 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiangning Zhang
MotionMaster: Training-free Camera Motion Transfer For Video Generation
May 01, 2024
The emergence of diffusion models has greatly propelled the progress in image and video generation. Recently, some efforts have been made in controllable video generation, including text-to-video generation and video motion control, among which camera motion control is an important topic. However, existing camera motion control methods rely on training a temporal camera module, and necessitate substantial computation resources due to the large amount of parameters in video generation models. Moreover, existing methods pre-define camera motion types during training, which limits their flexibility in camera control. Therefore, to reduce training costs and achieve flexible camera control, we propose COMD, a novel training-free video motion transfer model, which disentangles camera motions and object motions in source videos and transfers the extracted camera motions to new videos. We first propose a one-shot camera motion disentanglement method to extract camera motion from a single source video, which separates the moving objects from the background and estimates the camera motion in the moving objects region based on the motion in the background by solving a Poisson equation. Furthermore, we propose a few-shot camera motion disentanglement method to extract the common camera motion from multiple videos with similar camera motions, which employs a window-based clustering technique to extract the common features in temporal attention maps of multiple videos. Finally, we propose a motion combination method to combine different types of camera motions together, enabling our model a more controllable and flexible camera control. Extensive experiments demonstrate that our training-free approach can effectively decouple camera-object motion and apply the decoupled camera motion to a wide range of controllable video generation tasks, achieving flexible and diverse camera motion control.
Learning Feature Inversion for Multi-class Anomaly Detection under General-purpose COCO-AD Benchmark
Apr 16, 2024Anomaly detection (AD) is often focused on detecting anomaly areas for industrial quality inspection and medical lesion examination. However, due to the specific scenario targets, the data scale for AD is relatively small, and evaluation metrics are still deficient compared to classic vision tasks, such as object detection and semantic segmentation. To fill these gaps, this work first constructs a large-scale and general-purpose COCO-AD dataset by extending COCO to the AD field. This enables fair evaluation and sustainable development for different methods on this challenging benchmark. Moreover, current metrics such as AU-ROC have nearly reached saturation on simple datasets, which prevents a comprehensive evaluation of different methods. Inspired by the metrics in the segmentation field, we further propose several more practical threshold-dependent AD-specific metrics, ie, m$F_1$$^{.2}_{.8}$, mAcc$^{.2}_{.8}$, mIoU$^{.2}_{.8}$, and mIoU-max. Motivated by GAN inversion's high-quality reconstruction capability, we propose a simple but more powerful InvAD framework to achieve high-quality feature reconstruction. Our method improves the effectiveness of reconstruction-based methods on popular MVTec AD, VisA, and our newly proposed COCO-AD datasets under a multi-class unsupervised setting, where only a single detection model is trained to detect anomalies from different classes. Extensive ablation experiments have demonstrated the effectiveness of each component of our InvAD. Full codes and models are available at https://github.com/zhangzjn/ader.
MambaAD: Exploring State Space Models for Multi-class Unsupervised Anomaly Detection
Apr 14, 2024Recent advancements in anomaly detection have seen the efficacy of CNN- and transformer-based approaches. However, CNNs struggle with long-range dependencies, while transformers are burdened by quadratic computational complexity. Mamba-based models, with their superior long-range modeling and linear efficiency, have garnered substantial attention. This study pioneers the application of Mamba to multi-class unsupervised anomaly detection, presenting MambaAD, which consists of a pre-trained encoder and a Mamba decoder featuring (Locality-Enhanced State Space) LSS modules at multi-scales. The proposed LSS module, integrating parallel cascaded (Hybrid State Space) HSS blocks and multi-kernel convolutions operations, effectively captures both long-range and local information. The HSS block, utilizing (Hybrid Scanning) HS encoders, encodes feature maps into five scanning methods and eight directions, thereby strengthening global connections through the (State Space Model) SSM. The use of Hilbert scanning and eight directions significantly improves feature sequence modeling. Comprehensive experiments on six diverse anomaly detection datasets and seven metrics demonstrate state-of-the-art performance, substantiating the method's effectiveness.
