 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWilliam Chen
Vision-Language Models Provide Promptable Representations for Reinforcement Learning
Feb 13, 2024
Humans can quickly learn new behaviors by leveraging background world knowledge. In contrast, agents trained with reinforcement learning (RL) typically learn behaviors from scratch. We thus propose a novel approach that uses the vast amounts of general and indexable world knowledge encoded in vision-language models (VLMs) pre-trained on Internet-scale data for embodied RL. We initialize policies with VLMs by using them as promptable representations: embeddings that are grounded in visual observations and encode semantic features based on the VLM's internal knowledge, as elicited through prompts that provide task context and auxiliary information. We evaluate our approach on visually-complex, long horizon RL tasks in Minecraft and robot navigation in Habitat. We find that our policies trained on embeddings extracted from general-purpose VLMs outperform equivalent policies trained on generic, non-promptable image embeddings. We also find our approach outperforms instruction-following methods and performs comparably to domain-specific embeddings.
OWSM v3.1: Better and Faster Open Whisper-Style Speech Models based on E-Branchformer
Jan 30, 2024Recent studies have advocated for fully open foundation models to promote transparency and open science. As an initial step, the Open Whisper-style Speech Model (OWSM) reproduced OpenAI's Whisper using publicly available data and open-source toolkits. With the aim of reproducing Whisper, the previous OWSM v1 through v3 models were still based on Transformer, which might lead to inferior performance compared to other state-of-the-art speech encoders. In this work, we aim to improve the performance and efficiency of OWSM without extra training data. We present E-Branchformer based OWSM v3.1 models at two scales, i.e., 100M and 1B. The 1B model is the largest E-Branchformer based speech model that has been made publicly available. It outperforms the previous OWSM v3 in a vast majority of evaluation benchmarks, while demonstrating up to 25% faster inference speed. We publicly release the data preparation scripts, pre-trained models and training logs.
AugSumm: towards generalizable speech summarization using synthetic labels from large language model
Jan 10, 2024Abstractive speech summarization (SSUM) aims to generate human-like summaries from speech. Given variations in information captured and phrasing, recordings can be summarized in multiple ways. Therefore, it is more reasonable to consider a probabilistic distribution of all potential summaries rather than a single summary. However, conventional SSUM models are mostly trained and evaluated with a single ground-truth (GT) human-annotated deterministic summary for every recording. Generating multiple human references would be ideal to better represent the distribution statistically, but is impractical because annotation is expensive. We tackle this challenge by proposing AugSumm, a method to leverage large language models (LLMs) as a proxy for human annotators to generate augmented summaries for training and evaluation. First, we explore prompting strategies to generate synthetic summaries from ChatGPT. We validate the quality of synthetic summaries using multiple metrics including human evaluation, where we find that summaries generated using AugSumm are perceived as more valid to humans. Second, we develop methods to utilize synthetic summaries in training and evaluation. Experiments on How2 demonstrate that pre-training on synthetic summaries and fine-tuning on GT summaries improves ROUGE-L by 1 point on both GT and AugSumm-based test sets. AugSumm summaries are available at https://github.com/Jungjee/AugSumm.
Indoor and Outdoor 3D Scene Graph Generation via Language-Enabled Spatial Ontologies
Dec 18, 2023This paper proposes an approach to build 3D scene graphs in arbitrary (indoor and outdoor) environments. Such extension is challenging; the hierarchy of concepts that describe an outdoor environment is more complex than for indoors, and manually defining such hierarchy is time-consuming and does not scale. Furthermore, the lack of training data prevents the straightforward application of learning-based tools used in indoor settings. To address these challenges, we propose two novel extensions. First, we develop methods to build a spatial ontology defining concepts and relations relevant for indoor and outdoor robot operation. In particular, we use a Large Language Model (LLM) to build such an ontology, thus largely reducing the amount of manual effort required. Second, we leverage the spatial ontology for 3D scene graph construction using Logic Tensor Networks (LTN) to add logical rules, or axioms (e.g., "a beach contains sand"), which provide additional supervisory signals at training time thus reducing the need for labelled data, providing better predictions, and even allowing predicting concepts unseen at training time. We test our approach in a variety of datasets, including indoor, rural, and coastal environments, and show that it leads to a significant increase in the quality of the 3D scene graph generation with sparsely annotated data.
