 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKarthik Dantu
l-dyno: framework to learn consistent visual features using robot's motion
Oct 10, 2023
Historically, feature-based approaches have been used extensively for camera-based robot perception tasks such as localization, mapping, tracking, and others. Several of these approaches also combine other sensors (inertial sensing, for example) to perform combined state estimation. Our work rethinks this approach; we present a representation learning mechanism that identifies visual features that best correspond to robot motion as estimated by an external signal. Specifically, we utilize the robot's transformations through an external signal (inertial sensing, for example) and give attention to image space that is most consistent with the external signal. We use a pairwise consistency metric as a representation to keep the visual features consistent through a sequence with the robot's relative pose transformations. This approach enables us to incorporate information from the robot's perspective instead of solely relying on the image attributes. We evaluate our approach on real-world datasets such as KITTI & EuRoC and compare the refined features with existing feature descriptors. We also evaluate our method using our real robot experiment. We notice an average of 49% reduction in the image search space without compromising the trajectory estimation accuracy. Our method reduces the execution time of visual odometry by 4.3% and also reduces reprojection errors. We demonstrate the need to select only the most important features and show the competitiveness using various feature detection baselines.
PyPose v0.6: The Imperative Programming Interface for Robotics
Sep 22, 2023
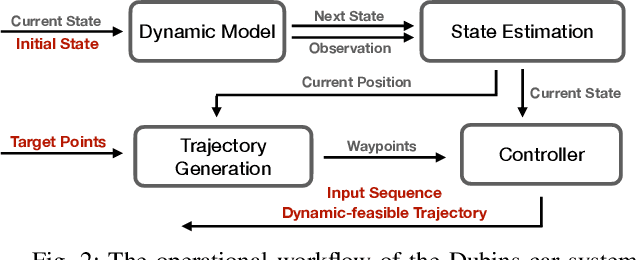
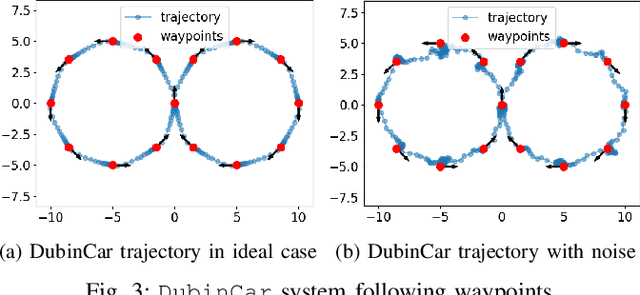
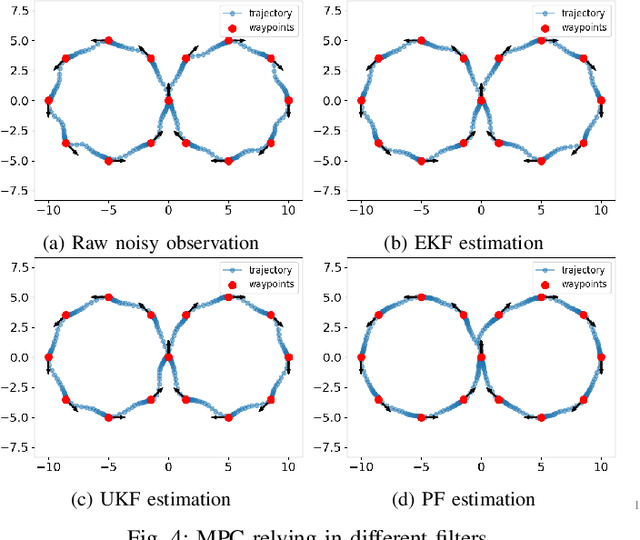
PyPose is an open-source library for robot learning. It combines a learning-based approach with physics-based optimization, which enables seamless end-to-end robot learning. It has been used in many tasks due to its meticulously designed application programming interface (API) and efficient implementation. From its initial launch in early 2022, PyPose has experienced significant enhancements, incorporating a wide variety of new features into its platform. To satisfy the growing demand for understanding and utilizing the library and reduce the learning curve of new users, we present the fundamental design principle of the imperative programming interface, and showcase the flexible usage of diverse functionalities and modules using an extremely simple Dubins car example. We also demonstrate that the PyPose can be easily used to navigate a real quadruped robot with a few lines of code.
