 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYabiao Wang
Single-temporal Supervised Remote Change Detection for Domain Generalization
Apr 19, 2024
Change detection is widely applied in remote sensing image analysis. Existing methods require training models separately for each dataset, which leads to poor domain generalization. Moreover, these methods rely heavily on large amounts of high-quality pair-labelled data for training, which is expensive and impractical. In this paper, we propose a multimodal contrastive learning (ChangeCLIP) based on visual-language pre-training for change detection domain generalization. Additionally, we propose a dynamic context optimization for prompt learning. Meanwhile, to address the data dependency issue of existing methods, we introduce a single-temporal and controllable AI-generated training strategy (SAIN). This allows us to train the model using a large number of single-temporal images without image pairs in the real world, achieving excellent generalization. Extensive experiments on series of real change detection datasets validate the superiority and strong generalization of ChangeCLIP, outperforming state-of-the-art change detection methods. Code will be available.
Leveraging Fine-Grained Information and Noise Decoupling for Remote Sensing Change Detection
Apr 17, 2024Change detection aims to identify remote sense object changes by analyzing data between bitemporal image pairs. Due to the large temporal and spatial span of data collection in change detection image pairs, there are often a significant amount of task-specific and task-agnostic noise. Previous effort has focused excessively on denoising, with this goes a great deal of loss of fine-grained information. In this paper, we revisit the importance of fine-grained features in change detection and propose a series of operations for fine-grained information compensation and noise decoupling (FINO). First, the context is utilized to compensate for the fine-grained information in the feature space. Next, a shape-aware and a brightness-aware module are designed to improve the capacity for representation learning. The shape-aware module guides the backbone for more precise shape estimation, guiding the backbone network in extracting object shape features. The brightness-aware module learns a overall brightness estimation to improve the model's robustness to task-agnostic noise. Finally, a task-specific noise decoupling structure is designed as a way to improve the model's ability to separate noise interference from feature similarity. With these training schemes, our proposed method achieves new state-of-the-art (SOTA) results in multiple change detection benchmarks. The code will be made available.
DMAD: Dual Memory Bank for Real-World Anomaly Detection
Mar 19, 2024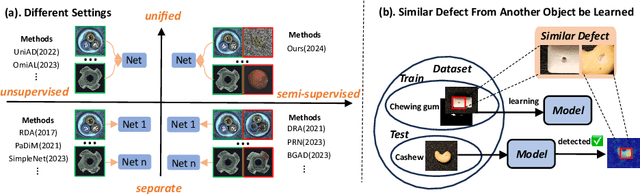
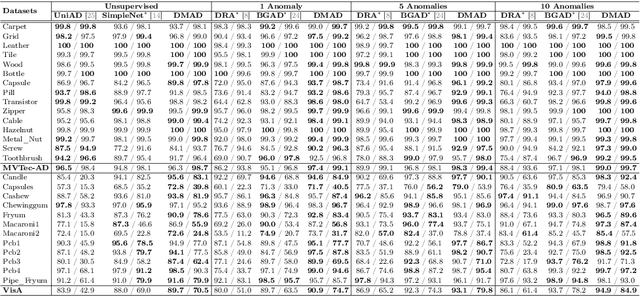
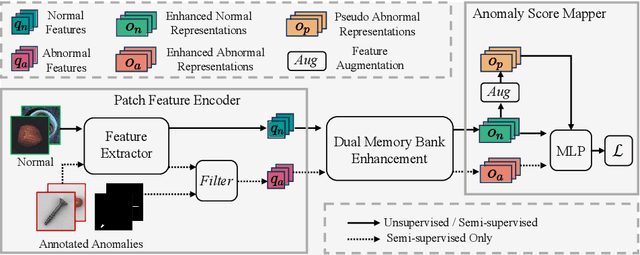

Training a unified model is considered to be more suitable for practical industrial anomaly detection scenarios due to its generalization ability and storage efficiency. However, this multi-class setting, which exclusively uses normal data, overlooks the few but important accessible annotated anomalies in the real world. To address the challenge of real-world anomaly detection, we propose a new framework named Dual Memory bank enhanced representation learning for Anomaly Detection (DMAD). This framework handles both unsupervised and semi-supervised scenarios in a unified (multi-class) setting. DMAD employs a dual memory bank to calculate feature distance and feature attention between normal and abnormal patterns, thereby encapsulating knowledge about normal and abnormal instances. This knowledge is then used to construct an enhanced representation for anomaly score learning. We evaluated DMAD on the MVTec-AD and VisA datasets. The results show that DMAD surpasses current state-of-the-art methods, highlighting DMAD's capability in handling the complexities of real-world anomaly detection scenarios.
