 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJie Hu
Rethinking 3D Dense Caption and Visual Grounding in A Unified Framework through Prompt-based Localization
Apr 17, 2024
3D Visual Grounding (3DVG) and 3D Dense Captioning (3DDC) are two crucial tasks in various 3D applications, which require both shared and complementary information in localization and visual-language relationships. Therefore, existing approaches adopt the two-stage "detect-then-describe/discriminate" pipeline, which relies heavily on the performance of the detector, resulting in suboptimal performance. Inspired by DETR, we propose a unified framework, 3DGCTR, to jointly solve these two distinct but closely related tasks in an end-to-end fashion. The key idea is to reconsider the prompt-based localization ability of the 3DVG model. In this way, the 3DVG model with a well-designed prompt as input can assist the 3DDC task by extracting localization information from the prompt. In terms of implementation, we integrate a Lightweight Caption Head into the existing 3DVG network with a Caption Text Prompt as a connection, effectively harnessing the existing 3DVG model's inherent localization capacity, thereby boosting 3DDC capability. This integration facilitates simultaneous multi-task training on both tasks, mutually enhancing their performance. Extensive experimental results demonstrate the effectiveness of this approach. Specifically, on the ScanRefer dataset, 3DGCTR surpasses the state-of-the-art 3DDC method by 4.3% in CIDEr@0.5IoU in MLE training and improves upon the SOTA 3DVG method by 3.16% in Acc@0.25IoU.
LIPT: Latency-aware Image Processing Transformer
Apr 09, 2024Transformer is leading a trend in the field of image processing. Despite the great success that existing lightweight image processing transformers have achieved, they are tailored to FLOPs or parameters reduction, rather than practical inference acceleration. In this paper, we present a latency-aware image processing transformer, termed LIPT. We devise the low-latency proportion LIPT block that substitutes memory-intensive operators with the combination of self-attention and convolutions to achieve practical speedup. Specifically, we propose a novel non-volatile sparse masking self-attention (NVSM-SA) that utilizes a pre-computing sparse mask to capture contextual information from a larger window with no extra computation overload. Besides, a high-frequency reparameterization module (HRM) is proposed to make LIPT block reparameterization friendly, which improves the model's detail reconstruction capability. Extensive experiments on multiple image processing tasks (e.g., image super-resolution (SR), JPEG artifact reduction, and image denoising) demonstrate the superiority of LIPT on both latency and PSNR. LIPT achieves real-time GPU inference with state-of-the-art performance on multiple image SR benchmarks.
Knowledge Distillation with Multi-granularity Mixture of Priors for Image Super-Resolution
Apr 03, 2024Knowledge distillation (KD) is a promising yet challenging model compression technique that transfers rich learning representations from a well-performing but cumbersome teacher model to a compact student model. Previous methods for image super-resolution (SR) mostly compare the feature maps directly or after standardizing the dimensions with basic algebraic operations (e.g. average, dot-product). However, the intrinsic semantic differences among feature maps are overlooked, which are caused by the disparate expressive capacity between the networks. This work presents MiPKD, a multi-granularity mixture of prior KD framework, to facilitate efficient SR model through the feature mixture in a unified latent space and stochastic network block mixture. Extensive experiments demonstrate the effectiveness of the proposed MiPKD method.
Distilling Semantic Priors from SAM to Efficient Image Restoration Models
Apr 02, 2024In image restoration (IR), leveraging semantic priors from segmentation models has been a common approach to improve performance. The recent segment anything model (SAM) has emerged as a powerful tool for extracting advanced semantic priors to enhance IR tasks. However, the computational cost of SAM is prohibitive for IR, compared to existing smaller IR models. The incorporation of SAM for extracting semantic priors considerably hampers the model inference efficiency. To address this issue, we propose a general framework to distill SAM's semantic knowledge to boost exiting IR models without interfering with their inference process. Specifically, our proposed framework consists of the semantic priors fusion (SPF) scheme and the semantic priors distillation (SPD) scheme. SPF fuses two kinds of information between the restored image predicted by the original IR model and the semantic mask predicted by SAM for the refined restored image. SPD leverages a self-distillation manner to distill the fused semantic priors to boost the performance of original IR models. Additionally, we design a semantic-guided relation (SGR) module for SPD, which ensures semantic feature representation space consistency to fully distill the priors. We demonstrate the effectiveness of our framework across multiple IR models and tasks, including deraining, deblurring, and denoising.