DIOR: Dataset for Indoor-Outdoor Reidentification -- Long Range 3D/2D Skeleton Gait Collection Pipeline, Semi-Automated Gait Keypoint Labeling and Baseline Evaluation Methods
Sep 21, 2023
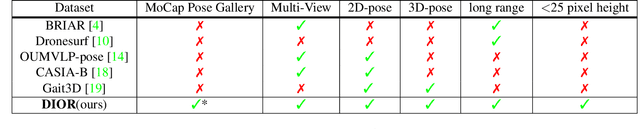
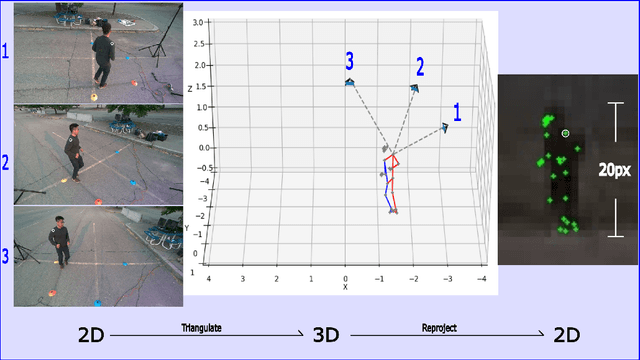

In recent times, there is an increased interest in the identification and re-identification of people at long distances, such as from rooftop cameras, UAV cameras, street cams, and others. Such recognition needs to go beyond face and use whole-body markers such as gait. However, datasets to train and test such recognition algorithms are not widely prevalent, and fewer are labeled. This paper introduces DIOR -- a framework for data collection, semi-automated annotation, and also provides a dataset with 14 subjects and 1.649 million RGB frames with 3D/2D skeleton gait labels, including 200 thousands frames from a long range camera. Our approach leverages advanced 3D computer vision techniques to attain pixel-level accuracy in indoor settings with motion capture systems. Additionally, for outdoor long-range settings, we remove the dependency on motion capture systems and adopt a low-cost, hybrid 3D computer vision and learning pipeline with only 4 low-cost RGB cameras, successfully achieving precise skeleton labeling on far-away subjects, even when their height is limited to a mere 20-25 pixels within an RGB frame. On publication, we will make our pipeline open for others to use.
Fast Decision Support for Air Traffic Management at Urban Air Mobility Vertiports using Graph Learning
Aug 17, 2023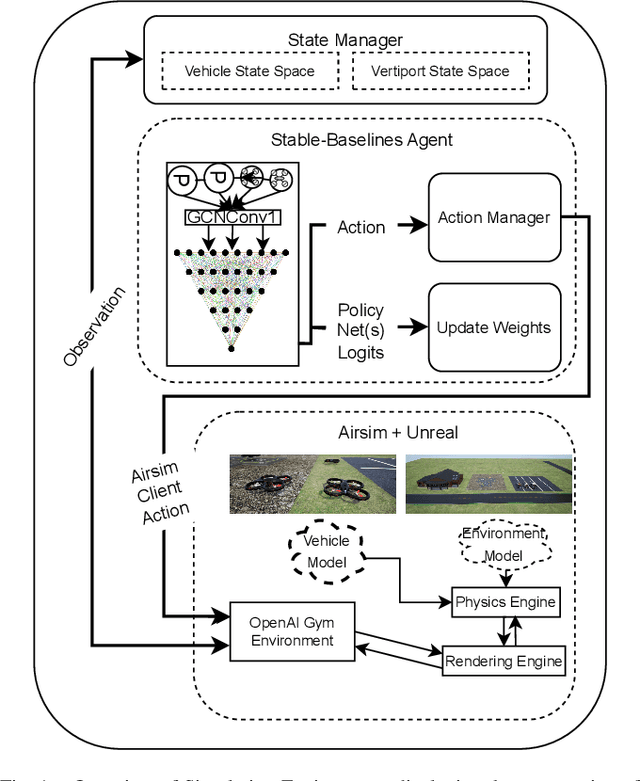
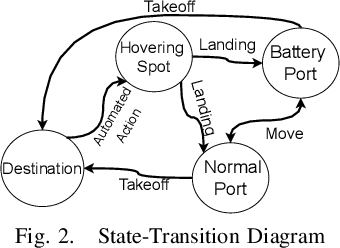

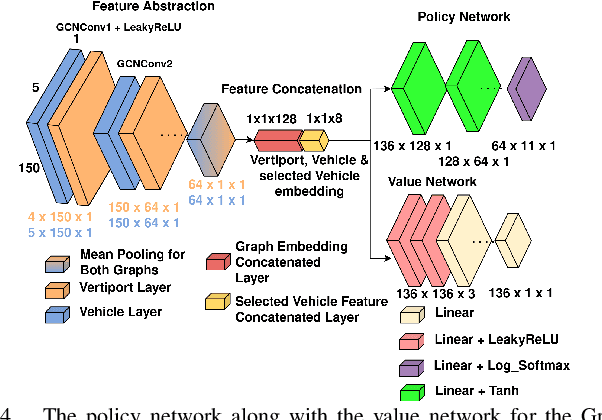
Urban Air Mobility (UAM) promises a new dimension to decongested, safe, and fast travel in urban and suburban hubs. These UAM aircraft are conceived to operate from small airports called vertiports each comprising multiple take-off/landing and battery-recharging spots. Since they might be situated in dense urban areas and need to handle many aircraft landings and take-offs each hour, managing this schedule in real-time becomes challenging for a traditional air-traffic controller but instead calls for an automated