Findings of the 2023 ML-SUPERB Challenge: Pre-Training and Evaluation over More Languages and Beyond
Oct 09, 2023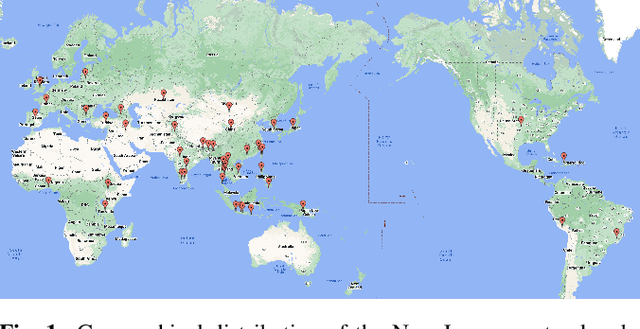


The 2023 Multilingual Speech Universal Performance Benchmark (ML-SUPERB) Challenge expands upon the acclaimed SUPERB framework, emphasizing self-supervised models in multilingual speech recognition and language identification. The challenge comprises a research track focused on applying ML-SUPERB to specific multilingual subjects, a Challenge Track for model submissions, and a New Language Track where language resource researchers can contribute and evaluate their low-resource language data in the context of the latest progress in multilingual speech recognition. The challenge garnered 12 model submissions and 54 language corpora, resulting in a comprehensive benchmark encompassing 154 languages. The findings indicate that merely scaling models is not the definitive solution for multilingual speech tasks, and a variety of speech/voice types present significant challenges in multilingual speech processing.
Evaluating Self-Supervised Speech Representations for Indigenous American Languages
Oct 08, 2023The application of self-supervision to speech representation learning has garnered significant interest in recent years, due to its scalability to large amounts of unlabeled data. However, much progress, both in terms of pre-training and downstream evaluation, has remained concentrated in monolingual models that only consider English. Few models consider other languages, and even fewer consider indigenous ones. In our submission to the New Language Track of the ASRU 2023 ML-SUPERB Challenge, we present an ASR corpus for Quechua, an indigenous South American Language. We benchmark the efficacy of large SSL models on Quechua, along with 6 other indigenous languages such as Guarani and Bribri, on low-resource ASR. Our results show surprisingly strong performance by state-of-the-art SSL models, showing the potential generalizability of large-scale models to real-world data.
EFFUSE: Efficient Self-Supervised Feature Fusion for E2E ASR in Multilingual and Low Resource Scenarios
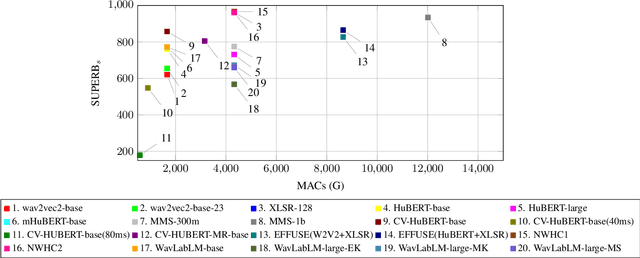
Oct 05, 2023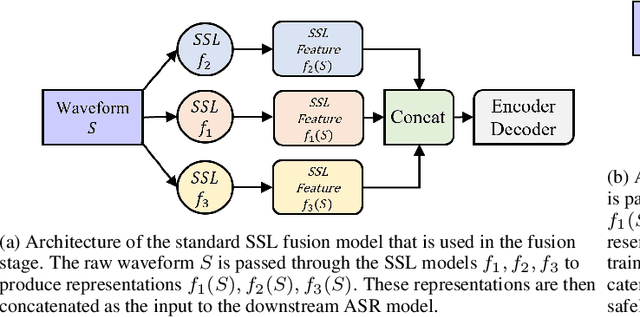

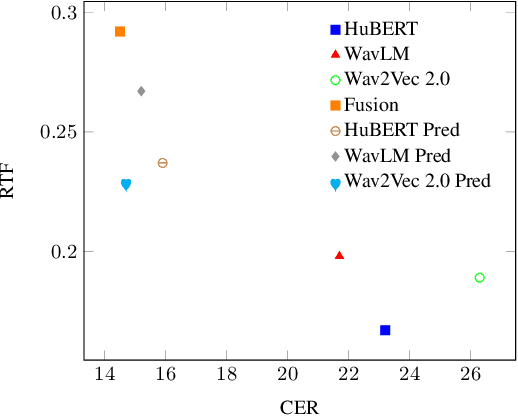
Self-Supervised Learning (SSL) models have demonstrated exceptional performance in various speech tasks, particularly in low-resource and multilingual domains. Recent works show that fusing SSL models could achieve superior performance compared to using one SSL model. However, fusion models have increased model parameter size, leading to longer inference times. In this paper, we propose a novel approach of predicting other SSL models' features from a single SSL model, resulting in a light-weight framework with competitive performance. Our experiments show that SSL feature prediction models outperform individual SSL models in multilingual speech recognition tasks. The leading prediction model achieves an average SUPERB score increase of 135.4 in ML-SUPERB benchmarks. Moreover, our proposed framework offers an efficient solution, as it reduces the resulting model parameter size and inference times compared to previous fusion models.
