 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiujuan Cao
Cantor: Inspiring Multimodal Chain-of-Thought of MLLM
Apr 24, 2024
With the advent of large language models(LLMs) enhanced by the chain-of-thought(CoT) methodology, visual reasoning problem is usually decomposed into manageable sub-tasks and tackled sequentially with various external tools. However, such a paradigm faces the challenge of the potential "determining hallucinations" in decision-making due to insufficient visual information and the limitation of low-level perception tools that fail to provide abstract summaries necessary for comprehensive reasoning. We argue that converging visual context acquisition and logical reasoning is pivotal for tackling visual reasoning tasks. This paper delves into the realm of multimodal CoT to solve intricate visual reasoning tasks with multimodal large language models(MLLMs) and their cognitive capability. To this end, we propose an innovative multimodal CoT framework, termed Cantor, characterized by a perception-decision architecture. Cantor first acts as a decision generator and integrates visual inputs to analyze the image and problem, ensuring a closer alignment with the actual context. Furthermore, Cantor leverages the advanced cognitive functions of MLLMs to perform as multifaceted experts for deriving higher-level information, enhancing the CoT generation process. Our extensive experiments demonstrate the efficacy of the proposed framework, showing significant improvements in multimodal CoT performance across two complex visual reasoning datasets, without necessitating fine-tuning or ground-truth rationales. Project Page: https://ggg0919.github.io/cantor/ .
CutDiffusion: A Simple, Fast, Cheap, and Strong Diffusion Extrapolation Method
Apr 23, 2024Transforming large pre-trained low-resolution diffusion models to cater to higher-resolution demands, i.e., diffusion extrapolation, significantly improves diffusion adaptability. We propose tuning-free CutDiffusion, aimed at simplifying and accelerating the diffusion extrapolation process, making it more affordable and improving performance. CutDiffusion abides by the existing patch-wise extrapolation but cuts a standard patch diffusion process into an initial phase focused on comprehensive structure denoising and a subsequent phase dedicated to specific detail refinement. Comprehensive experiments highlight the numerous almighty advantages of CutDiffusion: (1) simple method construction that enables a concise higher-resolution diffusion process without third-party engagement; (2) fast inference speed achieved through a single-step higher-resolution diffusion process, and fewer inference patches required; (3) cheap GPU cost resulting from patch-wise inference and fewer patches during the comprehensive structure denoising; (4) strong generation performance, stemming from the emphasis on specific detail refinement.
Multi-Modal Prompt Learning on Blind Image Quality Assessment
Apr 23, 2024Image Quality Assessment (IQA) models benefit significantly from semantic information, which allows them to treat different types of objects distinctly. Currently, leveraging semantic information to enhance IQA is a crucial research direction. Traditional methods, hindered by a lack of sufficiently annotated data, have employed the CLIP image-text pretraining model as their backbone to gain semantic awareness. However, the generalist nature of these pre-trained Vision-Language (VL) models often renders them suboptimal for IQA-specific tasks. Recent approaches have attempted to address this mismatch using prompt technology, but these solutions have shortcomings. Existing prompt-based VL models overly focus on incremental semantic information from text, neglecting the rich insights available from visual data analysis. This imbalance limits their performance improvements in IQA tasks. This paper introduces an innovative multi-modal prompt-based methodology for IQA. Our approach employs carefully crafted prompts that synergistically mine incremental semantic information from both visual and linguistic data. Specifically, in the visual branch, we introduce a multi-layer prompt structure to enhance the VL model's adaptability. In the text branch, we deploy a dual-prompt scheme that steers the model to recognize and differentiate between scene category and distortion type, thereby refining the model's capacity to assess image quality. Our experimental findings underscore the effectiveness of our method over existing Blind Image Quality Assessment (BIQA) approaches. Notably, it demonstrates competitive performance across various datasets. Our method achieves Spearman Rank Correlation Coefficient (SRCC) values of 0.961(surpassing 0.946 in CSIQ) and 0.941 (exceeding 0.930 in KADID), illustrating its robustness and accuracy in diverse contexts.
