 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMingchen Zhuge
Data Interpreter: An LLM Agent For Data Science
Mar 12, 2024
Large Language Model (LLM)-based agents have demonstrated remarkable effectiveness. However, their performance can be compromised in data science scenarios that require real-time data adjustment, expertise in optimization due to complex dependencies among various tasks, and the ability to identify logical errors for precise reasoning. In this study, we introduce the Data Interpreter, a solution designed to solve with code that emphasizes three pivotal techniques to augment problem-solving in data science: 1) dynamic planning with hierarchical graph structures for real-time data adaptability;2) tool integration dynamically to enhance code proficiency during execution, enriching the requisite expertise;3) logical inconsistency identification in feedback, and efficiency enhancement through experience recording. We evaluate the Data Interpreter on various data science and real-world tasks. Compared to open-source baselines, it demonstrated superior performance, exhibiting significant improvements in machine learning tasks, increasing from 0.86 to 0.95. Additionally, it showed a 26% increase in the MATH dataset and a remarkable 112% improvement in open-ended tasks. The solution will be released at https://github.com/geekan/MetaGPT.
Language Agents as Optimizable Graphs
Feb 27, 2024Various human-designed prompt engineering techniques have been proposed to improve problem solvers based on Large Language Models (LLMs), yielding many disparate code bases. We unify these approaches by describing LLM-based agents as computational graphs. The nodes implement functions to process multimodal data or query LLMs, and the edges describe the information flow between operations. Graphs can be recursively combined into larger composite graphs representing hierarchies of inter-agent collaboration (where edges connect operations of different agents). Our novel automatic graph optimizers (1) refine node-level LLM prompts (node optimization) and (2) improve agent orchestration by changing graph connectivity (edge optimization). Experiments demonstrate that our framework can be used to efficiently develop, integrate, and automatically improve various LLM agents. The code can be found at https://github.com/metauto-ai/gptswarm.
Learning to Identify Critical States for Reinforcement Learning from Videos
Aug 15, 2023



