 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBingyi Jing
Knowledge Distillation with Multi-granularity Mixture of Priors for Image Super-Resolution
Apr 03, 2024
Knowledge distillation (KD) is a promising yet challenging model compression technique that transfers rich learning representations from a well-performing but cumbersome teacher model to a compact student model. Previous methods for image super-resolution (SR) mostly compare the feature maps directly or after standardizing the dimensions with basic algebraic operations (e.g. average, dot-product). However, the intrinsic semantic differences among feature maps are overlooked, which are caused by the disparate expressive capacity between the networks. This work presents MiPKD, a multi-granularity mixture of prior KD framework, to facilitate efficient SR model through the feature mixture in a unified latent space and stochastic network block mixture. Extensive experiments demonstrate the effectiveness of the proposed MiPKD method.
Enhanced Bayesian Personalized Ranking for Robust Hard Negative Sampling in Recommender Systems
Mar 28, 2024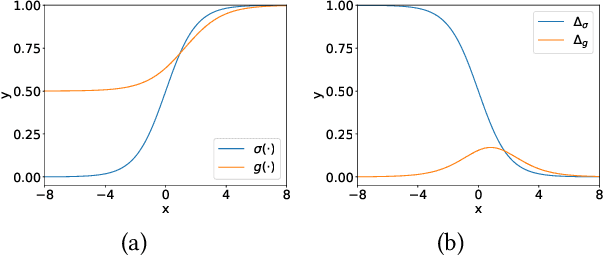
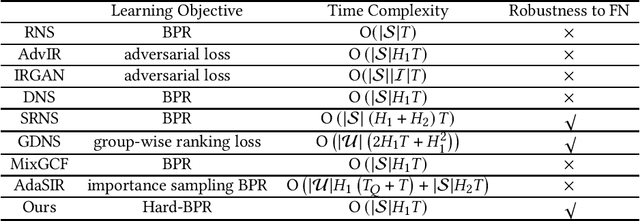

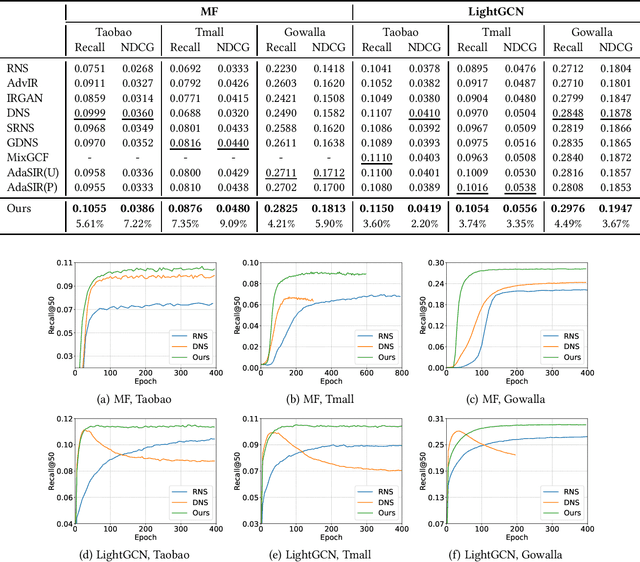
In implicit collaborative filtering, hard negative mining techniques are developed to accelerate and enhance the recommendation model learning. However, the inadvertent selection of false negatives remains a major concern in hard negative sampling, as these false negatives can provide incorrect information and mislead the model learning. To date, only a small number of studies have been committed to solve the false negative problem, primarily focusing on designing sophisticated sampling algorithms to filter false negatives. In contrast, this paper shifts its focus to refining the loss function. We find that the original Bayesian Personalized Ranking (BPR), initially designed for uniform negative sampling, is inadequate in adapting to hard sampling scenarios. Hence, we introduce an enhanced Bayesian Personalized Ranking objective, named as Hard-BPR, which is specifically crafted for dynamic hard negative sampling to mitigate the influence of false negatives. This method is simple yet efficient for real-world deployment. Extensive experiments conducted on three real-world datasets demonstrate the effectiveness and robustness of our approach, along with the enhanced ability to distinguish false negatives.
Exploring Learning Complexity for Downstream Data Pruning
Feb 08, 2024The over-parameterized pre-trained models pose a great challenge to fine-tuning with limited computation resources. An intuitive solution is to prune the less informative samples from the fine-tuning dataset. A series of training-based scoring functions are proposed to quantify the informativeness of the data subset but the pruning cost becomes non-negligible due to the heavy parameter updating. For efficient pruning, it is viable to adapt the similarity scoring function of geometric-based methods from training-based to training-free. However, we empirically show that such adaption distorts the original pruning and results in inferior performance on the downstream tasks. In this paper, we propose to treat the learning complexity (LC) as the scoring function for classification and regression tasks. Specifically, the learning complexity is defined as the average predicted confidence of subnets with different capacities, which encapsulates data processing within a converged model. Then we preserve the diverse and easy samples for fine-tuning. Extensive experiments with vision datasets demonstrate the effectiveness and efficiency of the proposed scoring function for classification tasks. For the instruction fine-tuning of large language models, our method achieves state-of-the-art performance with stable convergence, outperforming the full training with only 10\% of the instruction dataset.
