 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTianzhu Zhang
Image-to-Image Matching via Foundation Models: A New Perspective for Open-Vocabulary Semantic Segmentation
Mar 30, 2024
Open-vocabulary semantic segmentation (OVS) aims to segment images of arbitrary categories specified by class labels or captions. However, most previous best-performing methods, whether pixel grouping methods or region recognition methods, suffer from false matches between image features and category labels. We attribute this to the natural gap between the textual features and visual features. In this work, we rethink how to mitigate false matches from the perspective of image-to-image matching and propose a novel relation-aware intra-modal matching (RIM) framework for OVS based on visual foundation models. RIM achieves robust region classification by firstly constructing diverse image-modal reference features and then matching them with region features based on relation-aware ranking distribution. The proposed RIM enjoys several merits. First, the intra-modal reference features are better aligned, circumventing potential ambiguities that may arise in cross-modal matching. Second, the ranking-based matching process harnesses the structure information implicit in the inter-class relationships, making it more robust than comparing individually. Extensive experiments on three benchmarks demonstrate that RIM outperforms previous state-of-the-art methods by large margins, obtaining a lead of more than 10% in mIoU on PASCAL VOC benchmark.
Instance-Adaptive and Geometric-Aware Keypoint Learning for Category-Level 6D Object Pose Estimation
Mar 28, 2024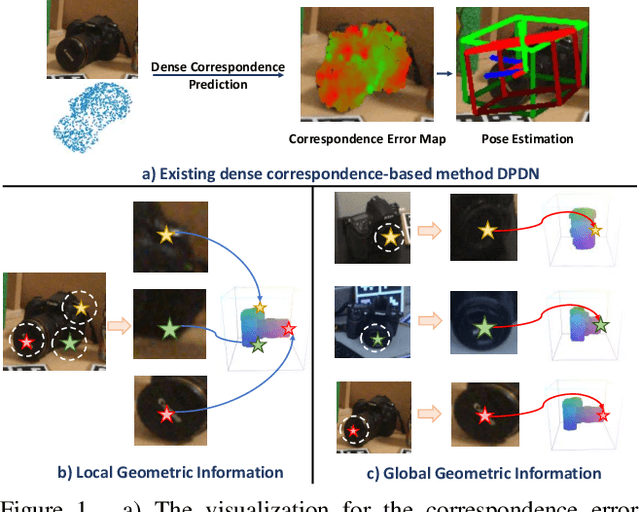
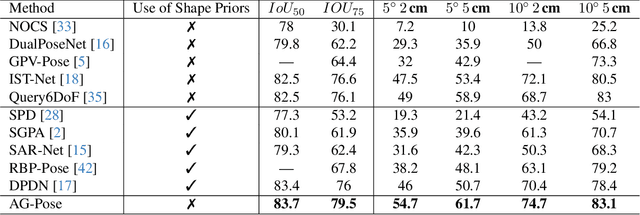
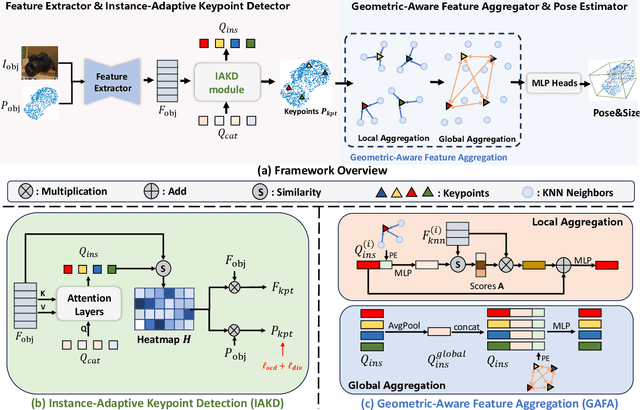
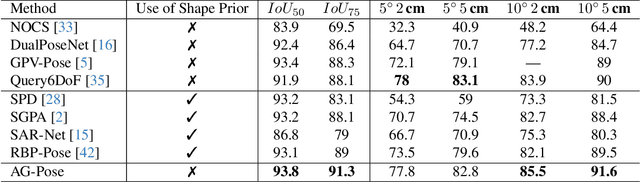
Category-level 6D object pose estimation aims to estimate the rotation, translation and size of unseen instances within specific categories. In this area, dense correspondence-based methods have achieved leading performance. However, they do not explicitly consider the local and global geometric information of different instances, resulting in poor generalization ability to unseen instances with significant shape variations. To deal with this problem, we propose a novel Instance-Adaptive and Geometric-Aware Keypoint Learning method for category-level 6D object pose estimation (AG-Pose), which includes two key designs: (1) The first design is an Instance-Adaptive Keypoint Detection module, which can adaptively detect a set of sparse keypoints for various instances to represent their geometric structures. (2) The second design is a Geometric-Aware Feature Aggregation module, which can efficiently integrate the local and global geometric information into keypoint features. These two modules can work together to establish robust keypoint-level correspondences for unseen instances, thus enhancing the generalization ability of the model.Experimental results on CAMERA25 and REAL275 datasets show that the proposed AG-Pose outperforms state-of-the-art methods by a large margin without category-specific shape priors.
