 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLuca Carlone
Long-Term Human Trajectory Prediction using 3D Dynamic Scene Graphs
May 01, 2024
We present a novel approach for long-term human trajectory prediction, which is essential for long-horizon robot planning in human-populated environments. State-of-the-art human trajectory prediction methods are limited by their focus on collision avoidance and short-term planning, and their inability to model complex interactions of humans with the environment. In contrast, our approach overcomes these limitations by predicting sequences of human interactions with the environment and using this information to guide trajectory predictions over a horizon of up to 60s. We leverage Large Language Models (LLMs) to predict interactions with the environment by conditioning the LLM prediction on rich contextual information about the scene. This information is given as a 3D Dynamic Scene Graph that encodes the geometry, semantics, and traversability of the environment into a hierarchical representation. We then ground these interaction sequences into multi-modal spatio-temporal distributions over human positions using a probabilistic approach based on continuous-time Markov Chains. To evaluate our approach, we introduce a new semi-synthetic dataset of long-term human trajectories in complex indoor environments, which also includes annotations of human-object interactions. We show in thorough experimental evaluations that our approach achieves a 54% lower average negative log-likelihood (NLL) and a 26.5% lower Best-of-20 displacement error compared to the best non-privileged baselines for a time horizon of 60s.
Clio: Real-time Task-Driven Open-Set 3D Scene Graphs
Apr 29, 2024Modern tools for class-agnostic image segmentation (e.g., SegmentAnything) and open-set semantic understanding (e.g., CLIP) provide unprecedented opportunities for robot perception and mapping. While traditional closed-set metric-semantic maps were restricted to tens or hundreds of semantic classes, we can now build maps with a plethora of objects and countless semantic variations. This leaves us with a fundamental question: what is the right granularity for the objects (and, more generally, for the semantic concepts) the robot has to include in its map representation? While related work implicitly chooses a level of granularity by tuning thresholds for object detection, we argue that such a choice is intrinsically task-dependent. The first contribution of this paper is to propose a task-driven 3D scene understanding problem, where the robot is given a list of tasks in natural language and has to select the granularity and the subset of objects and scene structure to retain in its map that is sufficient to complete the tasks. We show that this problem can be naturally formulated using the Information Bottleneck (IB), an established information-theoretic framework. The second contribution is an algorithm for task-driven 3D scene understanding based on an Agglomerative IB approach, that is able to cluster 3D primitives in the environment into task-relevant objects and regions and executes incrementally. The third contribution is to integrate our task-driven clustering algorithm into a real-time pipeline, named Clio, that constructs a hierarchical 3D scene graph of the environment online using only onboard compute, as the robot explores it. Our final contribution is an extensive experimental campaign showing that Clio not only allows real-time construction of compact open-set 3D scene graphs, but also improves the accuracy of task execution by limiting the map to relevant semantic concepts.