NeRF-DetS: Enhancing Multi-View 3D Object Detection with Sampling-adaptive Network of Continuous NeRF-based Representation
Apr 22, 2024As a preliminary work, NeRF-Det unifies the tasks of novel view synthesis and 3D perception, demonstrating that perceptual tasks can benefit from novel view synthesis methods like NeRF, significantly improving the performance of indoor multi-view 3D object detection. Using the geometry MLP of NeRF to direct the attention of detection head to crucial parts and incorporating self-supervised loss from novel view rendering contribute to the achieved improvement. To better leverage the notable advantages of the continuous representation through neural rendering in space, we introduce a novel 3D perception network structure, NeRF-DetS. The key component of NeRF-DetS is the Multi-level Sampling-Adaptive Network, making the sampling process adaptively from coarse to fine. Also, we propose a superior multi-view information fusion method, known as Multi-head Weighted Fusion. This fusion approach efficiently addresses the challenge of losing multi-view information when using arithmetic mean, while keeping low computational costs. NeRF-DetS outperforms competitive NeRF-Det on the ScanNetV2 dataset, by achieving +5.02% and +5.92% improvement in mAP@.25 and mAP@.50, respectively.
DiffusionFace: Towards a Comprehensive Dataset for Diffusion-Based Face Forgery Analysis
Mar 27, 2024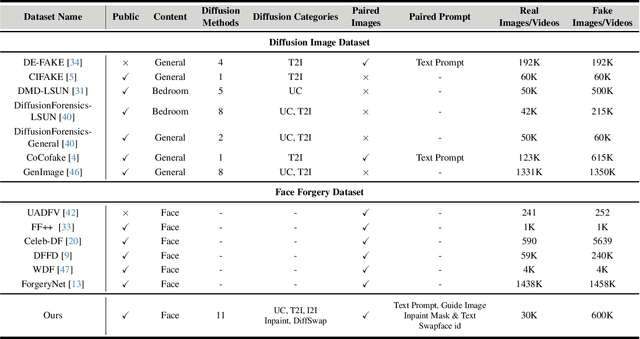

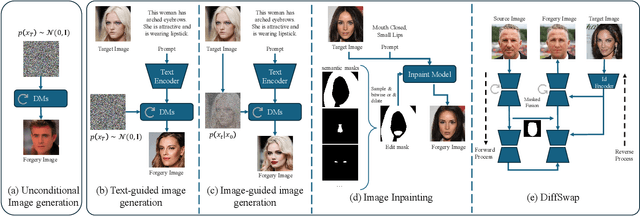
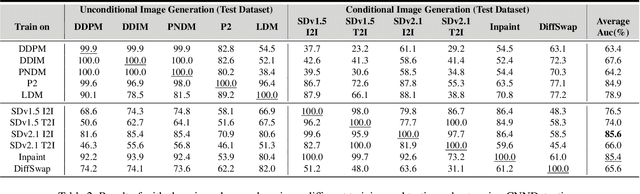
The rapid progress in deep learning has given rise to hyper-realistic facial forgery methods, leading to concerns related to misinformation and security risks. Existing face forgery datasets have limitations in generating high-quality facial images and addressing the challenges posed by evolving generative techniques. To combat this, we present DiffusionFace, the first diffusion-based face forgery dataset, covering various forgery categories, including unconditional and Text Guide facial image generation, Img2Img, Inpaint, and Diffusion-based facial exchange algorithms. Our DiffusionFace dataset stands out with its extensive collection of 11 diffusion models and the high-quality of the generated images, providing essential metadata and a real-world internet-sourced forgery facial image dataset for evaluation. Additionally, we provide an in-depth analysis of the data and introduce practical evaluation protocols to rigorously assess discriminative models' effectiveness in detecting counterfeit facial images, aiming to enhance security in facial image authentication processes. The dataset is available for download at \url{https://github.com/Rapisurazurite/DiffFace}.