Learning Unified Reference Representation for Unsupervised Multi-class Anomaly Detection
Mar 18, 2024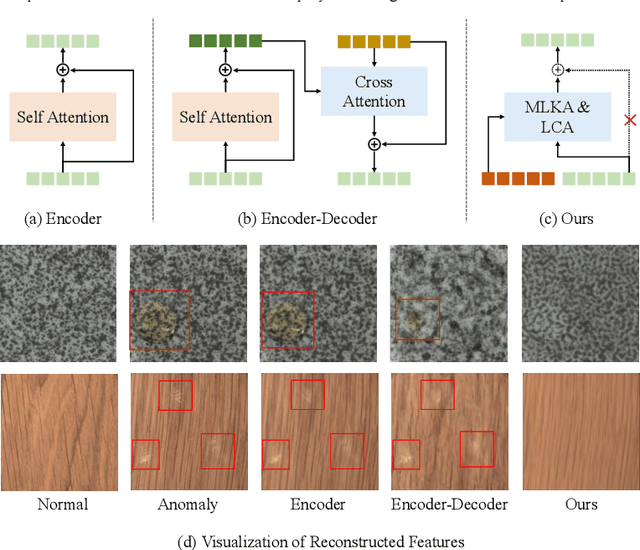
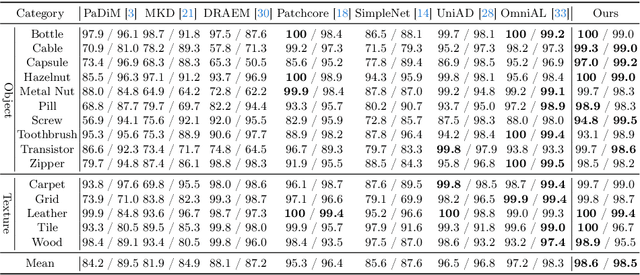
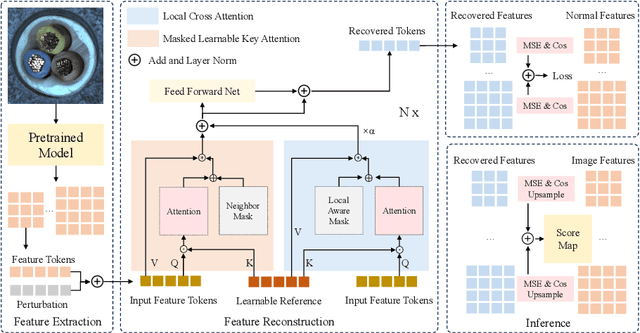
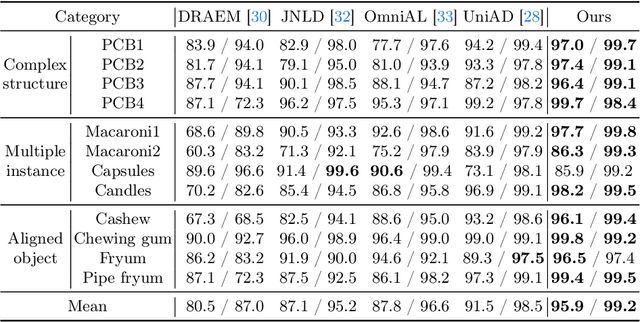
In the field of multi-class anomaly detection, reconstruction-based methods derived from single-class anomaly detection face the well-known challenge of ``learning shortcuts'', wherein the model fails to learn the patterns of normal samples as it should, opting instead for shortcuts such as identity mapping or artificial noise elimination. Consequently, the model becomes unable to reconstruct genuine anomalies as normal instances, resulting in a failure of anomaly detection. To counter this issue, we present a novel unified feature reconstruction-based anomaly detection framework termed RLR (Reconstruct features from a Learnable Reference representation). Unlike previous methods, RLR utilizes learnable reference representations to compel the model to learn normal feature patterns explicitly, thereby prevents the model from succumbing to the ``learning shortcuts'' issue. Additionally, RLR incorporates locality constraints into the learnable reference to facilitate more effective normal pattern capture and utilizes a masked learnable key attention mechanism to enhance robustness. Evaluation of RLR on the 15-category MVTec-AD dataset and the 12-category VisA dataset shows superior performance compared to state-of-the-art methods under the unified setting. The code of RLR will be publicly available.