solution. This paper provides a novel approach to this problem of Urban Air Mobility - Vertiport Schedule Management (UAM-VSM), which leverages graph reinforcement learning to generate decision-support policies. Here the designated physical spots within the vertiport's airspace and the vehicles being managed are represented as two separate graphs, with feature extraction performed through a graph convolutional network (GCN). Extracted features are passed onto perceptron layers to decide actions such as continue to hover or cruise, continue idling or take-off, or land on an allocated vertiport spot. Performance is measured based on delays, safety (no. of collisions) and battery consumption. Through realistic simulations in AirSim applied to scaled down multi-rotor vehicles, our results demonstrate the suitability of using graph reinforcement learning to solve the UAM-VSM problem and its superiority to basic reinforcement learning (with graph embeddings) or random choice baselines.
PQM: A Point Quality Evaluation Metric for Dense Maps
Jun 06, 2023
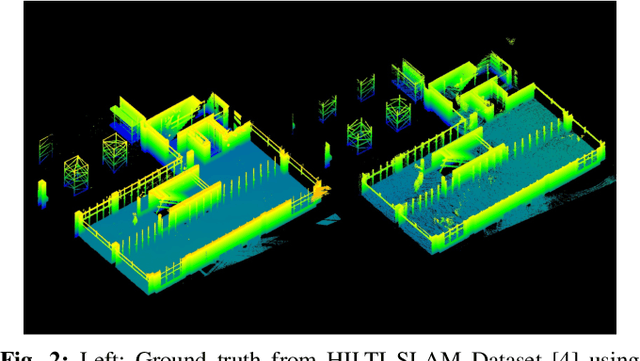
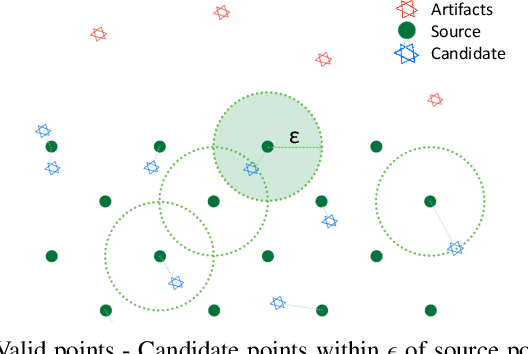

LiDAR-based mapping/reconstruction are important for various applications, but evaluating the quality of the dense maps they produce is challenging. The current methods have limitations, including the inability to capture completeness, structural information, and local variations in error. In this paper, we propose a novel point quality evaluation metric (PQM) that consists of four sub-metrics to provide a more comprehensive evaluation of point cloud quality. The completeness sub-metric evaluates the proportion of missing data, the artifact score sub-metric recognizes and characterizes artifacts, the accuracy sub-metric measures registration accuracy, and the resolution sub-metric quantifies point cloud density. Through an ablation study using a prototype dataset, we demonstrate the effectiveness of each of the sub-metrics and compare them to popular point cloud distance measures. Using three LiDAR SLAM systems to generate maps, we evaluate their output map quality and demonstrate the metrics robustness to noise and artifacts. Our implementation of PQM, datasets and detailed documentation on how to integrate with your custom dense mapping pipeline can be found at github.com/droneslab/pqm