DMAD: Dual Memory Bank for Real-World Anomaly Detection
Mar 19, 2024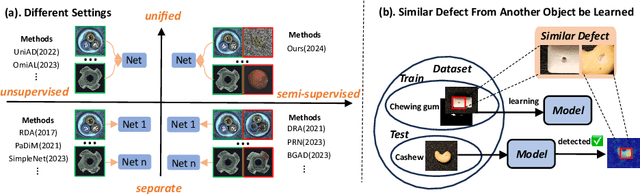
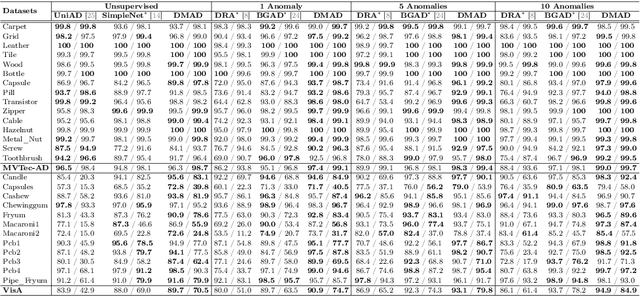
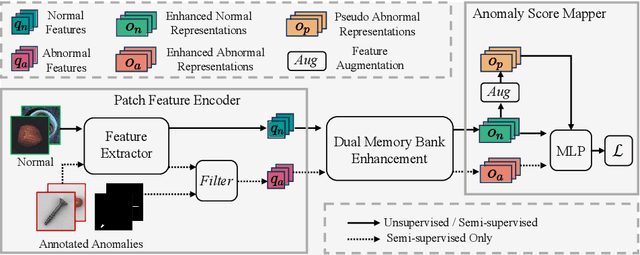

Training a unified model is considered to be more suitable for practical industrial anomaly detection scenarios due to its generalization ability and storage efficiency. However, this multi-class setting, which exclusively uses normal data, overlooks the few but important accessible annotated anomalies in the real world. To address the challenge of real-world anomaly detection, we propose a new framework named Dual Memory bank enhanced representation learning for Anomaly Detection (DMAD). This framework handles both unsupervised and semi-supervised scenarios in a unified (multi-class) setting. DMAD employs a dual memory bank to calculate feature distance and feature attention between normal and abnormal patterns, thereby encapsulating knowledge about normal and abnormal instances. This knowledge is then used to construct an enhanced representation for anomaly score learning. We evaluated DMAD on the MVTec-AD and VisA datasets. The results show that DMAD surpasses current state-of-the-art methods, highlighting DMAD's capability in handling the complexities of real-world anomaly detection scenarios.
Weakly Supervised Open-Vocabulary Object Detection
Dec 19, 2023Despite weakly supervised object detection (WSOD) being a promising step toward evading strong instance-level annotations, its capability is confined to closed-set categories within a single training dataset. In this paper, we propose a novel weakly supervised open-vocabulary object detection framework, namely WSOVOD, to extend traditional WSOD to detect novel concepts and utilize diverse datasets with only image-level annotations. To achieve this, we explore three vital strategies, including dataset-level feature adaptation, image-level salient object localization, and region-level vision-language alignment. First, we perform data-aware feature extraction to produce an input-conditional coefficient, which is leveraged into dataset attribute prototypes to identify dataset bias and help achieve cross-dataset generalization. Second, a customized location-oriented weakly supervised region proposal network is proposed to utilize high-level semantic layouts from the category-agnostic segment anything model to distinguish object boundaries. Lastly, we introduce a proposal-concept synchronized multiple-instance network, i.e., object mining and refinement with visual-semantic alignment, to discover objects matched to the text embeddings of concepts. Extensive experiments on Pascal VOC and MS COCO demonstrate that the proposed WSOVOD achieves new state-of-the-art compared with previous WSOD methods in both close-set object localization and detection tasks. Meanwhile, WSOVOD enables cross-dataset and open-vocabulary learning to achieve on-par or even better performance than well-established fully-supervised open-vocabulary object detection (FSOVOD).
A Unified Framework for 3D Point Cloud Visual Grounding
Aug 23, 2023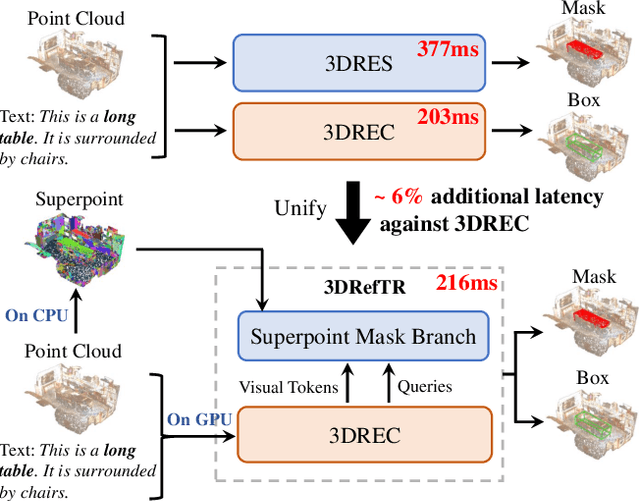
