 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChengju Liu
Efficient Text-driven Motion Generation via Latent Consistency Training
May 05, 2024
Motion diffusion models have recently proven successful for text-driven human motion generation. Despite their excellent generation performance, they are challenging to infer in real time due to the multi-step sampling mechanism that involves tens or hundreds of repeat function evaluation iterations. To this end, we investigate a motion latent consistency Training (MLCT) for motion generation to alleviate the computation and time consumption during iteration inference. It applies diffusion pipelines to low-dimensional motion latent spaces to mitigate the computational burden of each function evaluation. Explaining the diffusion process with probabilistic flow ordinary differential equation (PF-ODE) theory, the MLCT allows extremely few steps infer between the prior distribution to the motion latent representation distribution via maintaining consistency of the outputs over the trajectory of PF-ODE. Especially, we introduce a quantization constraint to optimize motion latent representations that are bounded, regular, and well-reconstructed compared to traditional variational constraints. Furthermore, we propose a conditional PF-ODE trajectory simulation method, which improves the conditional generation performance with minimal additional training costs. Extensive experiments on two human motion generation benchmarks show that the proposed model achieves state-of-the-art performance with less than 10\% time cost.
Vision-and-Language Navigation via Causal Learning
Apr 16, 2024In the pursuit of robust and generalizable environment perception and language understanding, the ubiquitous challenge of dataset bias continues to plague vision-and-language navigation (VLN) agents, hindering their performance in unseen environments. This paper introduces the generalized cross-modal causal transformer (GOAT), a pioneering solution rooted in the paradigm of causal inference. By delving into both observable and unobservable confounders within vision, language, and history, we propose the back-door and front-door adjustment causal learning (BACL and FACL) modules to promote unbiased learning by comprehensively mitigating potential spurious correlations. Additionally, to capture global confounder features, we propose a cross-modal feature pooling (CFP) module supervised by contrastive learning, which is also shown to be effective in improving cross-modal representations during pre-training. Extensive experiments across multiple VLN datasets (R2R, REVERIE, RxR, and SOON) underscore the superiority of our proposed method over previous state-of-the-art approaches. Code is available at https://github.com/CrystalSixone/VLN-GOAT.
Causality-based Cross-Modal Representation Learning for Vision-and-Language Navigation
Mar 06, 2024
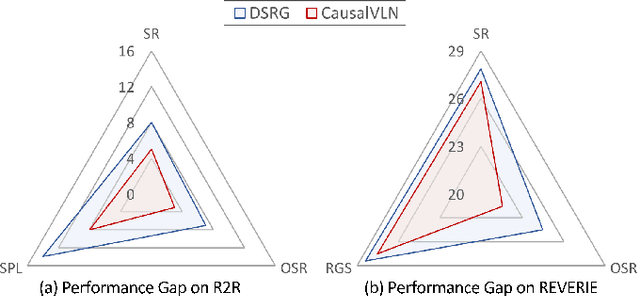
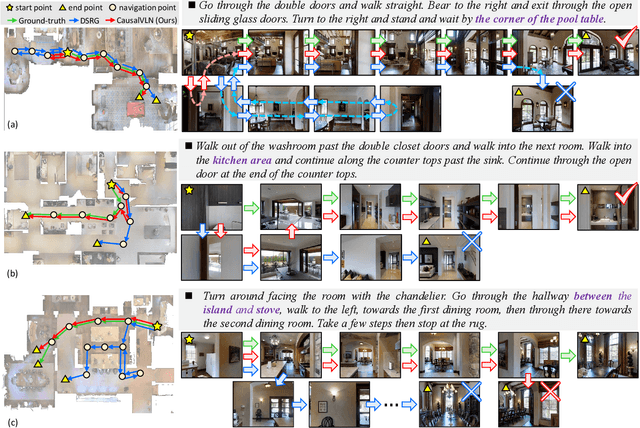

Vision-and-Language Navigation (VLN) has gained significant research interest in recent years due to its potential applications in real-world scenarios. However, existing VLN methods struggle with the issue of spurious associations, resulting in poor generalization with a significant performance gap between seen and unseen environments. In this paper, we tackle this challenge by proposing a unified framework CausalVLN based on the causal learning paradigm to train a robust navigator capable of learning unbiased feature representations. Specifically, we establish reasonable assumptions about confounders for vision and language in VLN using the structured causal model (SCM). Building upon this, we propose an iterative backdoor-based representation learning (IBRL) method that allows for the adaptive and effective intervention on confounders. Furthermore, we introduce the visual and linguistic backdoor causal encoders to enable unbiased feature expression for multi-modalities during training and validation, enhancing the agent's capability to generalize across different environments. Experiments on three VLN datasets (R2R, RxR, and REVERIE) showcase the superiority of our proposed method over previous state-of-the-art approaches. Moreover, detailed visualization analysis demonstrates the effectiveness of CausalVLN in significantly narrowing down the performance gap between seen and unseen environments, underscoring its strong generalization capability.