Dual-path Frequency Discriminators for Few-shot Anomaly Detection
Mar 11, 2024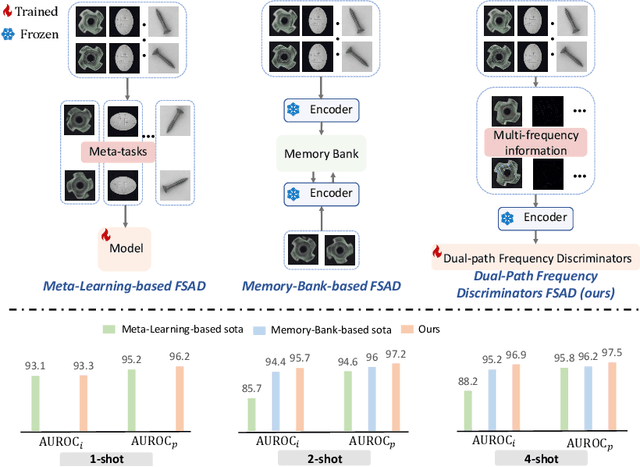
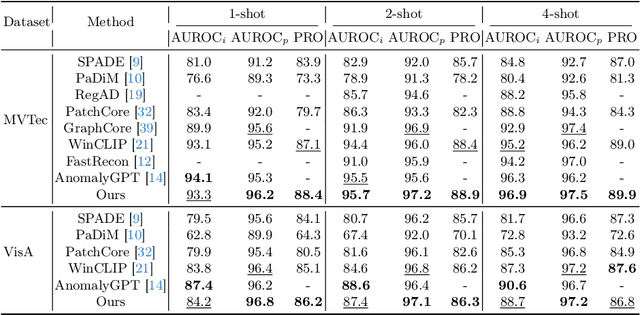
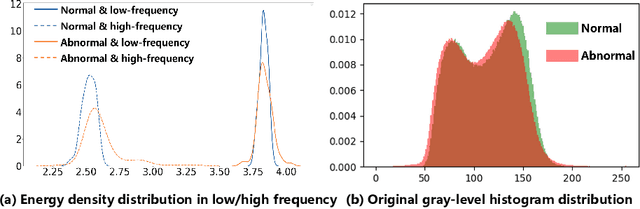
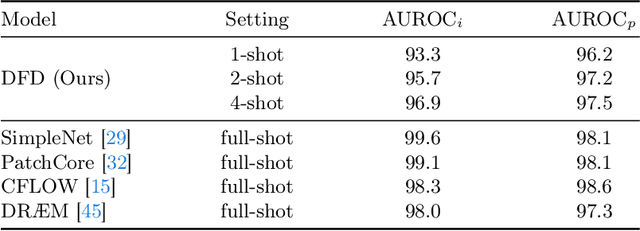
Few-shot anomaly detection (FSAD) is essential in industrial manufacturing. However, existing FSAD methods struggle to effectively leverage a limited number of normal samples, and they may fail to detect and locate inconspicuous anomalies in the spatial domain. We further discover that these subtle anomalies would be more noticeable in the frequency domain. In this paper, we propose a Dual-Path Frequency Discriminators (DFD) network from a frequency perspective to tackle these issues. Specifically, we generate anomalies at both image-level and feature-level. Differential frequency components are extracted by the multi-frequency information construction module and supplied into the fine-grained feature construction module to provide adapted features. We consider anomaly detection as a discriminative classification problem, wherefore the dual-path feature discrimination module is employed to detect and locate the image-level and feature-level anomalies in the feature space. The discriminators aim to learn a joint representation of anomalous features and normal features in the latent space. Extensive experiments conducted on MVTec AD and VisA benchmarks demonstrate that our DFD surpasses current state-of-the-art methods. Source code will be available.