Deepfake Generation and Detection: A Benchmark and Survey
Apr 09, 2024

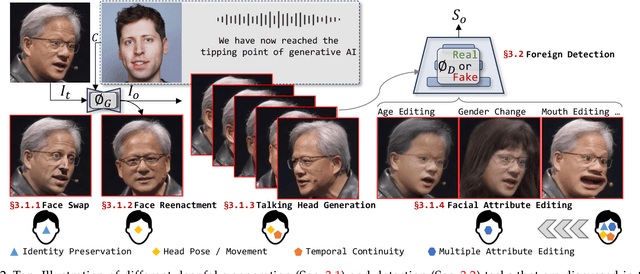

In addition to the advancements in deepfake generation, corresponding detection technologies need to continuously evolve to regulate the potential misuse of deepfakes, such as for privacy invasion and phishing attacks. This survey comprehensively reviews the latest developments in deepfake generation and detection, summarizing and analyzing the current state of the art in this rapidly evolving field. We first unify task definitions, comprehensively introduce datasets and metrics, and discuss the development of generation and detection technology frameworks. Then, we discuss the development of several related sub-fields and focus on researching four mainstream deepfake fields: popular face swap, face reenactment, talking face generation, and facial attribute editing, as well as foreign detection. Subsequently, we comprehensively benchmark representative methods on popular datasets for each field, fully evaluating the latest and influential works published in top conferences/journals. Finally, we analyze the challenges and future research directions of the discussed fields. We closely follow the latest developments in https://github.com/flyingby/Awesome-Deepfake-Generation-and-Detection.
DiffFAE: Advancing High-fidelity One-shot Facial Appearance Editing with Space-sensitive Customization and Semantic Preservation
Mar 26, 2024
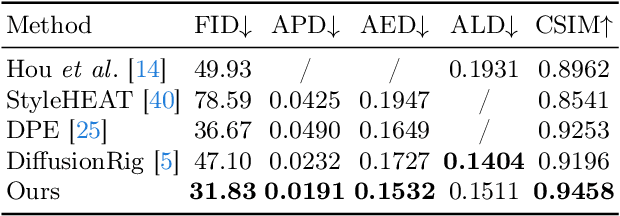
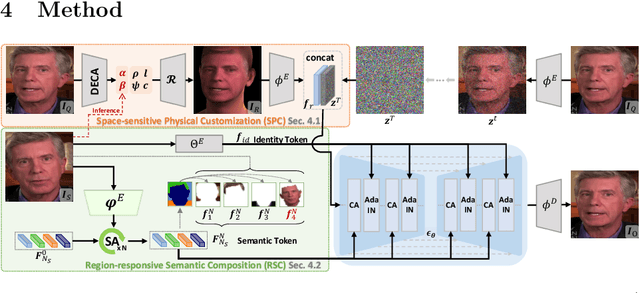

Facial Appearance Editing (FAE) aims to modify physical attributes, such as pose, expression and lighting, of human facial images while preserving attributes like identity and background, showing great importance in photograph. In spite of the great progress in this area, current researches generally meet three challenges: low generation fidelity, poor attribute preservation, and inefficient inference. To overcome above challenges, this paper presents DiffFAE, a one-stage and highly-efficient diffusion-based framework tailored for high-fidelity FAE. For high-fidelity query attributes transfer, we adopt Space-sensitive Physical Customization (SPC), which ensures the fidelity and generalization ability by utilizing rendering texture derived from 3D Morphable Model (3DMM). In order to preserve source attributes, we introduce the Region-responsive Semantic Composition (RSC). This module is guided to learn decoupled source-regarding features, thereby better preserving the identity and alleviating artifacts from non-facial attributes such as hair, clothes, and background. We further introduce a consistency regularization for our pipeline to enhance editing controllability by leveraging prior knowledge in the attention matrices of diffusion model. Extensive experiments demonstrate the superiority of DiffFAE over existing methods, achieving state-of-the-art performance in facial appearance editing.