CLIPose: Category-Level Object Pose Estimation with Pre-trained Vision-Language Knowledge
Feb 24, 2024Most of existing category-level object pose estimation methods devote to learning the object category information from point cloud modality. However, the scale of 3D datasets is limited due to the high cost of 3D data collection and annotation. Consequently, the category features extracted from these limited point cloud samples may not be comprehensive. This motivates us to investigate whether we can draw on knowledge of other modalities to obtain category information. Inspired by this motivation, we propose CLIPose, a novel 6D pose framework that employs the pre-trained vision-language model to develop better learning of object category information, which can fully leverage abundant semantic knowledge in image and text modalities. To make the 3D encoder learn category-specific features more efficiently, we align representations of three modalities in feature space via multi-modal contrastive learning. In addition to exploiting the pre-trained knowledge of the CLIP's model, we also expect it to be more sensitive with pose parameters. Therefore, we introduce a prompt tuning approach to fine-tune image encoder while we incorporate rotations and translations information in the text descriptions. CLIPose achieves state-of-the-art performance on two mainstream benchmark datasets, REAL275 and CAMERA25, and runs in real-time during inference (40FPS).
TransPose: 6D Object Pose Estimation with Geometry-Aware Transformer
Oct 25, 2023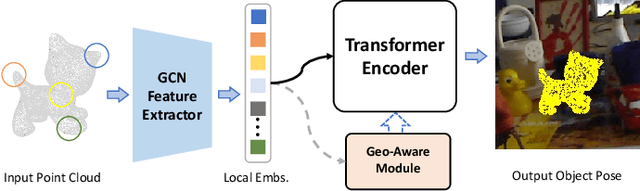
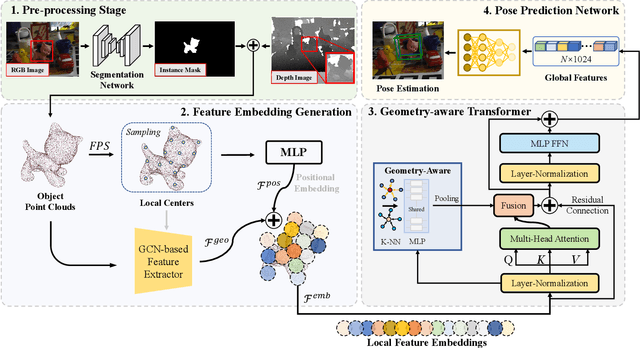
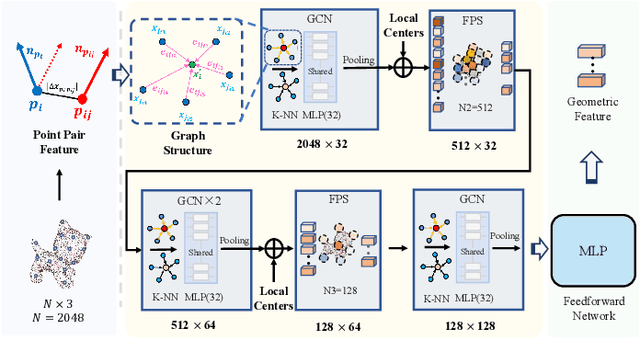
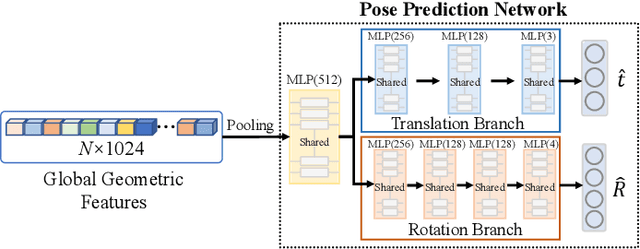
Estimating the 6D object pose is an essential task in many applications. Due to the lack of depth information, existing RGB-based methods are sensitive to occlusion and illumination changes. How to extract and utilize the geometry features in depth information is crucial to achieve accurate predictions. To this end, we propose TransPose, a novel 6D pose framework that exploits Transformer Encoder with geometry-aware module to develop better learning of point cloud feature representations. Specifically, we first uniformly sample point cloud and extract local geometry features with the designed local feature extractor base on graph