You Only Crash Once: Improved Object Detection for Real-Time, Sim-to-Real Hazardous Terrain Detection and Classification for Autonomous Planetary Landings
Mar 08, 2023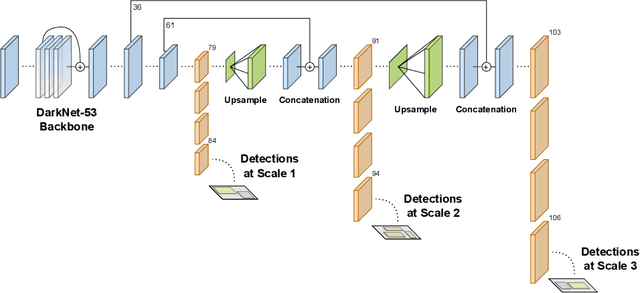
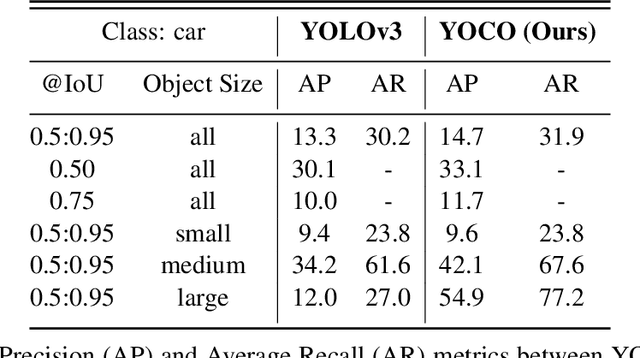


The detection of hazardous terrain during the planetary landing of spacecraft plays a critical role in assuring vehicle safety and mission success. A cheap and effective way of detecting hazardous terrain is through the use of visual cameras, which ensure operational ability from atmospheric entry through touchdown. Plagued by resource constraints and limited computational power, traditional techniques for visual hazardous terrain detection focus on template matching and registration to pre-built hazard maps. Although successful on previous missions, this approach is restricted to the specificity of the templates and limited by the fidelity of the underlying hazard map, which both require extensive pre-flight cost and effort to obtain and develop. Terrestrial systems that perform a similar task in applications such as autonomous driving utilize state-of-the-art deep learning techniques to successfully localize and classify navigation hazards. Advancements in spacecraft co-processors aimed at accelerating deep learning inference enable the application of these methods in space for the first time. In this work, we introduce You Only Crash Once (YOCO), a deep learning-based visual hazardous terrain detection and classification technique for autonomous spacecraft planetary landings. Through the use of unsupervised domain adaptation we tailor YOCO for training by simulation, removing the need for real-world annotated data and expensive mission surveying phases. We further improve the transfer of representative terrain knowledge between simulation and the real world through visual similarity clustering. We demonstrate the utility of YOCO through a series of terrestrial and extraterrestrial simulation-to-real experiments and show substantial improvements toward the ability to both detect and accurately classify instances of planetary terrain.