DMAD: Dual Memory Bank for Real-World Anomaly Detection
Mar 19, 2024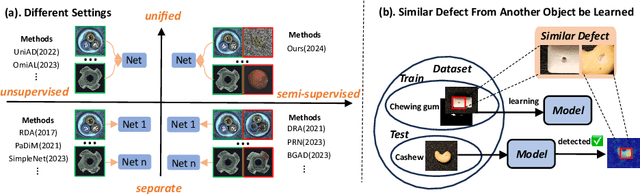
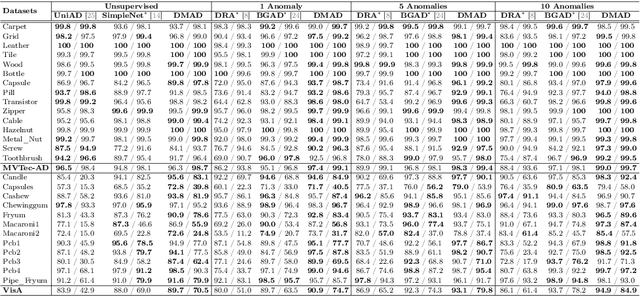
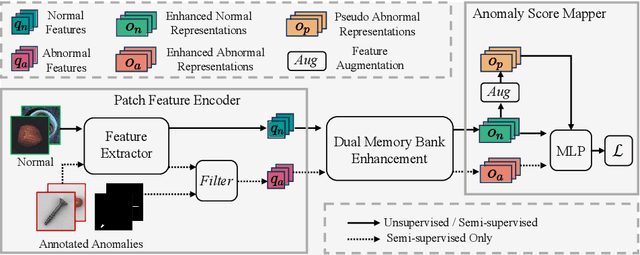

Training a unified model is considered to be more suitable for practical industrial anomaly detection scenarios due to its generalization ability and storage efficiency. However, this multi-class setting, which exclusively uses normal data, overlooks the few but important accessible annotated anomalies in the real world. To address the challenge of real-world anomaly detection, we propose a new framework named Dual Memory bank enhanced representation learning for Anomaly Detection (DMAD). This framework handles both unsupervised and semi-supervised scenarios in a unified (multi-class) setting. DMAD employs a dual memory bank to calculate feature distance and feature attention between normal and abnormal patterns, thereby encapsulating knowledge about normal and abnormal instances. This knowledge is then used to construct an enhanced representation for anomaly score learning. We evaluated DMAD on the MVTec-AD and VisA datasets. The results show that DMAD surpasses current state-of-the-art methods, highlighting DMAD's capability in handling the complexities of real-world anomaly detection scenarios.
