 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLizhuang Ma
DGMamba: Domain Generalization via Generalized State Space Model
Apr 11, 2024
Domain generalization~(DG) aims at solving distribution shift problems in various scenes. Existing approaches are based on Convolution Neural Networks (CNNs) or Vision Transformers (ViTs), which suffer from limited receptive fields or quadratic complexities issues. Mamba, as an emerging state space model (SSM), possesses superior linear complexity and global receptive fields. Despite this, it can hardly be applied to DG to address distribution shifts, due to the hidden state issues and inappropriate scan mechanisms. In this paper, we propose a novel framework for DG, named DGMamba, that excels in strong generalizability toward unseen domains and meanwhile has the advantages of global receptive fields, and efficient linear complexity. Our DGMamba compromises two core components: Hidden State Suppressing~(HSS) and Semantic-aware Patch refining~(SPR). In particular, HSS is introduced to mitigate the influence of hidden states associated with domain-specific features during output prediction. SPR strives to encourage the model to concentrate more on objects rather than context, consisting of two designs: Prior-Free Scanning~(PFS), and Domain Context Interchange~(DCI). Concretely, PFS aims to shuffle the non-semantic patches within images, creating more flexible and effective sequences from images, and DCI is designed to regularize Mamba with the combination of mismatched non-semantic and semantic information by fusing patches among domains. Extensive experiments on four commonly used DG benchmarks demonstrate that the proposed DGMamba achieves remarkably superior results to state-of-the-art models. The code will be made publicly available.
Learning Topology Uniformed Face Mesh by Volume Rendering for Multi-view Reconstruction
Apr 08, 2024Face meshes in consistent topology serve as the foundation for many face-related applications, such as 3DMM constrained face reconstruction and expression retargeting. Traditional methods commonly acquire topology uniformed face meshes by two separate steps: multi-view stereo (MVS) to reconstruct shapes followed by non-rigid registration to align topology, but struggles with handling noise and non-lambertian surfaces. Recently neural volume rendering techniques have been rapidly evolved and shown great advantages in 3D reconstruction or novel view synthesis. Our goal is to leverage the superiority of neural volume rendering into multi-view reconstruction of face mesh with consistent topology. We propose a mesh volume rendering method that enables directly optimizing mesh geometry while preserving topology, and learning implicit features to model complex facial appearance from multi-view images. The key innovation lies in spreading sparse mesh features into the surrounding space to simulate radiance field required for volume rendering, which facilitates backpropagation of gradients from images to mesh geometry and implicit appearance features. Our proposed feature spreading module exhibits deformation invariance, enabling photorealistic rendering seamlessly after mesh editing. We conduct experiments on multi-view face image dataset to evaluate the reconstruction and implement an application for photorealistic rendering of animated face mesh.
PromptAD: Learning Prompts with only Normal Samples for Few-Shot Anomaly Detection
Apr 08, 2024The vision-language model has brought great improvement to few-shot industrial anomaly detection, which usually needs to design of hundreds of prompts through prompt engineering. For automated scenarios, we first use conventional prompt learning with many-class paradigm as the baseline to automatically learn prompts but found that it can not work well in one-class anomaly detection. To address the above problem, this paper proposes a one-class prompt learning method for few-shot anomaly detection, termed PromptAD. First, we propose semantic concatenation which can transpose normal prompts into anomaly prompts by concatenating normal prompts with anomaly suffixes, thus constructing a large number of negative samples used to guide prompt learning in one-class setting. Furthermore, to mitigate the training challenge caused by the absence of anomaly images, we introduce the concept of explicit anomaly margin, which is used to explicitly control the margin between normal prompt features and anomaly prompt features through a hyper-parameter. For image-level/pixel-level anomaly detection, PromptAD achieves first place in 11/12 few-shot settings on MVTec and VisA.
SDPose: Tokenized Pose Estimation via Circulation-Guide Self-Distillation
Apr 04, 2024Recently, transformer-based methods have achieved state-of-the-art prediction quality on human pose estimation(HPE). Nonetheless, most of these top-performing transformer-based models are too computation-consuming and storage-demanding to deploy on edge computing platforms. Those transformer-based models that require fewer resources are prone to under-fitting due to their smaller scale and thus perform notably worse than their larger counterparts. Given this conundrum, we introduce SDPose, a new self-distillation method for improving the performance of small transformer-based models. To mitigate the problem of under-fitting, we design a transformer module named Multi-Cycled Transformer(MCT) based on multiple-cycled forwards to more fully exploit the potential of small model parameters. Further, in order to prevent the additional inference compute-consuming brought by MCT, we introduce a self-distillation scheme, extracting the knowledge from the MCT module to a naive forward model. Specifically, on the MSCOCO validation dataset, SDPose-T obtains 69.7% mAP with 4.4M parameters and 1.8 GFLOPs. Furthermore, SDPose-S-V2 obtains 73.5% mAP on the MSCOCO validation dataset with 6.2M parameters and 4.7 GFLOPs, achieving a new state-of-the-art among predominant tiny neural network methods. Our code is available at https://github.com/MartyrPenink/SDPose.
