 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMin Wang
Autoencoder-assisted Feature Ensemble Net for Incipient Faults
Apr 22, 2024
Deep learning has shown the great power in the field of fault detection. However, for incipient faults with tiny amplitude, the detection performance of the current deep learning networks (DLNs) is not satisfactory. Even if prior information about the faults is utilized, DLNs can't successfully detect faults 3, 9 and 15 in Tennessee Eastman process (TEP). These faults are notoriously difficult to detect, lacking effective detection technologies in the field of fault detection. In this work, we propose Autoencoder-assisted Feature Ensemble Net (AE-FENet): a deep feature ensemble framework that uses the unsupervised autoencoder to conduct the feature transformation. Compared with the principle component analysis (PCA) technique adopted in the original Feature Ensemble Net (FENet), autoencoder can mine more exact features on incipient faults, which results in the better detection performance of AE-FENet. With same kinds of basic detectors, AE-FENet achieves a state-of-the-art average accuracy over 96% on faults 3, 9 and 15 in TEP, which represents a significant enhancement in performance compared to other methods. Plenty of experiments have been done to extend our framework, proving that DLNs can be utilized efficiently within this architecture.
Token-Efficient Leverage Learning in Large Language Models
Apr 01, 2024Large Language Models (LLMs) have excelled in various tasks but perform better in high-resource scenarios, which presents challenges in low-resource scenarios. Data scarcity and the inherent difficulty of adapting LLMs to specific tasks compound the challenge. To address the twin hurdles, we introduce \textbf{Leverage Learning}. We present a streamlined implement of this methodology called Token-Efficient Leverage Learning (TELL). TELL showcases the potential of Leverage Learning, demonstrating effectiveness across various LLMs and low-resource tasks, ranging from $10^4$ to $10^6$ tokens. It reduces task data requirements by up to nearly an order of magnitude compared to conventional Supervised Fine-Tuning (SFT) while delivering competitive performance. With the same amount of task data, TELL leads in improving task performance compared to SFT. We discuss the mechanism of Leverage Learning, suggesting it aligns with quantization hypothesis and explore its promising potential through empirical testing.
GaussNav: Gaussian Splatting for Visual Navigation
Mar 20, 2024
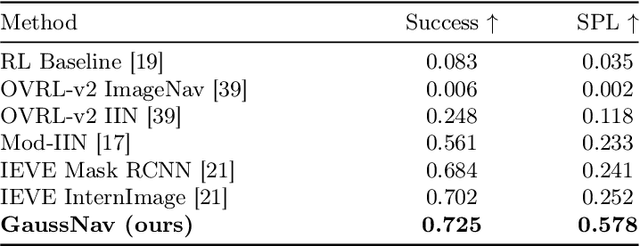
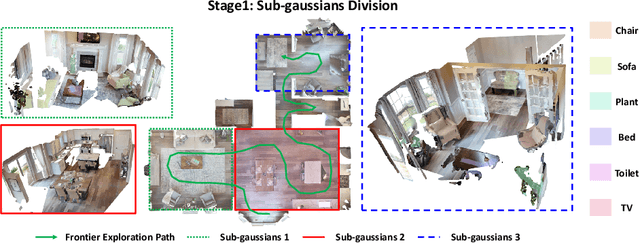

In embodied vision, Instance ImageGoal Navigation (IIN) requires an agent to locate a specific object depicted in a goal image within an unexplored environment. The primary difficulty of IIN stems from the necessity of recognizing the target object across varying viewpoints and rejecting potential distractors. Existing map-based navigation methods largely adopt the representation form of Bird's Eye View (BEV) maps, which, however, lack the representation of detailed textures in a scene. To address the above issues, we propose a new Gaussian Splatting Navigation (abbreviated as GaussNav) framework for IIN task, which constructs a novel map representation based on 3D Gaussian Splatting (3DGS). The proposed framework enables the agent to not only memorize the geometry and semantic information of the scene, but also retain the textural features of objects. Our GaussNav framework demonstrates a significant leap in performance, evidenced by an increase in Success weighted by Path Length (SPL) from 0.252 to 0.578 on the challenging Habitat-Matterport 3D (HM3D) dataset. Our code will be made publicly available.
