 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeixian Chen
Cantor: Inspiring Multimodal Chain-of-Thought of MLLM
Apr 24, 2024
With the advent of large language models(LLMs) enhanced by the chain-of-thought(CoT) methodology, visual reasoning problem is usually decomposed into manageable sub-tasks and tackled sequentially with various external tools. However, such a paradigm faces the challenge of the potential "determining hallucinations" in decision-making due to insufficient visual information and the limitation of low-level perception tools that fail to provide abstract summaries necessary for comprehensive reasoning. We argue that converging visual context acquisition and logical reasoning is pivotal for tackling visual reasoning tasks. This paper delves into the realm of multimodal CoT to solve intricate visual reasoning tasks with multimodal large language models(MLLMs) and their cognitive capability. To this end, we propose an innovative multimodal CoT framework, termed Cantor, characterized by a perception-decision architecture. Cantor first acts as a decision generator and integrates visual inputs to analyze the image and problem, ensuring a closer alignment with the actual context. Furthermore, Cantor leverages the advanced cognitive functions of MLLMs to perform as multifaceted experts for deriving higher-level information, enhancing the CoT generation process. Our extensive experiments demonstrate the efficacy of the proposed framework, showing significant improvements in multimodal CoT performance across two complex visual reasoning datasets, without necessitating fine-tuning or ground-truth rationales. Project Page: https://ggg0919.github.io/cantor/ .
SDPose: Tokenized Pose Estimation via Circulation-Guide Self-Distillation
Apr 04, 2024Recently, transformer-based methods have achieved state-of-the-art prediction quality on human pose estimation(HPE). Nonetheless, most of these top-performing transformer-based models are too computation-consuming and storage-demanding to deploy on edge computing platforms. Those transformer-based models that require fewer resources are prone to under-fitting due to their smaller scale and thus perform notably worse than their larger counterparts. Given this conundrum, we introduce SDPose, a new self-distillation method for improving the performance of small transformer-based models. To mitigate the problem of under-fitting, we design a transformer module named Multi-Cycled Transformer(MCT) based on multiple-cycled forwards to more fully exploit the potential of small model parameters. Further, in order to prevent the additional inference compute-consuming brought by MCT, we introduce a self-distillation scheme, extracting the knowledge from the MCT module to a naive forward model. Specifically, on the MSCOCO validation dataset, SDPose-T obtains 69.7% mAP with 4.4M parameters and 1.8 GFLOPs. Furthermore, SDPose-S-V2 obtains 73.5% mAP on the MSCOCO validation dataset with 6.2M parameters and 4.7 GFLOPs, achieving a new state-of-the-art among predominant tiny neural network methods. Our code is available at https://github.com/MartyrPenink/SDPose.
A Challenger to GPT-4V? Early Explorations of Gemini in Visual Expertise
Dec 20, 2023The surge of interest towards Multi-modal Large Language Models (MLLMs), e.g., GPT-4V(ision) from OpenAI, has marked a significant trend in both academia and industry. They endow Large Language Models (LLMs) with powerful capabilities in visual understanding, enabling them to tackle diverse multi-modal tasks. Very recently, Google released Gemini, its newest and most capable MLLM built from the ground up for multi-modality. In light of the superior reasoning capabilities, can Gemini challenge GPT-4V's leading position in multi-modal learning? In this paper, we present a preliminary exploration of Gemini Pro's visual understanding proficiency, which comprehensively covers four domains: fundamental perception, advanced cognition, challenging vision tasks, and various expert capacities. We compare Gemini Pro with the state-of-the-art GPT-4V to evaluate its upper limits, along with the latest open-sourced MLLM, Sphinx, which reveals the gap between manual efforts and black-box systems. The qualitative samples indicate that, while GPT-4V and Gemini showcase different answering styles and preferences, they can exhibit comparable visual reasoning capabilities, and Sphinx still trails behind them concerning domain generalizability. Specifically, GPT-4V tends to elaborate detailed explanations and intermediate steps, and Gemini prefers to output a direct and concise answer. The quantitative evaluation on the popular MME benchmark also demonstrates the potential of Gemini to be a strong challenger to GPT-4V. Our early investigation of Gemini also observes some common issues of MLLMs, indicating that there still remains a considerable distance towards artificial general intelligence. Our project for tracking the progress of MLLM is released at https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models.