Reproducing Whisper-Style Training Using an Open-Source Toolkit and Publicly Available Data
Oct 02, 2023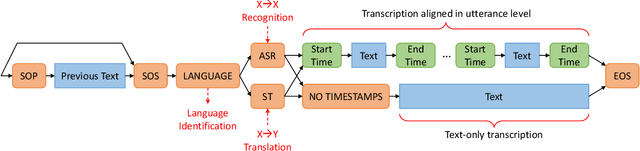
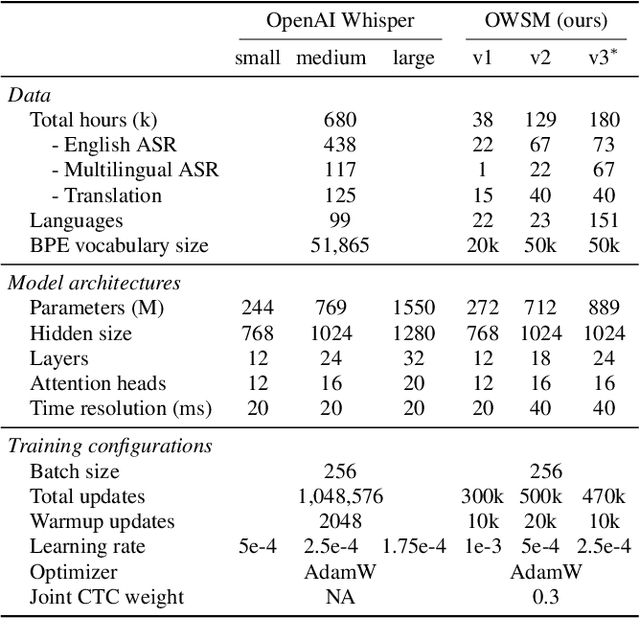
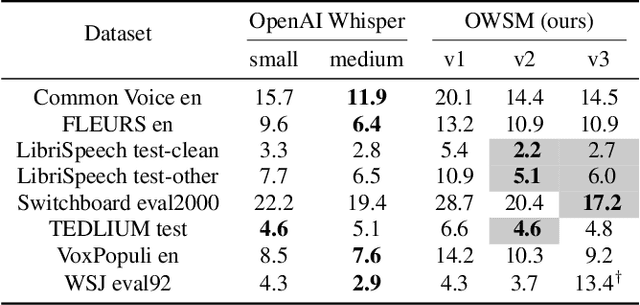
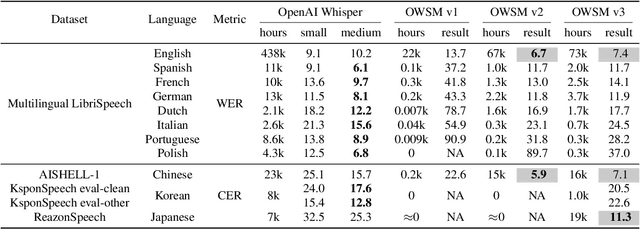
Pre-training speech models on large volumes of data has achieved remarkable success. OpenAI Whisper is a multilingual multitask model trained on 680k hours of supervised speech data. It generalizes well to various speech recognition and translation benchmarks even in a zero-shot setup. However, the full pipeline for developing such models (from data collection to training) is not publicly accessible, which makes it difficult for researchers to further improve its performance and address training-related issues such as efficiency, robustness, fairness, and bias. This work presents an Open Whisper-style Speech Model (OWSM), which reproduces Whisper-style training using an open-source toolkit and publicly available data. OWSM even supports more translation directions and can be more efficient to train. We will publicly release all scripts used for data preparation, training, inference, and scoring as well as pre-trained models and training logs to promote open science.