TexDreamer: Towards Zero-Shot High-Fidelity 3D Human Texture Generation
Mar 19, 2024
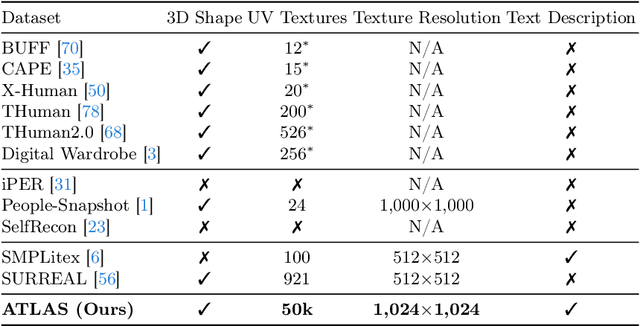
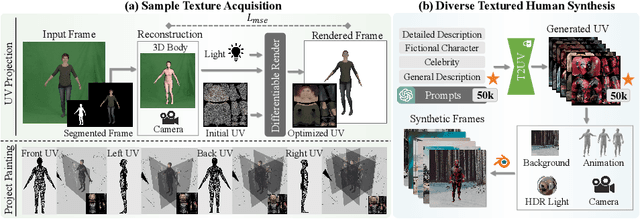
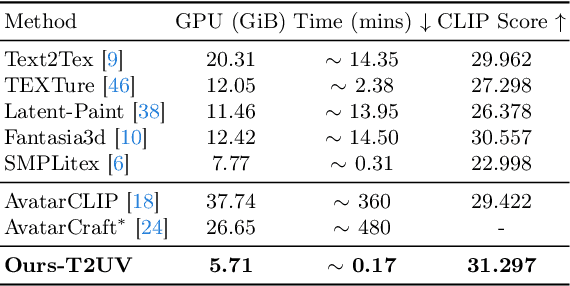
Texturing 3D humans with semantic UV maps remains a challenge due to the difficulty of acquiring reasonably unfolded UV. Despite recent text-to-3D advancements in supervising multi-view renderings using large text-to-image (T2I) models, issues persist with generation speed, text consistency, and texture quality, resulting in data scarcity among existing datasets. We present TexDreamer, the first zero-shot multimodal high-fidelity 3D human texture generation model. Utilizing an efficient texture adaptation finetuning strategy, we adapt large T2I model to a semantic UV structure while preserving its original generalization capability. Leveraging a novel feature translator module, the trained model is capable of generating high-fidelity 3D human textures from either text or image within seconds. Furthermore, we introduce ArTicuLated humAn textureS (ATLAS), the largest high-resolution (1024 X 1024) 3D human texture dataset which contains 50k high-fidelity textures with text descriptions.
Explore In-Context Segmentation via Latent Diffusion Models
Mar 14, 2024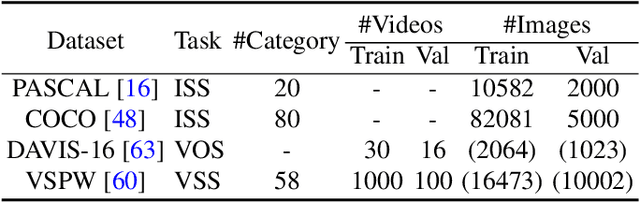
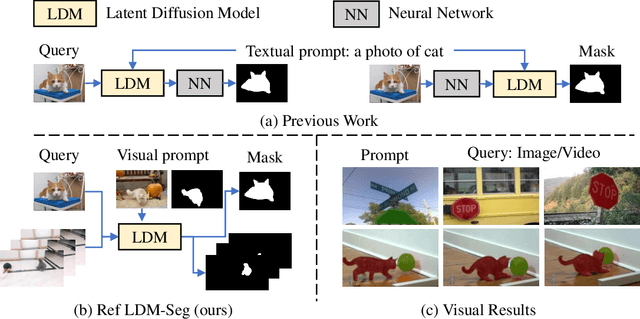

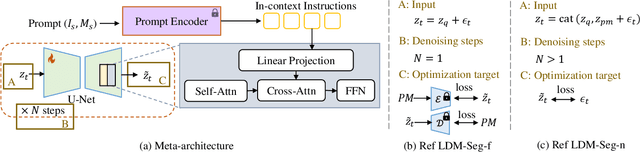
In-context segmentation has drawn more attention with the introduction of vision foundation models. Most existing approaches adopt metric learning or masked image modeling to build the correlation between visual prompts and input image queries. In this work, we explore this problem from a new perspective, using one representative generation model, the latent diffusion model (LDM). We observe a task gap between generation and segmentation in diffusion models, but LDM is still an effective minimalist for in-context segmentation. In particular, we propose two meta-architectures and correspondingly design several output alignment and optimization strategies. We have conducted comprehensive ablation studies and empirically found that the segmentation quality counts on output alignment and in-context instructions. Moreover, we build a new and fair in-context segmentation benchmark that includes both image and video datasets. Experiments validate the efficiency of our approach, demonstrating comparable or even stronger results than previous specialist models or visual foundation models. Our study shows that LDMs can also achieve good enough results for challenging in-context segmentation tasks.
