 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiawu Zheng
GraCo: Granularity-Controllable Interactive Segmentation
May 01, 2024
Interactive Segmentation (IS) segments specific objects or parts in the image according to user input. Current IS pipelines fall into two categories: single-granularity output and multi-granularity output. The latter aims to alleviate the spatial ambiguity present in the former. However, the multi-granularity output pipeline suffers from limited interaction flexibility and produces redundant results. In this work, we introduce Granularity-Controllable Interactive Segmentation (GraCo), a novel approach that allows precise control of prediction granularity by introducing additional parameters to input. This enhances the customization of the interactive system and eliminates redundancy while resolving ambiguity. Nevertheless, the exorbitant cost of annotating multi-granularity masks and the lack of available datasets with granularity annotations make it difficult for models to acquire the necessary guidance to control output granularity. To address this problem, we design an any-granularity mask generator that exploits the semantic property of the pre-trained IS model to automatically generate abundant mask-granularity pairs without requiring additional manual annotation. Based on these pairs, we propose a granularity-controllable learning strategy that efficiently imparts the granularity controllability to the IS model. Extensive experiments on intricate scenarios at object and part levels demonstrate that our GraCo has significant advantages over previous methods. This highlights the potential of GraCo to be a flexible annotation tool, capable of adapting to diverse segmentation scenarios. The project page: https://zhao-yian.github.io/GraCo.
Cantor: Inspiring Multimodal Chain-of-Thought of MLLM
Apr 24, 2024With the advent of large language models(LLMs) enhanced by the chain-of-thought(CoT) methodology, visual reasoning problem is usually decomposed into manageable sub-tasks and tackled sequentially with various external tools. However, such a paradigm faces the challenge of the potential "determining hallucinations" in decision-making due to insufficient visual information and the limitation of low-level perception tools that fail to provide abstract summaries necessary for comprehensive reasoning. We argue that converging visual context acquisition and logical reasoning is pivotal for tackling visual reasoning tasks. This paper delves into the realm of multimodal CoT to solve intricate visual reasoning tasks with multimodal large language models(MLLMs) and their cognitive capability. To this end, we propose an innovative multimodal CoT framework, termed Cantor, characterized by a perception-decision architecture. Cantor first acts as a decision generator and integrates visual inputs to analyze the image and problem, ensuring a closer alignment with the actual context. Furthermore, Cantor leverages the advanced cognitive functions of MLLMs to perform as multifaceted experts for deriving higher-level information, enhancing the CoT generation process. Our extensive experiments demonstrate the efficacy of the proposed framework, showing significant improvements in multimodal CoT performance across two complex visual reasoning datasets, without necessitating fine-tuning or ground-truth rationales. Project Page: https://ggg0919.github.io/cantor/ .
Multi-Modal Prompt Learning on Blind Image Quality Assessment
Apr 23, 2024Image Quality Assessment (IQA) models benefit significantly from semantic information, which allows them to treat different types of objects distinctly. Currently, leveraging semantic information to enhance IQA is a crucial research direction. Traditional methods, hindered by a lack of sufficiently annotated data, have employed the CLIP image-text pretraining model as their backbone to gain semantic awareness. However, the generalist nature of these pre-trained Vision-Language (VL) models often renders them suboptimal for IQA-specific tasks. Recent approaches have attempted to address this mismatch using prompt technology, but these solutions have shortcomings. Existing prompt-based VL models overly focus on incremental semantic information from text, neglecting the rich insights available from visual data analysis. This imbalance limits their performance improvements in IQA tasks. This paper introduces an innovative multi-modal prompt-based methodology for IQA. Our approach employs carefully crafted prompts that synergistically mine incremental semantic information from both visual and linguistic data. Specifically, in the visual branch, we introduce a multi-layer prompt structure to enhance the VL model's adaptability. In the text branch, we deploy a dual-prompt scheme that steers the model to recognize and differentiate between scene category and distortion type, thereby refining the model's capacity to assess image quality. Our experimental findings underscore the effectiveness of our method over existing Blind Image Quality Assessment (BIQA) approaches. Notably, it demonstrates competitive performance across various datasets. Our method achieves Spearman Rank Correlation Coefficient (SRCC) values of 0.961(surpassing 0.946 in CSIQ) and 0.941 (exceeding 0.930 in KADID), illustrating its robustness and accuracy in diverse contexts.