Joint Prediction and Denoising for Large-scale Multilingual Self-supervised Learning
Sep 28, 2023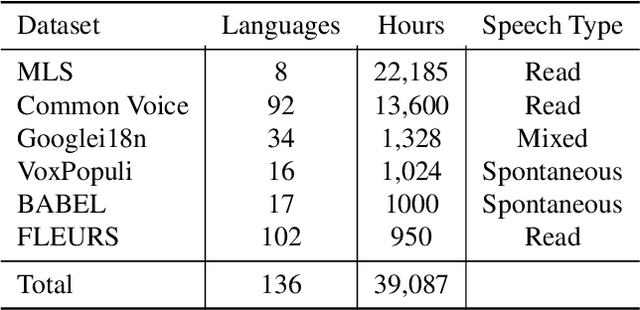
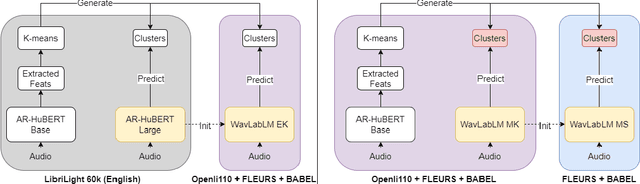
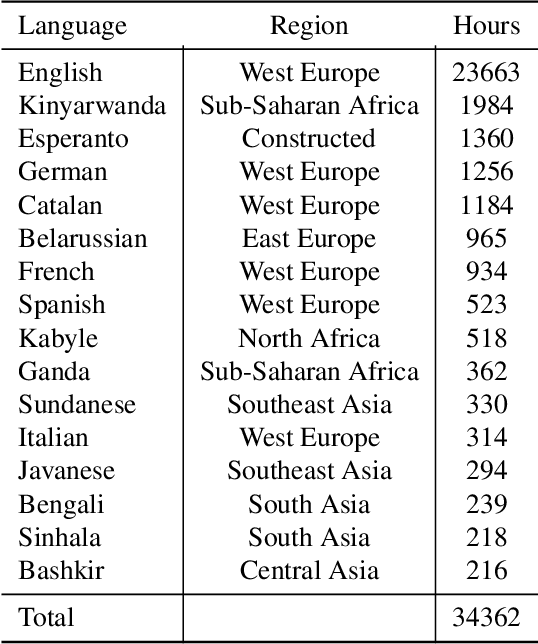
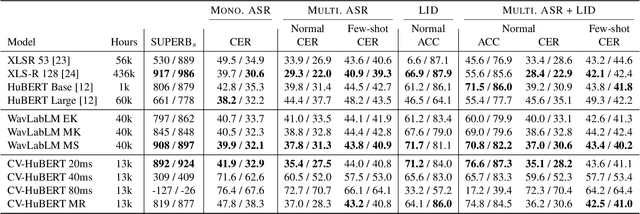
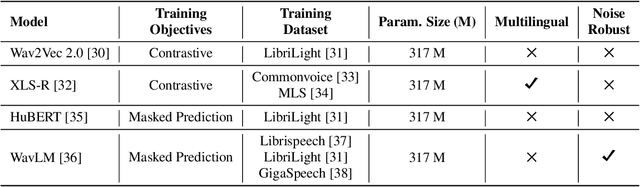
Multilingual self-supervised learning (SSL) has often lagged behind state-of-the-art (SOTA) methods due to the expenses and complexity required to handle many languages. This further harms the reproducibility of SSL, which is already limited to few research groups due to its resource usage. We show that more powerful techniques can actually lead to more efficient pre-training, opening SSL to more research groups. We propose WavLabLM, which extends WavLM's joint prediction and denoising to 40k hours of data across 136 languages. To build WavLabLM, we devise a novel multi-stage pre-training method, designed to address the language imbalance of multilingual data. WavLabLM achieves comparable performance to XLS-R on ML-SUPERB with less than 10% of the training data, making SSL realizable with academic compute. We show that further efficiency can be achieved with a vanilla HuBERT Base model, which can maintain 94% of XLS-R's performance with only 3% of the data, 4 GPUs, and limited trials. We open-source all code and models in ESPnet.
