 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhuo Xu
SSHPool: The Separated Subgraph-based Hierarchical Pooling
Mar 24, 2024
In this paper, we develop a novel local graph pooling method, namely the Separated Subgraph-based Hierarchical Pooling (SSHPool), for graph classification. To this end, we commence by assigning the nodes of a sample graph into different clusters, resulting in a family of separated subgraphs. We individually employ a local graph convolution units as the local structure to further compress each subgraph into a coarsened node, transforming the original graph into a coarsened graph. Since these subgraphs are separated by different clusters and the structural information cannot be propagated between them, the local convolution operation can significantly avoid the over-smoothing problem arising in most existing Graph Neural Networks (GNNs). By hierarchically performing the proposed procedures on the resulting coarsened graph, the proposed SSHPool can effectively extract the hierarchical global feature of the original graph structure, encapsulating rich intrinsic structural characteristics. Furthermore, we develop an end-to-end GNN framework associated with the proposed SSHPool module for graph classification. Experimental results demonstrate the superior performance of the proposed model on real-world datasets, significantly outperforming state-of-the-art GNN methods in terms of the classification accuracies.
MATRIX: Multi-Agent Trajectory Generation with Diverse Contexts
Mar 09, 2024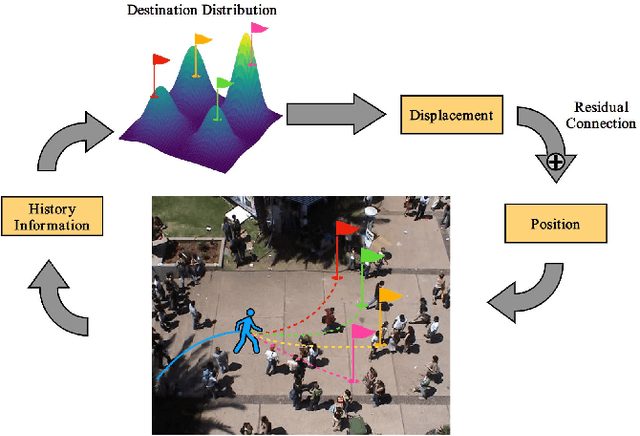
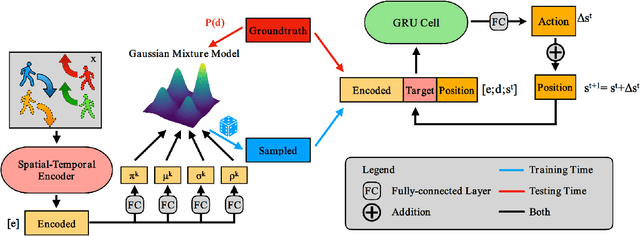
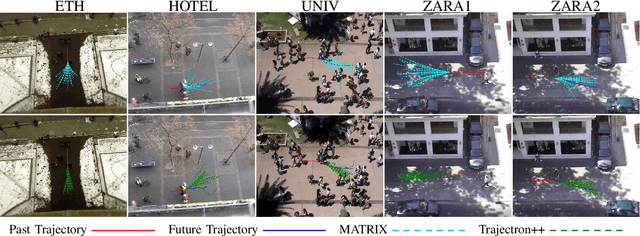

Data-driven methods have great advantages in modeling complicated human behavioral dynamics and dealing with many human-robot interaction applications. However, collecting massive and annotated real-world human datasets has been a laborious task, especially for highly interactive scenarios. On the other hand, algorithmic data generation methods are usually limited by their model capacities, making them unable to offer realistic and diverse data needed by various application users. In this work, we study trajectory-level data generation for multi-human or human-robot interaction scenarios and propose a learning-based automatic trajectory generation model, which we call Multi-Agent TRajectory generation with dIverse conteXts (MATRIX). MATRIX is capable of generating interactive human behaviors in realistic diverse contexts. We achieve this goal by modeling the explicit and interpretable objectives so that MATRIX can generate human motions based on diverse destinations and heterogeneous behaviors. We carried out extensive comparison and ablation studies to illustrate the effectiveness of our approach across various metrics. We also presented experiments that demonstrate the capability of MATRIX to serve as data augmentation for imitation-based motion planning.