Aligning and Prompting Everything All at Once for Universal Visual Perception
Dec 04, 2023Vision foundation models have been explored recently to build general-purpose vision systems. However, predominant paradigms, driven by casting instance-level tasks as an object-word alignment, bring heavy cross-modality interaction, which is not effective in prompting object detection and visual grounding. Another line of work that focuses on pixel-level tasks often encounters a large annotation gap of things and stuff, and suffers from mutual interference between foreground-object and background-class segmentation. In stark contrast to the prevailing methods, we present APE, a universal visual perception model for aligning and prompting everything all at once in an image to perform diverse tasks, i.e., detection, segmentation, and grounding, as an instance-level sentence-object matching paradigm. Specifically, APE advances the convergence of detection and grounding by reformulating language-guided grounding as open-vocabulary detection, which efficiently scales up model prompting to thousands of category vocabularies and region descriptions while maintaining the effectiveness of cross-modality fusion. To bridge the granularity gap of different pixel-level tasks, APE equalizes semantic and panoptic segmentation to proxy instance learning by considering any isolated regions as individual instances. APE aligns vision and language representation on broad data with natural and challenging characteristics all at once without task-specific fine-tuning. The extensive experiments on over 160 datasets demonstrate that, with only one-suit of weights, APE outperforms (or is on par with) the state-of-the-art models, proving that an effective yet universal perception for anything aligning and prompting is indeed feasible. Codes and trained models are released at https://github.com/shenyunhang/APE.
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Jul 02, 2023
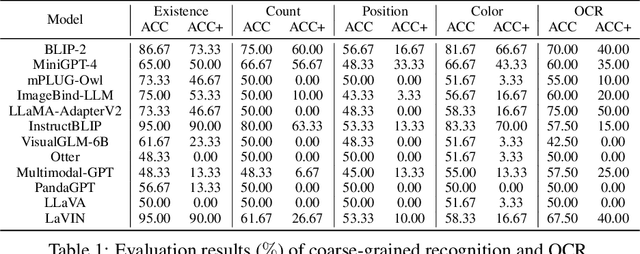
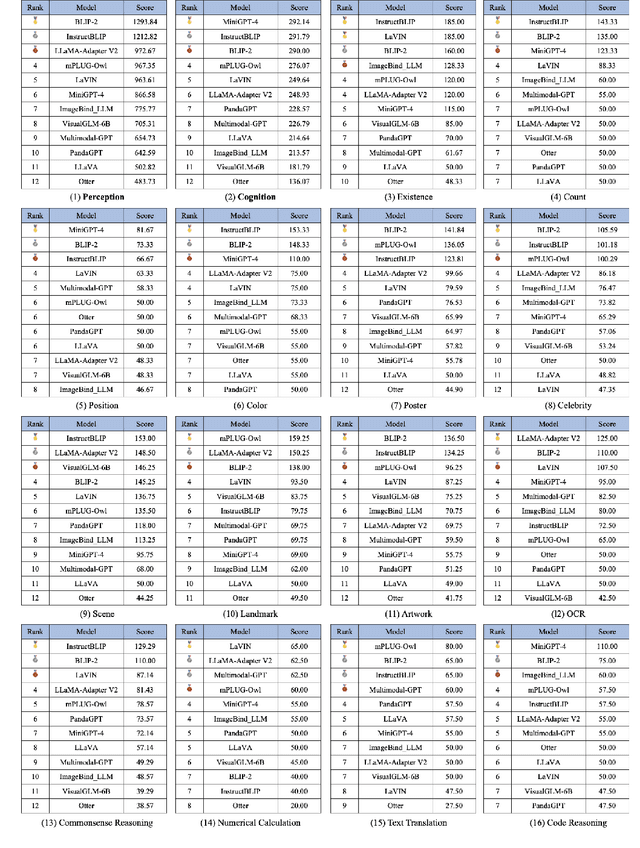
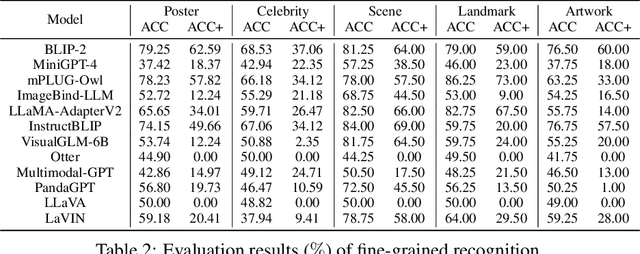
Multimodal Large Language Model (MLLM) relies on the powerful LLM to perform multimodal tasks, showing amazing emergent abilities in recent studies, such as writing poems based on an image. However, it is difficult for these case studies to fully reflect the performance of MLLM, lacking a comprehensive evaluation. In this paper, we fill in this blank, presenting the first MLLM Evaluation benchmark MME. It measures both perception and cognition abilities on a total of 14 subtasks. In order to avoid data leakage that may arise from direct use of public datasets for evaluation, the annotations of instruction-answer pairs are all manually designed. The concise instruction design allows us to fairly compare MLLMs, instead of struggling in prompt engineering. Besides, with such an instruction, we can also easily carry out quantitative statistics. A total of 12 advanced MLLMs are comprehensively evaluated on our MME, which not only suggests that existing MLLMs still have a large room for improvement, but also reveals the potential directions for the subsequent model optimization.