Recent work on deep reinforcement learning (DRL) has pointed out that algorithmic information about good policies can be extracted from offline data which lack explicit information about executed actions. For example, videos of humans or robots may convey a lot of implicit information about rewarding action sequences, but a DRL machine that wants to profit from watching such videos must first learn by itself to identify and recognize relevant states/actions/rewards. Without relying on ground-truth annotations, our new method called Deep State Identifier learns to predict returns from episodes encoded as videos. Then it uses a kind of mask-based sensitivity analysis to extract/identify important critical states. Extensive experiments showcase our method's potential for understanding and improving agent behavior. The source code and the generated datasets are available at https://github.com/AI-Initiative-KAUST/VideoRLCS.
Mindstorms in Natural Language-Based Societies of Mind
May 26, 2023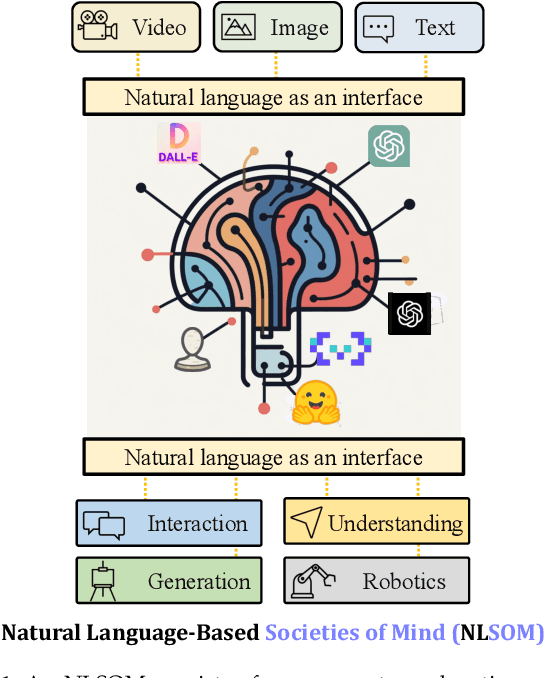
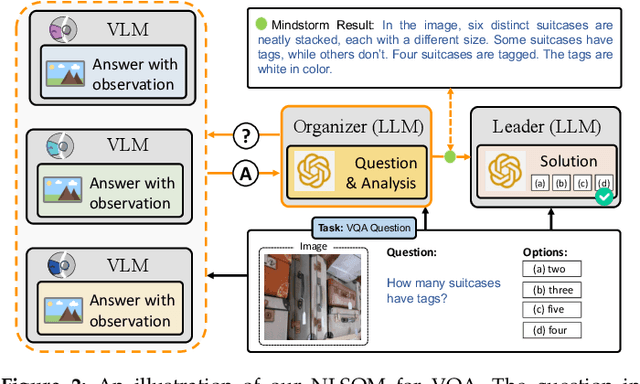
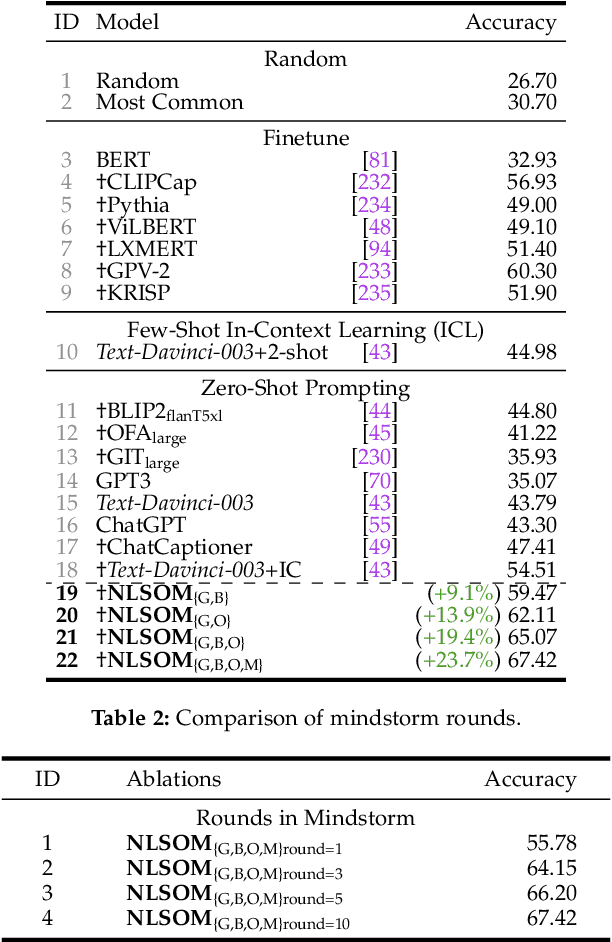

Both Minsky's "society of mind" and Schmidhuber's "learning to think" inspire diverse societies of large multimodal neural networks (NNs) that solve problems by interviewing each other in a "mindstorm." Recent implementations of NN-based societies of minds consist of large language models (LLMs) and other NN-based experts communicating through a natural language interface. In doing so, they overcome the limitations of single LLMs, improving multimodal zero-shot reasoning. In these natural language-based societies of mind (NLSOMs), new agents -- all communicating through the same universal symbolic language -- are easily added in a modular fashion. To demonstrate the power of NLSOMs, we assemble and experiment with several of them (having up to 129 members), leveraging mindstorms in them to solve some practical AI tasks: visual question answering, image captioning, text-to-image synthesis, 3D generation, egocentric retrieval, embodied AI, and general language-based task solving. We view this as a starting point towards much larger NLSOMs with billions of agents-some of which may be humans. And with this emergence of great societies of heterogeneous minds, many new research questions have suddenly become paramount to the future of artificial intelligence. What should be the social structure of an NLSOM? What would be the (dis)advantages of having a monarchical rather than a democratic structure? How can principles of NN economies be used to maximize the total reward of a reinforcement learning NLSOM? In this work, we identify, discuss, and try to answer some of these questions.