Data Upcycling Knowledge Distillation for Image Super-Resolution
Sep 25, 2023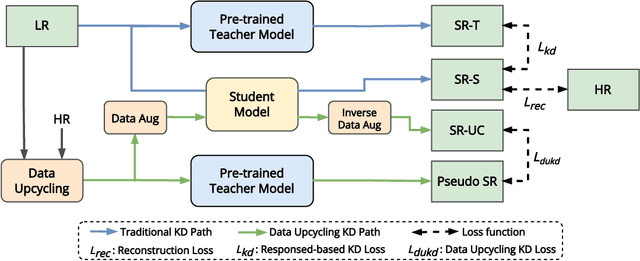
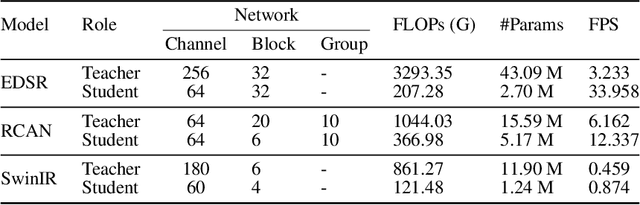
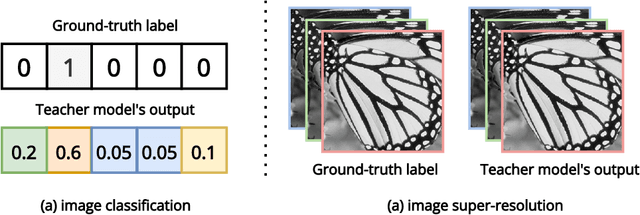
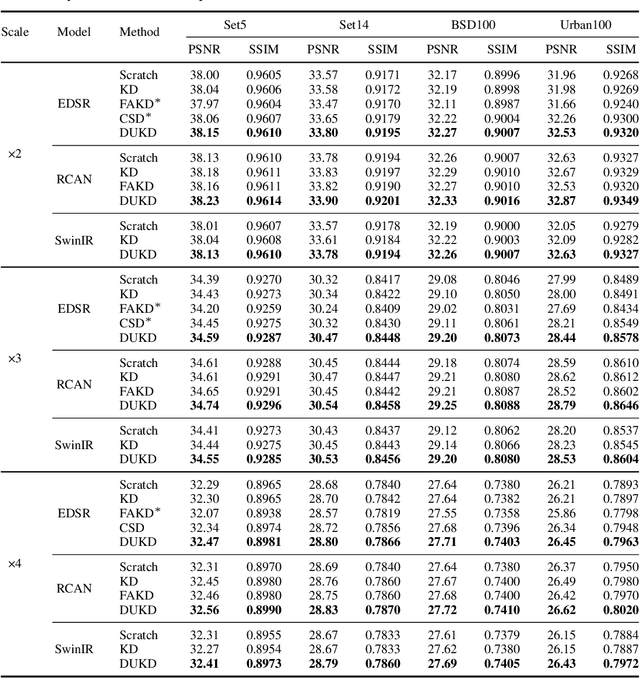
Knowledge distillation (KD) emerges as a challenging yet promising technique for compressing deep learning models, characterized by the transmission of extensive learning representations from proficient and computationally intensive teacher models to compact student models. However, only a handful of studies have endeavored to compress the models for single image super-resolution (SISR) through KD, with their effects on student model enhancement remaining marginal. In this paper, we put forth an approach from the perspective of efficient data utilization, namely, the Data Upcycling Knowledge Distillation (DUKD) which facilitates the student model by the prior knowledge teacher provided via upcycled in-domain data derived from their inputs. This upcycling process is realized through two efficient image zooming operations and invertible data augmentations which introduce the label consistency regularization to the field of KD for SISR and substantially boosts student model's generalization. The DUKD, due to its versatility, can be applied across a broad spectrum of teacher-student architectures. Comprehensive experiments across diverse benchmarks demonstrate that our proposed DUKD method significantly outperforms previous art, exemplified by an increase of up to 0.5dB in PSNR over baselines methods, and a 67% parameters reduced RCAN model's performance remaining on par with that of the RCAN teacher model.
Soft BPR Loss for Dynamic Hard Negative Sampling in Recommender Systems
Nov 25, 2022
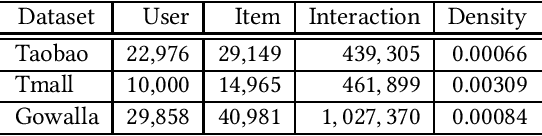
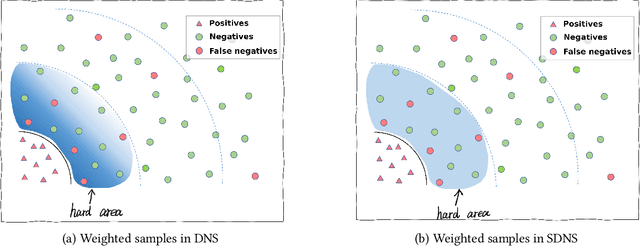
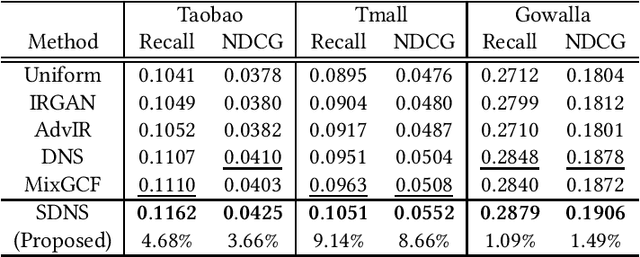
In recommender systems, leveraging Graph Neural Networks (GNNs) to formulate the bipartite relation between users and items is a promising way. However, powerful negative sampling methods that is adapted to GNN-based recommenders still requires a lot of efforts. One critical gap is that it is rather tough to distinguish real negatives from massive unobserved items during hard negative sampling. Towards this problem, this paper develops a novel hard negative sampling method for GNN-based recommendation systems by simply reformulating the loss function. We conduct various experiments on three datasets, demonstrating that the method proposed outperforms a set of state-of-the-art benchmarks.