Unsupervised Template-assisted Point Cloud Shape Correspondence Network
Mar 25, 2024Unsupervised point cloud shape correspondence aims to establish point-wise correspondences between source and target point clouds. Existing methods obtain correspondences directly by computing point-wise feature similarity between point clouds. However, non-rigid objects possess strong deformability and unusual shapes, making it a longstanding challenge to directly establish correspondences between point clouds with unconventional shapes. To address this challenge, we propose an unsupervised Template-Assisted point cloud shape correspondence Network, termed TANet, including a template generation module and a template assistance module. The proposed TANet enjoys several merits. Firstly, the template generation module establishes a set of learnable templates with explicit structures. Secondly, we introduce a template assistance module that extensively leverages the generated templates to establish more accurate shape correspondences from multiple perspectives. Extensive experiments on four human and animal datasets demonstrate that TANet achieves favorable performance against state-of-the-art methods.
BSNet: Box-Supervised Simulation-assisted Mean Teacher for 3D Instance Segmentation
Mar 22, 20243D instance segmentation (3DIS) is a crucial task, but point-level annotations are tedious in fully supervised settings. Thus, using bounding boxes (bboxes) as annotations has shown great potential. The current mainstream approach is a two-step process, involving the generation of pseudo-labels from box annotations and the training of a 3DIS network with the pseudo-labels. However, due to the presence of intersections among bboxes, not every point has a determined instance label, especially in overlapping areas. To generate higher quality pseudo-labels and achieve more precise weakly supervised 3DIS results, we propose the Box-Supervised Simulation-assisted Mean Teacher for 3D Instance Segmentation (BSNet), which devises a novel pseudo-labeler called Simulation-assisted Transformer. The labeler consists of two main components. The first is Simulation-assisted Mean Teacher, which introduces Mean Teacher for the first time in this task and constructs simulated samples to assist the labeler in acquiring prior knowledge about overlapping areas. To better model local-global structure, we also propose Local-Global Aware Attention as the decoder for teacher and student labelers. Extensive experiments conducted on the ScanNetV2 and S3DIS datasets verify the superiority of our designs. Code is available at \href{https://github.com/peoplelu/BSNet}{https://github.com/peoplelu/BSNet}.
Proxy-RLHF: Decoupling Generation and Alignment in Large Language Model with Proxy
Mar 07, 2024
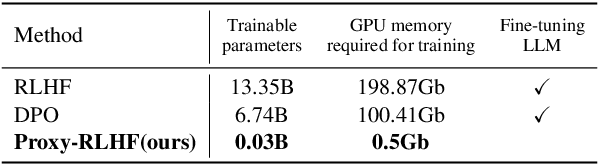
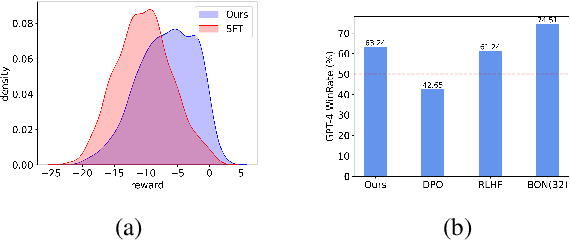
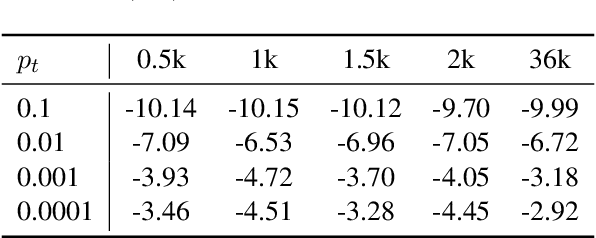
Reinforcement Learning from Human Feedback (RLHF) is the prevailing approach to ensure Large Language Models (LLMs) align with human values. However, existing RLHF methods require a high computational cost, one main reason being that RLHF assigns both the generation and alignment tasks to the LLM simultaneously. In this paper, we introduce Proxy-RLHF, which decouples the generation and alignment processes of LLMs, achieving alignment with human values at a much lower computational cost. We start with a novel Markov Decision Process (MDP) designed for the alignment process and employ Reinforcement Learning (RL) to train a streamlined proxy model that oversees the token generation of the LLM, without altering the LLM itself. Experiments show that our method achieves a comparable level of alignment with only 1\% of the training parameters of other methods.
