpasses existing techniques, establishing new state-of-the-art in the realm of text-to-3D generation. Furthermore, our approach exhibits impressive performance on both NeRF and the newly introduced 3D Gaussian Splatting backbones. Additionally, our framework yields insightful contributions to the understanding of recent score distillation methods, such as the VSD and DDS loss.
GaussianEditor: Swift and Controllable 3D Editing with Gaussian Splatting
Dec 01, 20233D editing plays a crucial role in many areas such as gaming and virtual reality. Traditional 3D editing methods, which rely on representations like meshes and point clouds, often fall short in realistically depicting complex scenes. On the other hand, methods based on implicit 3D representations, like Neural Radiance Field (NeRF), render complex scenes effectively but suffer from slow processing speeds and limited control over specific scene areas. In response to these challenges, our paper presents GaussianEditor, an innovative and efficient 3D editing algorithm based on Gaussian Splatting (GS), a novel 3D representation. GaussianEditor enhances precision and control in editing through our proposed Gaussian semantic tracing, which traces the editing target throughout the training process. Additionally, we propose Hierarchical Gaussian splatting (HGS) to achieve stabilized and fine results under stochastic generative guidance from 2D diffusion models. We also develop editing strategies for efficient object removal and integration, a challenging task for existing methods. Our comprehensive experiments demonstrate GaussianEditor's superior control, efficacy, and rapid performance, marking a significant advancement in 3D editing. Project Page: https://buaacyw.github.io/gaussian-editor/
Map-assisted TDOA Localization Enhancement Based On CNN
Nov 09, 2023For signal processing related to localization technologies, non line of sight (NLOS) multipaths have great impact over the localization error level. This study proposes a localization correction method based on convolution neural network (CNN) that extracts obstacles' features from maps to predict the localization errors caused by NLOS effects. A novel compensation scheme is developed and structured around the localization error in terms of distance and azimuth angle predicted by the CNN. Four prediction tasks are executed over different building distributions within the maps for typical urban scenario, resulting in CNN models with high prediction accuracy. Finally, a thorough comparison of the accuracy performance between the time difference of arrival (TDOA) localization algorithm and the results after the error compensation reveals that, generally, the CNN prediction approach demonstrates a great localization error correction performance. It can be observed that the powerful feature extraction capability of CNN can be exploited by processing surrounding maps to predict localization error distribution, which has great potential in further enhancement of TDOA performance under challenging scenarios with rich multi-path propagation.
IT3D: Improved Text-to-3D Generation with Explicit View Synthesis
Aug 22, 2023
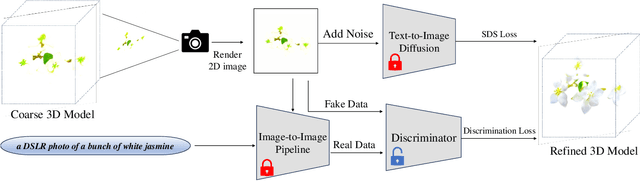


Recent strides in Text-to-3D techniques have been propelled by distilling knowledge from powerful large text-to-image diffusion models (LDMs). Nonetheless, existing Text-to-3D approaches often grapple with challenges such as over-saturation, inadequate detailing, and unrealistic outputs. This study presents a novel strategy that leverages explicitly synthesized multi-view images to address these issues. Our approach involves the utilization of image-to-image pipelines, empowered by LDMs, to generate posed high-quality images based on the renderings of coarse 3D models. Although the generated images mostly alleviate the aforementioned issues, challenges such as view inconsistency and significant content variance persist due to the inherent generative nature of large diffusion models, posing extensive difficulties in leveraging these images effectively. To overcome this hurdle, we advocate integrating a discriminator alongside a novel Diffusion-GAN dual training strategy to guide the training of 3D models. For the incorporated discriminator, the synthesized multi-view images are considered real data, while the renderings of the optimized 3D models function as fake data. We conduct a comprehensive set of experiments that demonstrate the effectiveness of our method over baseline approaches.