Task and Motion Planning in Hierarchical 3D Scene Graphs
Mar 12, 2024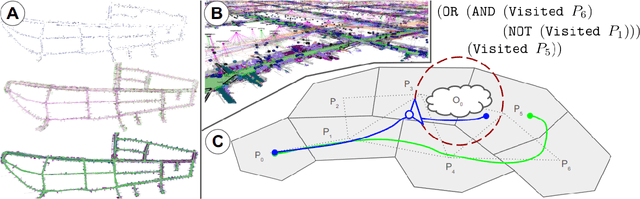
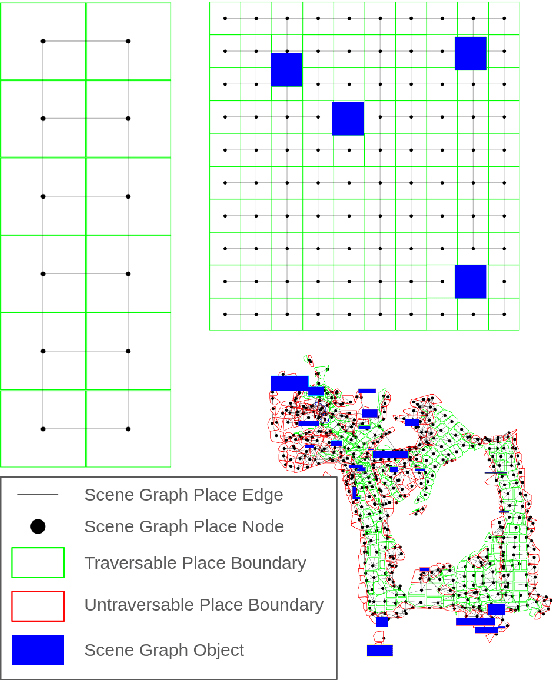
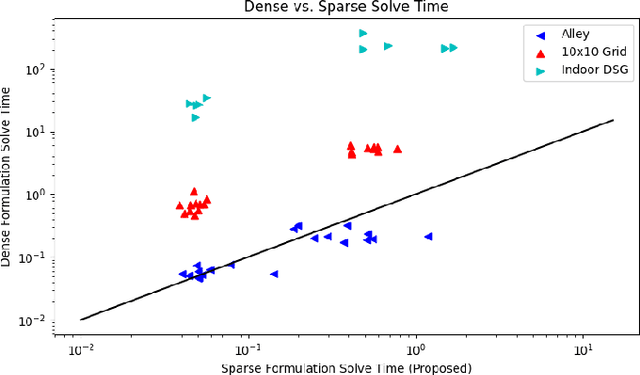
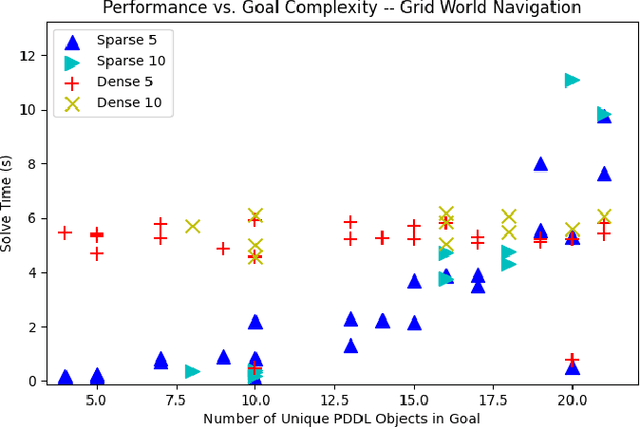
Recent work in the construction of 3D scene graphs has enabled mobile robots to build large-scale hybrid metric-semantic hierarchical representations of the world. These detailed models contain information that is useful for planning, however how to derive a planning domain from a 3D scene graph that enables efficient computation of executable plans is an open question. In this work, we present a novel approach for defining and solving Task and Motion Planning problems in large-scale environments using hierarchical 3D scene graphs. We identify a method for building sparse problem domains which enable scaling to large scenes, and propose a technique for incrementally adding objects to that domain during planning time to avoid wasting computation on irrelevant elements of the scene graph. We test our approach in two hand crafted domains as well as two scene graphs built from perception, including one constructed from the KITTI dataset. A video supplement is available at https://youtu.be/63xuCCaN0I4.
GMKF: Generalized Moment Kalman Filter for Polynomial Systems with Arbitrary Noise
Mar 08, 2024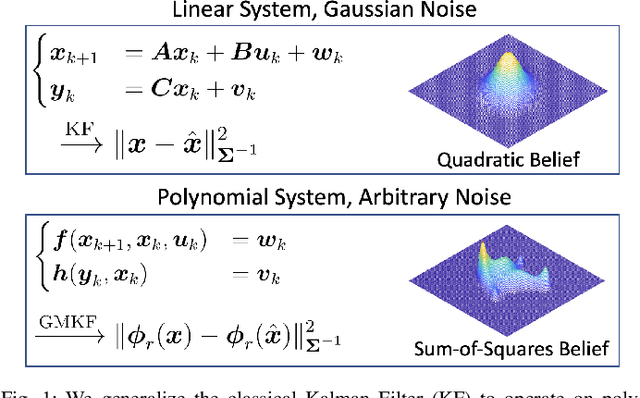

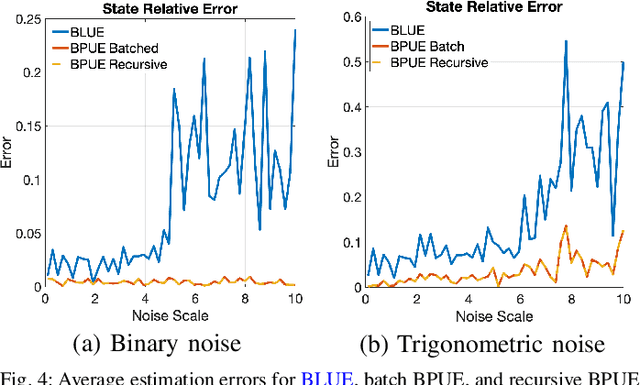
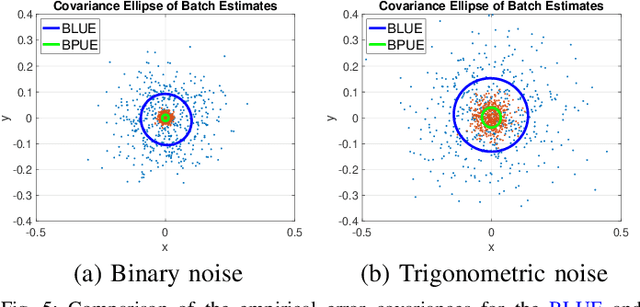
This paper develops a new filtering approach for state estimation in polynomial systems corrupted by arbitrary noise, which commonly arise in robotics. We first consider a batch setup where we perform state estimation using all data collected from the initial to the current time. We formulate the batch state estimation problem as a Polynomial Optimization Problem (POP) and relax the assumption of Gaussian noise by specifying a finite number of moments of the noise. We solve the resulting POP using a moment relaxation and prove that under suitable conditions on the rank of the relaxation, (i) we can extract a provably optimal estimate from the moment relaxation, and (ii) we can obtain a belief representation from the dual (sum-of-squares) relaxation. We then turn our attention to the filtering setup and apply similar insights to develop a GMKF for recursive state estimation in polynomial systems with arbitrary noise. The GMKF formulates the prediction and update steps as POPs and solves them using moment relaxations, carrying over a possibly non-Gaussian belief. In the linear-Gaussian case, GMKF reduces to the standard Kalman Filter. We demonstrate that GMKF performs well under highly non-Gaussian noise and outperforms common alternatives, including the Extended and Unscented Kalman Filter, and their variants on matrix Lie group.
Khronos: A Unified Approach for Spatio-Temporal Metric-Semantic SLAM in Dynamic Environments