Design of an Adaptive Lightweight LiDAR to Decouple Robot-Camera Geometry
Feb 28, 2023
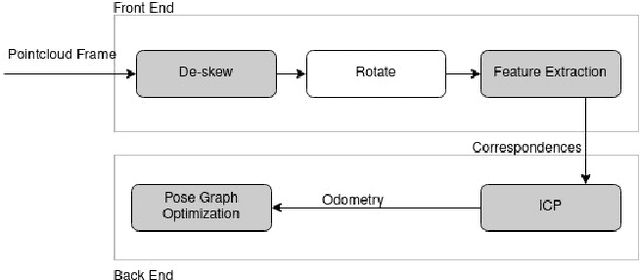
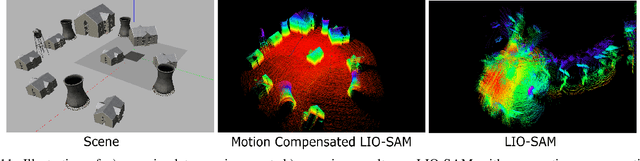
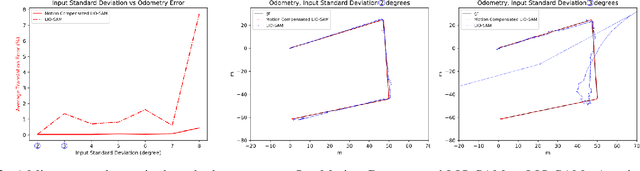
A fundamental challenge in robot perception is the coupling of the sensor pose and robot pose. This has led to research in active vision where robot pose is changed to reorient the sensor to areas of interest for perception. Further, egomotion such as jitter, and external effects such as wind and others affect perception requiring additional effort in software such as image stabilization. This effect is particularly pronounced in micro-air vehicles and micro-robots who typically are lighter and subject to larger jitter but do not have the computational capability to perform stabilization in real-time. We present a novel microelectromechanical (MEMS) mirror LiDAR system to change the field of view of the LiDAR independent of the robot motion. Our design has the potential for use on small, low-power systems where the expensive components of the LiDAR can be placed external to the small robot. We show the utility of our approach in simulation and on prototype hardware mounted on a UAV. We believe that this LiDAR and its compact movable scanning design provide mechanisms to decouple robot and sensor geometry allowing us to simplify robot perception. We also demonstrate examples of motion compensation using IMU and external odometry feedback in hardware.
PyPose: A Library for Robot Learning with Physics-based Optimization
Sep 30, 2022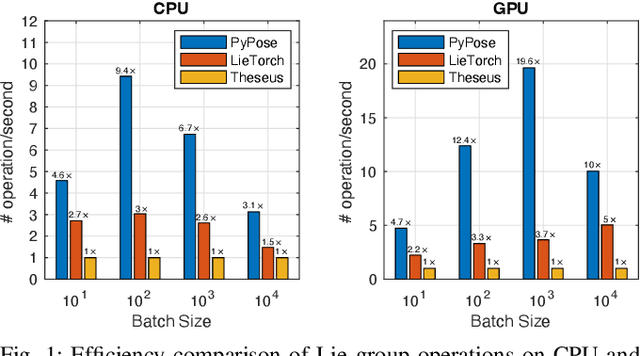

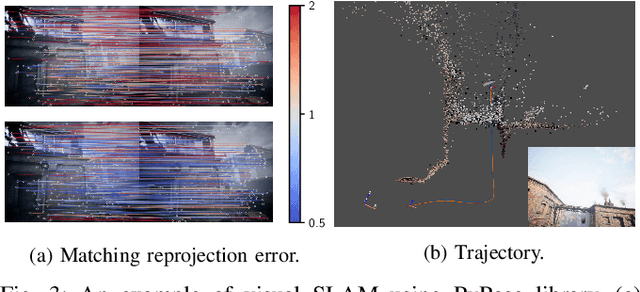
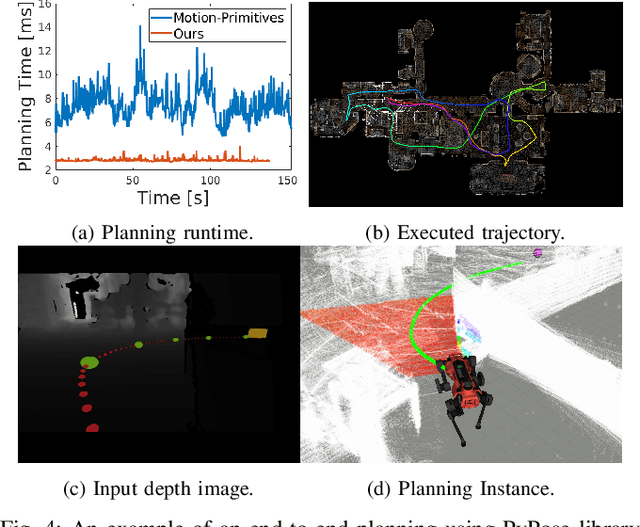
Deep learning has had remarkable success in robotic perception, but its data-centric nature suffers when it comes to generalizing to ever-changing environments. By contrast, physics-based optimization generalizes better, but it does not perform as well in complicated tasks due to the lack of high-level semantic information and the reliance on manual parametric tuning. To take advantage of these two complementary worlds, we present PyPose: a robotics-oriented, PyTorch-based library that combines deep perceptual models with physics-based optimization