A New Heterogeneous Hybrid MIMO Receive Structure of Rapidly Eliminating DOA Ambiguity
Aug 16, 2023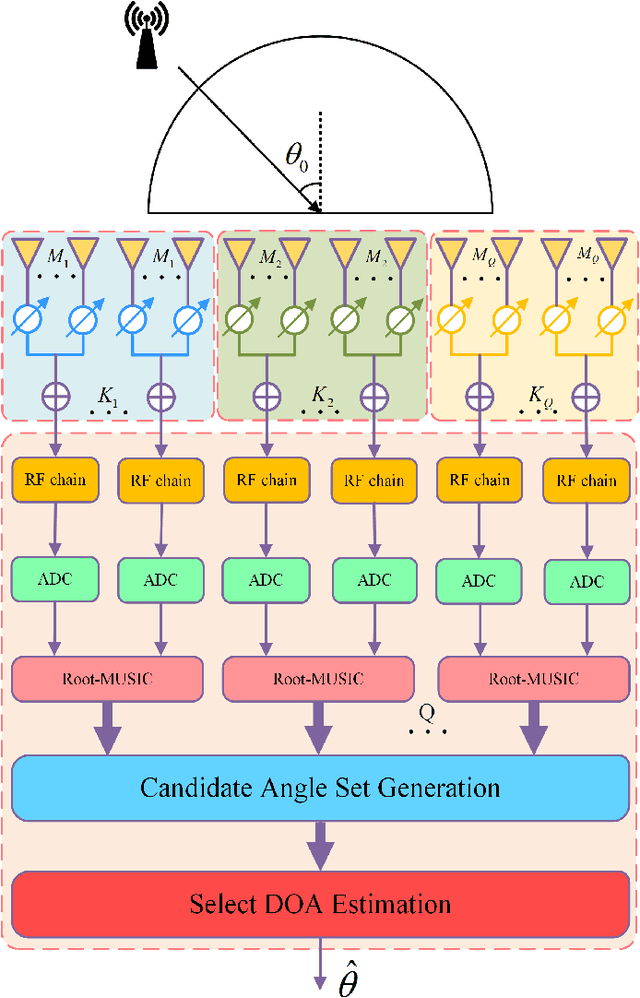

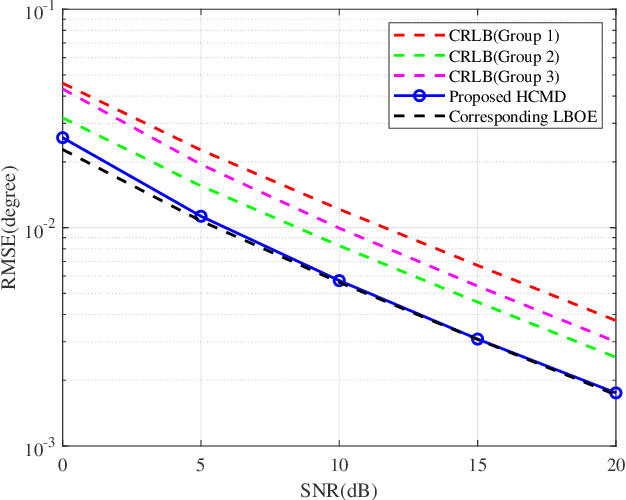
Massive multiple input multiple output(MIMO)-based fully-digital receive antenna arrays eventuate a huge amount of circuit costs and complexity to direction of arrival(DOA) estimation, which is hard to satisfy the needs of high precision and low cost in future green wireless communication. To address this challenge, a novel heterogeneous hybrid MIMO receiver is proposed in this paper and a high performance DOA estimator called heterogeneous cross-minimum distance (HCMD) is developed based on the structure. The antenna arrays are first divided into multiple groups, and each group adopts a different hybrid structure. The virtual antenna arrays of these groups are then used for DOA estimation to generate multiple candidate angle sets, where each set contains a unique true solution and multiple pseudo-solutions. Finally, the cross-distance minimization method is applied to the multiple candidate angle sets to select the corresponding true solution for each group, and the final DOA estimation is given by combining the multiple true solutions. Simulation results show that as the number of antennas tends to large-scale, the proposed method can rapidly find the true solution for each group and achieve excellent estimation performance.