Feb 21, 2024Perceiving and understanding highly dynamic and changing environments is a crucial capability for robot autonomy. While large strides have been made towards developing dynamic SLAM approaches that estimate the robot pose accurately, a lesser emphasis has been put on the construction of dense spatio-temporal representations of the robot environment. A detailed understanding of the scene and its evolution through time is crucial for long-term robot autonomy and essential to tasks that require long-term reasoning, such as operating effectively in environments shared with humans and other agents and thus are subject to short and long-term dynamics. To address this challenge, this work defines the Spatio-temporal Metric-semantic SLAM (SMS) problem, and presents a framework to factorize and solve it efficiently. We show that the proposed factorization suggests a natural organization of a spatio-temporal perception system, where a fast process tracks short-term dynamics in an active temporal window, while a slower process reasons over long-term changes in the environment using a factor graph formulation. We provide an efficient implementation of the proposed spatio-temporal perception approach, that we call Khronos, and show that it unifies exiting interpretations of short-term and long-term dynamics and is able to construct a dense spatio-temporal map in real-time. We provide simulated and real results, showing that the spatio-temporal maps built by Khronos are an accurate reflection of a 3D scene over time and that Khronos outperforms baselines across multiple metrics. We further validate our approach on two heterogeneous robots in challenging, large-scale real-world environments.
Multi-Model 3D Registration: Finding Multiple Moving Objects in Cluttered Point Clouds
Feb 16, 2024We investigate a variation of the 3D registration problem, named multi-model 3D registration. In the multi-model registration problem, we are given two point clouds picturing a set of objects at different poses (and possibly including points belonging to the background) and we want to simultaneously reconstruct how all objects moved between the two point clouds. This setup generalizes standard 3D registration where one wants to reconstruct a single pose, e.g., the motion of the sensor picturing a static scene. Moreover, it provides a mathematically grounded formulation for relevant robotics applications, e.g., where a depth sensor onboard a robot perceives a dynamic scene and has the goal of estimating its own motion (from the static portion of the scene) while simultaneously recovering the motion of all dynamic objects. We assume a correspondence-based setup where we have putative matches between the two point clouds and consider the practical case where these correspondences are plagued with outliers. We then propose a simple approach based on Expectation-Maximization (EM) and establish theoretical conditions under which the EM approach converges to the ground truth. We evaluate the approach in simulated and real datasets ranging from table-top scenes to self-driving scenarios and demonstrate its effectiveness when combined with state-of-the-art scene flow methods to establish dense correspondences.