Multi-modal Queried Object Detection in the Wild
May 30, 2023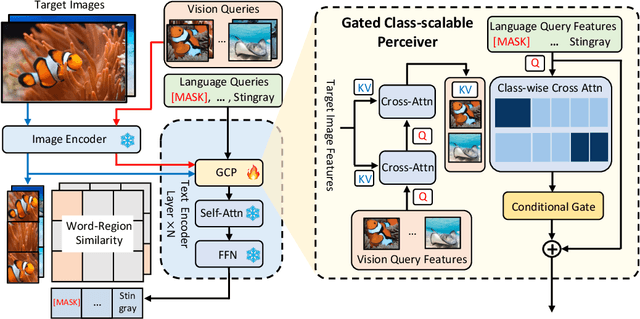
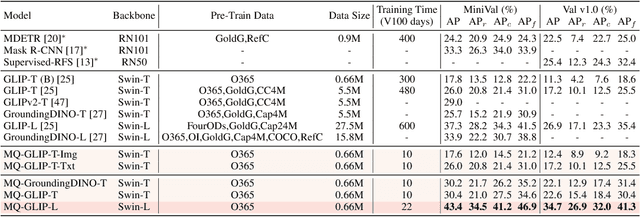
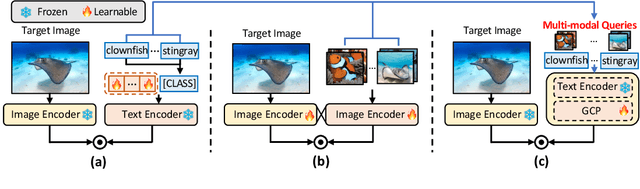
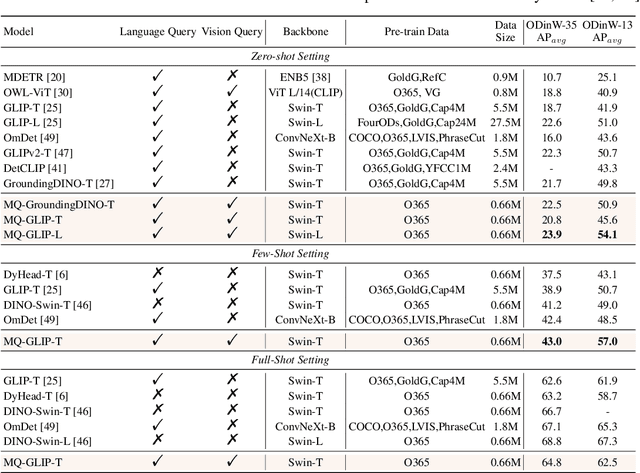
We introduce MQ-Det, an efficient architecture and pre-training strategy design to utilize both textual description with open-set generalization and visual exemplars with rich description granularity as category queries, namely, Multi-modal Queried object Detection, for real-world detection with both open-vocabulary categories and various granularity. MQ-Det incorporates vision queries into existing well-established language-queried-only detectors. A plug-and-play gated class-scalable perceiver module upon the frozen detector is proposed to augment category text with class-wise visual information. To address the learning inertia problem brought by the frozen detector, a vision conditioned masked language prediction strategy is proposed. MQ-Det's simple yet effective architecture and training strategy design is compatible with most language-queried object detectors, thus yielding versatile applications. Experimental results demonstrate that multi-modal queries largely boost open-world detection. For instance, MQ-Det significantly improves the state-of-the-art open-set detector GLIP by +7.8% zero-shot AP on the LVIS benchmark and averagely +6.3% AP on 13 few-shot downstream tasks, with merely 3% pre-training time required by GLIP. Code is available at https://github.com/YifanXu74/MQ-Det.