PointSeg: A Training-Free Paradigm for 3D Scene Segmentation via Foundation Models
Mar 11, 2024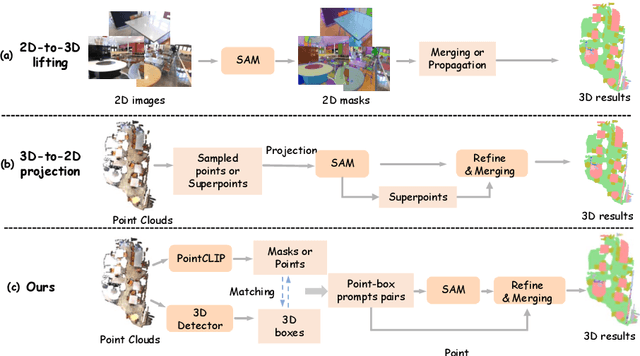
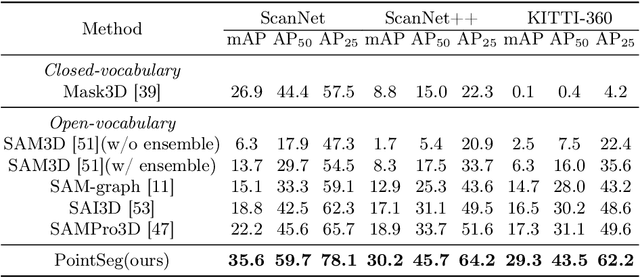
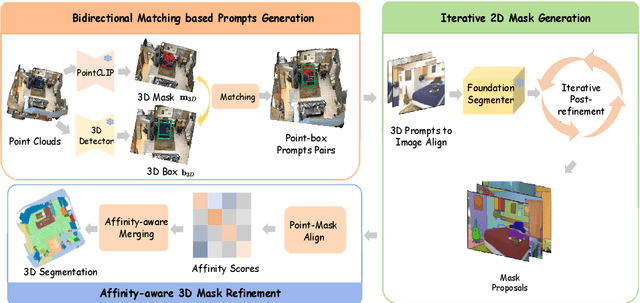
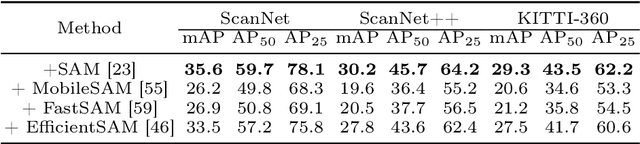
Recent success of vision foundation models have shown promising performance for the 2D perception tasks. However, it is difficult to train a 3D foundation network directly due to the limited dataset and it remains under explored whether existing foundation models can be lifted to 3D space seamlessly. In this paper, we present PointSeg, a novel training-free paradigm that leverages off-the-shelf vision foundation models to address 3D scene perception tasks. PointSeg can segment anything in 3D scene by acquiring accurate 3D prompts to align their corresponding pixels across frames. Concretely, we design a two-branch prompts learning structure to construct the 3D point-box prompts pairs, combining with the bidirectional matching strategy for accurate point and proposal prompts generation. Then, we perform the iterative post-refinement adaptively when cooperated with different vision foundation models. Moreover, we design a affinity-aware merging algorithm to improve the final ensemble masks. PointSeg demonstrates impressive segmentation performance across various datasets, all without training. Specifically, our approach significantly surpasses the state-of-the-art specialist model by 13.4$\%$, 11.3$\%$, and 12$\%$ mAP on ScanNet, ScanNet++, and KITTI-360 datasets, respectively. On top of that, PointSeg can incorporate with various segmentation models and even surpasses the supervised methods.