QR-CLIP: Introducing Explicit Open-World Knowledge for Location and Time Reasoning
Feb 02, 2023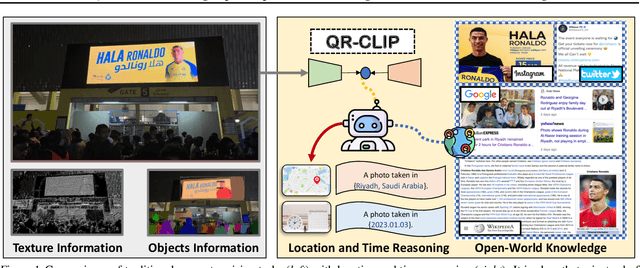
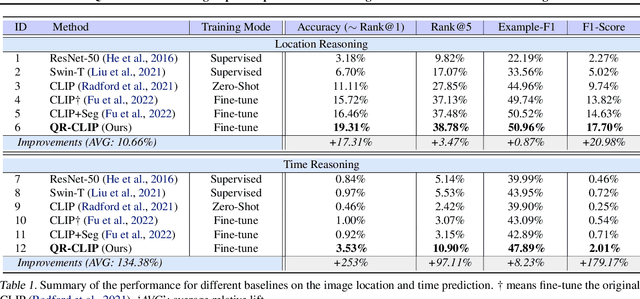
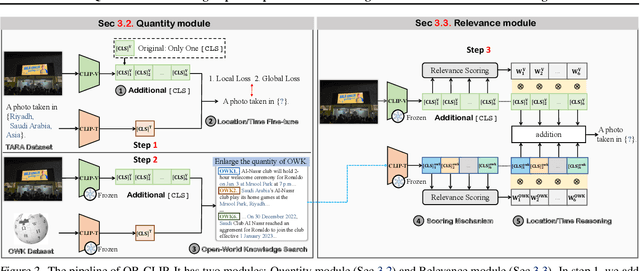
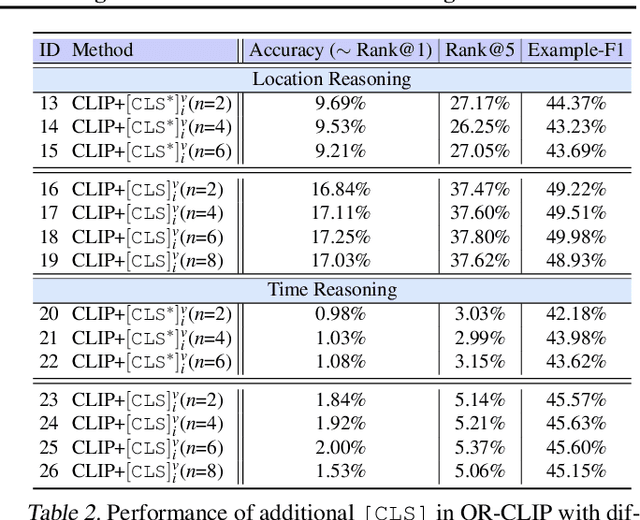
Daily images may convey abstract meanings that require us to memorize and infer profound information from them. To encourage such human-like reasoning, in this work, we teach machines to predict where and when it was taken rather than performing basic tasks like traditional segmentation or classification. Inspired by Horn's QR theory, we designed a novel QR-CLIP model consisting of two components: 1) the Quantity module first retrospects more open-world knowledge as the candidate language inputs; 2) the Relevance module carefully estimates vision and language cues and infers the location and time. Experiments show our QR-CLIP's effectiveness, and it outperforms the previous SOTA on each task by an average of about 10% and 130% relative lift in terms of location and time reasoning. This study lays a technical foundation for location and time reasoning and suggests that effectively introducing open-world knowledge is one of the panaceas for the tasks.