convolution network. To improve robustness to occlusion, we adopt Transformer to perform the exchange of global information, making each local feature contains global information. Finally, we introduce geometry-aware module in Transformer Encoder, which to form an effective constrain for point cloud feature learning and makes the global information exchange more tightly coupled with point cloud tasks. Extensive experiments indicate the effectiveness of TransPose, our pose estimation pipeline achieves competitive results on three benchmark datasets.
InstructDET: Diversifying Referring Object Detection with Generalized Instructions
Oct 17, 2023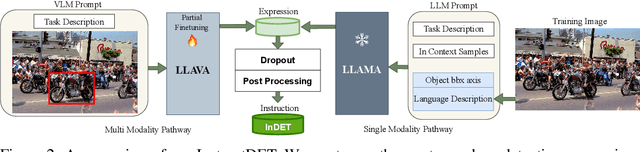

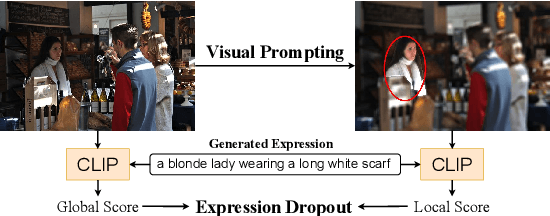
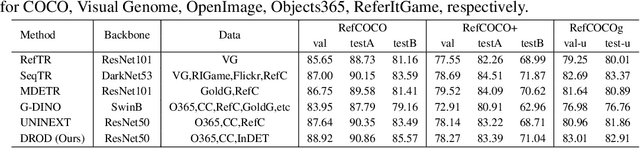
We propose InstructDET, a data-centric method for referring object detection (ROD) that localizes target objects based on user instructions. While deriving from referring expressions (REC), the instructions we leverage are greatly diversified to encompass common user intentions related to object detection. For one image, we produce tremendous instructions that refer to every single object and different combinations of multiple objects. Each instruction and its corresponding object bounding boxes (bbxs) constitute one training data pair. In order to encompass common detection expressions, we involve emerging vision-language model (VLM) and large language model (LLM) to generate instructions guided by text prompts and object bbxs, as the generalizations of foundation models are effective to produce human-like expressions (e.g., describing object property, category, and relationship). We name our constructed dataset as InDET. It contains images, bbxs and generalized instructions that are from foundation models. Our InDET is developed from existing REC datasets and object detection datasets, with the expanding potential that any image with object bbxs can be incorporated through using our InstructDET method. By using our InDET dataset, we show that a conventional ROD model surpasses existing methods on standard REC datasets and our InDET test set. Our data-centric method InstructDET, with automatic data expansion by leveraging foundation models, directs a promising field that ROD can be greatly diversified to execute common object detection instructions.
