 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYubo Huang
Improved Genetic Algorithm Based on Greedy and Simulated Annealing Ideas for Vascular Robot Ordering Strategy
Mar 28, 2024




This study presents a comprehensive approach for optimizing the acquisition, utilization, and maintenance of ABLVR vascular robots in healthcare settings. Medical robotics, particularly in vascular treatments, necessitates precise resource allocation and optimization due to the complex nature of robot and operator maintenance. Traditional heuristic methods, though intuitive, often fail to achieve global optimization. To address these challenges, this research introduces a novel strategy, combining mathematical modeling, a hybrid genetic algorithm, and ARIMA time series forecasting. Considering the dynamic healthcare environment, our approach includes a robust resource allocation model for robotic vessels and operators. We incorporate the unique requirements of the adaptive learning process for operators and the maintenance needs of robotic components. The hybrid genetic algorithm, integrating simulated annealing and greedy approaches, efficiently solves the optimization problem. Additionally, ARIMA time series forecasting predicts the demand for vascular robots, further enhancing the adaptability of our strategy. Experimental results demonstrate the superiority of our approach in terms of optimization, transparency, and convergence speed from other state-of-the-art methods.
A Challenger to GPT-4V? Early Explorations of Gemini in Visual Expertise
Dec 20, 2023The surge of interest towards Multi-modal Large Language Models (MLLMs), e.g., GPT-4V(ision) from OpenAI, has marked a significant trend in both academia and industry. They endow Large Language Models (LLMs) with powerful capabilities in visual understanding, enabling them to tackle diverse multi-modal tasks. Very recently, Google released Gemini, its newest and most capable MLLM built from the ground up for multi-modality. In light of the superior reasoning capabilities, can Gemini challenge GPT-4V's leading position in multi-modal learning? In this paper, we present a preliminary exploration of Gemini Pro's visual understanding proficiency, which comprehensively covers four domains: fundamental perception, advanced cognition, challenging vision tasks, and various expert capacities. We compare Gemini Pro with the state-of-the-art GPT-4V to evaluate its upper limits, along with the latest open-sourced MLLM, Sphinx, which reveals the gap between manual efforts and black-box systems. The qualitative samples indicate that, while GPT-4V and Gemini showcase different answering styles and preferences, they can exhibit comparable visual reasoning capabilities, and Sphinx still trails behind them concerning domain generalizability. Specifically, GPT-4V tends to elaborate detailed explanations and intermediate steps, and Gemini prefers to output a direct and concise answer. The quantitative evaluation on the popular MME benchmark also demonstrates the potential of Gemini to be a strong challenger to GPT-4V. Our early investigation of Gemini also observes some common issues of MLLMs, indicating that there still remains a considerable distance towards artificial general intelligence. Our project for tracking the progress of MLLM is released at https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models.
Soft policy optimization using dual-track advantage estimator
Sep 15, 2020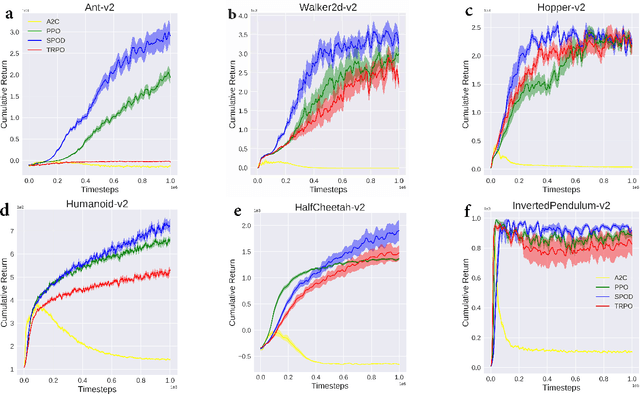
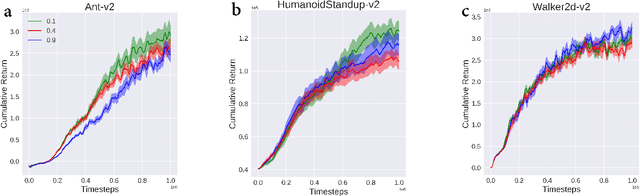
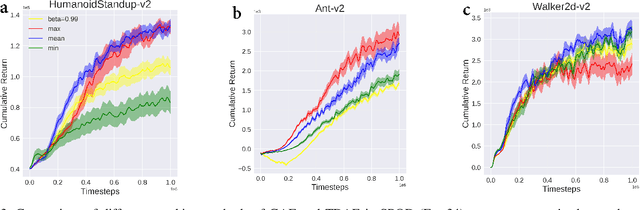
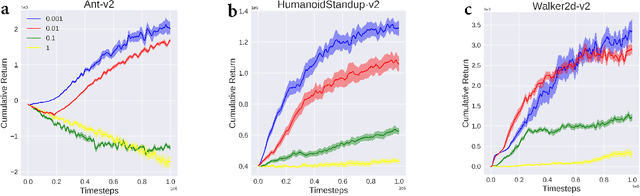
In reinforcement learning (RL), we always expect the agent to explore as many states as possible in the initial stage of training and exploit the explored information in the subsequent stage to discover the most returnable trajectory. Based on this principle, in this paper, we soften the proximal policy optimization by introducing the entropy and dynamically setting the temperature coefficient to balance the opportunity of exploration and exploitation. While maximizing the expected reward, the agent will also seek other trajectories to avoid the local optimal policy. Nevertheless, the increase of randomness induced by entropy will reduce the train speed in the early stage. Integrating the temporal-difference (TD) method and the general advantage estimator (GAE), we propose the dual-track advantage estimator (DTAE) to accelerate the convergence of value functions and further enhance the performance of the algorithm. Compared with other on-policy RL algorithms on the Mujoco environment, the proposed method not only significantly speeds up the training but also achieves the most advanced results in cumulative return.