Kimera2: Robust and Accurate Metric-Semantic SLAM in the Real World
Jan 12, 2024We present improvements to Kimera, an open-source metric-semantic visual-inertial SLAM library. In particular, we enhance Kimera-VIO, the visual-inertial odometry pipeline powering Kimera, to support better feature tracking, more efficient keyframe selection, and various input modalities (eg monocular, stereo, and RGB-D images, as well as wheel odometry). Additionally, Kimera-RPGO and Kimera-PGMO, Kimera's pose-graph optimization backends, are updated to support modern outlier rejection methods - specifically, Graduated-Non-Convexity - for improved robustness to spurious loop closures. These new features are evaluated extensively on a variety of simulated and real robotic platforms, including drones, quadrupeds, wheeled robots, and simulated self-driving cars. We present comparisons against several state-of-the-art visual-inertial SLAM pipelines and discuss strengths and weaknesses of the new release of Kimera. The newly added features have been released open-source at https://github.com/MIT-SPARK/Kimera.
Indoor and Outdoor 3D Scene Graph Generation via Language-Enabled Spatial Ontologies
Dec 18, 2023This paper proposes an approach to build 3D scene graphs in arbitrary (indoor and outdoor) environments. Such extension is challenging; the hierarchy of concepts that describe an outdoor environment is more complex than for indoors, and manually defining such hierarchy is time-consuming and does not scale. Furthermore, the lack of training data prevents the straightforward application of learning-based tools used in indoor settings. To address these challenges, we propose two novel extensions. First, we develop methods to build a spatial ontology defining concepts and relations relevant for indoor and outdoor robot operation. In particular, we use a Large Language Model (LLM) to build such an ontology, thus largely reducing the amount of manual effort required. Second, we leverage the spatial ontology for 3D scene graph construction using Logic Tensor Networks (LTN) to add logical rules, or axioms (e.g., "a beach contains sand"), which provide additional supervisory signals at training time thus reducing the need for labelled data, providing better predictions, and even allowing predicting concepts unseen at training time. We test our approach in a variety of datasets, including indoor, rural, and coastal environments, and show that it leads to a significant increase in the quality of the 3D scene graph generation with sparsely annotated data.
PyPose v0.6: The Imperative Programming Interface for Robotics
Sep 22, 2023
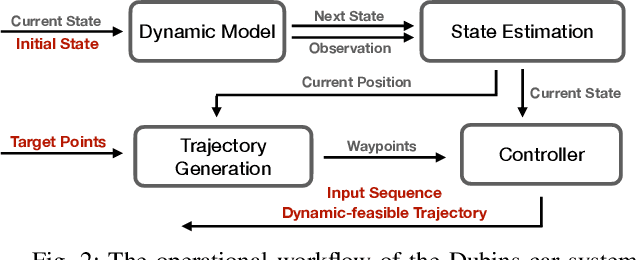
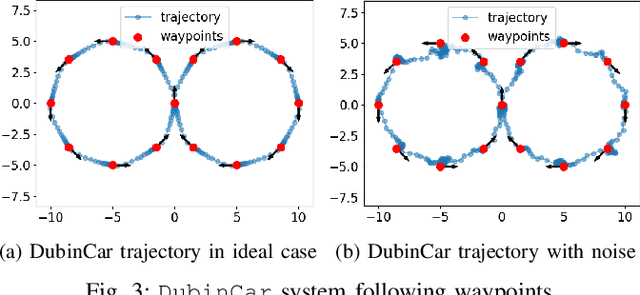
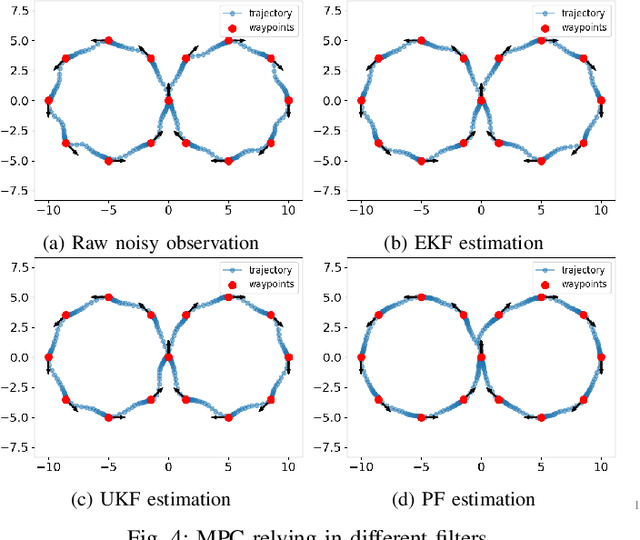
PyPose is an open-source library for robot learning. It combines a learning-based approach with physics-based optimization, which enables seamless end-to-end robot learning. It has been used in many tasks due to its meticulously designed application programming interface (API) and efficient implementation. From its initial launch in early 2022, PyPose has experienced significant enhancements, incorporating a wide variety of new features into its platform. To satisfy the growing demand for understanding and utilizing the library and reduce the learning curve of new users, we present the fundamental design principle of the imperative programming interface, and showcase the flexible usage of diverse functionalities and modules using an extremely simple Dubins car example. We also demonstrate that the PyPose can be easily used to navigate a real quadruped robot with a few lines of code.
