 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiao Lin
Instance-Adaptive and Geometric-Aware Keypoint Learning for Category-Level 6D Object Pose Estimation
Mar 28, 2024
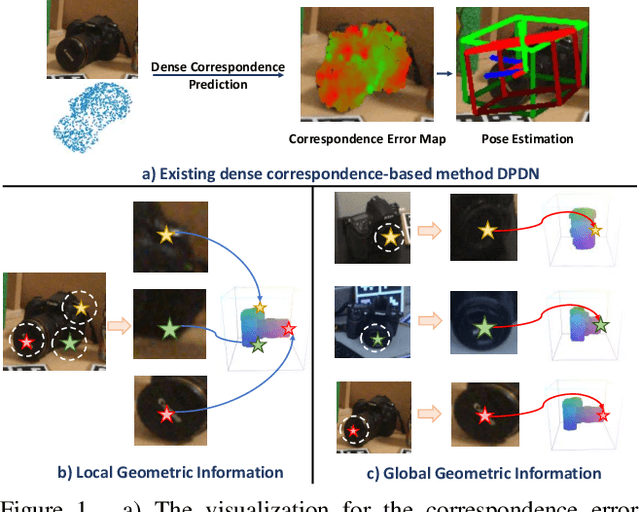
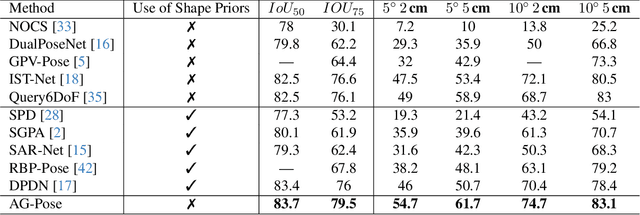
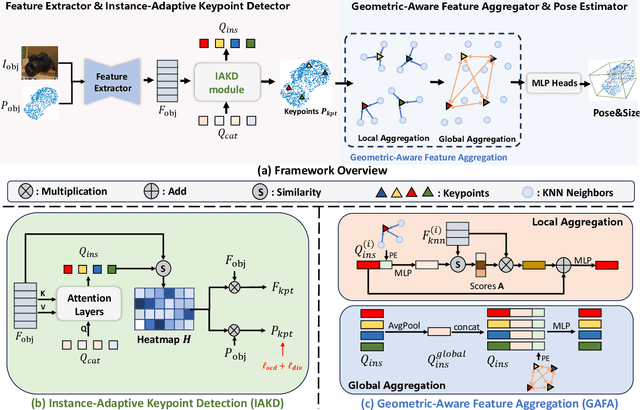
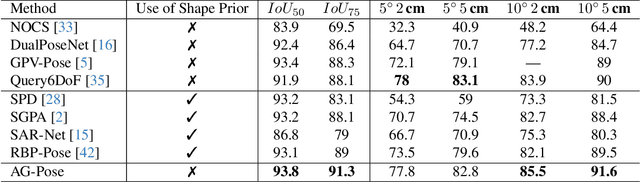
Category-level 6D object pose estimation aims to estimate the rotation, translation and size of unseen instances within specific categories. In this area, dense correspondence-based methods have achieved leading performance. However, they do not explicitly consider the local and global geometric information of different instances, resulting in poor generalization ability to unseen instances with significant shape variations. To deal with this problem, we propose a novel Instance-Adaptive and Geometric-Aware Keypoint Learning method for category-level 6D object pose estimation (AG-Pose), which includes two key designs: (1) The first design is an Instance-Adaptive Keypoint Detection module, which can adaptively detect a set of sparse keypoints for various instances to represent their geometric structures. (2) The second design is a Geometric-Aware Feature Aggregation module, which can efficiently integrate the local and global geometric information into keypoint features. These two modules can work together to establish robust keypoint-level correspondences for unseen instances, thus enhancing the generalization ability of the model.Experimental results on CAMERA25 and REAL275 datasets show that the proposed AG-Pose outperforms state-of-the-art methods by a large margin without category-specific shape priors.