3D-SeqMOS: A Novel Sequential 3D Moving Object Segmentation in Autonomous Driving
Jul 18, 2023
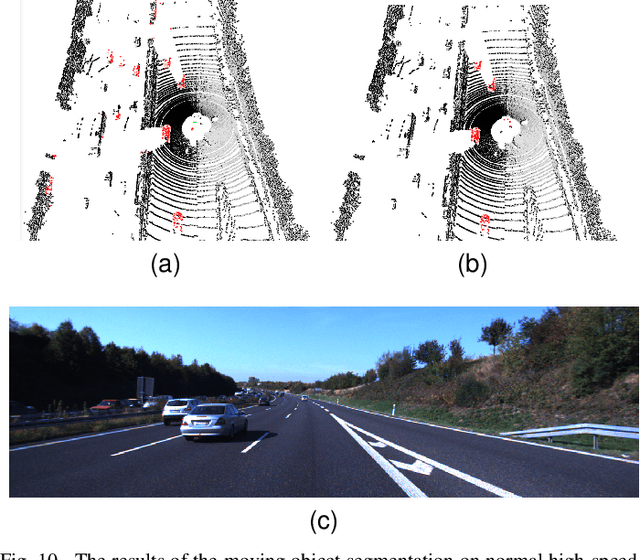
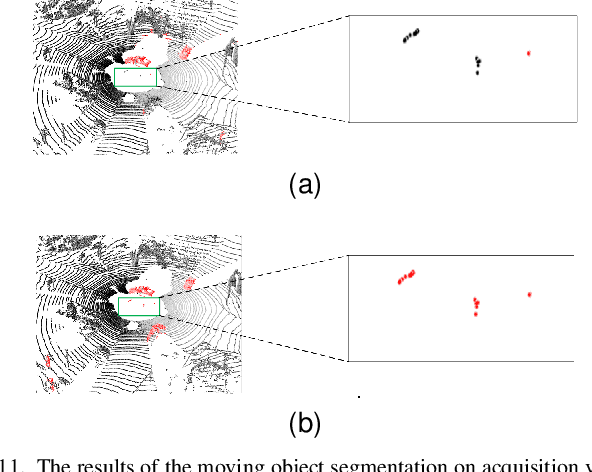
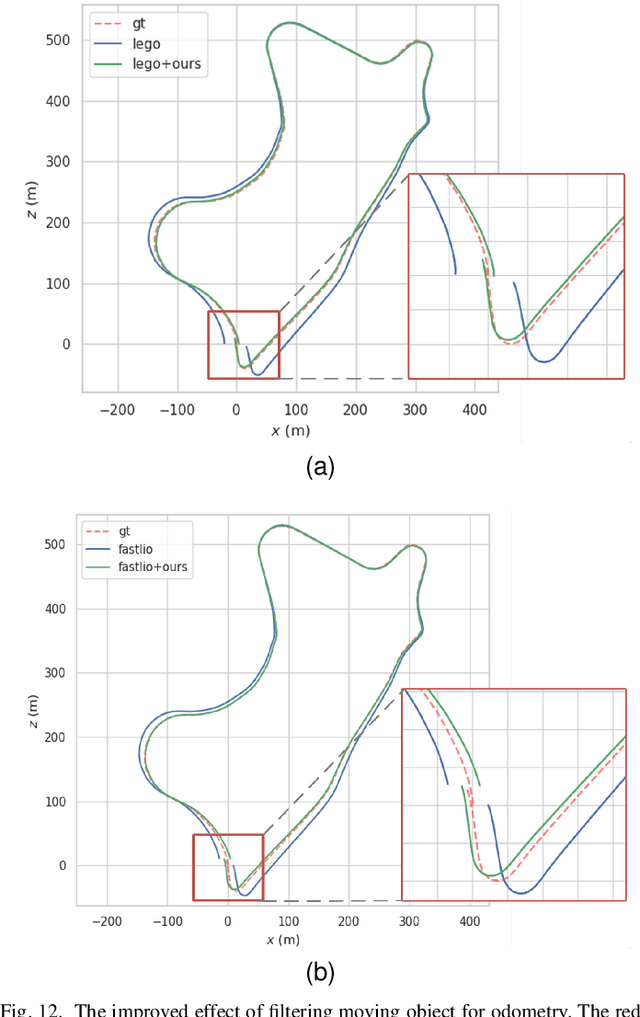
For the SLAM system in robotics and autonomous driving, the accuracy of front-end odometry and back-end loop-closure detection determine the whole intelligent system performance. But the LiDAR-SLAM could be disturbed by current scene moving objects, resulting in drift errors and even loop-closure failure. Thus, the ability to detect and segment moving objects is essential for high-precision positioning and building a consistent map. In this paper, we address the problem of moving object segmentation from 3D LiDAR scans to improve the odometry and loop-closure accuracy of SLAM. We propose a novel 3D Sequential Moving-Object-Segmentation (3D-SeqMOS) method that can accurately segment the scene into moving and static objects, such as moving and static cars. Different from the existing projected-image method, we process the raw 3D point cloud and build a 3D convolution neural network for MOS task. In addition, to make full use of the spatio-temporal information of point cloud, we propose a point cloud residual mechanism using the spatial features of current scan and the temporal features of previous residual scans. Besides, we build a complete SLAM framework to verify the effectiveness and accuracy of 3D-SeqMOS. Experiments on SemanticKITTI dataset show that our proposed 3D-SeqMOS method can effectively detect moving objects and improve the accuracy of LiDAR odometry and loop-closure detection. The test results show our 3D-SeqMOS outperforms the state-of-the-art method by 12.4%. We extend the proposed method to the SemanticKITTI: Moving Object Segmentation competition and achieve the 2nd in the leaderboard, showing its effectiveness.