techniques. Our design goal for PyPose is to make it user-friendly, efficient, and interpretable with a tidy and well-organized architecture. Using an imperative style interface, it can be easily integrated into real-world robotic applications. Besides, it supports parallel computing of any order gradients of Lie groups and Lie algebras and $2^{\text{nd}}$-order optimizers, such as trust region methods. Experiments show that PyPose achieves 3-20$\times$ speedup in computation compared to state-of-the-art libraries. To boost future research, we provide concrete examples across several fields of robotics, including SLAM, inertial navigation, planning, and control.
Learning Robot Swarm Tactics over Complex Adversarial Environments
Sep 13, 2021
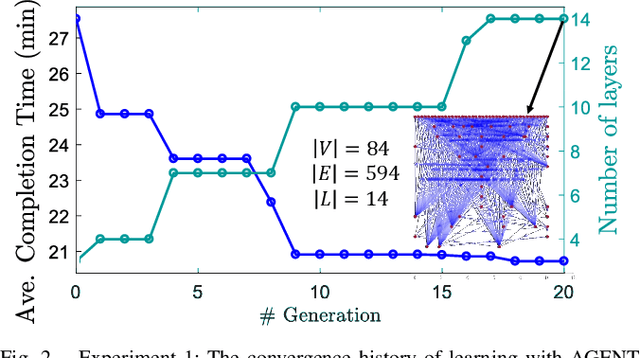

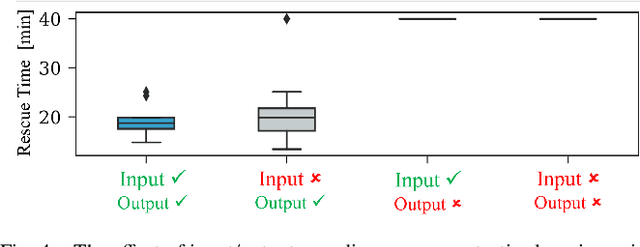
To accomplish complex swarm robotic missions in the real world, one needs to plan and execute a combination of single robot behaviors, group primitives such as task allocation, path planning, and formation control, and mission-specific objectives such as target search and group coverage. Most such missions are designed manually by teams of robotics experts. Recent work in automated approaches to learning swarm behavior has been limited to individual primitives with sparse work on learning complete missions. This paper presents a systematic approach to learn tactical mission-specific policies that compose primitives in a swarm to accomplish the mission efficiently using neural networks with special input and output encoding. To learn swarm tactics in an adversarial environment, we employ a combination of 1) map-to-graph abstraction, 2) input/output encoding via Pareto filtering of points of interest and clustering of robots, and 3) learning via neuroevolution and policy gradient approaches. We illustrate this combination as critical to providing tractable learning, especially given the computational cost of simulating swarm missions of this scale and complexity. Successful mission completion outcomes are demonstrated with up to 60 robots. In addition, a close match in the performance statistics in training and testing scenarios shows the potential generalizability of the proposed framework.