PointSeg: A Training-Free Paradigm for 3D Scene Segmentation via Foundation Models
Mar 11, 2024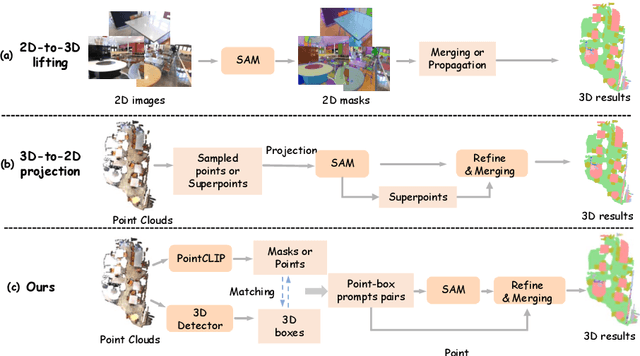
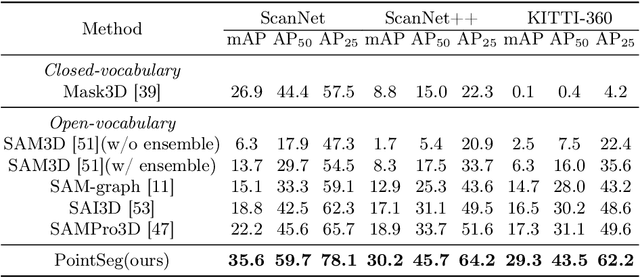
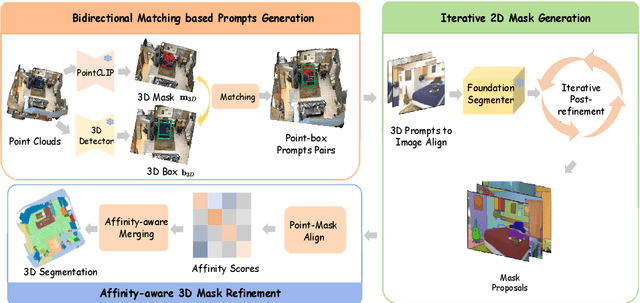
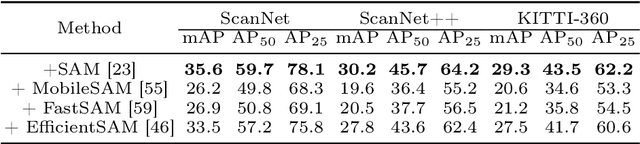
Recent success of vision foundation models have shown promising performance for the 2D perception tasks. However, it is difficult to train a 3D foundation network directly due to the limited dataset and it remains under explored whether existing foundation models can be lifted to 3D space seamlessly. In this paper, we present PointSeg, a novel training-free paradigm that leverages off-the-shelf vision foundation models to address 3D scene perception tasks. PointSeg can segment anything in 3D scene by acquiring accurate 3D prompts to align their corresponding pixels across frames. Concretely, we design a two-branch prompts learning structure to construct the 3D point-box prompts pairs, combining with the bidirectional matching strategy for accurate point and proposal prompts generation. Then, we perform the iterative post-refinement adaptively when cooperated with different vision foundation models. Moreover, we design a affinity-aware merging algorithm to improve the final ensemble masks. PointSeg demonstrates impressive segmentation performance across various datasets, all without training. Specifically, our approach significantly surpasses the state-of-the-art specialist model by 13.4$\%$, 11.3$\%$, and 12$\%$ mAP on ScanNet, ScanNet++, and KITTI-360 datasets, respectively. On top of that, PointSeg can incorporate with various segmentation models and even surpasses the supervised methods.
UniM-OV3D: Uni-Modality Open-Vocabulary 3D Scene Understanding with Fine-Grained Feature Representation
Jan 31, 20243D open-vocabulary scene understanding aims to recognize arbitrary novel categories beyond the base label space. However, existing works not only fail to fully utilize all the available modal information in the 3D domain but also lack sufficient granularity in representing the features of each modality. In this paper, we propose a unified multimodal 3D open-vocabulary scene understanding network, namely UniM-OV3D, which aligns point clouds with image, language and depth. To better integrate global and local features of the point clouds, we design a hierarchical point cloud feature extraction module that learns comprehensive fine-grained feature representations. Further, to facilitate the learning of coarse-to-fine point-semantic representations from captions, we propose the utilization of hierarchical 3D caption pairs, capitalizing on geometric constraints across various viewpoints of 3D scenes. Extensive experimental results demonstrate the effectiveness and superiority of our method in open-vocabulary semantic and instance segmentation, which achieves state-of-the-art performance on both indoor and outdoor benchmarks such as ScanNet, ScanNet200, S3IDS and nuScenes. Code is available at https://github.com/hithqd/UniM-OV3D.