Open Vocabulary Object Detection with Proposal Mining and Prediction Equalization
Jun 24, 2022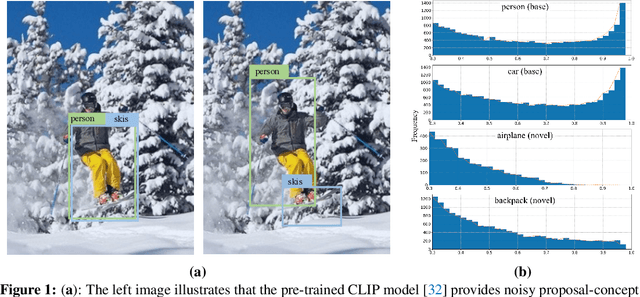
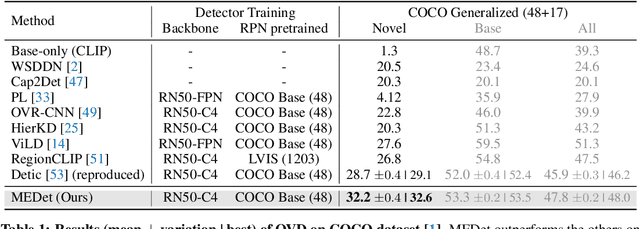
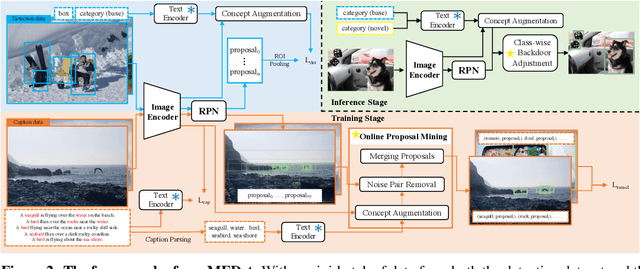
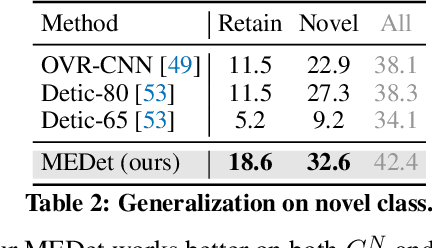
Open-vocabulary object detection (OVD) aims to scale up vocabulary size to detect objects of novel categories beyond the training vocabulary. Recent work resorts to the rich knowledge in pre-trained vision-language models. However, existing methods are ineffective in proposal-level vision-language alignment. Meanwhile, the models usually suffer from confidence bias toward base categories and perform worse on novel ones. To overcome the challenges, we present MEDet, a novel and effective OVD framework with proposal mining and prediction equalization. First, we design an online proposal mining to refine the inherited vision-semantic knowledge from coarse to fine, allowing for proposal-level detection-oriented feature alignment. Second, based on causal inference theory, we introduce a class-wise backdoor adjustment to reinforce the predictions on novel categories to improve the overall OVD performance. Extensive experiments on COCO and LVIS benchmarks verify the superiority of MEDet over the competing approaches in detecting objects of novel categories, e.g., 32.6% AP50 on COCO and 22.4% mask mAP on LVIS.