IPT-V2: Efficient Image Processing Transformer using Hierarchical Attentions
Mar 31, 2024Recent advances have demonstrated the powerful capability of transformer architecture in image restoration. However, our analysis indicates that existing transformerbased methods can not establish both exact global and local dependencies simultaneously, which are much critical to restore the details and missing content of degraded images. To this end, we present an efficient image processing transformer architecture with hierarchical attentions, called IPTV2, adopting a focal context self-attention (FCSA) and a global grid self-attention (GGSA) to obtain adequate token interactions in local and global receptive fields. Specifically, FCSA applies the shifted window mechanism into the channel self-attention, helps capture the local context and mutual interaction across channels. And GGSA constructs long-range dependencies in the cross-window grid, aggregates global information in spatial dimension. Moreover, we introduce structural re-parameterization technique to feed-forward network to further improve the model capability. Extensive experiments demonstrate that our proposed IPT-V2 achieves state-of-the-art results on various image processing tasks, covering denoising, deblurring, deraining and obtains much better trade-off for performance and computational complexity than previous methods. Besides, we extend our method to image generation as latent diffusion backbone, and significantly outperforms DiTs.
Joint Port Selection and Beamforming Design for Fluid Antenna Assisted Integrated Data and Energy Transfer
Mar 14, 2024
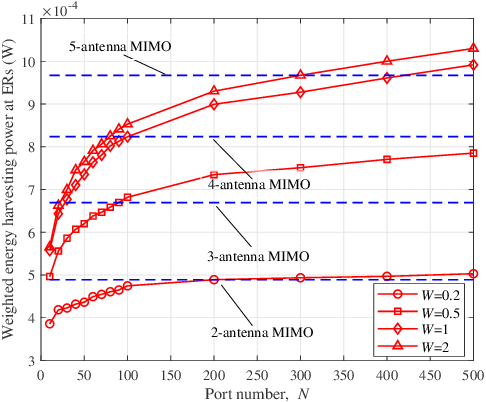
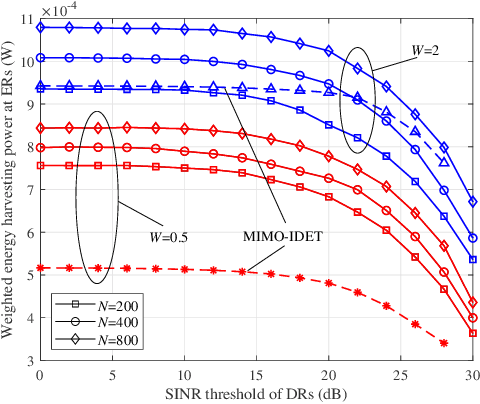
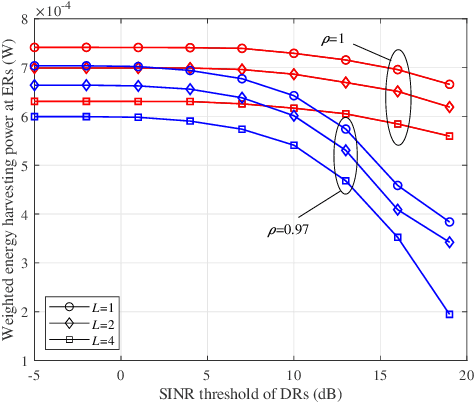
Integrated data and energy transfer (IDET) has been of fundamental importance for providing both wireless data transfer (WDT) and wireless energy transfer (WET) services towards low-power devices. Fluid antenna (FA) is capable of exploiting the huge spatial diversity of the wireless channel to enhance the receive signal strength, which is more suitable for the tiny-size low-power devices having the IDET requirements. In this letter, a multiuser FA assisted IDET system is studied and the weighted energy harvesting power at energy receivers (ERs) is maximized by jointly optimizing the port selection and transmit beamforming design under imperfect channel state information (CSI), while the signal-to-interference-plus-noise ratio (SINR) constraint for each data receiver (DR) is satisfied. An efficient algorithm is proposed to obtain the suboptimal solutions for the non-convex problem. Simulation results evaluate the performance of the FA-IDET system, while also demonstrate that FA outperforms the multi-input-multi-output (MIMO) counterpart in terms of the IDET performance, as long as the port number is large enough.