Dual-path Frequency Discriminators for Few-shot Anomaly Detection
Mar 11, 2024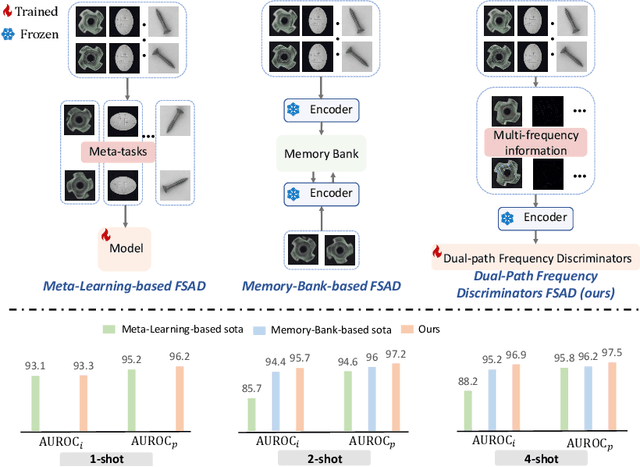
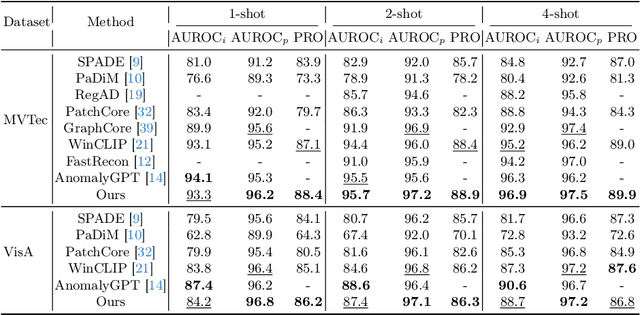
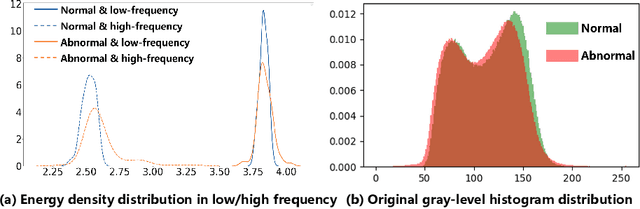
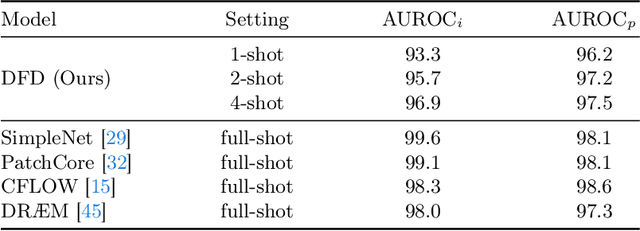
Few-shot anomaly detection (FSAD) is essential in industrial manufacturing. However, existing FSAD methods struggle to effectively leverage a limited number of normal samples, and they may fail to detect and locate inconspicuous anomalies in the spatial domain. We further discover that these subtle anomalies would be more noticeable in the frequency domain. In this paper, we propose a Dual-Path Frequency Discriminators (DFD) network from a frequency perspective to tackle these issues. Specifically, we generate anomalies at both image-level and feature-level. Differential frequency components are extracted by the multi-frequency information construction module and supplied into the fine-grained feature construction module to provide adapted features. We consider anomaly detection as a discriminative classification problem, wherefore the dual-path feature discrimination module is employed to detect and locate the image-level and feature-level anomalies in the feature space. The discriminators aim to learn a joint representation of anomalous features and normal features in the latent space. Extensive experiments conducted on MVTec AD and VisA benchmarks demonstrate that our DFD surpasses current state-of-the-art methods. Source code will be available.