Motion-aware 3D Gaussian Splatting for Efficient Dynamic Scene Reconstruction
Mar 18, 2024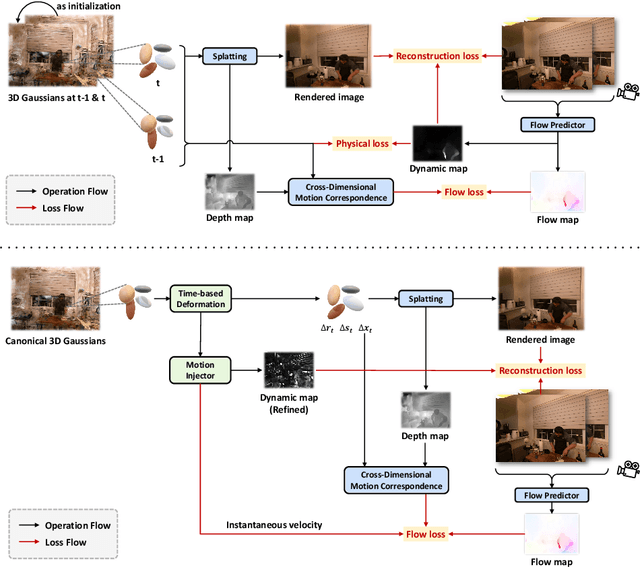
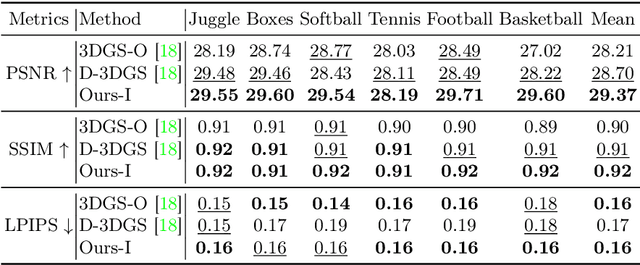
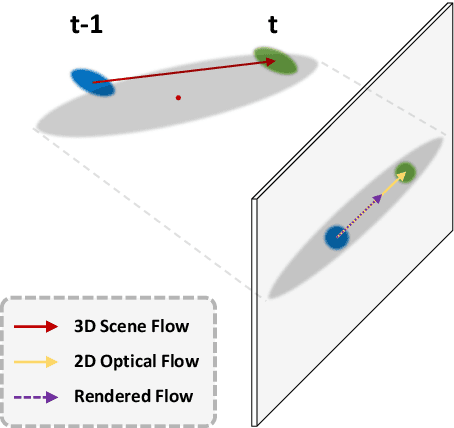
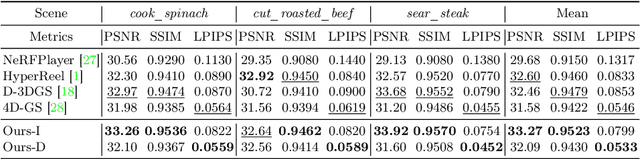
3D Gaussian Splatting (3DGS) has become an emerging tool for dynamic scene reconstruction. However, existing methods focus mainly on extending static 3DGS into a time-variant representation, while overlooking the rich motion information carried by 2D observations, thus suffering from performance degradation and model redundancy. To address the above problem, we propose a novel motion-aware enhancement framework for dynamic scene reconstruction, which mines useful motion cues from optical flow to improve different paradigms of dynamic 3DGS. Specifically, we first establish a correspondence between 3D Gaussian movements and pixel-level flow. Then a novel flow augmentation method is introduced with additional insights into uncertainty and loss collaboration. Moreover, for the prevalent deformation-based paradigm that presents a harder optimization problem, a transient-aware deformation auxiliary module is proposed. We conduct extensive experiments on both multi-view and monocular scenes to verify the merits of our work. Compared with the baselines, our method shows significant superiority in both rendering quality and efficiency.