Task-Agnostic Detector for Insertion-Based Backdoor Attacks
Mar 25, 2024Textual backdoor attacks pose significant security threats. Current detection approaches, typically relying on intermediate feature representation or reconstructing potential triggers, are task-specific and less effective beyond sentence classification, struggling with tasks like question answering and named entity recognition. We introduce TABDet (Task-Agnostic Backdoor Detector), a pioneering task-agnostic method for backdoor detection. TABDet leverages final layer logits combined with an efficient pooling technique, enabling unified logit representation across three prominent NLP tasks. TABDet can jointly learn from diverse task-specific models, demonstrating superior detection efficacy over traditional task-specific methods.
CLIPose: Category-Level Object Pose Estimation with Pre-trained Vision-Language Knowledge
Feb 24, 2024Most of existing category-level object pose estimation methods devote to learning the object category information from point cloud modality. However, the scale of 3D datasets is limited due to the high cost of 3D data collection and annotation. Consequently, the category features extracted from these limited point cloud samples may not be comprehensive. This motivates us to investigate whether we can draw on knowledge of other modalities to obtain category information. Inspired by this motivation, we propose CLIPose, a novel 6D pose framework that employs the pre-trained vision-language model to develop better learning of object category information, which can fully leverage abundant semantic knowledge in image and text modalities. To make the 3D encoder learn category-specific features more efficiently, we align representations of three modalities in feature space via multi-modal contrastive learning. In addition to exploiting the pre-trained knowledge of the CLIP's model, we also expect it to be more sensitive with pose parameters. Therefore, we introduce a prompt tuning approach to fine-tune image encoder while we incorporate rotations and translations information in the text descriptions. CLIPose achieves state-of-the-art performance on two mainstream benchmark datasets, REAL275 and CAMERA25, and runs in real-time during inference (40FPS).
Hybridnet for depth estimation and semantic segmentation
Feb 09, 2024Semantic segmentation and depth estimation are two important tasks in the area of image processing. Traditionally, these two tasks are addressed in an independent manner. However, for those applications where geometric and semantic information is required, such as robotics or autonomous navigation,depth or semantic segmentation alone are not sufficient. In this paper, depth estimation and semantic segmentation are addressed together from a single input image through a hybrid convolutional network. Different from the state of the art methods where features are extracted by a sole feature extraction network for both tasks, the proposed HybridNet improves the features extraction by separating the relevant features for one task from those which are relevant for both. Experimental results demonstrate that HybridNet results are comparable with the state of the art methods, as well as the single task methods that HybridNet is based on.
RHOBIN Challenge: Reconstruction of Human Object Interaction
Jan 07, 2024Modeling the interaction between humans and objects has been an emerging research direction in recent years. Capturing human-object interaction is however a very challenging task due to heavy occlusion and complex dynamics, which requires understanding not only 3D human pose, and object pose but also the interaction between them. Reconstruction of 3D humans and objects has been two separate research fields in computer vision for a long time. We hence proposed the first RHOBIN challenge: reconstruction of human-object interactions in conjunction with the RHOBIN workshop. It was aimed at bringing the research communities of human and object reconstruction as well as interaction modeling together to discuss techniques and exchange ideas. Our challenge consists of three tracks of 3D reconstruction from monocular RGB images with a focus on dealing with challenging interaction scenarios. Our challenge attracted more than 100 participants with more than 300 submissions, indicating the broad interest in the research communities. This paper describes the settings of our challenge and discusses the winning methods of each track in more detail. We observe that the human reconstruction task is becoming mature even under heavy occlusion settings while object pose estimation and joint reconstruction remain challenging tasks. With the growing interest in interaction modeling, we hope this report can provide useful insights and foster future research in this direction. Our workshop website can be found at \href{https://rhobin-challenge.github.io/}{https://rhobin-challenge.github.io/}.