Efficient Decoder-free Object Detection with Transformers
Jun 17, 2022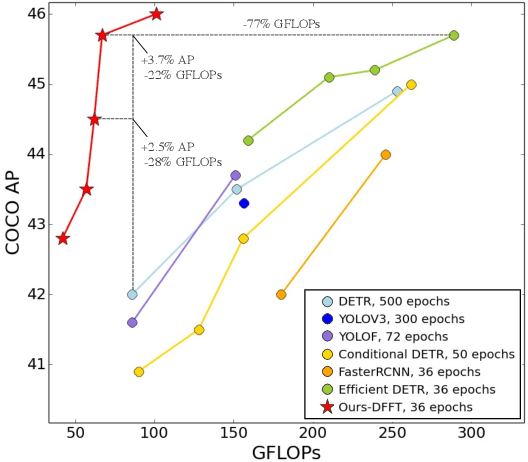
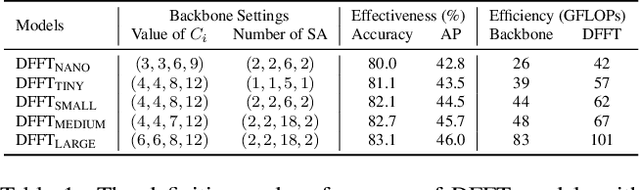
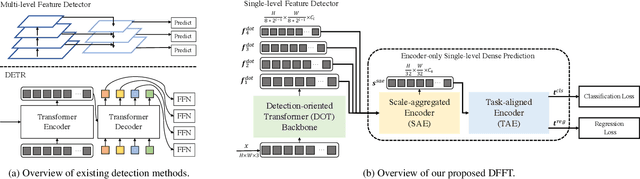
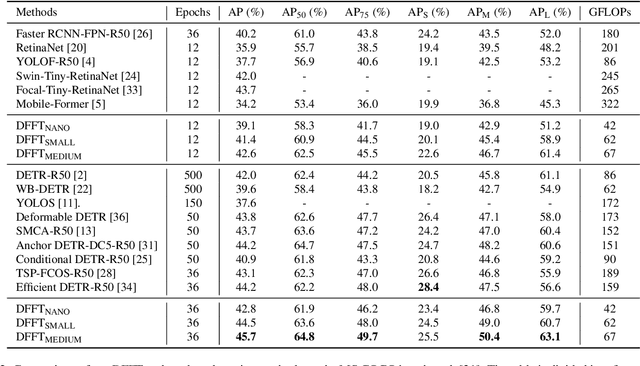
Vision transformers (ViTs) are changing the landscape of object detection approaches. A natural usage of ViTs in detection is to replace the CNN-based backbone with a transformer-based backbone, which is straightforward and effective, with the price of bringing considerable computation burden for inference. More subtle usage is the DETR family, which eliminates the need for many hand-designed components in object detection but introduces a decoder demanding an extra-long time to converge. As a result, transformer-based object detection can not prevail in large-scale applications. To overcome these issues, we propose a novel decoder-free fully transformer-based (DFFT) object detector, achieving high efficiency in both training and inference stages, for the first time. We simplify objection detection into an encoder-only single-level anchor-based dense prediction problem by centering around two entry points: 1) Eliminate the training-inefficient decoder and leverage two strong encoders to preserve the accuracy of single-level feature map prediction; 2) Explore low-level semantic features for the detection task with limited computational resources. In particular, we design a novel lightweight detection-oriented transformer backbone that efficiently captures low-level features with rich semantics based on a well-conceived ablation study. Extensive experiments on the MS COCO benchmark demonstrate that DFFT_SMALL outperforms DETR by 2.5% AP with 28% computation cost reduction and more than $10$x fewer training epochs. Compared with the cutting-edge anchor-based detector RetinaNet, DFFT_SMALL obtains over 5.5% AP gain while cutting down 70% computation cost.