Motion-aware Latent Diffusion Models for Video Frame Interpolation
Apr 21, 2024With the advancement of AIGC, video frame interpolation (VFI) has become a crucial component in existing video generation frameworks, attracting widespread research interest. For the VFI task, the motion estimation between neighboring frames plays a crucial role in avoiding motion ambiguity. However, existing VFI methods always struggle to accurately predict the motion information between consecutive frames, and this imprecise estimation leads to blurred and visually incoherent interpolated frames. In this paper, we propose a novel diffusion framework, motion-aware latent diffusion models (MADiff), which is specifically designed for the VFI task. By incorporating motion priors between the conditional neighboring frames with the target interpolated frame predicted throughout the diffusion sampling procedure, MADiff progressively refines the intermediate outcomes, culminating in generating both visually smooth and realistic results. Extensive experiments conducted on benchmark datasets demonstrate that our method achieves state-of-the-art performance significantly outperforming existing approaches, especially under challenging scenarios involving dynamic textures with complex motion.
Rethinking 3D Dense Caption and Visual Grounding in A Unified Framework through Prompt-based Localization
Apr 17, 20243D Visual Grounding (3DVG) and 3D Dense Captioning (3DDC) are two crucial tasks in various 3D applications, which require both shared and complementary information in localization and visual-language relationships. Therefore, existing approaches adopt the two-stage "detect-then-describe/discriminate" pipeline, which relies heavily on the performance of the detector, resulting in suboptimal performance. Inspired by DETR, we propose a unified framework, 3DGCTR, to jointly solve these two distinct but closely related tasks in an end-to-end fashion. The key idea is to reconsider the prompt-based localization ability of the 3DVG model. In this way, the 3DVG model with a well-designed prompt as input can assist the 3DDC task by extracting localization information from the prompt. In terms of implementation, we integrate a Lightweight Caption Head into the existing 3DVG network with a Caption Text Prompt as a connection, effectively harnessing the existing 3DVG model's inherent localization capacity, thereby boosting 3DDC capability. This integration facilitates simultaneous multi-task training on both tasks, mutually enhancing their performance. Extensive experimental results demonstrate the effectiveness of this approach. Specifically, on the ScanRefer dataset, 3DGCTR surpasses the state-of-the-art 3DDC method by 4.3% in CIDEr@0.5IoU in MLE training and improves upon the SOTA 3DVG method by 3.16% in Acc@0.25IoU.
AffineQuant: Affine Transformation Quantization for Large Language Models
Mar 19, 2024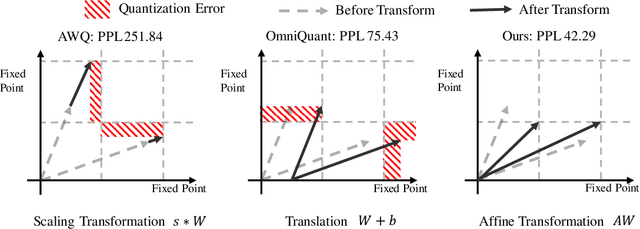
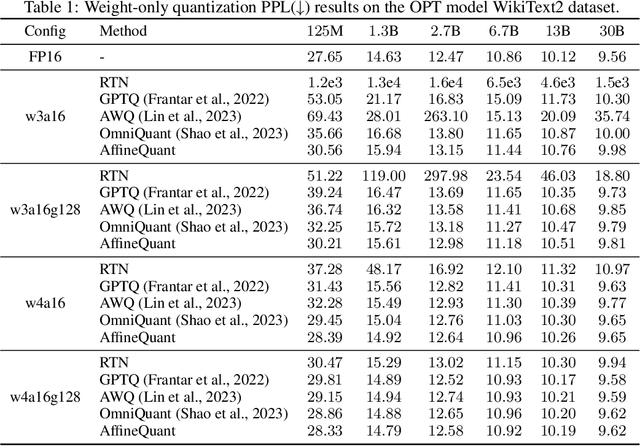

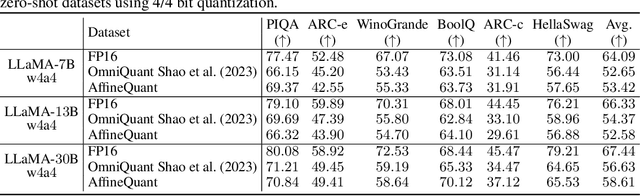