Ambient-Aware LiDAR Odometry in Variable Terrains
Sep 26, 2023

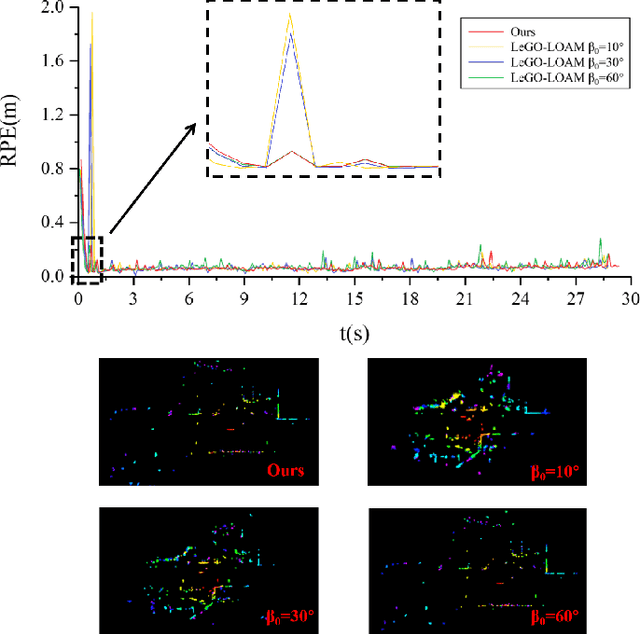
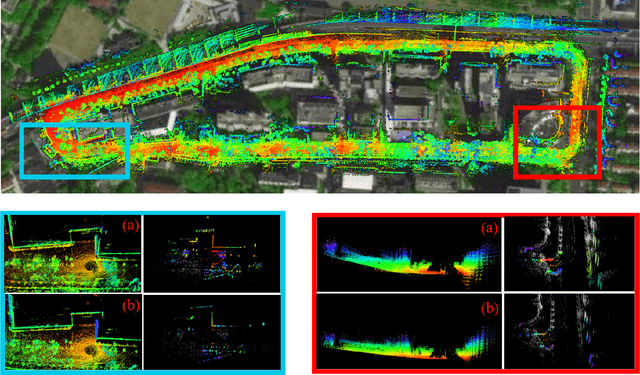
The flexibility of Simultaneous Localization and Mapping (SLAM) algorithms in various environments has consistently been a significant challenge. To address the issue of LiDAR odometry drift in high-noise settings, integrating clustering methods to filter out unstable features has become an effective module of SLAM frameworks. However, reducing the amount of point cloud data can lead to potential loss of information and possible degeneration. As a result, this research proposes a LiDAR odometry that can dynamically assess the point cloud's reliability. The algorithm aims to improve adaptability in diverse settings by selecting important feature points with sensitivity to the level of environmental degeneration. Firstly, a fast adaptive Euclidean clustering algorithm based on range image is proposed, which, combined with depth clustering, extracts the primary structural points of the environment defined as ambient skeleton points. Then, the environmental degeneration level is computed through the dense normal features of the skeleton points, and the point cloud cleaning is dynamically adjusted accordingly. The algorithm is validated on the KITTI benchmark and real environments, demonstrating higher accuracy and robustness in different environments.