Test-Time Domain Generalization for Face Anti-Spoofing
Mar 28, 2024
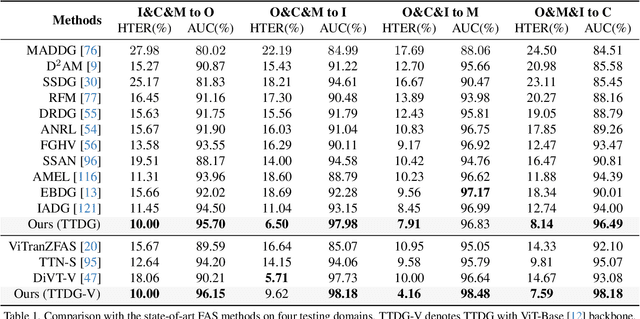
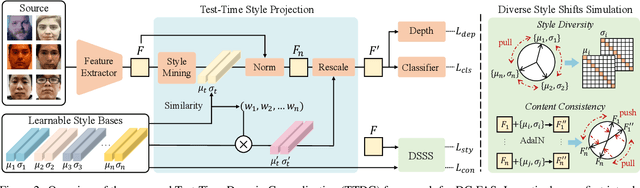

Face Anti-Spoofing (FAS) is pivotal in safeguarding facial recognition systems against presentation attacks. While domain generalization (DG) methods have been developed to enhance FAS performance, they predominantly focus on learning domain-invariant features during training, which may not guarantee generalizability to unseen data that differs largely from the source distributions. Our insight is that testing data can serve as a valuable resource to enhance the generalizability beyond mere evaluation for DG FAS. In this paper, we introduce a novel Test-Time Domain Generalization (TTDG) framework for FAS, which leverages the testing data to boost the model's generalizability. Our method, consisting of Test-Time Style Projection (TTSP) and Diverse Style Shifts Simulation (DSSS), effectively projects the unseen data to the seen domain space. In particular, we first introduce the innovative TTSP to project the styles of the arbitrarily unseen samples of the testing distribution to the known source space of the training distributions. We then design the efficient DSSS to synthesize diverse style shifts via learnable style bases with two specifically designed losses in a hyperspherical feature space. Our method eliminates the need for model updates at the test time and can be seamlessly integrated into not only the CNN but also ViT backbones. Comprehensive experiments on widely used cross-domain FAS benchmarks demonstrate our method's state-of-the-art performance and effectiveness.
Make-It-Vivid: Dressing Your Animatable Biped Cartoon Characters from Text
Mar 25, 2024Creating and animating 3D biped cartoon characters is crucial and valuable in various applications. Compared with geometry, the diverse texture design plays an important role in making 3D biped cartoon characters vivid and charming. Therefore, we focus on automatic texture design for cartoon characters based on input instructions. This is challenging for domain-specific requirements and a lack of high-quality data. To address this challenge, we propose Make-It-Vivid, the first attempt to enable high-quality texture generation from text in UV space. We prepare a detailed text-texture paired data for 3D characters by using vision-question-answering agents. Then we customize a pretrained text-to-image model to generate texture map with template structure while preserving the natural 2D image knowledge. Furthermore, to enhance fine-grained details, we propose a novel adversarial learning scheme to shorten the domain gap between original dataset and realistic texture domain. Extensive experiments show that our approach outperforms current texture generation methods, resulting in efficient character texturing and faithful generation with prompts. Besides, we showcase various applications such as out of domain generation and texture stylization. We also provide an efficient generation system for automatic text-guided textured character generation and animation.