Reducing Barriers to Self-Supervised Learning: HuBERT Pre-training with Academic Compute
Jun 11, 2023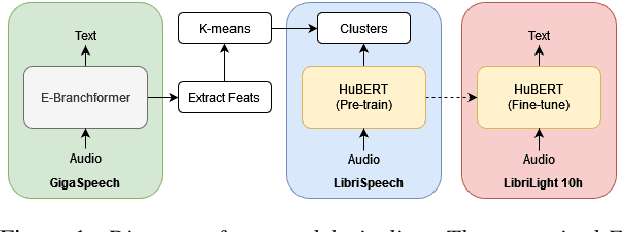
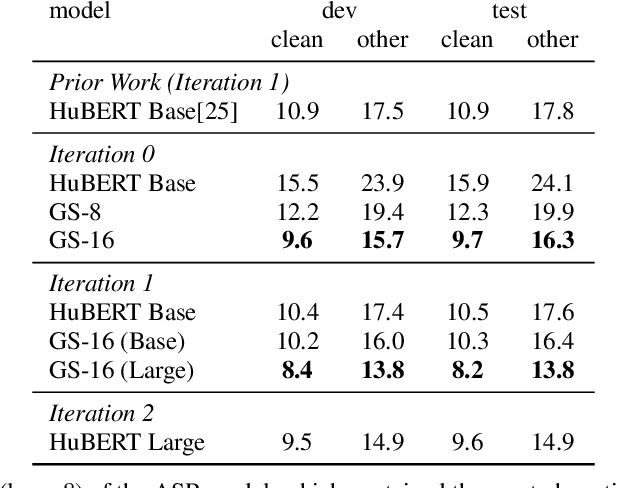
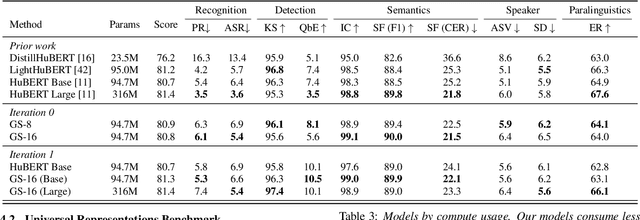
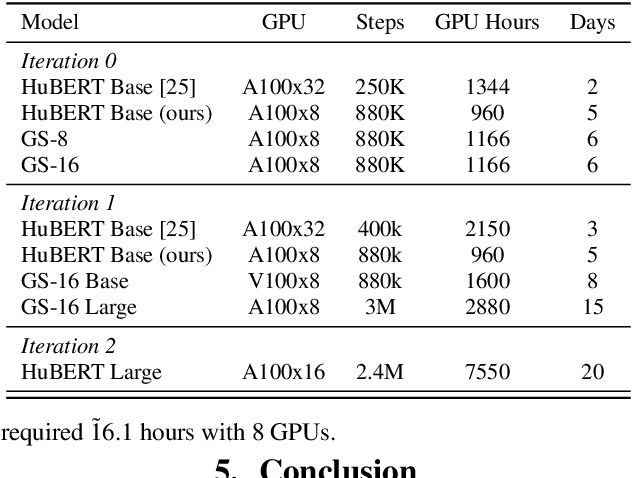
Self-supervised learning (SSL) has led to great strides in speech processing. However, the resources needed to train these models has become prohibitively large as they continue to scale. Currently, only a few groups with substantial resources are capable of creating SSL models, which harms reproducibility. In this work, we optimize HuBERT SSL to fit in academic constraints. We reproduce HuBERT independently from the original implementation, with no performance loss. Our code and training optimizations make SSL feasible with only 8 GPUs, instead of the 32 used in the original work. We also explore a semi-supervised route, using an ASR model to skip the first pre-training iteration. Within one iteration of pre-training, our models improve over HuBERT on several tasks. Furthermore, our HuBERT Large variant requires only 8 GPUs, achieving similar performance to the original trained on 128. As our contribution to the community, all models, configurations, and code are made open-source in ESPnet.