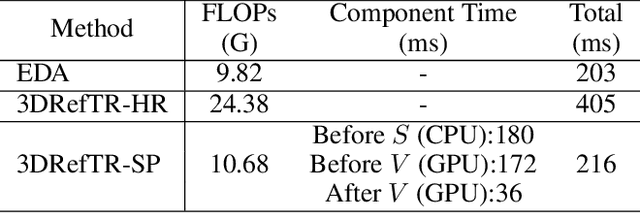
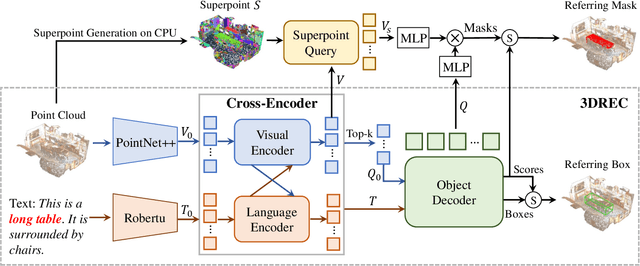
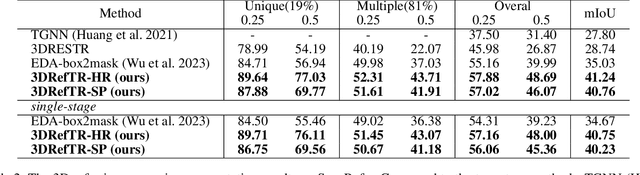
3D point cloud visual grounding plays a critical role in 3D scene comprehension, encompassing 3D referring expression comprehension (3DREC) and segmentation (3DRES). We argue that 3DREC and 3DRES should be unified in one framework, which is also a natural progression in the community. To explain, 3DREC can help 3DRES locate the referent, while 3DRES can also facilitate 3DREC via more finegrained language-visual alignment. To achieve this, this paper takes the initiative step to integrate 3DREC and 3DRES into a unified framework, termed 3D Referring Transformer (3DRefTR). Its key idea is to build upon a mature 3DREC model and leverage ready query embeddings and visual tokens from the 3DREC model to construct a dedicated mask branch. Specially, we propose Superpoint Mask Branch, which serves a dual purpose: i) By leveraging the heterogeneous CPU-GPU parallelism, while the GPU is occupied generating visual tokens, the CPU concurrently produces superpoints, equivalently accomplishing the upsampling computation; ii) By harnessing on the inherent association between the superpoints and point cloud, it eliminates the heavy computational overhead on the high-resolution visual features for upsampling. This elegant design enables 3DRefTR to achieve both well-performing 3DRES and 3DREC capacities with only a 6% additional latency compared to the original 3DREC model. Empirical evaluations affirm the superiority of 3DRefTR. Specifically, on the ScanRefer dataset, 3DRefTR surpasses the state-of-the-art 3DRES method by 12.43% in mIoU and improves upon the SOTA 3DREC method by 0.6% Acc@0.25IoU.
Pseudo-label Alignment for Semi-supervised Instance Segmentation
Aug 10, 2023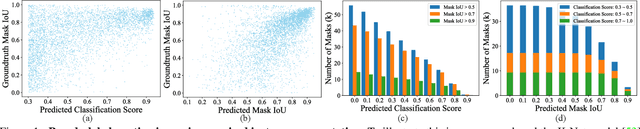
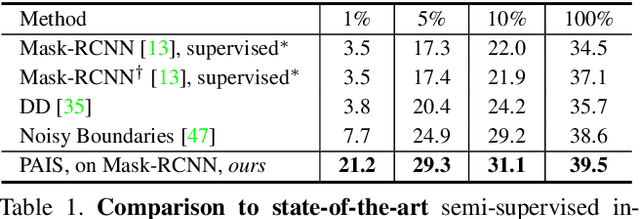
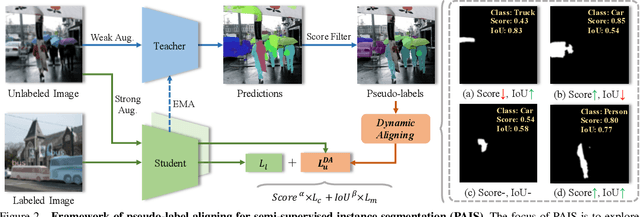
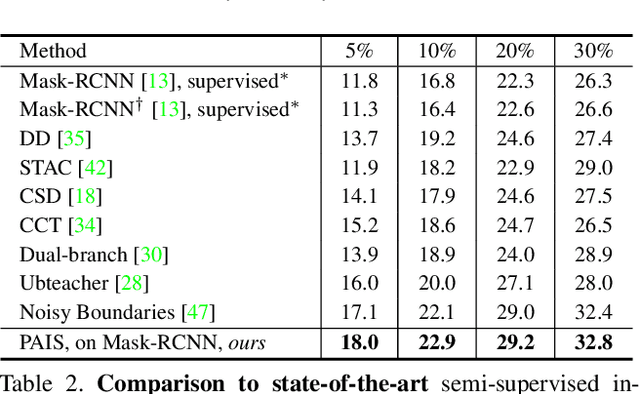
Pseudo-labeling is significant for semi-supervised instance segmentation, which generates instance masks and classes from unannotated images for subsequent training. However, in existing pipelines, pseudo-labels that contain valuable information may be directly filtered out due to mismatches in class and mask quality. To address this issue, we propose a novel framework, called pseudo-label aligning instance segmentation (PAIS), in this paper. In PAIS, we devise a dynamic aligning loss (DALoss) that adjusts the weights of semi-supervised loss terms with varying class and mask score pairs. Through extensive experiments conducted on the COCO and Cityscapes datasets, we demonstrate that PAIS is a promising framework for semi-supervised instance segmentation, particularly in cases where labeled data is severely limited. Notably, with just 1\% labeled data, PAIS achieves 21.2 mAP (based on Mask-RCNN) and 19.9 mAP (based on K-Net) on the COCO dataset, outperforming the current state-of-the-art model, \ie, NoisyBoundary with 7.7 mAP, by a margin of over 12 points. Code is available at: \url{https://github.com/hujiecpp/PAIS}.