PIVOT: Iterative Visual Prompting Elicits Actionable Knowledge for VLMs
Feb 12, 2024Vision language models (VLMs) have shown impressive capabilities across a variety of tasks, from logical reasoning to visual understanding. This opens the door to richer interaction with the world, for example robotic control. However, VLMs produce only textual outputs, while robotic control and other spatial tasks require outputting continuous coordinates, actions, or trajectories. How can we enable VLMs to handle such settings without fine-tuning on task-specific data? In this paper, we propose a novel visual prompting approach for VLMs that we call Prompting with Iterative Visual Optimization (PIVOT), which casts tasks as iterative visual question answering. In each iteration, the image is annotated with a visual representation of proposals that the VLM can refer to (e.g., candidate robot actions, localizations, or trajectories). The VLM then selects the best ones for the task. These proposals are iteratively refined, allowing the VLM to eventually zero in on the best available answer. We investigate PIVOT on real-world robotic navigation, real-world manipulation from images, instruction following in simulation, and additional spatial inference tasks such as localization. We find, perhaps surprisingly, that our approach enables zero-shot control of robotic systems without any robot training data, navigation in a variety of environments, and other capabilities. Although current performance is far from perfect, our work highlights potentials and limitations of this new regime and shows a promising approach for Internet-Scale VLMs in robotic and spatial reasoning domains. Website: pivot-prompt.github.io and HuggingFace: https://huggingface.co/spaces/pivot-prompt/pivot-prompt-demo.
Generative Expressive Robot Behaviors using Large Language Models
Jan 30, 2024People employ expressive behaviors to effectively communicate and coordinate their actions with others, such as nodding to acknowledge a person glancing at them or saying "excuse me" to pass people in a busy corridor. We would like robots to also demonstrate expressive behaviors in human-robot interaction. Prior work proposes rule-based methods that struggle to scale to new communication modalities or social situations, while data-driven methods require specialized datasets for each social situation the robot is used in. We propose to leverage the rich social context available from large language models (LLMs) and their ability to generate motion based on instructions or user preferences, to generate expressive robot motion that is adaptable and composable, building upon each other. Our approach utilizes few-shot chain-of-thought prompting to translate human language instructions into parametrized control code using the robot's available and learned skills. Through user studies and simulation experiments, we demonstrate that our approach produces behaviors that users found to be competent and easy to understand. Supplementary material can be found at https://generative-expressive-motion.github.io/.
AutoRT: Embodied Foundation Models for Large Scale Orchestration of Robotic Agents
Jan 23, 2024Foundation models that incorporate language, vision, and more recently actions have revolutionized the ability to harness internet scale data to reason about useful tasks. However, one of the key challenges of training embodied foundation models is the lack of data grounded in the physical world. In this paper, we propose AutoRT, a system that leverages existing foundation models to scale up the deployment of operational robots in completely unseen scenarios with minimal human supervision. AutoRT leverages vision-language models (VLMs) for scene understanding and grounding, and further uses large language models (LLMs) for proposing diverse and novel instructions to be performed by a fleet of robots. Guiding data collection by tapping into the knowledge of foundation models enables AutoRT to effectively reason about autonomy tradeoffs and safety while significantly scaling up data collection for robot learning. We demonstrate AutoRT proposing instructions to over 20 robots across multiple buildings and collecting 77k real robot episodes via both teleoperation and autonomous robot policies. We experimentally show that such "in-the-wild" data collected by AutoRT is significantly more diverse, and that AutoRT's use of LLMs allows for instruction following data collection robots that can align to human preferences.
SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities
Jan 22, 2024Understanding and reasoning about spatial relationships is a fundamental capability for Visual Question Answering (VQA) and robotics. While Vision Language Models (VLM) have demonstrated remarkable performance in certain VQA benchmarks, they still lack capabilities in 3D spatial reasoning, such as recognizing quantitative relationships of physical objects like distances or size differences. We hypothesize that VLMs' limited spatial reasoning capability is due to the lack of 3D spatial knowledge in training data and aim to solve this problem by training VLMs with Internet-scale spatial reasoning data. To this end, we present a system to facilitate this approach. We first develop an automatic 3D spatial VQA data generation framework that scales up to 2 billion VQA examples on 10 million real-world images. We then investigate various factors in the training recipe, including data quality, training pipeline, and VLM architecture. Our work features the first internet-scale 3D spatial reasoning dataset in metric space. By training a VLM on such data, we significantly enhance its ability on both qualitative and quantitative spatial VQA. Finally, we demonstrate that this VLM unlocks novel downstream applications in chain-of-thought spatial reasoning and robotics due to its quantitative estimation capability. Project website: https://spatial-vlm.github.io/
On State Estimation in Multi-Sensor Fusion Navigation: Optimization and Filtering
Jan 11, 2024The essential of navigation, perception, and decision-making which are basic tasks for intelligent robots, is to estimate necessary system states. Among them, navigation is fundamental for other upper applications, providing precise position and orientation, by integrating measurements from multiple sensors. With observations of each sensor appropriately modelled, multi-sensor fusion tasks for navigation are reduced to the state estimation problem which can be solved by two approaches: optimization and filtering. Recent research has shown that optimization-based frameworks outperform filtering-based ones in terms of accuracy. However, both methods are based on maximum likelihood estimation (MLE) and should be theoretically equivalent with the same linearization points, observation model, measurements, and Gaussian noise assumption. In this paper, we deeply dig into the theories and existing strategies utilized in both optimization-based and filtering-based approaches. It is demonstrated that the two methods are equal theoretically, but this equivalence corrupts due to different strategies applied in real-time operation. By adjusting existing strategies of the filtering-based approaches, the Monte-Carlo simulation and vehicular ablation experiments based on visual odometry (VO) indicate that the strategy adjusted filtering strictly equals to optimization. Therefore, future research on sensor-fusion problems should concentrate on their own algorithms and strategies rather than state estimation approaches.