Self-supervised Feature Adaptation for 3D Industrial Anomaly Detection
Jan 17, 2024Industrial anomaly detection is generally addressed as an unsupervised task that aims at locating defects with only normal training samples. Recently, numerous 2D anomaly detection methods have been proposed and have achieved promising results, however, using only the 2D RGB data as input is not sufficient to identify imperceptible geometric surface anomalies. Hence, in this work, we focus on multi-modal anomaly detection. Specifically, we investigate early multi-modal approaches that attempted to utilize models pre-trained on large-scale visual datasets, i.e., ImageNet, to construct feature databases. And we empirically find that directly using these pre-trained models is not optimal, it can either fail to detect subtle defects or mistake abnormal features as normal ones. This may be attributed to the domain gap between target industrial data and source data.Towards this problem, we propose a Local-to-global Self-supervised Feature Adaptation (LSFA) method to finetune the adaptors and learn task-oriented representation toward anomaly detection.Both intra-modal adaptation and cross-modal alignment are optimized from a local-to-global perspective in LSFA to ensure the representation quality and consistency in the inference stage.Extensive experiments demonstrate that our method not only brings a significant performance boost to feature embedding based approaches, but also outperforms previous State-of-The-Art (SoTA) methods prominently on both MVTec-3D AD and Eyecandies datasets, e.g., LSFA achieves 97.1% I-AUROC on MVTec-3D, surpass previous SoTA by +3.4%.
Density Matters: Improved Core-set for Active Domain Adaptive Segmentation
Dec 15, 2023Active domain adaptation has emerged as a solution to balance the expensive annotation cost and the performance of trained models in semantic segmentation. However, existing works usually ignore the correlation between selected samples and its local context in feature space, which leads to inferior usage of annotation budgets. In this work, we revisit the theoretical bound of the classical Core-set method and identify that the performance is closely related to the local sample distribution around selected samples. To estimate the density of local samples efficiently, we introduce a local proxy estimator with Dynamic Masked Convolution and develop a Density-aware Greedy algorithm to optimize the bound. Extensive experiments demonstrate the superiority of our approach. Moreover, with very few labels, our scheme achieves comparable performance to the fully supervised counterpart.
Exploring Plain ViT Reconstruction for Multi-class Unsupervised Anomaly Detection
Dec 12, 2023This work studies the recently proposed challenging and practical Multi-class Unsupervised Anomaly Detection (MUAD) task, which only requires normal images for training while simultaneously testing both normal/anomaly images for multiple classes. Existing reconstruction-based methods typically adopt pyramid networks as encoders/decoders to obtain multi-resolution features, accompanied by elaborate sub-modules with heavier handcraft engineering designs for more precise localization. In contrast, a plain Vision Transformer (ViT) with simple architecture has been shown effective in multiple domains, which is simpler, more effective, and elegant. Following this spirit, this paper explores plain ViT architecture for MUAD. Specifically, we abstract a Meta-AD concept by inducing current reconstruction-based methods. Then, we instantiate a novel and elegant plain ViT-based symmetric ViTAD structure, effectively designed step by step from three macro and four micro perspectives. In addition, this paper reveals several interesting findings for further exploration. Finally, we propose a comprehensive and fair evaluation benchmark on eight metrics for the MUAD task. Based on a naive training recipe, ViTAD achieves state-of-the-art (SoTA) results and efficiency on the MVTec AD and VisA datasets without bells and whistles, obtaining 85.4 mAD that surpasses SoTA UniAD by +3.0, and only requiring 1.1 hours and 2.3G GPU memory to complete model training by a single V100 GPU. Source code, models, and more results are available at https://zhangzjn.github.io/projects/ViTAD.