Audio-Visual MLP for Scoring Sport
Mar 22, 2022



Figure skating scoring is a challenging task because it requires judging players' technical moves as well as coordination with the background music. Prior learning-based work cannot solve it well for two reasons: 1) each move in figure skating changes quickly, hence simply applying traditional frame sampling will lose a lot of valuable information, especially in a 3-5 minutes lasting video, so an extremely long-range representation learning is necessary; 2) prior methods rarely considered the critical audio-visual relationship in their models. Thus, we introduce a multimodal MLP architecture, named Skating-Mixer. It extends the MLP-Mixer-based framework into a multimodal fashion and effectively learns long-term representations through our designed memory recurrent unit (MRU). Aside from the model, we also collected a high-quality audio-visual FS1000 dataset, which contains over 1000 videos on 8 types of programs with 7 different rating metrics, overtaking other datasets in both quantity and diversity. Experiments show the proposed method outperforms SOTAs over all major metrics on the public Fis-V and our FS1000 dataset. In addition, we include an analysis applying our method to recent competitions that occurred in Beijing 2022 Winter Olympic Games, proving our method has strong robustness.
Fast Camouflaged Object Detection via Edge-based Reversible Re-calibration Network
Nov 05, 2021



Camouflaged Object Detection (COD) aims to detect objects with similar patterns (e.g., texture, intensity, colour, etc) to their surroundings, and recently has attracted growing research interest. As camouflaged objects often present very ambiguous boundaries, how to determine object locations as well as their weak boundaries is challenging and also the key to this task. Inspired by the biological visual perception process when a human observer discovers camouflaged objects, this paper proposes a novel edge-based reversible re-calibration network called ERRNet. Our model is characterized by two innovative designs, namely Selective Edge Aggregation (SEA) and Reversible Re-calibration Unit (RRU), which aim to model the visual perception behaviour and achieve effective edge prior and cross-comparison between potential camouflaged regions and background. More importantly, RRU incorporates diverse priors with more comprehensive information comparing to existing COD models. Experimental results show that ERRNet outperforms existing cutting-edge baselines on three COD datasets and five medical image segmentation datasets. Especially, compared with the existing top-1 model SINet, ERRNet significantly improves the performance by $\sim$6% (mean E-measure) with notably high speed (79.3 FPS), showing that ERRNet could be a general and robust solution for the COD task.
Kaleido-BERT: Vision-Language Pre-training on Fashion Domain
Apr 15, 2021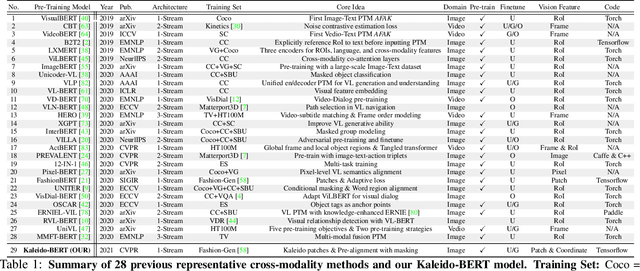
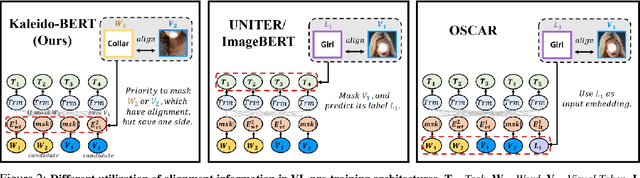
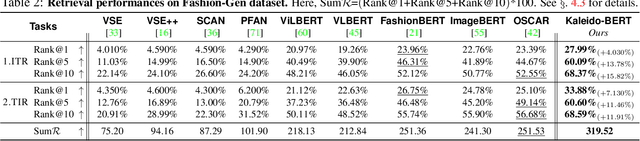
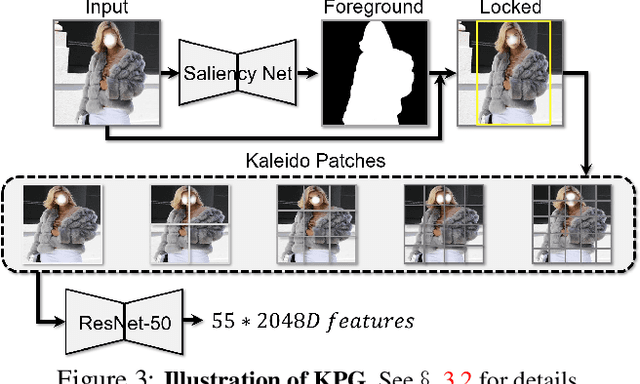
We present a new vision-language (VL) pre-training model dubbed Kaleido-BERT, which introduces a novel kaleido strategy for fashion cross-modality representations from transformers. In contrast to random masking strategy of recent VL models, we design alignment guided masking to jointly focus more on image-text semantic relations. To this end, we carry out five novel tasks, i.e., rotation, jigsaw, camouflage, grey-to-color, and blank-to-color for self-supervised VL pre-training at patches of different scale. Kaleido-BERT is conceptually simple and easy to extend to the existing BERT framework, it attains new state-of-the-art results by large margins on four downstream tasks, including text retrieval (R@1: 4.03% absolute improvement), image retrieval (R@1: 7.13% abs imv.), category recognition (ACC: 3.28% abs imv.), and fashion captioning (Bleu4: 1.2 abs imv.). We validate the efficiency of Kaleido-BERT on a wide range of e-commerical websites, demonstrating its broader potential in real-world applications.