RT-Trajectory: Robotic Task Generalization via Hindsight Trajectory Sketches
Nov 06, 2023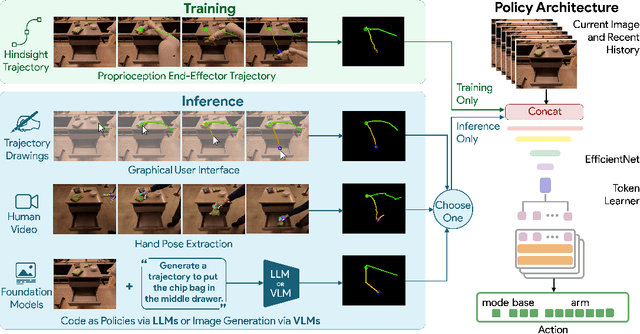
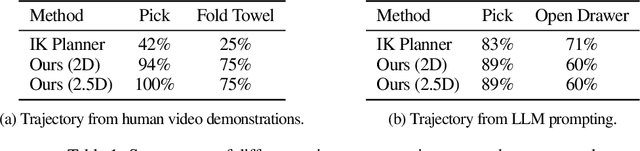
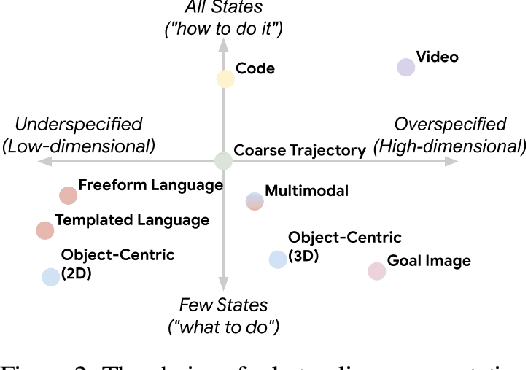

Generalization remains one of the most important desiderata for robust robot learning systems. While recently proposed approaches show promise in generalization to novel objects, semantic concepts, or visual distribution shifts, generalization to new tasks remains challenging. For example, a language-conditioned policy trained on pick-and-place tasks will not be able to generalize to a folding task, even if the arm trajectory of folding is similar to pick-and-place. Our key insight is that this kind of generalization becomes feasible if we represent the task through rough trajectory sketches. We propose a policy conditioning method using such rough trajectory sketches, which we call RT-Trajectory, that is practical, easy to specify, and allows the policy to effectively perform new tasks that would otherwise be challenging to perform. We find that trajectory sketches strike a balance between being detailed enough to express low-level motion-centric guidance while being coarse enough to allow the learned policy to interpret the trajectory sketch in the context of situational visual observations. In addition, we show how trajectory sketches can provide a useful interface to communicate with robotic policies: they can be specified through simple human inputs like drawings or videos, or through automated methods such as modern image-generating or waypoint-generating methods. We evaluate RT-Trajectory at scale on a variety of real-world robotic tasks, and find that RT-Trajectory is able to perform a wider range of tasks compared to language-conditioned and goal-conditioned policies, when provided the same training data.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023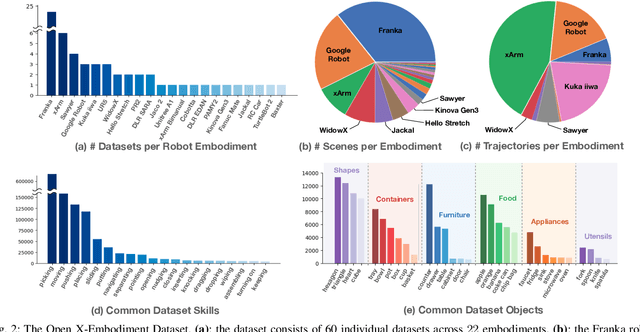
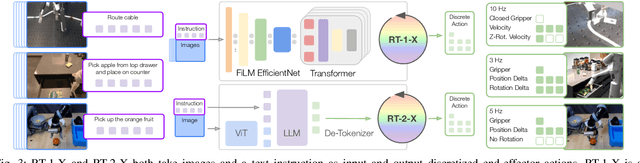
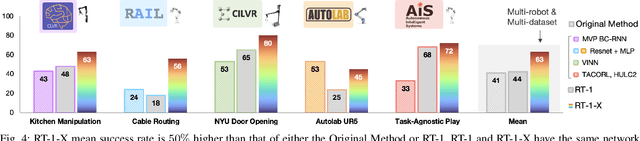

Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.