ARM: Any-Time Super-Resolution Method
Mar 21, 2022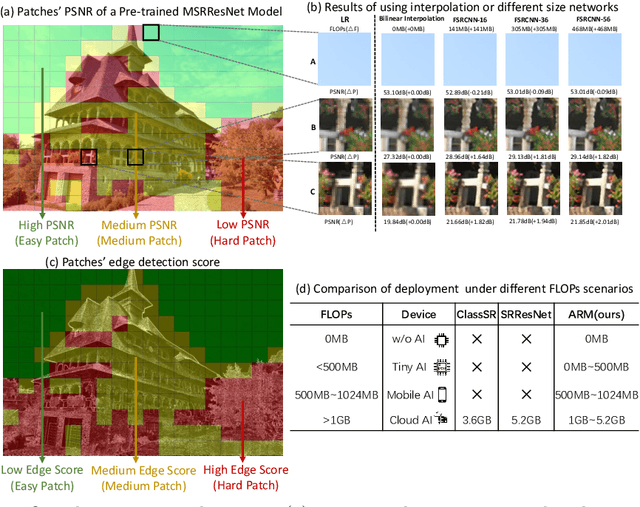
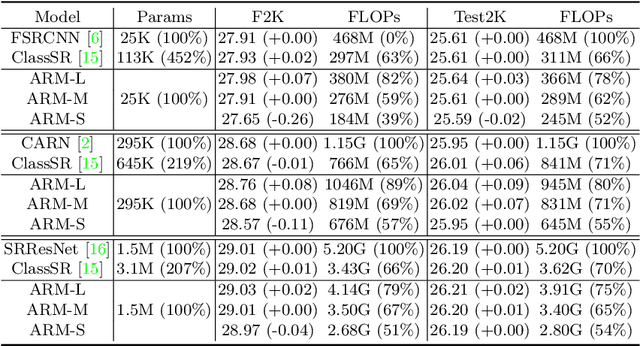

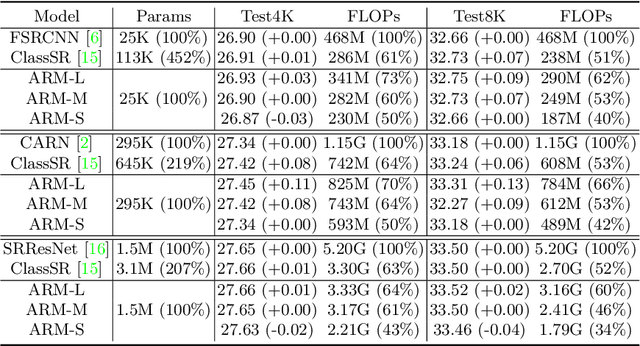
This paper proposes an Any-time super-Resolution Method (ARM) to tackle the over-parameterized single image super-resolution (SISR) models. Our ARM is motivated by three observations: (1) The performance of different image patches varies with SISR networks of different sizes. (2) There is a tradeoff between computation overhead and performance of the reconstructed image. (3) Given an input image, its edge information can be an effective option to estimate its PSNR. Subsequently, we train an ARM supernet containing SISR subnets of different sizes to deal with image patches of various complexity. To that effect, we construct an Edge-to-PSNR lookup table that maps the edge score of an image patch to the PSNR performance for each subnet, together with a set of computation costs for the subnets. In the inference, the image patches are individually distributed to different subnets for a better computation-performance tradeoff. Moreover, each SISR subnet shares weights of the ARM supernet, thus no extra parameters are introduced. The setting of multiple subnets can well adapt the computational cost of SISR model to the dynamically available hardware resources, allowing the SISR task to be in service at any time. Extensive experiments on resolution datasets of different sizes with popular SISR networks as backbones verify the effectiveness and the versatility of our ARM. The source code is available at \url{https://github.com/chenbong/ARM-Net}.
Learning Task-oriented Disentangled Representations for Unsupervised Domain Adaptation
Jul 27, 2020



Unsupervised domain adaptation (UDA) aims to address the domain-shift problem between a labeled source domain and an unlabeled target domain. Many efforts have been made to address the mismatch between the distributions of training and testing data, but unfortunately, they ignore the task-oriented information across domains and are inflexible to perform well in complicated open-set scenarios. Many efforts have been made to eliminate the mismatch between the distributions of training and testing data by learning domain-invariant representations. However, the learned representations are usually not task-oriented, i.e., being class-discriminative and domain-transferable simultaneously. This drawback limits the flexibility of UDA in complicated open-set tasks where no labels are shared between domains. In this paper, we break the concept of task-orientation into task-relevance and task-irrelevance, and propose a dynamic task-oriented disentangling network (DTDN) to learn disentangled representations in an end-to-end fashion for UDA. The dynamic disentangling network effectively disentangles data representations into two components: the task-relevant ones embedding critical information associated with the task across domains, and the task-irrelevant ones with the remaining non-transferable or disturbing information. These two components are regularized by a group of task-specific objective functions across domains. Such regularization explicitly encourages disentangling and avoids the use of generative models or decoders. Experiments in complicated, open-set scenarios (retrieval tasks) and empirical benchmarks (classification tasks) demonstrate that the proposed method captures rich disentangled information and achieves superior performance.