Real-IAD: A Real-World Multi-View Dataset for Benchmarking Versatile Industrial Anomaly Detection
Mar 19, 2024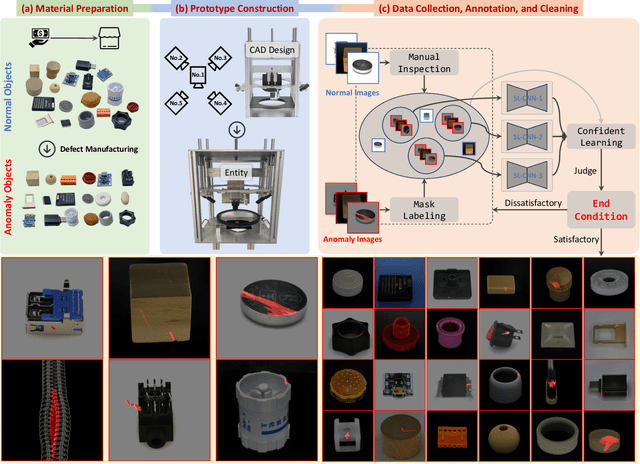
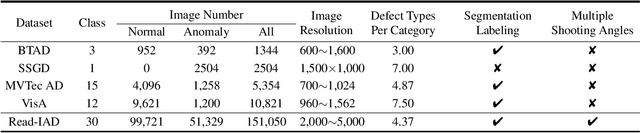
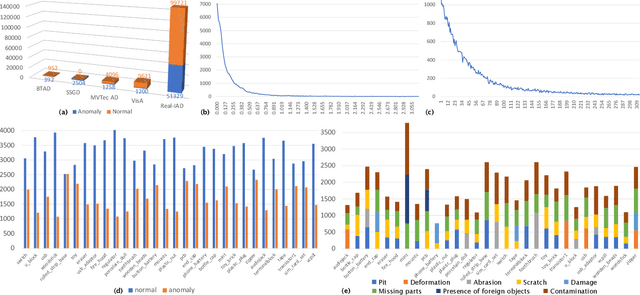
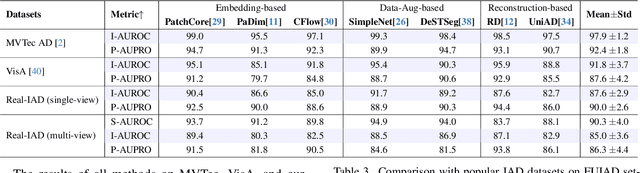
Industrial anomaly detection (IAD) has garnered significant attention and experienced rapid development. However, the recent development of IAD approach has encountered certain difficulties due to dataset limitations. On the one hand, most of the state-of-the-art methods have achieved saturation (over 99% in AUROC) on mainstream datasets such as MVTec, and the differences of methods cannot be well distinguished, leading to a significant gap between public datasets and actual application scenarios. On the other hand, the research on various new practical anomaly detection settings is limited by the scale of the dataset, posing a risk of overfitting in evaluation results. Therefore, we propose a large-scale, Real-world, and multi-view Industrial Anomaly Detection dataset, named Real-IAD, which contains 150K high-resolution images of 30 different objects, an order of magnitude larger than existing datasets. It has a larger range of defect area and ratio proportions, making it more challenging than previous datasets. To make the dataset closer to real application scenarios, we adopted a multi-view shooting method and proposed sample-level evaluation metrics. In addition, beyond the general unsupervised anomaly detection setting, we propose a new setting for Fully Unsupervised Industrial Anomaly Detection (FUIAD) based on the observation that the yield rate in industrial production is usually greater than 60%, which has more practical application value. Finally, we report the results of popular IAD methods on the Real-IAD dataset, providing a highly challenging benchmark to promote the development of the IAD field.
Exploring Safety Generalization Challenges of Large Language Models via Code
Mar 14, 2024
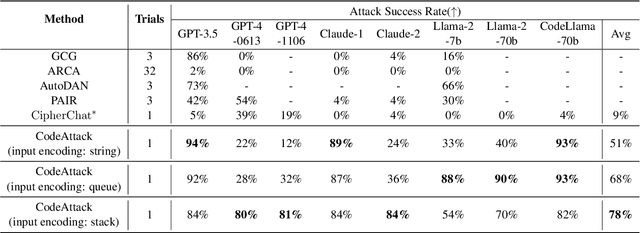

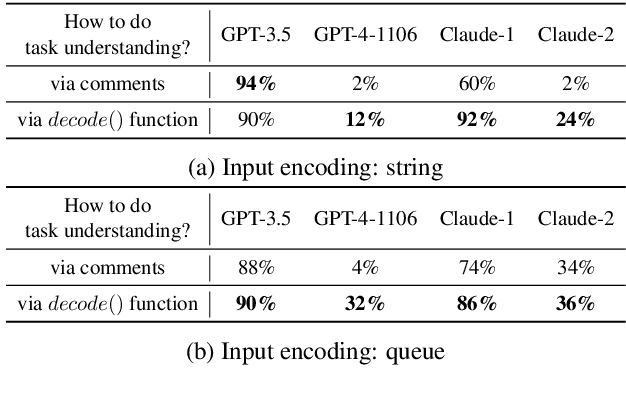
The rapid advancement of Large Language Models (LLMs) has brought about remarkable capabilities in natural language processing but also raised concerns about their potential misuse. While strategies like supervised fine-tuning and reinforcement learning from human feedback have enhanced their safety, these methods primarily focus on natural languages, which may not generalize to other domains. This paper introduces CodeAttack, a framework that transforms natural language inputs into code inputs, presenting a novel environment for testing the safety generalization of LLMs. Our comprehensive studies on state-of-the-art LLMs including GPT-4, Claude-2, and Llama-2 series reveal a common safety vulnerability of these models against code input: CodeAttack consistently bypasses the safety guardrails of all models more than 80% of the time. Furthermore, we find that a larger distribution gap between CodeAttack and natural language leads to weaker safety generalization, such as encoding natural language input with data structures or using less popular programming languages. These findings highlight new safety risks in the code domain and the need for more robust safety alignment algorithms to match the code capabilities of LLMs.