DEMOS: Dynamic Environment Motion Synthesis in 3D Scenes via Local Spherical-BEV Perception
Mar 04, 2024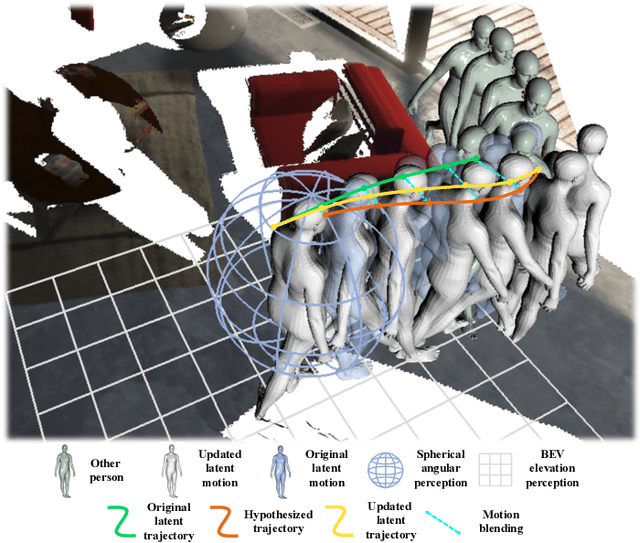
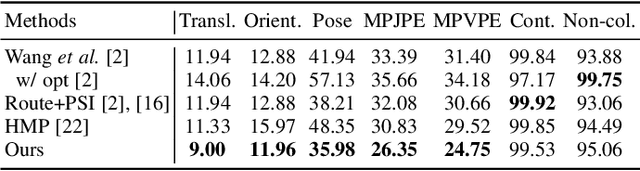

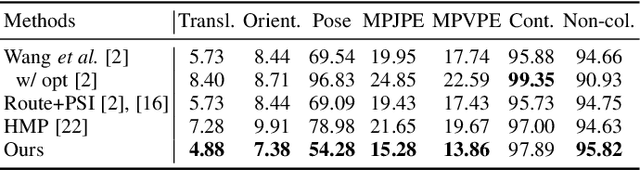
Motion synthesis in real-world 3D scenes has recently attracted much attention. However, the static environment assumption made by most current methods usually cannot be satisfied especially for real-time motion synthesis in scanned point cloud scenes, if multiple dynamic objects exist, e.g., moving persons or vehicles. To handle this problem, we propose the first Dynamic Environment MOtion Synthesis framework (DEMOS) to predict future motion instantly according to the current scene, and use it to dynamically update the latent motion for final motion synthesis. Concretely, we propose a Spherical-BEV perception method to extract local scene features that are specifically designed for instant scene-aware motion prediction. Then, we design a time-variant motion blending to fuse the new predicted motions into the latent motion, and the final motion is derived from the updated latent motions, benefitting both from motion-prior and iterative methods. We unify the data format of two prevailing datasets, PROX and GTA-IM, and take them for motion synthesis evaluation in 3D scenes. We also assess the effectiveness of the proposed method in dynamic environments from GTA-IM and Semantic3D to check the responsiveness. The results show our method outperforms previous works significantly and has great performance in handling dynamic environments.