Salient Object Detection via Integrity Learning
Feb 21, 2021



Albeit current salient object detection (SOD) works have achieved fantastic progress, they are cast into the shade when it comes to the integrity of the predicted salient regions. We define the concept of integrity at both the micro and macro level. Specifically, at the micro level, the model should highlight all parts that belong to a certain salient object, while at the macro level, the model needs to discover all salient objects from the given image scene. To facilitate integrity learning for salient object detection, we design a novel Integrity Cognition Network (ICON), which explores three important components to learn strong integrity features. 1) Unlike the existing models that focus more on feature discriminability, we introduce a diverse feature aggregation (DFA) component to aggregate features with various receptive fields (i.e.,, kernel shape and context) and increase the feature diversity. Such diversity is the foundation for mining the integral salient objects. 2) Based on the DFA features, we introduce the integrity channel enhancement (ICE) component with the goal of enhancing feature channels that highlight the integral salient objects at the macro level, while suppressing the other distracting ones. 3) After extracting the enhanced features, the part-whole verification (PWV) method is employed to determine whether the part and whole object features have strong agreement. Such part-whole agreements can further improve the micro-level integrity for each salient object. To demonstrate the effectiveness of ICON, comprehensive experiments are conducted on seven challenging benchmarks, where promising results are achieved.
Towards Accurate Camouflaged Object Detection with Mixture Convolution and Interactive Fusion
Jan 14, 2021



Camouflaged object detection (COD), which aims to identify the objects that conceal themselves into the surroundings, has recently drawn increasing research efforts in the field of computer vision. In practice, the success of deep learning based COD is mainly determined by two key factors, including (i) A significantly large receptive field, which provides rich context information, and (ii) An effective fusion strategy, which aggregates the rich multi-level features for accurate COD. Motivated by these observations, in this paper, we propose a novel deep learning based COD approach, which integrates the large receptive field and effective feature fusion into a unified framework. Specifically, we first extract multi-level features from a backbone network. The resulting features are then fed to the proposed dual-branch mixture convolution modules, each of which utilizes multiple asymmetric convolutional layers and two dilated convolutional layers to extract rich context features from a large receptive field. Finally, we fuse the features using specially-designed multi-level interactive fusion modules, each of which employs an attention mechanism along with feature interaction for effective feature fusion. Our method detects camouflaged objects with an effective fusion strategy, which aggregates the rich context information from a large receptive field. All of these designs meet the requirements of COD well, allowing the accurate detection of camouflaged objects. Extensive experiments on widely-used benchmark datasets demonstrate that our method is capable of accurately detecting camouflaged objects and outperforms the state-of-the-art methods.