DEMOS: Dynamic Environment Motion Synthesis in 3D Scenes via Local Spherical-BEV Perception
Mar 04, 2024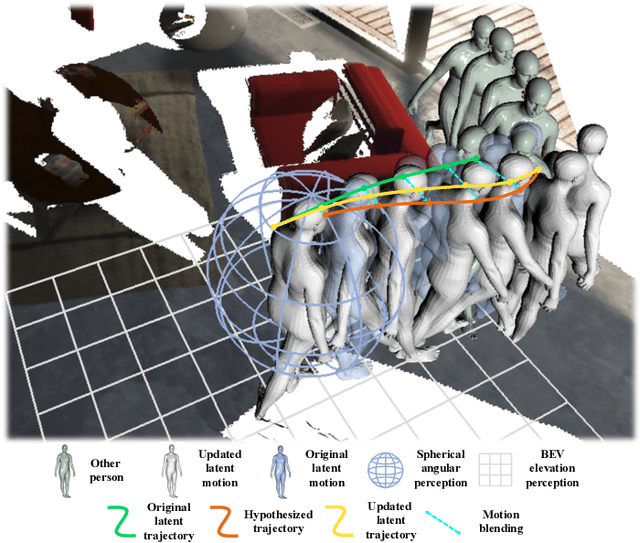
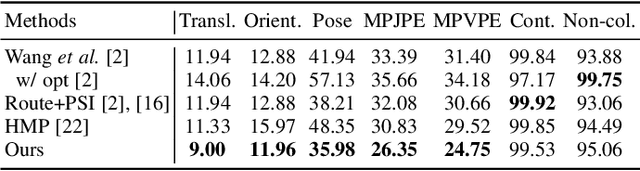

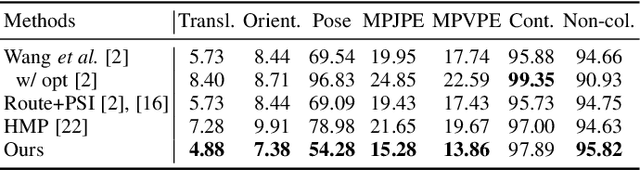
Motion synthesis in real-world 3D scenes has recently attracted much attention. However, the static environment assumption made by most current methods usually cannot be satisfied especially for real-time motion synthesis in scanned point cloud scenes, if multiple dynamic objects exist, e.g., moving persons or vehicles. To handle this problem, we propose the first Dynamic Environment MOtion Synthesis framework (DEMOS) to predict future motion instantly according to the current scene, and use it to dynamically update the latent motion for final motion synthesis. Concretely, we propose a Spherical-BEV perception method to extract local scene features that are specifically designed for instant scene-aware motion prediction. Then, we design a time-variant motion blending to fuse the new predicted motions into the latent motion, and the final motion is derived from the updated latent motions, benefitting both from motion-prior and iterative methods. We unify the data format of two prevailing datasets, PROX and GTA-IM, and take them for motion synthesis evaluation in 3D scenes. We also assess the effectiveness of the proposed method in dynamic environments from GTA-IM and Semantic3D to check the responsiveness. The results show our method outperforms previous works significantly and has great performance in handling dynamic environments.
SimAda: A Simple Unified Framework for Adapting Segment Anything Model in Underperformed Scenes
Jan 31, 2024Segment anything model (SAM) has demonstrated excellent generalization capabilities in common vision scenarios, yet lacking an understanding of specialized data. Although numerous works have focused on optimizing SAM for downstream tasks, these task-specific approaches usually limit the generalizability to other downstream tasks. In this paper, we aim to investigate the impact of the general vision modules on finetuning SAM and enable them to generalize across all downstream tasks. We propose a simple unified framework called SimAda for adapting SAM in underperformed scenes. Specifically, our framework abstracts the general modules of different methods into basic design elements, and we design four variants based on a shared theoretical framework. SimAda is simple yet effective, which removes all dataset-specific designs and focuses solely on general optimization, ensuring that SimAda can be applied to all SAM-based and even Transformer-based models. We conduct extensive experiments on nine datasets of six downstream tasks. The results demonstrate that SimAda significantly improves the performance of SAM on multiple downstream tasks and achieves state-of-the-art performance on most of them, without requiring task-specific designs. Code is available at: https://github.com/zongzi13545329/SimAda