The significant resource requirements associated with Large-scale Language Models (LLMs) have generated considerable interest in the development of techniques aimed at compressing and accelerating neural networks. Among these techniques, Post-Training Quantization (PTQ) has emerged as a subject of considerable interest due to its noteworthy compression efficiency and cost-effectiveness in the context of training. Existing PTQ methods for LLMs limit the optimization scope to scaling transformations between pre- and post-quantization weights. In this paper, we advocate for the direct optimization using equivalent Affine transformations in PTQ (AffineQuant). This approach extends the optimization scope and thus significantly minimizing quantization errors. Additionally, by employing the corresponding inverse matrix, we can ensure equivalence between the pre- and post-quantization outputs of PTQ, thereby maintaining its efficiency and generalization capabilities. To ensure the invertibility of the transformation during optimization, we further introduce a gradual mask optimization method. This method initially focuses on optimizing the diagonal elements and gradually extends to the other elements. Such an approach aligns with the Levy-Desplanques theorem, theoretically ensuring invertibility of the transformation. As a result, significant performance improvements are evident across different LLMs on diverse datasets. To illustrate, we attain a C4 perplexity of 15.76 (2.26 lower vs 18.02 in OmniQuant) on the LLaMA2-7B model of W4A4 quantization without overhead. On zero-shot tasks, AffineQuant achieves an average of 58.61 accuracy (1.98 lower vs 56.63 in OmniQuant) when using 4/4-bit quantization for LLaMA-30B, which setting a new state-of-the-art benchmark for PTQ in LLMs.
Data Interpreter: An LLM Agent For Data Science
Mar 12, 2024Large Language Model (LLM)-based agents have demonstrated remarkable effectiveness. However, their performance can be compromised in data science scenarios that require real-time data adjustment, expertise in optimization due to complex dependencies among various tasks, and the ability to identify logical errors for precise reasoning. In this study, we introduce the Data Interpreter, a solution designed to solve with code that emphasizes three pivotal techniques to augment problem-solving in data science: 1) dynamic planning with hierarchical graph structures for real-time data adaptability;2) tool integration dynamically to enhance code proficiency during execution, enriching the requisite expertise;3) logical inconsistency identification in feedback, and efficiency enhancement through experience recording. We evaluate the Data Interpreter on various data science and real-world tasks. Compared to open-source baselines, it demonstrated superior performance, exhibiting significant improvements in machine learning tasks, increasing from 0.86 to 0.95. Additionally, it showed a 26% increase in the MATH dataset and a remarkable 112% improvement in open-ended tasks. The solution will be released at https://github.com/geekan/MetaGPT.
Feast Your Eyes: Mixture-of-Resolution Adaptation for Multimodal Large Language Models
Mar 05, 2024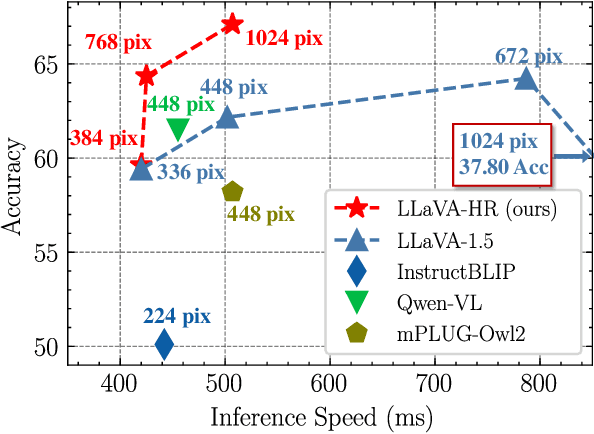
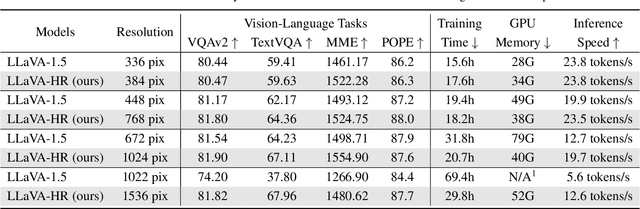
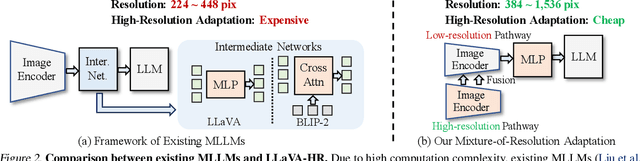
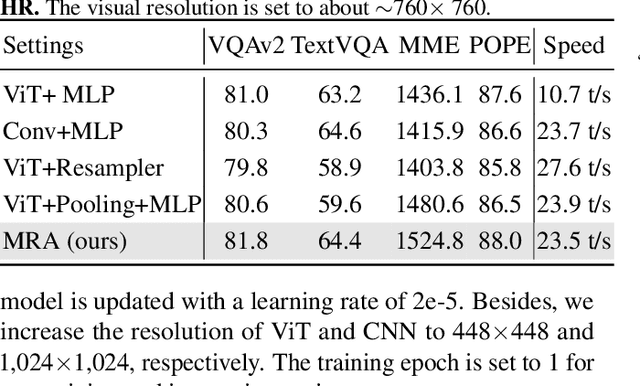