Image2Sentence based Asymmetrical Zero-shot Composed Image Retrieval
Mar 03, 2024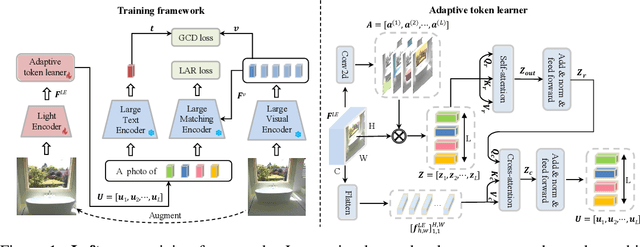
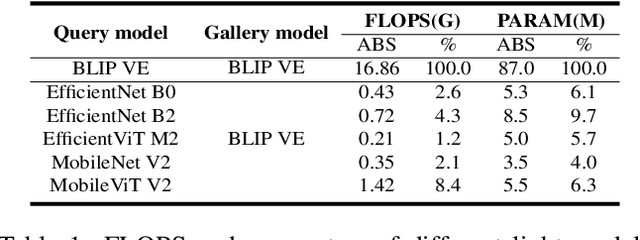
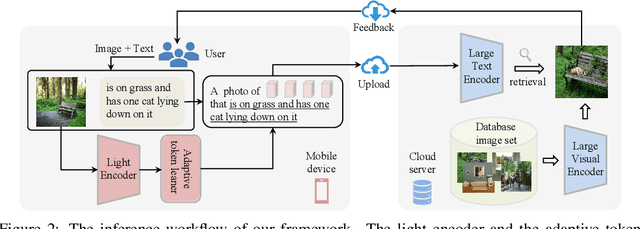
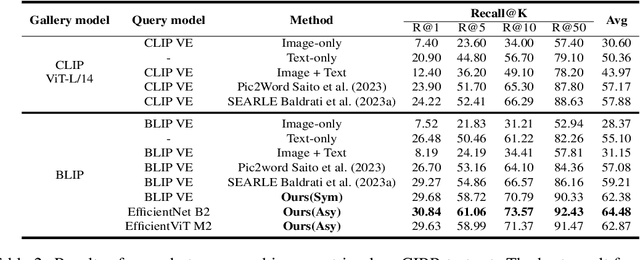
The task of composed image retrieval (CIR) aims to retrieve images based on the query image and the text describing the users' intent. Existing methods have made great progress with the advanced large vision-language (VL) model in CIR task, however, they generally suffer from two main issues: lack of labeled triplets for model training and difficulty of deployment on resource-restricted environments when deploying the large vision-language model. To tackle the above problems, we propose Image2Sentence based Asymmetric zero-shot composed image retrieval (ISA), which takes advantage of the VL model and only relies on unlabeled images for composition learning. In the framework, we propose a new adaptive token learner that maps an image to a sentence in the word embedding space of VL model. The sentence adaptively captures discriminative visual information and is further integrated with the text modifier. An asymmetric structure is devised for flexible deployment, in which the lightweight model is adopted for the query side while the large VL model is deployed on the gallery side. The global contrastive distillation and the local alignment regularization are adopted for the alignment between the light model and the VL model for CIR task. Our experiments demonstrate that the proposed ISA could better cope with the real retrieval scenarios and further improve retrieval accuracy and efficiency.