Multi-modal Attribute Prompting for Vision-Language Models
Mar 01, 2024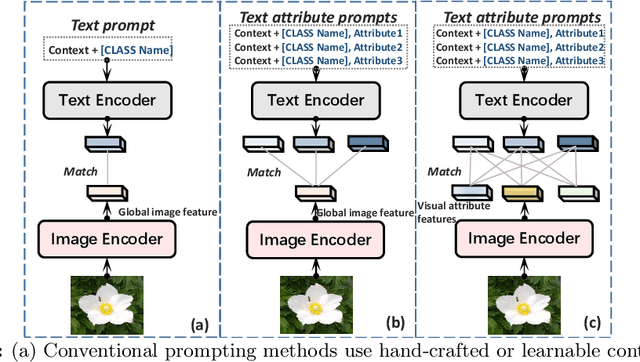
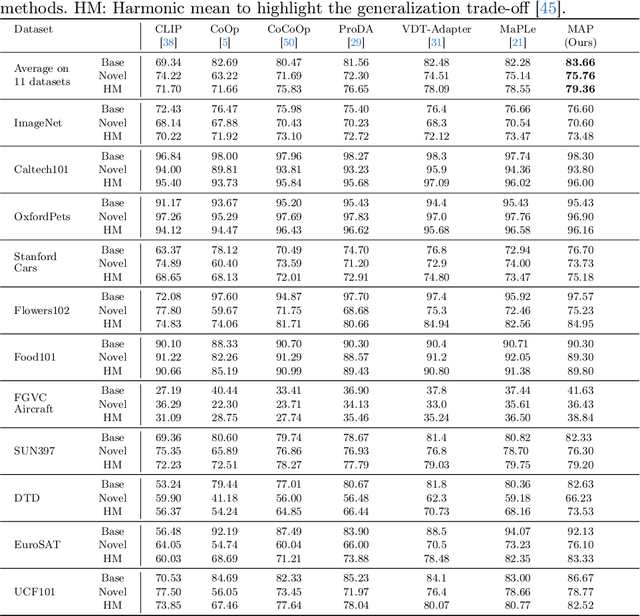

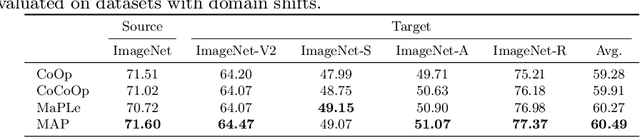
Large pre-trained Vision-Language Models (VLMs), like CLIP, exhibit strong generalization ability to downstream tasks but struggle in few-shot scenarios. Existing prompting techniques primarily focus on global text and image representations, yet overlooking multi-modal attribute characteristics. This limitation hinders the model's ability to perceive fine-grained visual details and restricts its generalization ability to a broader range of unseen classes. To address this issue, we propose a Multi-modal Attribute Prompting method (MAP) by jointly exploring textual attribute prompting, visual attribute prompting, and attribute-level alignment. The proposed MAP enjoys several merits. First, we introduce learnable visual attribute prompts enhanced by textual attribute semantics to adaptively capture visual attributes for images from unknown categories, boosting fine-grained visual perception capabilities for CLIP. Second, the proposed attribute-level alignment complements the global alignment to enhance the robustness of cross-modal alignment for open-vocabulary objects. To our knowledge, this is the first work to establish cross-modal attribute-level alignment for CLIP-based few-shot adaptation. Extensive experimental results on 11 datasets demonstrate that our method performs favorably against state-of-the-art approaches.