StyleAvatar3D: Leveraging Image-Text Diffusion Models for High-Fidelity 3D Avatar Generation
May 31, 2023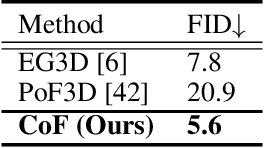
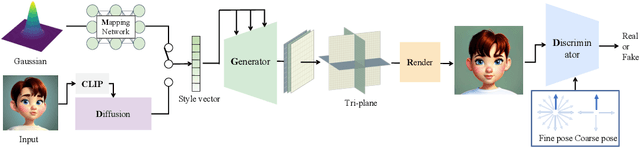


The recent advancements in image-text diffusion models have stimulated research interest in large-scale 3D generative models. Nevertheless, the limited availability of diverse 3D resources presents significant challenges to learning. In this paper, we present a novel method for generating high-quality, stylized 3D avatars that utilizes pre-trained image-text diffusion models for data generation and a Generative Adversarial Network (GAN)-based 3D generation network for training. Our method leverages the comprehensive priors of appearance and geometry offered by image-text diffusion models to generate multi-view images of avatars in various styles. During data generation, we employ poses extracted from existing 3D models to guide the generation of multi-view images. To address the misalignment between poses and images in data, we investigate view-specific prompts and develop a coarse-to-fine discriminator for GAN training. We also delve into attribute-related prompts to increase the diversity of the generated avatars. Additionally, we develop a latent diffusion model within the style space of StyleGAN to enable the generation of avatars based on image inputs. Our approach demonstrates superior performance over current state-of-the-art methods in terms of visual quality and diversity of the produced avatars.
MoDA: Modeling Deformable 3D Objects from Casual Videos
Apr 17, 2023
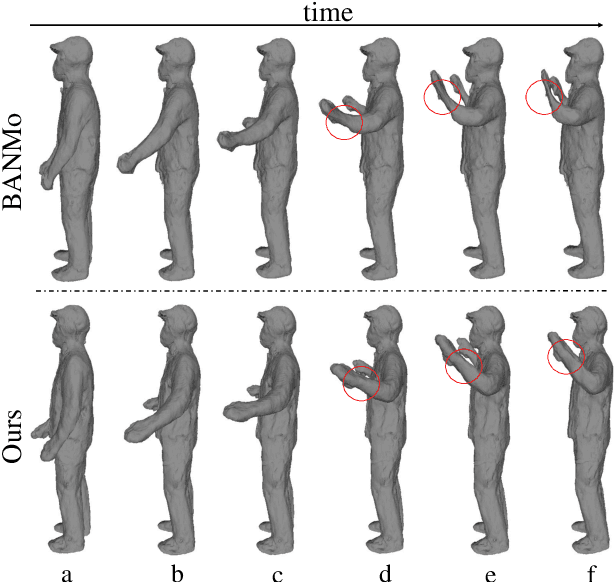
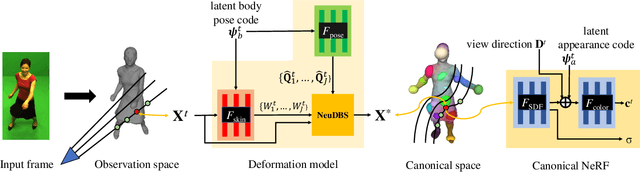
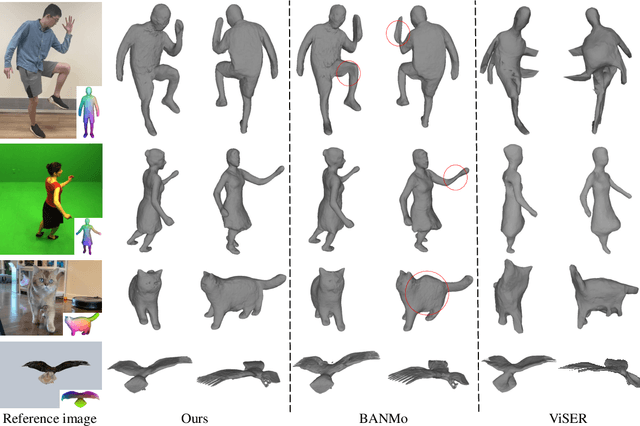
In this paper, we focus on the challenges of modeling deformable 3D objects from casual videos. With the popularity of neural radiance fields (NeRF), many works extend it to dynamic scenes with a canonical NeRF and a deformation model that achieves 3D point transformation between the observation space and the canonical space. Recent works rely on linear blend skinning (LBS) to achieve the canonical-observation transformation. However, the linearly weighted combination of rigid transformation matrices is not guaranteed to be rigid. As a matter of fact, unexpected scale and shear factors often appear. In practice, using LBS as the deformation model can always lead to skin-collapsing artifacts for bending or twisting motions. To solve this problem, we propose neural dual quaternion blend skinning (NeuDBS) to achieve 3D point deformation, which can perform rigid transformation without skin-collapsing artifacts. Besides, we introduce a texture filtering approach for texture rendering that effectively minimizes the impact of noisy colors outside target deformable objects. Extensive experiments on real and synthetic datasets show that our approach can reconstruct 3D models for humans and animals with better qualitative and quantitative performance than state-of-the-art methods.