Proxy-RLHF: Decoupling Generation and Alignment in Large Language Model with Proxy
Mar 07, 2024
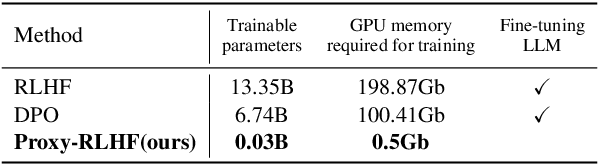
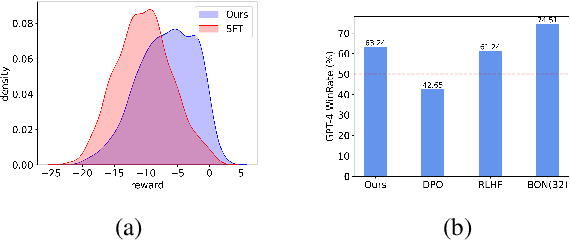
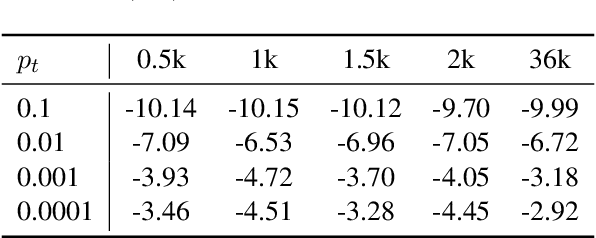
Reinforcement Learning from Human Feedback (RLHF) is the prevailing approach to ensure Large Language Models (LLMs) align with human values. However, existing RLHF methods require a high computational cost, one main reason being that RLHF assigns both the generation and alignment tasks to the LLM simultaneously. In this paper, we introduce Proxy-RLHF, which decouples the generation and alignment processes of LLMs, achieving alignment with human values at a much lower computational cost. We start with a novel Markov Decision Process (MDP) designed for the alignment process and employ Reinforcement Learning (RL) to train a streamlined proxy model that oversees the token generation of the LLM, without altering the LLM itself. Experiments show that our method achieves a comparable level of alignment with only 1\% of the training parameters of other methods.
Self-Supervised Representation Learning with Meta Comprehensive Regularization
Mar 03, 2024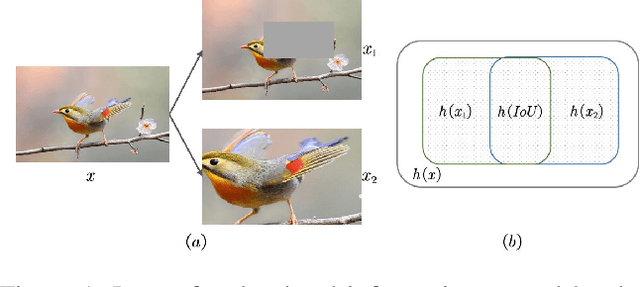
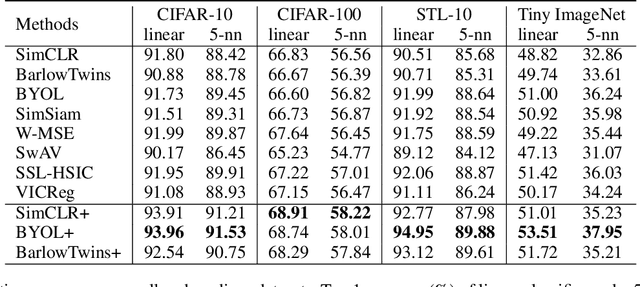
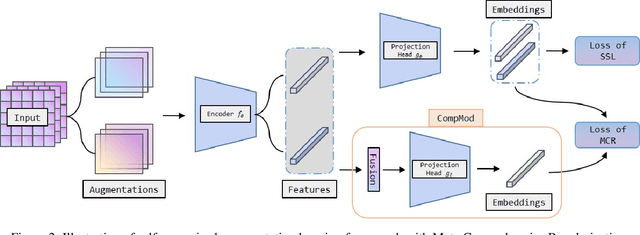
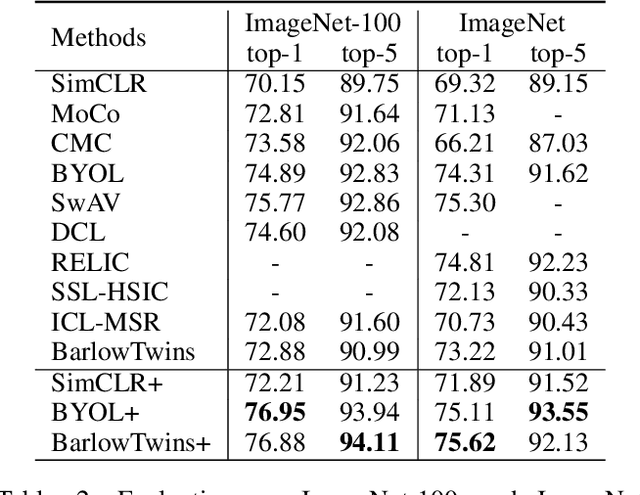
Self-Supervised Learning (SSL) methods harness the concept of semantic invariance by utilizing data augmentation strategies to produce similar representations for different deformations of the same input. Essentially, the model captures the shared information among multiple augmented views of samples, while disregarding the non-shared information that may be beneficial for downstream tasks. To address this issue, we introduce a module called CompMod with Meta Comprehensive Regularization (MCR), embedded into existing self-supervised frameworks, to make the learned representations more comprehensive. Specifically, we update our proposed model through a bi-level optimization mechanism, enabling it to capture comprehensive features. Additionally, guided by the constrained extraction of features using maximum