Human Body Model based ID using Shape and Pose Parameters
Dec 06, 2023We present a Human Body model based IDentification system (HMID) system that is jointly trained for shape, pose and biometric identification. HMID is based on the Human Mesh Recovery (HMR) network and we propose additional losses to improve and stabilize shape estimation and biometric identification while maintaining the pose and shape output. We show that when our HMID network is trained using additional shape and pose losses, it shows a significant improvement in biometric identification performance when compared to an identical model that does not use such losses. The HMID model uses raw images instead of silhouettes and is able to perform robust recognition on images collected at range and altitude as many anthropometric properties are reasonably invariant to clothing, view and range. We show results on the USF dataset as well as the BRIAR dataset which includes probes with both clothing and view changes. Our approach (using body model losses) shows a significant improvement in Rank20 accuracy and True Accuracy Rate on the BRIAR evaluation dataset.
Performance Analysis of Integrated Data and Energy Transfer Assisted by Fluid Antenna Systems
Nov 13, 2023Fluid antenna multiple access (FAMA) is capable of exploiting the high spatial diversity of wireless channels to mitigate multi-user interference via flexible port switching, which achieves a better performance than traditional multi-input-multi-output (MIMO) systems. Moreover, integrated data and energy transfer (IDET) is able to provide both the wireless data transfer (WDT) and wireless energy transfer (WET) services towards low-power devices. In this paper, a FAMA assisted IDET system is studied, where $N$ access points (APs) provide dedicated IDET services towards $N$ user equipments (UEs). Each UE is equipped with a single fluid antenna. The performance of WDT and WET , \textit{i.e.}, the WDT outage probability, the WET outage probability, the reliable throughput and the average energy harvesting amount, are analysed theoretically by using time switching (TS) between WDT and WET. Numerical results validate our theoretical analysis, which reveals that the number of UEs and TS ratio should be optimized to achieve a trade-off between the WDT and WET performance. Moreover, FAMA assisted IDET achieves a better performance in terms of both WDT and WET than traditional MIMO with the same antenna size.
TransPose: 6D Object Pose Estimation with Geometry-Aware Transformer
Oct 25, 2023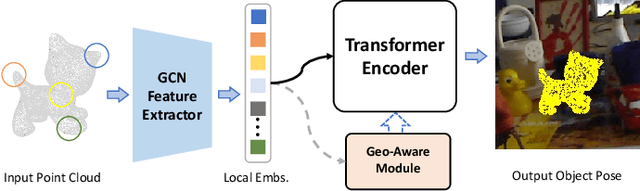
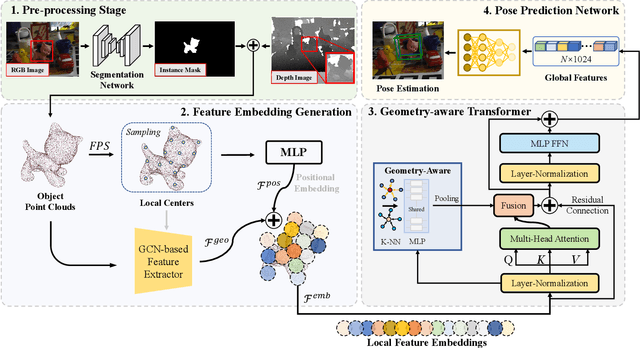
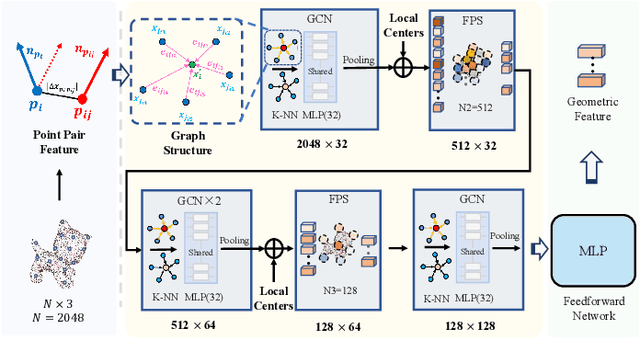
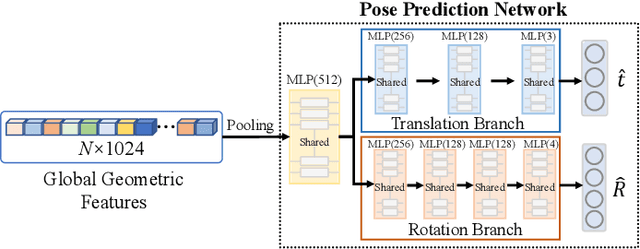