Structure Similarity Preservation Learning for Asymmetric Image Retrieval
Mar 01, 2024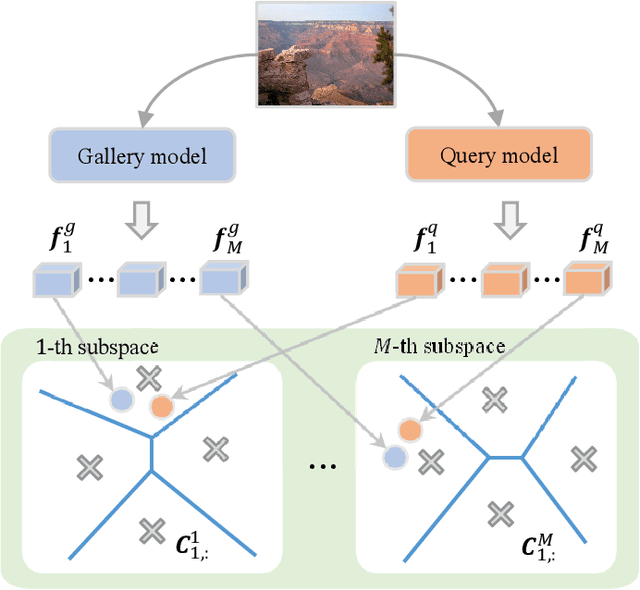
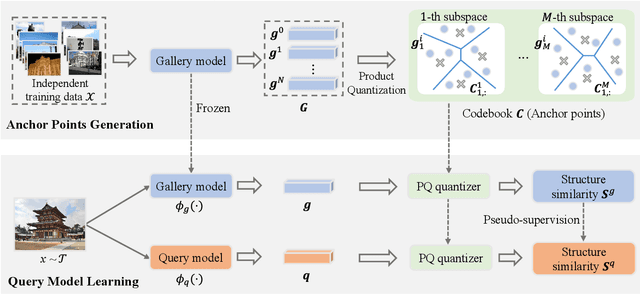
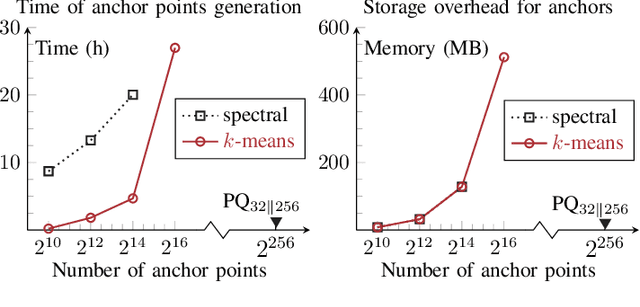
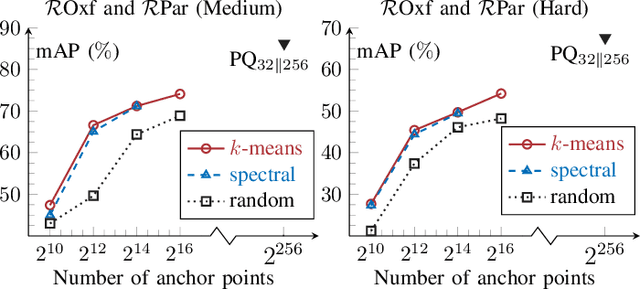
Asymmetric image retrieval is a task that seeks to balance retrieval accuracy and efficiency by leveraging lightweight and large models for the query and gallery sides, respectively. The key to asymmetric image retrieval is realizing feature compatibility between different models. Despite the great progress, most existing approaches either rely on classifiers inherited from gallery models or simply impose constraints at the instance level, ignoring the structure of embedding space. In this work, we propose a simple yet effective structure similarity preserving method to achieve feature compatibility between query and gallery models. Specifically, we first train a product quantizer offline with the image features embedded by the gallery model. The centroid vectors in the quantizer serve as anchor points in the embedding space of the gallery model to characterize its structure. During the training of the query model, anchor points are shared by the query and gallery models. The relationships between image features and centroid vectors are considered as structure similarities and constrained to be consistent. Moreover, our approach makes no assumption about the existence of any labeled training data and thus can be extended to an unlimited amount of data. Comprehensive experiments on large-scale landmark retrieval demonstrate the effectiveness of our approach. Our code is released at: https://github.com/MCC-WH/SSP.