StyleRF: Zero-shot 3D Style Transfer of Neural Radiance Fields
Mar 24, 2023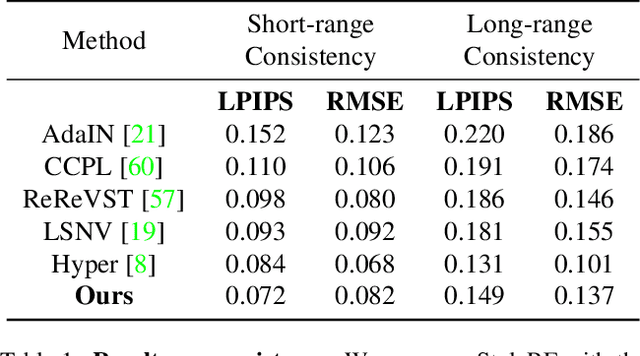
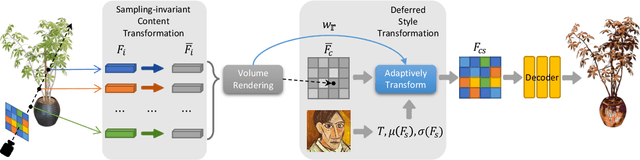
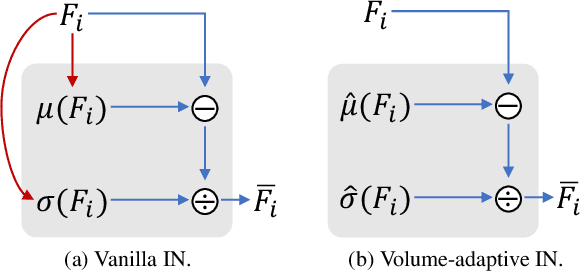
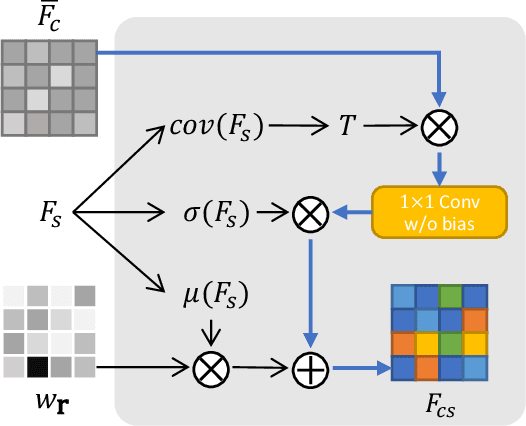
3D style transfer aims to render stylized novel views of a 3D scene with multi-view consistency. However, most existing work suffers from a three-way dilemma over accurate geometry reconstruction, high-quality stylization, and being generalizable to arbitrary new styles. We propose StyleRF (Style Radiance Fields), an innovative 3D style transfer technique that resolves the three-way dilemma by performing style transformation within the feature space of a radiance field. StyleRF employs an explicit grid of high-level features to represent 3D scenes, with which high-fidelity geometry can be reliably restored via volume rendering. In addition, it transforms the grid features according to the reference style which directly leads to high-quality zero-shot style transfer. StyleRF consists of two innovative designs. The first is sampling-invariant content transformation that makes the transformation invariant to the holistic statistics of the sampled 3D points and accordingly ensures multi-view consistency. The second is deferred style transformation of 2D feature maps which is equivalent to the transformation of 3D points but greatly reduces memory footprint without degrading multi-view consistency. Extensive experiments show that StyleRF achieves superior 3D stylization quality with precise geometry reconstruction and it can generalize to various new styles in a zero-shot manner.