 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeng Zhu
Causal Deconfounding via Confounder Disentanglement for Dual-Target Cross-Domain Recommendation
Apr 17, 2024
In recent years, dual-target Cross-Domain Recommendation (CDR) has been proposed to capture comprehensive user preferences in order to ultimately enhance the recommendation accuracy in both data-richer and data-sparser domains simultaneously. However, in addition to users' true preferences, the user-item interactions might also be affected by confounders (e.g., free shipping, sales promotion). As a result, dual-target CDR has to meet two challenges: (1) how to effectively decouple observed confounders, including single-domain confounders and cross-domain confounders, and (2) how to preserve the positive effects of observed confounders on predicted interactions, while eliminating their negative effects on capturing comprehensive user preferences. To address the above two challenges, we propose a Causal Deconfounding framework via Confounder Disentanglement for dual-target Cross-Domain Recommendation, called CD2CDR. In CD2CDR, we first propose a confounder disentanglement module to effectively decouple observed single-domain and cross-domain confounders. We then propose a causal deconfounding module to preserve the positive effects of such observed confounders and eliminate their negative effects via backdoor adjustment, thereby enhancing the recommendation accuracy in each domain. Extensive experiments conducted on five real-world datasets demonstrate that CD2CDR significantly outperforms the state-of-the-art methods.
3D Geometry-aware Deformable Gaussian Splatting for Dynamic View Synthesis
Apr 14, 2024In this paper, we propose a 3D geometry-aware deformable Gaussian Splatting method for dynamic view synthesis. Existing neural radiance fields (NeRF) based solutions learn the deformation in an implicit manner, which cannot incorporate 3D scene geometry. Therefore, the learned deformation is not necessarily geometrically coherent, which results in unsatisfactory dynamic view synthesis and 3D dynamic reconstruction. Recently, 3D Gaussian Splatting provides a new representation of the 3D scene, building upon which the 3D geometry could be exploited in learning the complex 3D deformation. Specifically, the scenes are represented as a collection of 3D Gaussian, where each 3D Gaussian is optimized to move and rotate over time to model the deformation. To enforce the 3D scene geometry constraint during deformation, we explicitly extract 3D geometry features and integrate them in learning the 3D deformation. In this way, our solution achieves 3D geometry-aware deformation modeling, which enables improved dynamic view synthesis and 3D dynamic reconstruction. Extensive experimental results on both synthetic and real datasets prove the superiority of our solution, which achieves new state-of-the-art performance. The project is available at https://npucvr.github.io/GaGS/
Online Local False Discovery Rate Control: A Resource Allocation Approach
Feb 18, 2024We consider the problem of online local false discovery rate (FDR) control where multiple tests are conducted sequentially, with the goal of maximizing the total expected number of discoveries. We formulate the problem as an online resource allocation problem with accept/reject decisions, which from a high level can be viewed as an online knapsack problem, with the additional uncertainty of random budget replenishment. We start with general arrival distributions and propose a simple policy that achieves a $O(\sqrt{T})$ regret. We complement the result by showing that such regret rate is in general not improvable. We then shift our focus to discrete arrival distributions. We find that many existing re-solving heuristics in the online resource allocation literature, albeit achieve bounded loss in canonical settings, may incur a $\Omega(\sqrt{T})$ or even a $\Omega(T)$ regret. With the observation that canonical policies tend to be too optimistic and over accept arrivals, we propose a novel policy that incorporates budget buffers. We show that small additional logarithmic buffers suffice to reduce the regret from $\Omega(\sqrt{T})$ or even $\Omega(T)$ to $O(\ln^2 T)$. Numerical experiments are conducted to validate our theoretical findings. Our formulation may have wider applications beyond the problem considered in this paper, and our results emphasize how effective policies should be designed to reach a balance between circumventing wrong accept and reducing wrong reject in online resource allocation problems with uncertain budgets.
Professional Agents -- Evolving Large Language Models into Autonomous Experts with Human-Level Competencies
Feb 06, 2024The advent of large language models (LLMs) such as ChatGPT, PaLM, and GPT-4 has catalyzed remarkable advances in natural language processing, demonstrating human-like language fluency and reasoning capacities. This position paper introduces the concept of Professional Agents (PAgents), an application framework harnessing LLM capabilities to create autonomous agents with controllable, specialized, interactive, and professional-level competencies. We posit that PAgents can reshape professional services through continuously developed expertise. Our proposed PAgents framework entails a tri-layered architecture for genesis, evolution, and synergy: a base tool layer, a middle agent layer, and a top synergy layer. This paper aims to spur discourse on promising real-world applications of LLMs. We argue the increasing sophistication and integration of PAgents could lead to AI systems exhibiting professional mastery over complex domains, serving critical needs, and potentially achieving artificial general intelligence.