Asymmetric Feature Fusion for Image Retrieval
Mar 01, 2024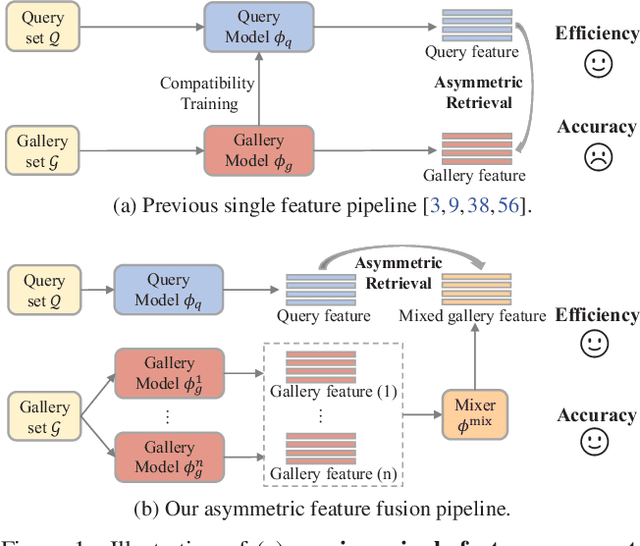
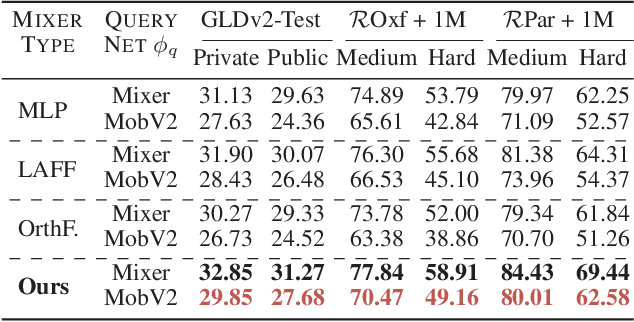
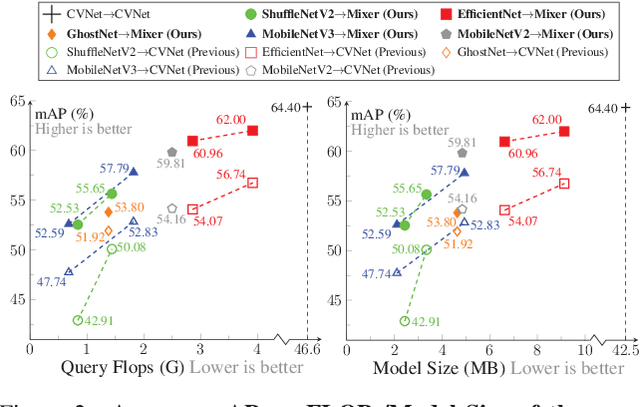
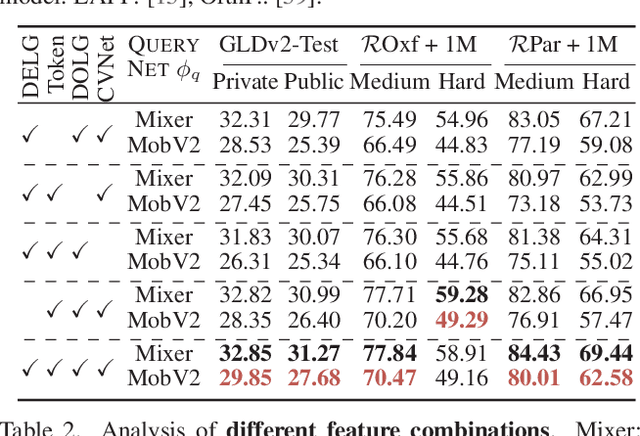
In asymmetric retrieval systems, models with different capacities are deployed on platforms with different computational and storage resources. Despite the great progress, existing approaches still suffer from a dilemma between retrieval efficiency and asymmetric accuracy due to the limited capacity of the lightweight query model. In this work, we propose an Asymmetric Feature Fusion (AFF) paradigm, which advances existing asymmetric retrieval systems by considering the complementarity among different features just at the gallery side. Specifically, it first embeds each gallery image into various features, e.g., local features and global features. Then, a dynamic mixer is introduced to aggregate these features into compact embedding for efficient search. On the query side, only a single lightweight model is deployed for feature extraction. The query model and dynamic mixer are jointly trained by sharing a momentum-updated classifier. Notably, the proposed paradigm boosts the accuracy of asymmetric retrieval without introducing any extra overhead to the query side. Exhaustive experiments on various landmark retrieval datasets demonstrate the superiority of our paradigm.