Joint Attention-Guided Feature Fusion Network for Saliency Detection of Surface Defects
Feb 05, 2024Surface defect inspection plays an important role in the process of industrial manufacture and production. Though Convolutional Neural Network (CNN) based defect inspection methods have made huge leaps, they still confront a lot of challenges such as defect scale variation, complex background, low contrast, and so on. To address these issues, we propose a joint attention-guided feature fusion network (JAFFNet) for saliency detection of surface defects based on the encoder-decoder network. JAFFNet mainly incorporates a joint attention-guided feature fusion (JAFF) module into decoding stages to adaptively fuse low-level and high-level features. The JAFF module learns to emphasize defect features and suppress background noise during feature fusion, which is beneficial for detecting low-contrast defects. In addition, JAFFNet introduces a dense receptive field (DRF) module following the encoder to capture features with rich context information, which helps detect defects of different scales. The JAFF module mainly utilizes a learned joint channel-spatial attention map provided by high-level semantic features to guide feature fusion. The attention map makes the model pay more attention to defect features. The DRF module utilizes a sequence of multi-receptive-field (MRF) units with each taking as inputs all the preceding MRF feature maps and the original input. The obtained DRF features capture rich context information with a large range of receptive fields. Extensive experiments conducted on SD-saliency-900, Magnetic tile, and DAGM 2007 indicate that our method achieves promising performance in comparison with other state-of-the-art methods. Meanwhile, our method reaches a real-time defect detection speed of 66 FPS.
Unifying Visual and Vision-Language Tracking via Contrastive Learning
Jan 20, 2024Single object tracking aims to locate the target object in a video sequence according to the state specified by different modal references, including the initial bounding box (BBOX), natural language (NL), or both (NL+BBOX). Due to the gap between different modalities, most existing trackers are designed for single or partial of these reference settings and overspecialize on the specific modality. Differently, we present a unified tracker called UVLTrack, which can simultaneously handle all three reference settings (BBOX, NL, NL+BBOX) with the same parameters. The proposed UVLTrack enjoys several merits. First, we design a modality-unified feature extractor for joint visual and language feature learning and propose a multi-modal contrastive loss to align the visual and language features into a unified semantic space. Second, a modality-adaptive box head is proposed, which makes full use of the target reference to mine ever-changing scenario features dynamically from video contexts and distinguish the target in a contrastive way, enabling robust performance in different reference settings. Extensive experimental results demonstrate that UVLTrack achieves promising performance on seven visual tracking datasets, three vision-language tracking datasets, and three visual grounding datasets. Codes and models will be open-sourced at https://github.com/OpenSpaceAI/UVLTrack.
Frequency Domain Modality-invariant Feature Learning for Visible-infrared Person Re-Identification
Jan 04, 2024Visible-infrared person re-identification (VI-ReID) is challenging due to the significant cross-modality discrepancies between visible and infrared images. While existing methods have focused on designing complex network architectures or using metric learning constraints to learn modality-invariant features, they often overlook which specific component of the image causes the modality discrepancy problem. In this paper, we first reveal that the difference in the amplitude component of visible and infrared images is the primary factor that causes the modality discrepancy and further propose a novel Frequency Domain modality-invariant feature learning framework (FDMNet) to reduce modality discrepancy from the frequency domain perspective. Our framework introduces two novel modules, namely the Instance-Adaptive Amplitude Filter (IAF) module and the Phrase-Preserving Normalization (PPNorm) module, to enhance the modality-invariant amplitude component and suppress the modality-specific component at both the image- and feature-levels. Extensive experimental results on two standard benchmarks, SYSU-MM01 and RegDB, demonstrate the superior performance of our FDMNet against state-of-the-art methods.
Not Every Side Is Equal: Localization Uncertainty Estimation for Semi-Supervised 3D Object Detection
Dec 16, 2023Semi-supervised 3D object detection from point cloud aims to train a detector with a small number of labeled data and a large number of unlabeled data. The core of existing methods lies in how to select high-quality pseudo-labels using the designed quality evaluation criterion. However, these methods treat each pseudo bounding box as a whole and assign equal importance to each side during training, which is detrimental to model performance due to many sides having poor localization quality. Besides, existing methods filter out a large number of low-quality pseudo-labels, which also contain some correct regression values that can help with model training. To address the above issues, we propose a side-aware framework for semi-supervised 3D object detection consisting of three key designs: a 3D bounding box parameterization method, an uncertainty estimation module, and a pseudo-label selection strategy. These modules work together to explicitly estimate the localization quality of each side and assign different levels of importance during the training phase. Extensive experiment results demonstrate that the proposed method can consistently outperform baseline models under different scenes and evaluation criteria. Moreover, our method achieves state-of-the-art performance on three datasets with different labeled ratios.