Estimating the 6D object pose is an essential task in many applications. Due to the lack of depth information, existing RGB-based methods are sensitive to occlusion and illumination changes. How to extract and utilize the geometry features in depth information is crucial to achieve accurate predictions. To this end, we propose TransPose, a novel 6D pose framework that exploits Transformer Encoder with geometry-aware module to develop better learning of point cloud feature representations. Specifically, we first uniformly sample point cloud and extract local geometry features with the designed local feature extractor base on graph convolution network. To improve robustness to occlusion, we adopt Transformer to perform the exchange of global information, making each local feature contains global information. Finally, we introduce geometry-aware module in Transformer Encoder, which to form an effective constrain for point cloud feature learning and makes the global information exchange more tightly coupled with point cloud tasks. Extensive experiments indicate the effectiveness of TransPose, our pose estimation pipeline achieves competitive results on three benchmark datasets.
SayNav: Grounding Large Language Models for Dynamic Planning to Navigation in New Environments
Sep 22, 2023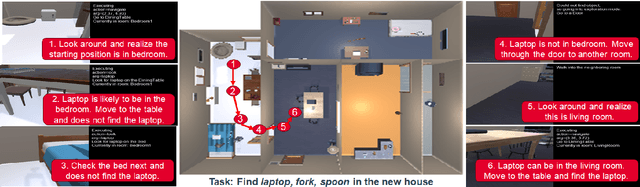
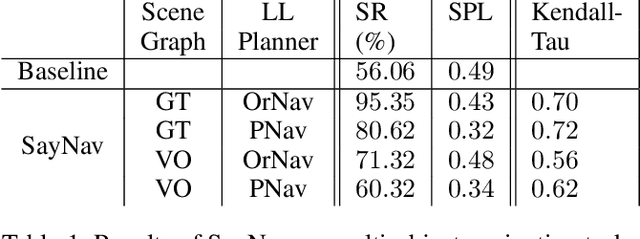
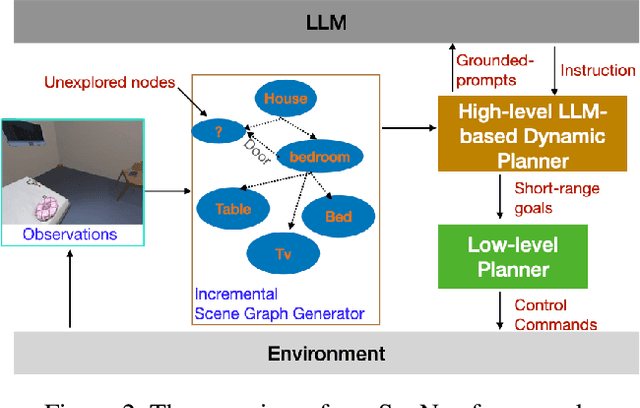
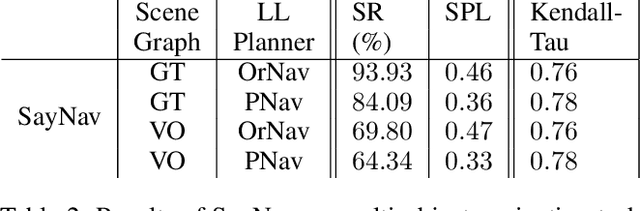
Semantic reasoning and dynamic planning capabilities are crucial for an autonomous agent to perform complex navigation tasks in unknown environments. It requires a large amount of common-sense knowledge, that humans possess, to succeed in these tasks. We present SayNav, a new approach that leverages human knowledge from Large Language Models (LLMs) for efficient generalization to complex navigation tasks in unknown large-scale environments. SayNav uses a novel grounding mechanism, that incrementally builds a 3D scene graph of the explored environment as inputs to LLMs, for generating feasible and contextually appropriate high-level plans for navigation. The LLM-generated plan is then executed by a pre-trained low-level planner, that treats each planned step as a short-distance point-goal navigation sub-task. SayNav dynamically generates step-by-step instructions during navigation and continuously refines future steps based on newly perceived information. We evaluate SayNav on a new multi-object navigation task, that requires the agent to utilize a massive amount of human knowledge to efficiently search multiple different objects in an unknown environment. SayNav outperforms an oracle based Point-nav baseline, achieving a success rate of 95.35% (vs 56.06% for the baseline), under the ideal settings on this task, highlighting its ability to generate dynamic plans for successfully locating objects in large-scale new environments. In addition, SayNav also enables efficient generalization of learning to navigate from simulation to real novel environments.