Instance-aware Exploration-Verification-Exploitation for Instance ImageGoal Navigation
Feb 25, 2024As a new embodied vision task, Instance ImageGoal Navigation (IIN) aims to navigate to a specified object depicted by a goal image in an unexplored environment. The main challenge of this task lies in identifying the target object from different viewpoints while rejecting similar distractors. Existing ImageGoal Navigation methods usually adopt the simple Exploration-Exploitation framework and ignore the identification of specific instance during navigation. In this work, we propose to imitate the human behaviour of ``getting closer to confirm" when distinguishing objects from a distance. Specifically, we design a new modular navigation framework named Instance-aware Exploration-Verification-Exploitation (IEVE) for instance-level image goal navigation. Our method allows for active switching among the exploration, verification, and exploitation actions, thereby facilitating the agent in making reasonable decisions under different situations. On the challenging HabitatMatterport 3D semantic (HM3D-SEM) dataset, our method surpasses previous state-of-the-art work, with a classical segmentation model (0.684 vs. 0.561 success) or a robust model (0.702 vs. 0.561 success). Our code will be made publicly available at https://github.com/XiaohanLei/IEVE.
Self-distillation Regularized Connectionist Temporal Classification Loss for Text Recognition: A Simple Yet Effective Approach
Aug 21, 2023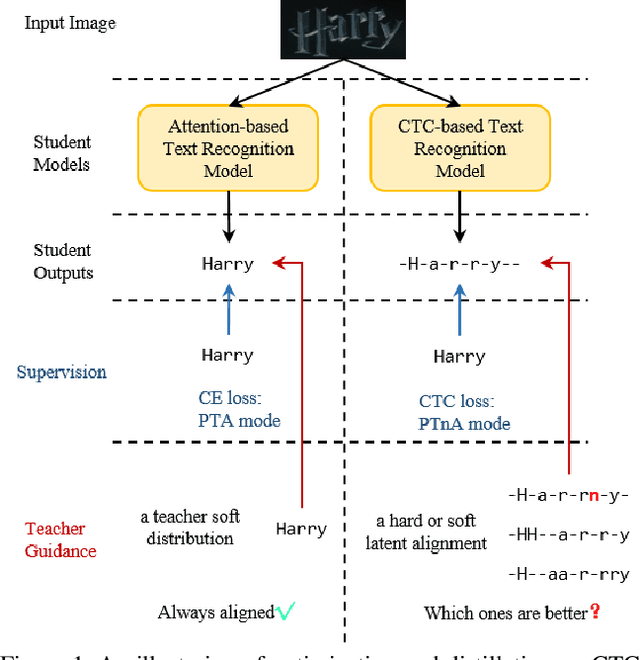
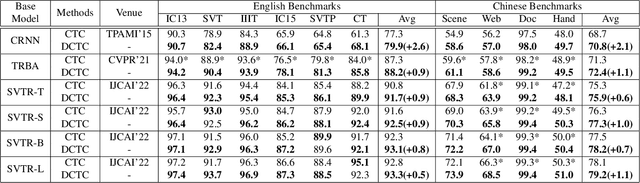

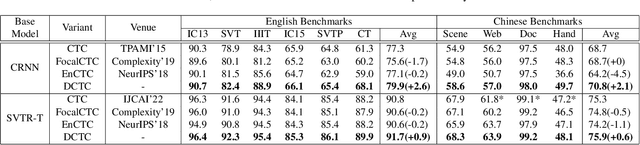
Text recognition methods are gaining rapid development. Some advanced techniques, e.g., powerful modules, language models, and un- and semi-supervised learning schemes, consecutively push the performance on public benchmarks forward. However, the problem of how to better optimize a text recognition model from the perspective of loss functions is largely overlooked. CTC-based methods, widely used in practice due to their good balance between performance and inference speed, still grapple with accuracy degradation. This is because CTC loss emphasizes the optimization of the entire sequence target while neglecting to learn individual characters. We propose a self-distillation scheme for CTC-based model to address this issue. It incorporates a framewise regularization term in CTC loss to emphasize individual supervision, and leverages the maximizing-a-posteriori of latent alignment to solve the inconsistency problem that arises in distillation between CTC-based models. We refer to the regularized CTC loss as Distillation Connectionist Temporal Classification (DCTC) loss. DCTC loss is module-free, requiring no extra parameters, longer inference lag, or additional training data or phases. Extensive experiments on public benchmarks demonstrate that DCTC can boost text recognition model accuracy by up to 2.6%, without any of these drawbacks.