On State Estimation in Multi-Sensor Fusion Navigation: Optimization and Filtering
Jan 11, 2024The essential of navigation, perception, and decision-making which are basic tasks for intelligent robots, is to estimate necessary system states. Among them, navigation is fundamental for other upper applications, providing precise position and orientation, by integrating measurements from multiple sensors. With observations of each sensor appropriately modelled, multi-sensor fusion tasks for navigation are reduced to the state estimation problem which can be solved by two approaches: optimization and filtering. Recent research has shown that optimization-based frameworks outperform filtering-based ones in terms of accuracy. However, both methods are based on maximum likelihood estimation (MLE) and should be theoretically equivalent with the same linearization points, observation model, measurements, and Gaussian noise assumption. In this paper, we deeply dig into the theories and existing strategies utilized in both optimization-based and filtering-based approaches. It is demonstrated that the two methods are equal theoretically, but this equivalence corrupts due to different strategies applied in real-time operation. By adjusting existing strategies of the filtering-based approaches, the Monte-Carlo simulation and vehicular ablation experiments based on visual odometry (VO) indicate that the strategy adjusted filtering strictly equals to optimization. Therefore, future research on sensor-fusion problems should concentrate on their own algorithms and strategies rather than state estimation approaches.
VisionTraj: A Noise-Robust Trajectory Recovery Framework based on Large-scale Camera Network
Dec 11, 2023

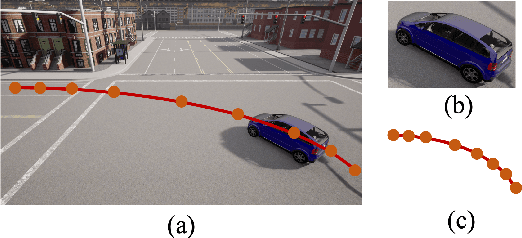

Trajectory recovery based on the snapshots from the city-wide multi-camera network facilitates urban mobility sensing and driveway optimization. The state-of-the-art solutions devoted to such a vision-based scheme typically incorporate predefined rules or unsupervised iterative feedback, struggling with multi-fold challenges such as lack of open-source datasets for training the whole pipeline, and the vulnerability to the noises from visual inputs. In response to the dilemma, this paper proposes VisionTraj, the first learning-based model that reconstructs vehicle trajectories from snapshots recorded by road network cameras. Coupled with it, we elaborate on two rational vision-trajectory datasets, which produce extensive trajectory data along with corresponding visual snapshots, enabling supervised vision-trajectory interplay extraction. Following the data creation, based on the results from the off-the-shelf multi-modal vehicle clustering, we first re-formulate the trajectory recovery problem as a generative task and introduce the canonical Transformer as the autoregressive backbone. Then, to identify clustering noises (e.g., false positives) with the bound on the snapshots' spatiotemporal dependencies, a GCN-based soft-denoising module is conducted based on the fine- and coarse-grained Re-ID clusters. Additionally, we harness strong semantic information extracted from the tracklet to provide detailed insights into the vehicle's entry and exit actions during trajectory recovery. The denoising and tracklet components can also act as plug-and-play modules to boost baselines. Experimental results on the two hand-crafted datasets show that the proposed VisionTraj achieves a maximum +11.5% improvement against the sub-best model.
Hulk: A Universal Knowledge Translator for Human-Centric Tasks
Dec 05, 2023Human-centric perception tasks, e.g., human mesh recovery, pedestrian detection, skeleton-based action recognition, and pose estimation, have wide industrial applications, such as metaverse and sports analysis. There is a recent surge to develop human-centric foundation models that can benefit a broad range of human-centric perception tasks. While many human-centric foundation models have achieved success, most of them only excel in 2D vision tasks or require extensive fine-tuning for practical deployment in real-world scenarios. These limitations severely restrict their usability across various downstream tasks and situations. To tackle these problems, we present Hulk, the first multimodal human-centric generalist model, capable of addressing most of the mainstream tasks simultaneously without task-specific finetuning, covering 2D vision, 3D vision, skeleton-based, and vision-language tasks. The key to achieving this is condensing various task-specific heads into two general heads, one for discrete representations, e.g., languages, and the other for continuous representations, e.g., location coordinates. The outputs of two heads can be further stacked into four distinct input and output modalities. This uniform representation enables Hulk to treat human-centric tasks as modality translation, integrating knowledge across a wide range of tasks. To validate the effectiveness of our proposed method, we conduct comprehensive experiments on 11 benchmarks across 8 human-centric tasks. Experimental results surpass previous methods substantially, demonstrating the superiority of our proposed method. The code will be available on https://github.com/OpenGVLab/HumanBench.