Despite remarkable progress, existing multimodal large language models (MLLMs) are still inferior in granular visual recognition. Contrary to previous works, we study this problem from the perspective of image resolution, and reveal that a combination of low- and high-resolution visual features can effectively mitigate this shortcoming. Based on this observation, we propose a novel and efficient method for MLLMs, termed Mixture-of-Resolution Adaptation (MRA). In particular, MRA adopts two visual pathways for images with different resolutions, where high-resolution visual information is embedded into the low-resolution pathway via the novel mixture-of-resolution adapters (MR-Adapters). This design also greatly reduces the input sequence length of MLLMs. To validate MRA, we apply it to a recent MLLM called LLaVA, and term the new model LLaVA-HR. We conduct extensive experiments on 11 vision-language (VL) tasks, which show that LLaVA-HR outperforms existing MLLMs on 8 VL tasks, e.g., +9.4% on TextVQA. More importantly, both training and inference of LLaVA-HR remain efficient with MRA, e.g., 20 training hours and 3$\times$ inference speed than LLaVA-1.5. Source codes are released at: https://github.com/luogen1996/LLaVA-HR.
EBFT: Effective and Block-Wise Fine-Tuning for Sparse LLMs
Feb 19, 2024Existing methods for fine-tuning sparse LLMs often suffer from resource-intensive requirements and high retraining costs. Additionally, many fine-tuning methods often rely on approximations or heuristic optimization strategies, which may lead to suboptimal solutions. To address these issues, we propose an efficient and fast framework for fine-tuning sparse LLMs based on minimizing reconstruction error. Our approach involves sampling a small dataset for calibration and utilizing backpropagation to iteratively optimize block-wise reconstruction error, on a block-by-block basis, aiming for optimal solutions. Extensive experiments on various benchmarks consistently demonstrate the superiority of our method over other baselines. For instance, on the Wikitext2 dataset with LlamaV1-7B at 70% sparsity, our proposed EBFT achieves a perplexity of 16.88, surpassing the state-of-the-art DSnoT with a perplexity of 75.14. Moreover, with a structured sparsity ratio of 26\%, EBFT achieves a perplexity of 16.27, outperforming LoRA (perplexity 16.44). Furthermore, the fine-tuning process of EBFT for LlamaV1-7B only takes approximately 30 minutes, and the entire framework can be executed on a single 16GB GPU. The source code is available at https://github.com/sunggo/EBFT.
Feature Denoising Diffusion Model for Blind Image Quality Assessment
Jan 22, 2024Blind Image Quality Assessment (BIQA) aims to evaluate image quality in line with human perception, without reference benchmarks. Currently, deep learning BIQA methods typically depend on using features from high-level tasks for transfer learning. However, the inherent differences between BIQA and these high-level tasks inevitably introduce noise into the quality-aware features. In this paper, we take an initial step towards exploring the diffusion model for feature denoising in BIQA, namely Perceptual Feature Diffusion for IQA (PFD-IQA), which aims to remove noise from quality-aware features. Specifically, (i) We propose a {Perceptual Prior Discovery and Aggregation module to establish two auxiliary tasks to discover potential low-level features in images that are used to aggregate perceptual text conditions for the diffusion model. (ii) We propose a Perceptual Prior-based Feature Refinement strategy, which matches noisy features to predefined denoising trajectories and then performs exact feature denoising based on text conditions. Extensive experiments on eight standard BIQA datasets demonstrate the superior performance to the state-of-the-art BIQA methods, i.e., achieving the PLCC values of 0.935 ( vs. 0.905 in KADID) and 0.922 ( vs. 0.894 in LIVEC).