Fine-Grained Spatiotemporal Motion Alignment for Contrastive Video Representation Learning
Sep 01, 2023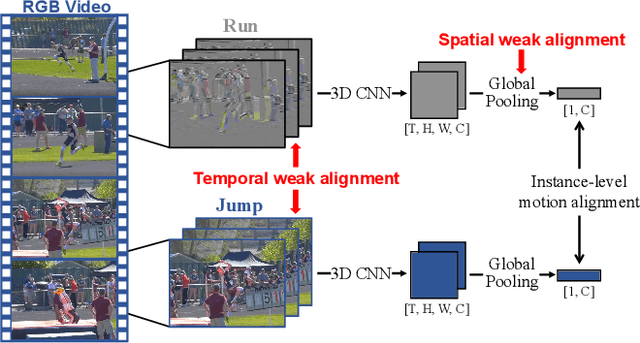



As the most essential property in a video, motion information is critical to a robust and generalized video representation. To inject motion dynamics, recent works have adopted frame difference as the source of motion information in video contrastive learning, considering the trade-off between quality and cost. However, existing works align motion features at the instance level, which suffers from spatial and temporal weak alignment across modalities. In this paper, we present a \textbf{Fi}ne-grained \textbf{M}otion \textbf{A}lignment (FIMA) framework, capable of introducing well-aligned and significant motion information. Specifically, we first develop a dense contrastive learning framework in the spatiotemporal domain to generate pixel-level motion supervision. Then, we design a motion decoder and a foreground sampling strategy to eliminate the weak alignments in terms of time and space. Moreover, a frame-level motion contrastive loss is presented to improve the temporal diversity of the motion features. Extensive experiments demonstrate that the representations learned by FIMA possess great motion-awareness capabilities and achieve state-of-the-art or competitive results on downstream tasks across UCF101, HMDB51, and Diving48 datasets. Code is available at \url{https://github.com/ZMHH-H/FIMA}.
PASTS: Progress-Aware Spatio-Temporal Transformer Speaker For Vision-and-Language Navigation
May 19, 2023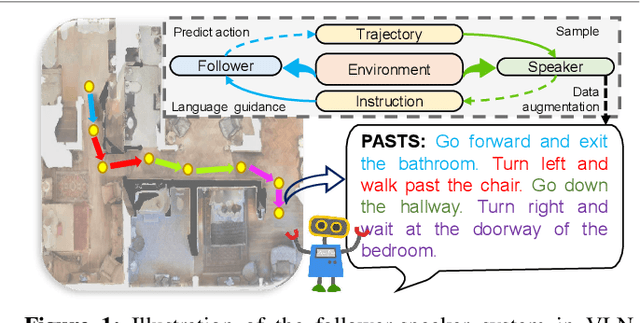
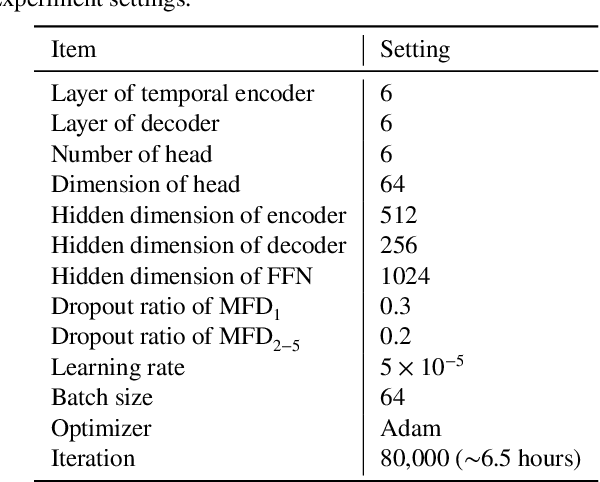
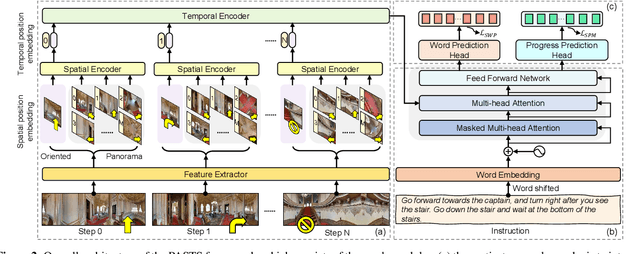

Vision-and-language navigation (VLN) is a crucial but challenging cross-modal navigation task. One powerful technique to enhance the generalization performance in VLN is the use of an independent speaker model to provide pseudo instructions for data augmentation. However, current speaker models based on Long-Short Term Memory (LSTM) lack the ability to attend to features relevant at different locations and time steps. To address this, we propose a novel progress-aware spatio-temporal transformer speaker (PASTS) model that uses the transformer as the core of the network. PASTS