entropy coding, the self-supervised learning model learns more comprehensive features on top of learning consistent features. In addition, we provide theoretical support for our proposed method from information theory and causal counterfactual perspective. Experimental results show that our method achieves significant improvement in classification, object detection and instance segmentation tasks on multiple benchmark datasets.
Accelerating Distributed Stochastic Optimization via Self-Repellent Random Walks
Jan 18, 2024We study a family of distributed stochastic optimization algorithms where gradients are sampled by a token traversing a network of agents in random-walk fashion. Typically, these random-walks are chosen to be Markov chains that asymptotically sample from a desired target distribution, and play a critical role in the convergence of the optimization iterates. In this paper, we take a novel approach by replacing the standard linear Markovian token by one which follows a nonlinear Markov chain - namely the Self-Repellent Radom Walk (SRRW). Defined for any given 'base' Markov chain, the SRRW, parameterized by a positive scalar {\alpha}, is less likely to transition to states that were highly visited in the past, thus the name. In the context of MCMC sampling on a graph, a recent breakthrough in Doshi et al. (2023) shows that the SRRW achieves O(1/{\alpha}) decrease in the asymptotic variance for sampling. We propose the use of a 'generalized' version of the SRRW to drive token algorithms for distributed stochastic optimization in the form of stochastic approximation, termed SA-SRRW. We prove that the optimization iterate errors of the resulting SA-SRRW converge to zero almost surely and prove a central limit theorem, deriving the explicit form of the resulting asymptotic covariance matrix corresponding to iterate errors. This asymptotic covariance is always smaller than that of an algorithm driven by the base Markov chain and decreases at rate O(1/{\alpha}^2) - the performance benefit of using SRRW thereby amplified in the stochastic optimization context. Empirical results support our theoretical findings.