InstructDET: Diversifying Referring Object Detection with Generalized Instructions
Oct 17, 2023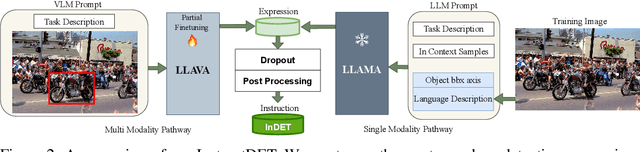

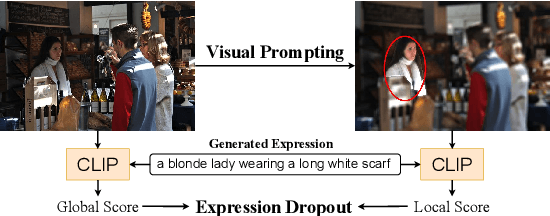
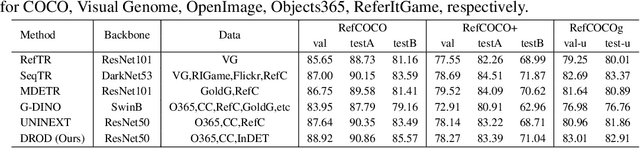
We propose InstructDET, a data-centric method for referring object detection (ROD) that localizes target objects based on user instructions. While deriving from referring expressions (REC), the instructions we leverage are greatly diversified to encompass common user intentions related to object detection. For one image, we produce tremendous instructions that refer to every single object and different combinations of multiple objects. Each instruction and its corresponding object bounding boxes (bbxs) constitute one training data pair. In order to encompass common detection expressions, we involve emerging vision-language model (VLM) and large language model (LLM) to generate instructions guided by text prompts and object bbxs, as the generalizations of foundation models are effective to produce human-like expressions (e.g., describing object property, category, and relationship). We name our constructed dataset as InDET. It contains images, bbxs and generalized instructions that are from foundation models. Our InDET is developed from existing REC datasets and object detection datasets, with the expanding potential that any image with object bbxs can be incorporated through using our InstructDET method. By using our InDET dataset, we show that a conventional ROD model surpasses existing methods on standard REC datasets and our InDET test set. Our data-centric method InstructDET, with automatic data expansion by leveraging foundation models, directs a promising field that ROD can be greatly diversified to execute common object detection instructions.
DRAG: Divergence-based Adaptive Aggregation in Federated learning on Non-IID Data
Sep 04, 2023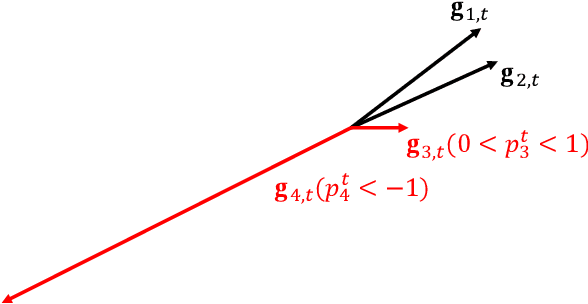
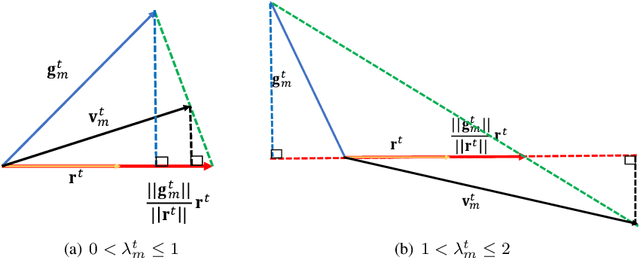
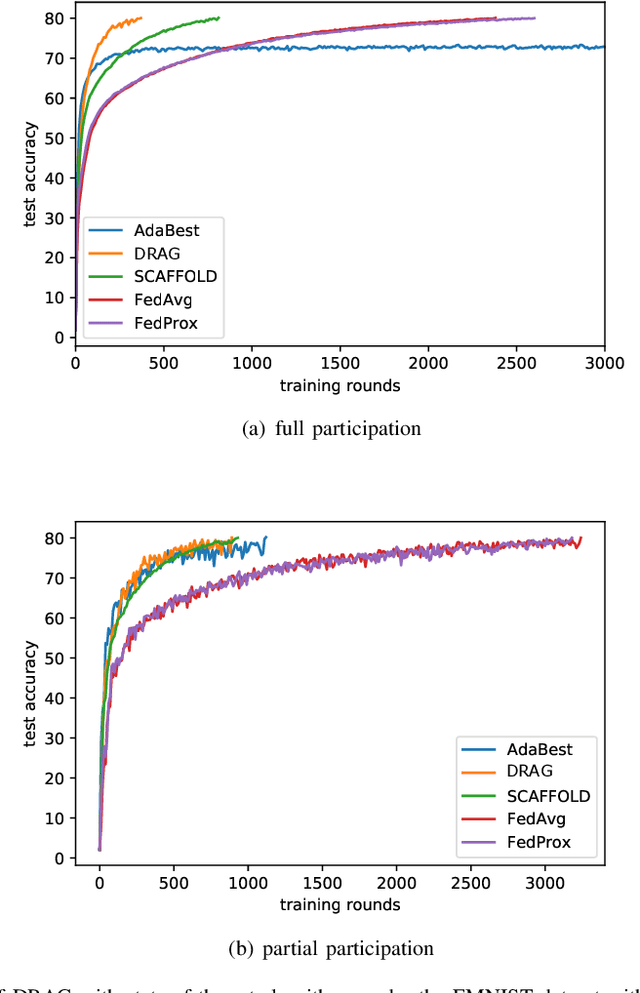

Local stochastic gradient descent (SGD) is a fundamental approach in achieving communication efficiency in Federated Learning (FL) by allowing individual workers to perform local updates. However, the presence of heterogeneous data distributions across working nodes causes each worker to update its local model towards a local optimum, leading to the phenomenon known as ``client-drift" and resulting in slowed convergence. To address this issue, previous works have explored methods that either introduce communication overhead or suffer from unsteady performance. In