Scalable Coverage Path Planning of Multi-Robot Teams for Monitoring Non-Convex Areas
Mar 26, 2021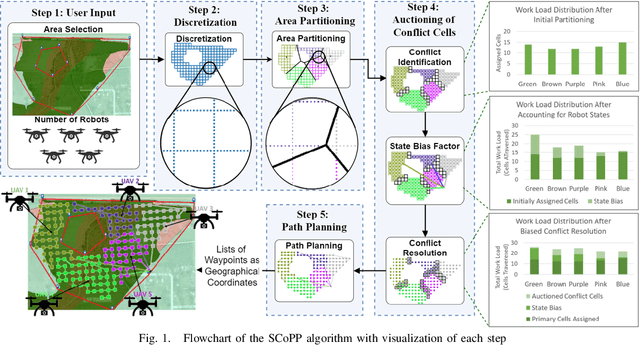
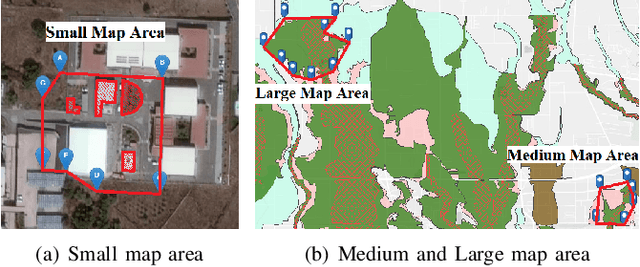
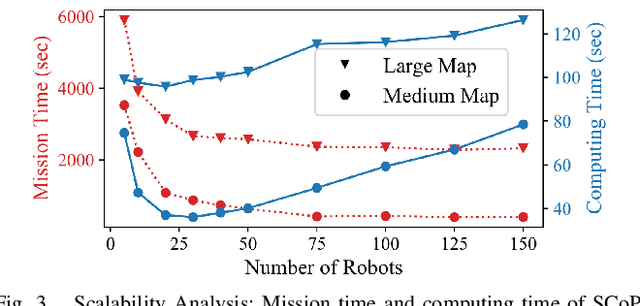
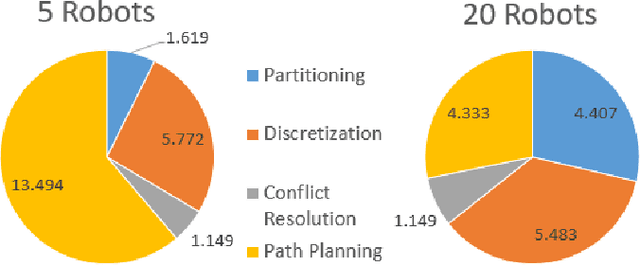
This paper presents a novel multi-robot coverage path planning (CPP) algorithm - aka SCoPP - that provides a time-efficient solution, with workload balanced plans for each robot in a multi-robot system, based on their initial states. This algorithm accounts for discontinuities (e.g., no-fly zones) in a specified area of interest, and provides an optimized ordered list of way-points per robot using a discrete, computationally efficient, nearest neighbor path planning algorithm. This algorithm involves five main stages, which include the transformation of the user's input as a set of vertices in geographical coordinates, discretization, load-balanced partitioning, auctioning of conflict cells in a discretized space, and a path planning procedure. To evaluate the effectiveness of the primary algorithm, a multi-unmanned aerial vehicle (UAV) post-flood assessment application is considered, and the performance of the algorithm is tested on three test maps of varying sizes. Additionally, our method is compared with a state-of-the-art method created by Guasella et al. Further analyses on scalability and computational time of SCoPP are conducted. The results show that SCoPP is superior in terms of mission completion time; its computing time is found to be under 2 mins for a large map covered by a 150-robot team, thereby demonstrating its computationally scalability.