PyPose v0.6: The Imperative Programming Interface for Robotics
Sep 22, 2023
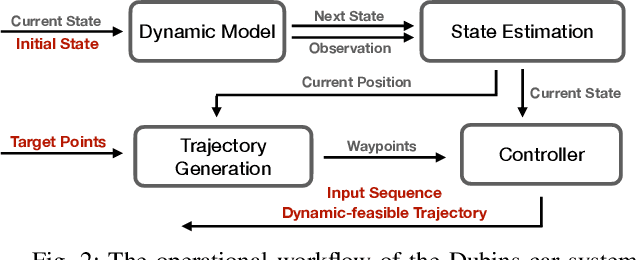
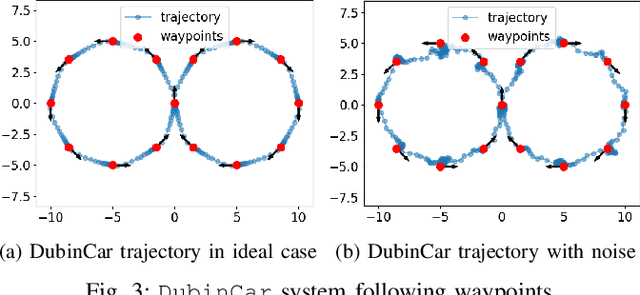
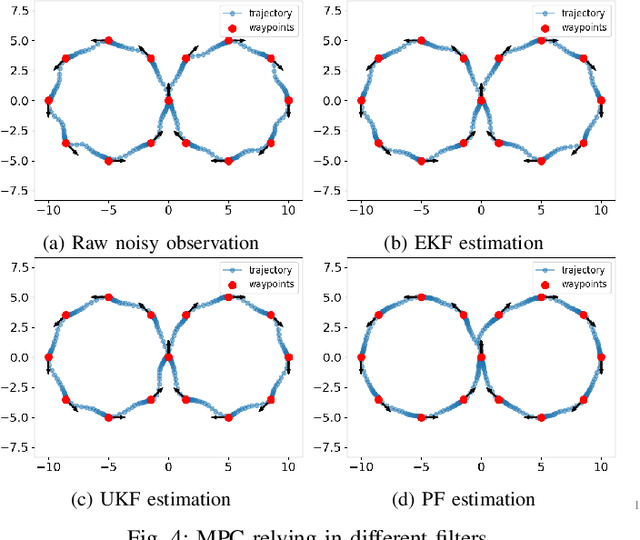
PyPose is an open-source library for robot learning. It combines a learning-based approach with physics-based optimization, which enables seamless end-to-end robot learning. It has been used in many tasks due to its meticulously designed application programming interface (API) and efficient implementation. From its initial launch in early 2022, PyPose has experienced significant enhancements, incorporating a wide variety of new features into its platform. To satisfy the growing demand for understanding and utilizing the library and reduce the learning curve of new users, we present the fundamental design principle of the imperative programming interface, and showcase the flexible usage of diverse functionalities and modules using an extremely simple Dubins car example. We also demonstrate that the PyPose can be easily used to navigate a real quadruped robot with a few lines of code.