this work, we introduce a novel metric called ``degree of divergence," quantifying the angle between the local gradient and the global reference direction. Leveraging this metric, we propose the divergence-based adaptive aggregation (DRAG) algorithm, which dynamically ``drags" the received local updates toward the reference direction in each round without requiring extra communication overhead. Furthermore, we establish a rigorous convergence analysis for DRAG, proving its ability to achieve a sublinear convergence rate. Compelling experimental results are presented to illustrate DRAG's superior performance compared to state-of-the-art algorithms in effectively managing the client-drift phenomenon. Additionally, DRAG exhibits remarkable resilience against certain Byzantine attacks. By securely sharing a small sample of the client's data with the FL server, DRAG effectively counters these attacks, as demonstrated through comprehensive experiments.
Link-Context Learning for Multimodal LLMs
Aug 15, 2023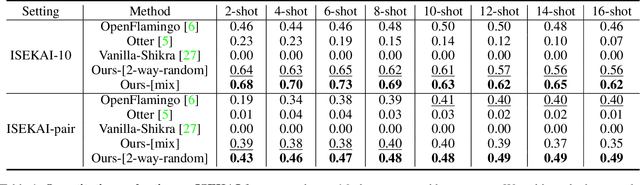
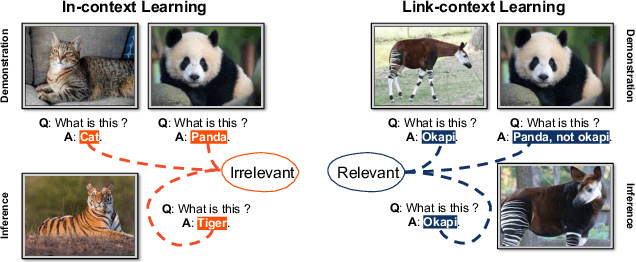


The ability to learn from context with novel concepts, and deliver appropriate responses are essential in human conversations. Despite current Multimodal Large Language Models (MLLMs) and Large Language Models (LLMs) being trained on mega-scale datasets, recognizing unseen images or understanding novel concepts in a training-free manner remains a challenge. In-Context Learning (ICL) explores training-free few-shot learning, where models are encouraged to ``learn to learn" from limited tasks and generalize to unseen tasks. In this work, we propose link-context learning (LCL), which emphasizes "reasoning from cause and effect" to augment the learning capabilities of MLLMs. LCL goes beyond traditional ICL by explicitly strengthening the causal relationship between the support set and the query set. By providing demonstrations with causal links, LCL guides the model to discern not only the analogy but also the underlying causal associations between data points, which empowers MLLMs to recognize unseen images and understand novel concepts more effectively. To facilitate the evaluation of this novel approach, we introduce the ISEKAI dataset, comprising exclusively of unseen generated image-label pairs designed for link-context learning. Extensive experiments show that our LCL-MLLM exhibits strong link-context learning capabilities to novel concepts over vanilla MLLMs. Code and data will be released at https://github.com/isekai-portal/Link-Context-Learning.