uses a spatio-temporal encoder to fuse panoramic representations and encode intermediate connections through steps. Besides, to avoid the misalignment problem that could result in incorrect supervision, a speaker progress monitor (SPM) is proposed to enable the model to estimate the progress of instruction generation and facilitate more fine-grained caption results. Additionally, a multifeature dropout (MFD) strategy is introduced to alleviate overfitting. The proposed PASTS is flexible to be combined with existing VLN models. The experimental results demonstrate that PASTS outperforms all existing speaker models and successfully improves the performance of previous VLN models, achieving state-of-the-art performance on the standard Room-to-Room (R2R) dataset.
A Dual Semantic-Aware Recurrent Global-Adaptive Network For Vision-and-Language Navigation
May 05, 2023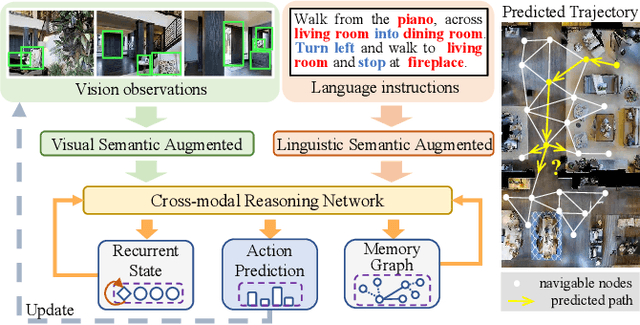
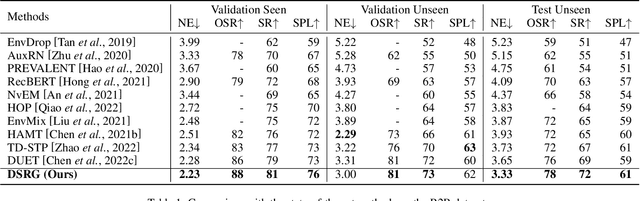

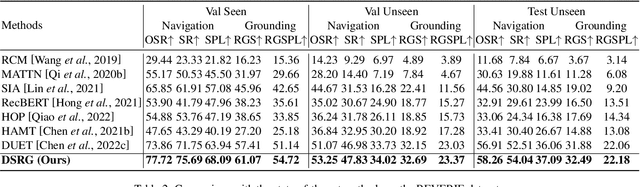
Vision-and-Language Navigation (VLN) is a realistic but challenging task that requires an agent to locate the target region using verbal and visual cues. While significant advancements have been achieved recently, there are still two broad limitations: (1) The explicit information mining for significant guiding semantics concealed in both vision and language is still under-explored; (2) The previously structured map method provides the average historical appearance of visited nodes, while it ignores distinctive contributions of various images and potent information retention in the reasoning process. This work proposes a dual semantic-aware recurrent global-adaptive network (DSRG) to address the above problems. First, DSRG proposes an instruction-guidance linguistic module (IGL) and an appearance-semantics visual module (ASV) for boosting vision and language semantic learning respectively. For the memory mechanism, a global adaptive aggregation module (GAA) is devised for explicit panoramic observation fusion, and a recurrent memory fusion module (RMF) is introduced to supply implicit temporal hidden states. Extensive experimental results on the R2R and REVERIE datasets demonstrate that our method achieves better performance than existing methods.