Geometric-aware Pretraining for Vision-centric 3D Object Detection
Apr 07, 2023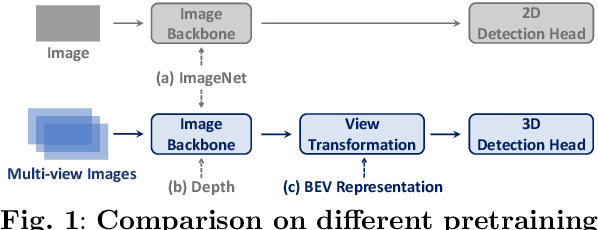
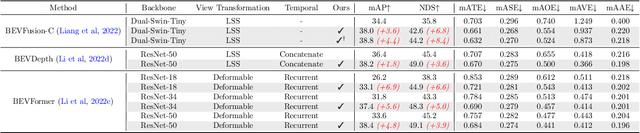
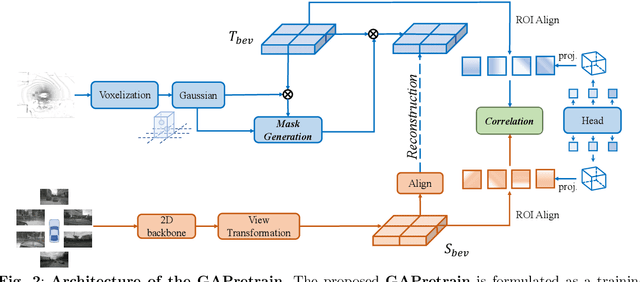
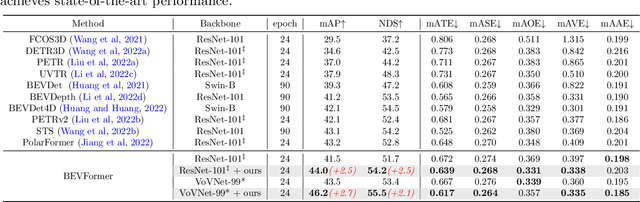
Multi-camera 3D object detection for autonomous driving is a challenging problem that has garnered notable attention from both academia and industry. An obstacle encountered in vision-based techniques involves the precise extraction of geometry-conscious features from RGB images. Recent approaches have utilized geometric-aware image backbones pretrained on depth-relevant tasks to acquire spatial information. However, these approaches overlook the critical aspect of view transformation, resulting in inadequate performance due to the misalignment of spatial knowledge between the image backbone and view transformation. To address this issue, we propose a novel geometric-aware pretraining framework called GAPretrain. Our approach incorporates spatial and structural cues to camera networks by employing the geometric-rich modality as guidance during the pretraining phase. The transference of modal-specific attributes across different modalities is non-trivial, but we bridge this gap by using a unified bird's-eye-view (BEV) representation and structural hints derived from LiDAR point clouds to facilitate the pretraining process. GAPretrain serves as a plug-and-play solution that can be flexibly applied to multiple state-of-the-art detectors. Our experiments demonstrate the effectiveness and generalization ability of the proposed method. We achieve 46.2 mAP and 55.5 NDS on the nuScenes val set using the BEVFormer method, with a gain of 2.7 and 2.1 points, respectively. We also conduct experiments on various image backbones and view transformations to validate the efficacy of our approach. Code will be released at https://github.com/OpenDriveLab/BEVPerception-Survey-Recipe.