Aggressive Aerial Grasping using a Soft Drone with Onboard Perception
Aug 11, 2023
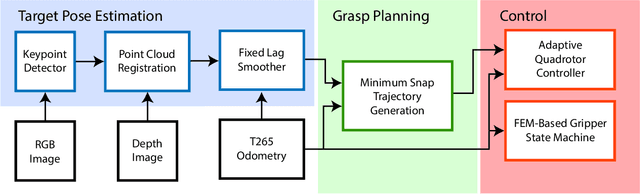
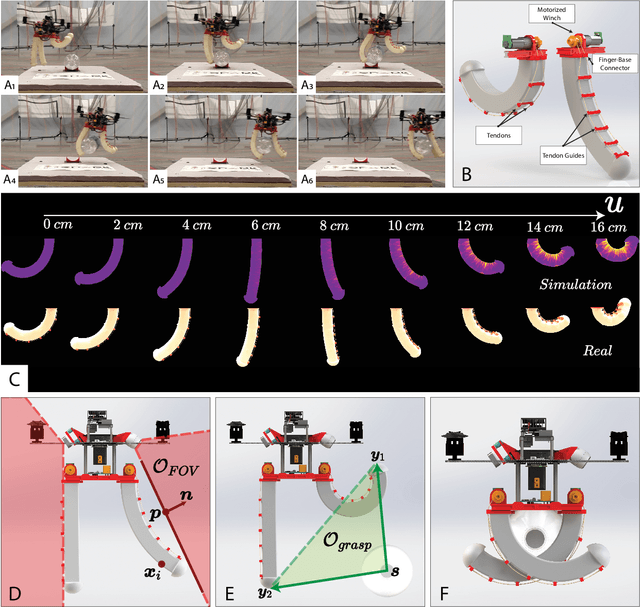
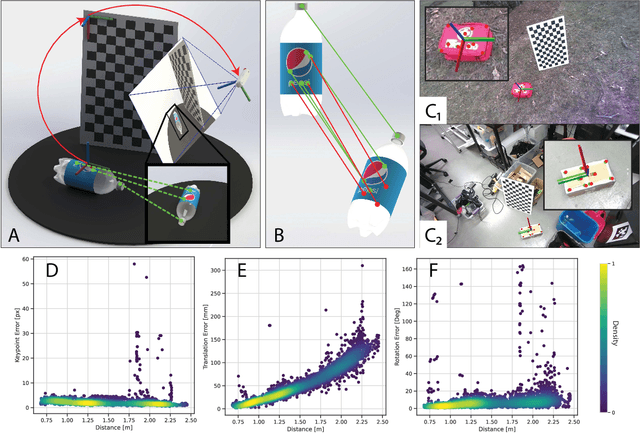
Contrary to the stunning feats observed in birds of prey, aerial manipulation and grasping with flying robots still lack versatility and agility. Conventional approaches using rigid manipulators require precise positioning and are subject to large reaction forces at grasp, which limit performance at high speeds. The few reported examples of aggressive aerial grasping rely on motion capture systems, or fail to generalize across environments and grasp targets. We describe the first example of a soft aerial manipulator equipped with a fully onboard perception pipeline, capable of robustly localizing and grasping visually and morphologically varied objects. The proposed system features a novel passively closing tendon-actuated soft gripper that enables fast closure at grasp, while compensating for position errors, complying to the target-object morphology, and dampening reaction forces. The system includes an onboard perception pipeline that combines a neural-network-based semantic keypoint detector with a state-of-the-art robust 3D object pose estimator, whose estimate is further refined using a fixed-lag smoother. The resulting pose estimate is passed to a minimum-snap trajectory planner, tracked by an adaptive controller that fully compensates for the added mass of the grasped object. Finally, a finite-element-based controller determines optimal gripper configurations for grasping. Rigorous experiments confirm that our approach enables dynamic, aggressive, and versatile grasping. We demonstrate fully onboard vision-based grasps of a variety of objects, in both indoor and outdoor environments, and up to speeds of 2.0 m/s -- the fastest vision-based grasp reported in the literature. Finally, we take a major step in expanding the utility of our platform beyond stationary targets, by demonstrating motion-capture-based grasps of targets moving up to 0.3 m/s, with relative speeds up to 1.5 m/s.